 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Differentiable Shadow Computation for Inverse Problems
Apr 01, 2021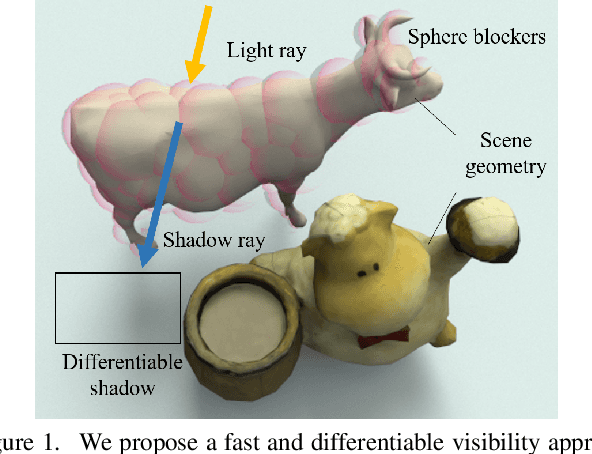
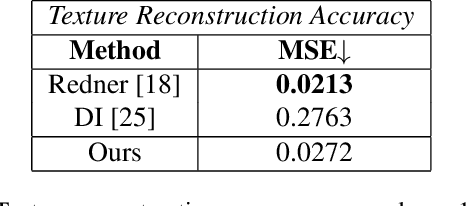
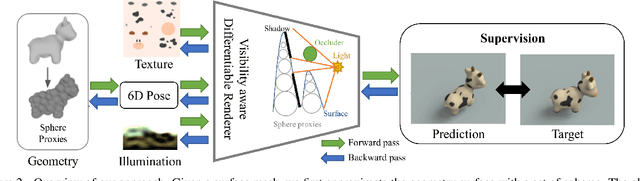
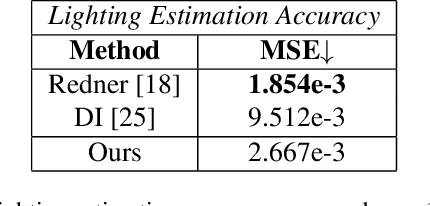
Differentiable rendering has received increasing interest for image-based inverse problems. It can benefit traditional optimization-based solutions to inverse problems, but also allows for self-supervision of learning-based approaches for which training data with ground truth annotation is hard to obtain. However, existing differentiable renderers either do not model visibility of the light sources from the different points in the scene, responsible for shadows in the images, or are too slow for being used to train deep architectures over thousands of iterations. To this end, we propose an accurate yet efficient approach for differentiable visibility and soft shadow computation. Our approach is based on the spherical harmonics approximations of the scene illumination and visibility, where the occluding surface is approximated with spheres. This allows for a significantly more efficient shadow computation compared to methods based on ray tracing. As our formulation is differentiable, it can be used to solve inverse problems such as texture, illumination, rigid pose, and geometric deformation recovery from images using analysis-by-synthesis optimization.
Synthesis of Compositional Animations from Textual Descriptions
Mar 31, 2021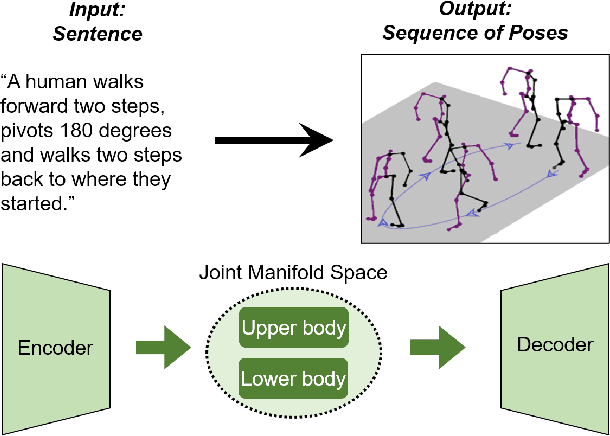
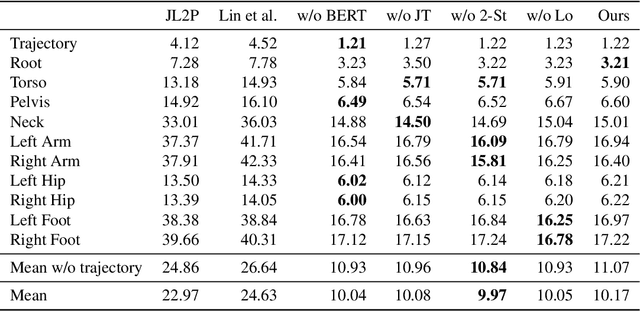
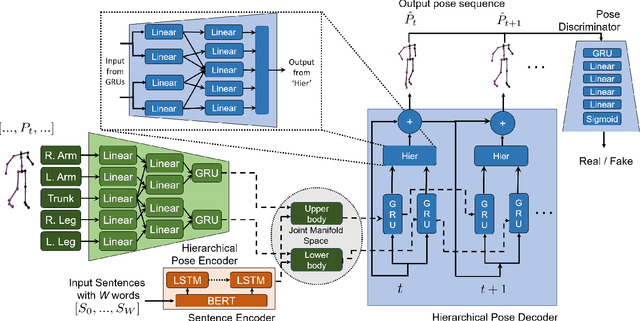
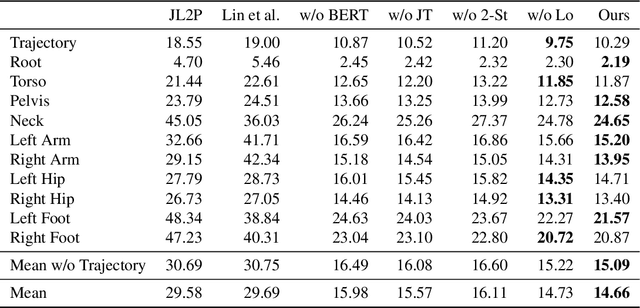
"How can we animate 3D-characters from a movie script or move robots by simply telling them what we would like them to do?" "How unstructured and complex can we make a sentence and still generate plausible movements from it?" These are questions that need to be answered in the long-run, as the field is still in its infancy. Inspired by these problems, we present a new technique for generating compositional actions, which handles complex input sentences. Our output is a 3D pose sequence depicting the actions in the input sentence. We propose a hierarchical two-stream sequential model to explore a finer joint-level mapping between natural language sentences and 3D pose sequences corresponding to the given motion. We learn two manifold representations of the motion -- one each for the upper body and the lower body movements. Our model can generate plausible pose sequences for short sentences describing single actions as well as long compositional sentences describing multiple sequential and superimposed actions. We evaluate our proposed model on the publicly available KIT Motion-Language Dataset containing 3D pose data with human-annotated sentences. Experimental results show that our model advances the state-of-the-art on text-based motion synthesis in objective evaluations by a margin of 50%. Qualitative evaluations based on a user study indicate that our synthesized motions are perceived to be the closest to the ground-truth motion captures for both short and compositional sentences.
Adaptive Surface Normal Constraint for Depth Estimation
Mar 29, 2021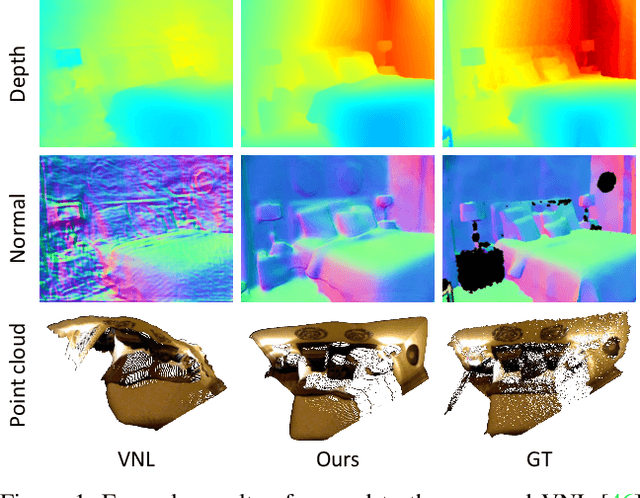
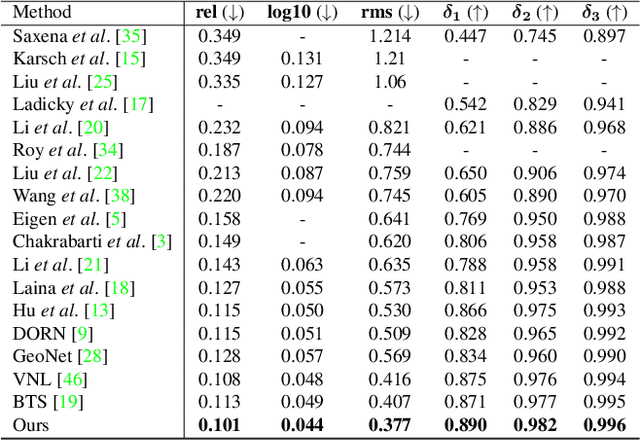
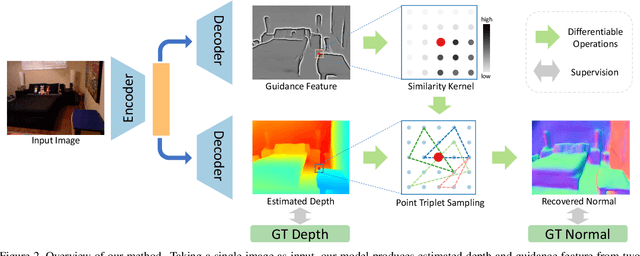
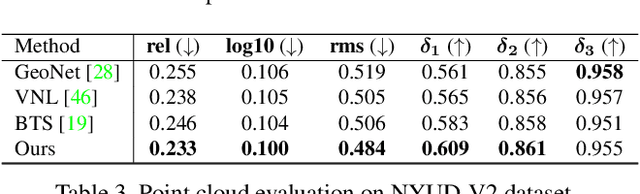
We present a novel method for single image depth estimation using surface normal constraints. Existing depth estimation methods either suffer from the lack of geometric constraints, or are limited to the difficulty of reliably capturing geometric context, which leads to a bottleneck of depth estimation quality. We therefore introduce a simple yet effective method, named Adaptive Surface Normal (ASN) constraint, to effectively correlate the depth estimation with geometric consistency. Our key idea is to adaptively determine the reliable local geometry from a set of randomly sampled candidates to derive surface normal constraint, for which we measure the consistency of the geometric contextual features. As a result, our method can faithfully reconstruct the 3D geometry and is robust to local shape variations, such as boundaries, sharp corners and noises. We conduct extensive evaluations and comparisons using public datasets. The experimental results demonstrate our method outperforms the state-of-the-art methods and has superior efficiency and robustness.
Towards High Fidelity Monocular Face Reconstruction with Rich Reflectance using Self-supervised Learning and Ray Tracing
Mar 29, 2021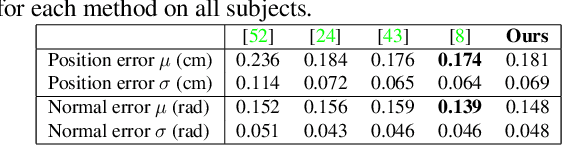
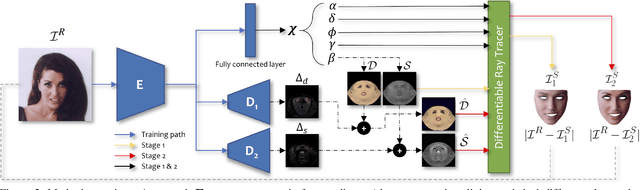
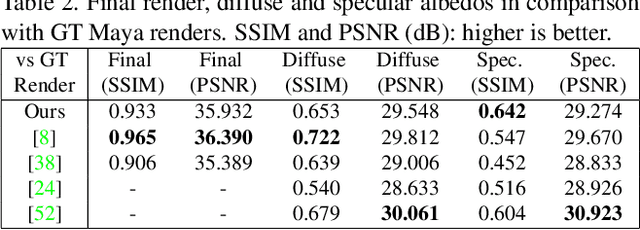
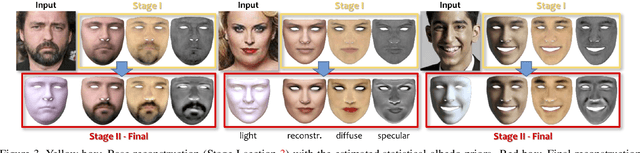
Robust face reconstruction from monocular image in general lighting conditions is challenging. Methods combining deep neural network encoders with differentiable rendering have opened up the path for very fast monocular reconstruction of geometry, lighting and reflectance. They can also be trained in self-supervised manner for increased robustness and better generalization. However, their differentiable rasterization based image formation models, as well as underlying scene parameterization, limit them to Lambertian face reflectance and to poor shape details. More recently, ray tracing was introduced for monocular face reconstruction within a classic optimization-based framework and enables state-of-the art results. However optimization-based approaches are inherently slow and lack robustness. In this paper, we build our work on the aforementioned approaches and propose a new method that greatly improves reconstruction quality and robustness in general scenes. We achieve this by combining a CNN encoder with a differentiable ray tracer, which enables us to base the reconstruction on much more advanced personalized diffuse and specular albedos, a more sophisticated illumination model and a plausible representation of self-shadows. This enables to take a big leap forward in reconstruction quality of shape, appearance and lighting even in scenes with difficult illumination. With consistent face attributes reconstruction, our method leads to practical applications such as relighting and self-shadows removal. Compared to state-of-the-art methods, our results show improved accuracy and validity of the approach.
PhotoApp: Photorealistic Appearance Editing of Head Portraits
Mar 13, 2021
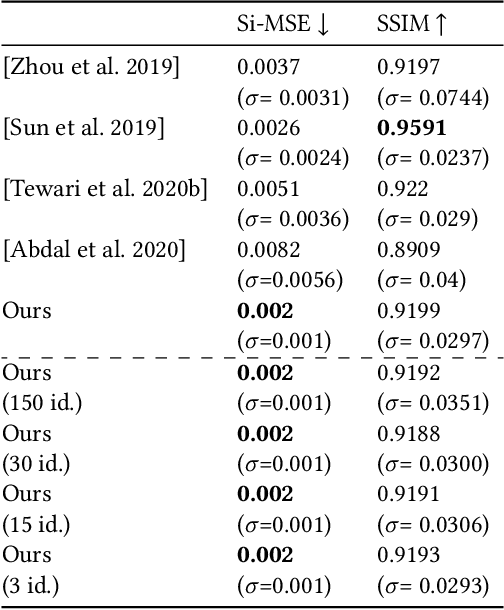
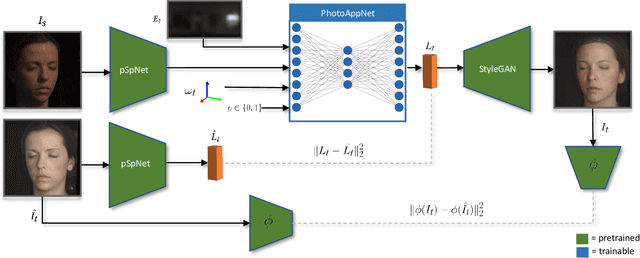
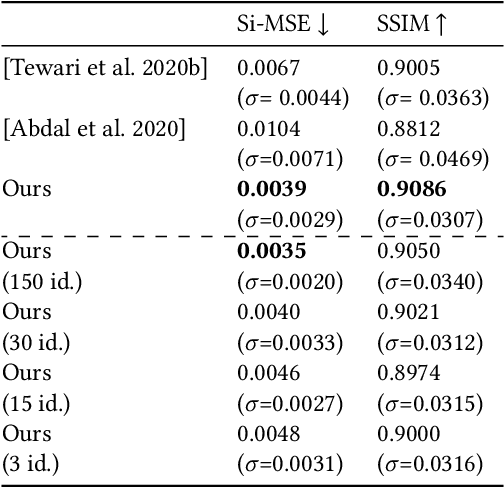
Photorealistic editing of portraits is a challenging task as humans are very sensitive to inconsistencies in faces. We present an approach for high-quality intuitive editing of the camera viewpoint and scene illumination in a portrait image. This requires our method to capture and control the full reflectance field of the person in the image. Most editing approaches rely on supervised learning using training data captured with setups such as light and camera stages. Such datasets are expensive to acquire, not readily available and do not capture all the rich variations of in-the-wild portrait images. In addition, most supervised approaches only focus on relighting, and do not allow camera viewpoint editing. Thus, they only capture and control a subset of the reflectance field. Recently, portrait editing has been demonstrated by operating in the generative model space of StyleGAN. While such approaches do not require direct supervision, there is a significant loss of quality when compared to the supervised approaches. In this paper, we present a method which learns from limited supervised training data. The training images only include people in a fixed neutral expression with eyes closed, without much hair or background variations. Each person is captured under 150 one-light-at-a-time conditions and under 8 camera poses. Instead of training directly in the image space, we design a supervised problem which learns transformations in the latent space of StyleGAN. This combines the best of supervised learning and generative adversarial modeling. We show that the StyleGAN prior allows for generalisation to different expressions, hairstyles and backgrounds. This produces high-quality photorealistic results for in-the-wild images and significantly outperforms existing methods. Our approach can edit the illumination and pose simultaneously, and runs at interactive rates.
HumanGAN: A Generative Model of Humans Images
Mar 11, 2021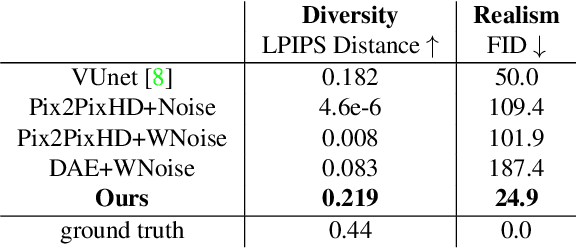


Generative adversarial networks achieve great performance in photorealistic image synthesis in various domains, including human images. However, they usually employ latent vectors that encode the sampled outputs globally. This does not allow convenient control of semantically-relevant individual parts of the image, and is not able to draw samples that only differ in partial aspects, such as clothing style. We address these limitations and present a generative model for images of dressed humans offering control over pose, local body part appearance and garment style. This is the first method to solve various aspects of human image generation such as global appearance sampling, pose transfer, parts and garment transfer, and parts sampling jointly in a unified framework. As our model encodes part-based latent appearance vectors in a normalized pose-independent space and warps them to different poses, it preserves body and clothing appearance under varying posture. Experiments show that our flexible and general generative method outperforms task-specific baselines for pose-conditioned image generation, pose transfer and part sampling in terms of realism and output resolution.
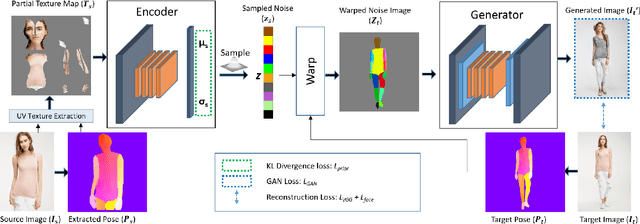
Style and Pose Control for Image Synthesis of Humans from a Single Monocular View
Feb 22, 2021
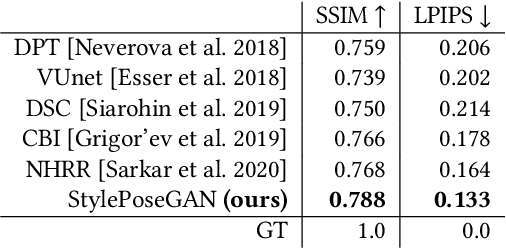


Photo-realistic re-rendering of a human from a single image with explicit control over body pose, shape and appearance enables a wide range of applications, such as human appearance transfer, virtual try-on, motion imitation, and novel view synthesis. While significant progress has been made in this direction using learning-based image generation tools, such as GANs, existing approaches yield noticeable artefacts such as blurring of fine details, unrealistic distortions of the body parts and garments as well as severe changes of the textures. We, therefore, propose a new method for synthesising photo-realistic human images with explicit control over pose and part-based appearance, i.e., StylePoseGAN, where we extend a non-controllable generator to accept conditioning of pose and appearance separately. Our network can be trained in a fully supervised way with human images to disentangle pose, appearance and body parts, and it significantly outperforms existing single image re-rendering methods. Our disentangled representation opens up further applications such as garment transfer, motion transfer, virtual try-on, head (identity) swap and appearance interpolation. StylePoseGAN achieves state-of-the-art image generation fidelity on common perceptual metrics compared to the current best-performing methods and convinces in a comprehensive user study.
Learning Speech-driven 3D Conversational Gestures from Video
Feb 13, 2021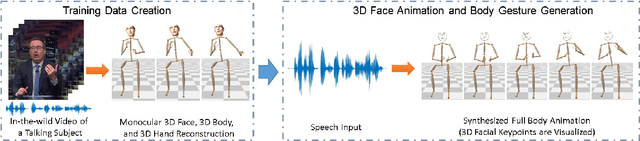
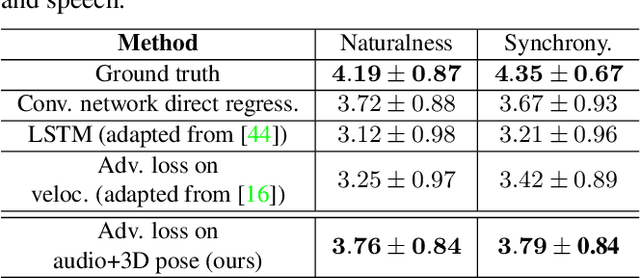
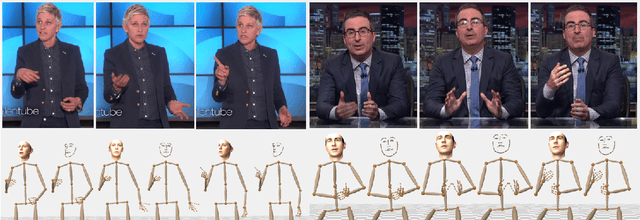
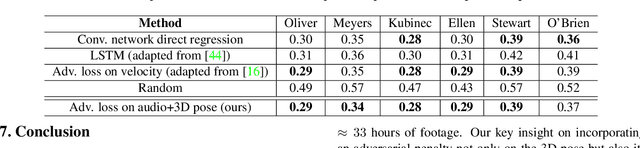
We propose the first approach to automatically and jointly synthesize both the synchronous 3D conversational body and hand gestures, as well as 3D face and head animations, of a virtual character from speech input. Our algorithm uses a CNN architecture that leverages the inherent correlation between facial expression and hand gestures. Synthesis of conversational body gestures is a multi-modal problem since many similar gestures can plausibly accompany the same input speech. To synthesize plausible body gestures in this setting, we train a Generative Adversarial Network (GAN) based model that measures the plausibility of the generated sequences of 3D body motion when paired with the input audio features. We also contribute a new way to create a large corpus of more than 33 hours of annotated body, hand, and face data from in-the-wild videos of talking people. To this end, we apply state-of-the-art monocular approaches for 3D body and hand pose estimation as well as dense 3D face performance capture to the video corpus. In this way, we can train on orders of magnitude more data than previous algorithms that resort to complex in-studio motion capture solutions, and thereby train more expressive synthesis algorithms. Our experiments and user study show the state-of-the-art quality of our speech-synthesized full 3D character animations.
Quantum Permutation Synchronization
Jan 19, 2021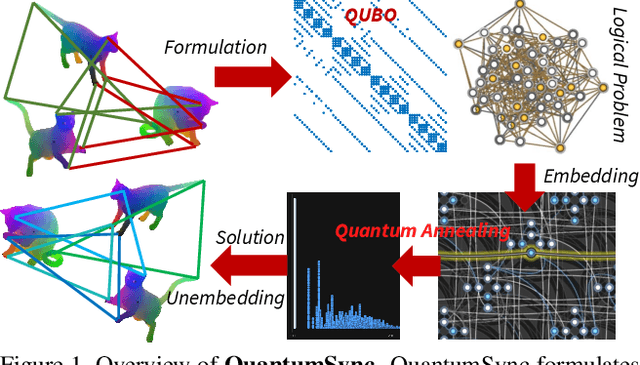
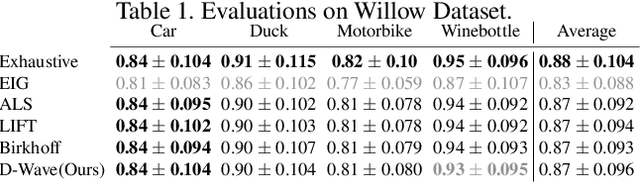

We present QuantumSync, the first quantum algorithm for solving a synchronization problem in the context of computer vision. In particular, we focus on permutation synchronization which involves solving a non-convex optimization problem in discrete variables. We start by formulating synchronization into a quadratic unconstrained binary optimization problem (QUBO). While such formulation respects the binary nature of the problem, ensuring that the result is a set of permutations requires extra care. Hence, we: (i) show how to insert permutation constraints into a QUBO problem and (ii) solve the constrained QUBO problem on the current generation of the adiabatic quantum computers D-Wave. Thanks to the quantum annealing, we guarantee global optimality with high probability while sampling the energy landscape to yield confidence estimates. Our proof-of-concepts realization on the adiabatic D-Wave computer demonstrates that quantum machines offer a promising way to solve the prevalent yet difficult synchronization problems.
Neural Re-Rendering of Humans from a Single Image
Jan 11, 2021
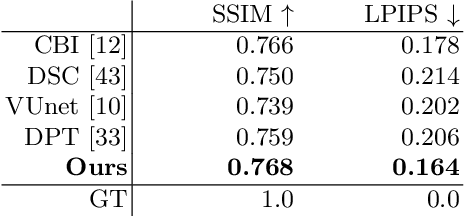
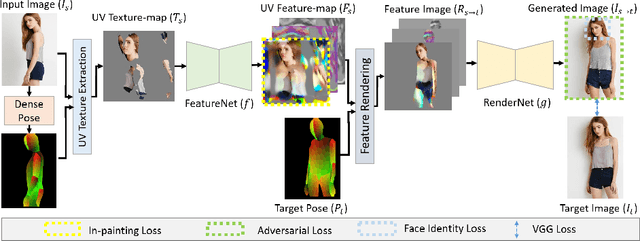

Human re-rendering from a single image is a starkly under-constrained problem, and state-of-the-art algorithms often exhibit undesired artefacts, such as over-smoothing, unrealistic distortions of the body parts and garments, or implausible changes of the texture. To address these challenges, we propose a new method for neural re-rendering of a human under a novel user-defined pose and viewpoint, given one input image. Our algorithm represents body pose and shape as a parametric mesh which can be reconstructed from a single image and easily reposed. Instead of a colour-based UV texture map, our approach further employs a learned high-dimensional UV feature map to encode appearance. This rich implicit representation captures detailed appearance variation across poses, viewpoints, person identities and clothing styles better than learned colour texture maps. The body model with the rendered feature maps is fed through a neural image-translation network that creates the final rendered colour image. The above components are combined in an end-to-end-trained neural network architecture that takes as input a source person image, and images of the parametric body model in the source pose and desired target pose. Experimental evaluation demonstrates that our approach produces higher quality single image re-rendering results than existing methods.