 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Shading-Guided Generative Implicit Model for Shape-Accurate 3D-Aware Image Synthesis
Nov 01, 2021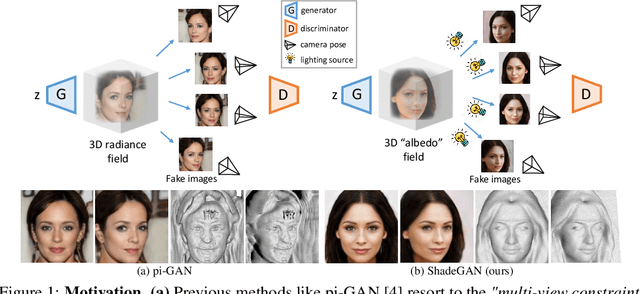
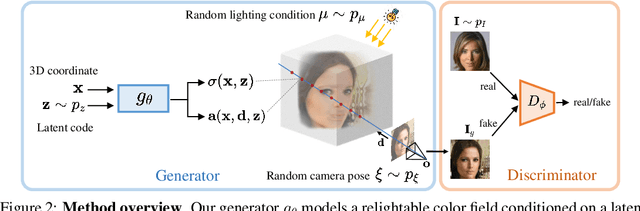
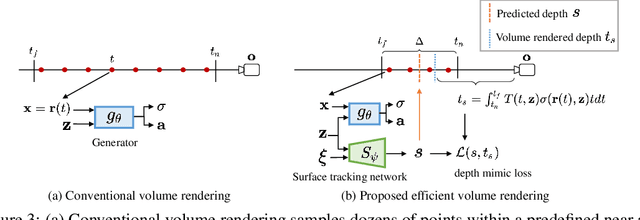

The advancement of generative radiance fields has pushed the boundary of 3D-aware image synthesis. Motivated by the observation that a 3D object should look realistic from multiple viewpoints, these methods introduce a multi-view constraint as regularization to learn valid 3D radiance fields from 2D images. Despite the progress, they often fall short of capturing accurate 3D shapes due to the shape-color ambiguity, limiting their applicability in downstream tasks. In this work, we address this ambiguity by proposing a novel shading-guided generative implicit model that is able to learn a starkly improved shape representation. Our key insight is that an accurate 3D shape should also yield a realistic rendering under different lighting conditions. This multi-lighting constraint is realized by modeling illumination explicitly and performing shading with various lighting conditions. Gradients are derived by feeding the synthesized images to a discriminator. To compensate for the additional computational burden of calculating surface normals, we further devise an efficient volume rendering strategy via surface tracking, reducing the training and inference time by 24% and 48%, respectively. Our experiments on multiple datasets show that the proposed approach achieves photorealistic 3D-aware image synthesis while capturing accurate underlying 3D shapes. We demonstrate improved performance of our approach on 3D shape reconstruction against existing methods, and show its applicability on image relighting. Our code will be released at https://github.com/XingangPan/ShadeGAN.
StyleNeRF: A Style-based 3D-Aware Generator for High-resolution Image Synthesis
Oct 18, 2021


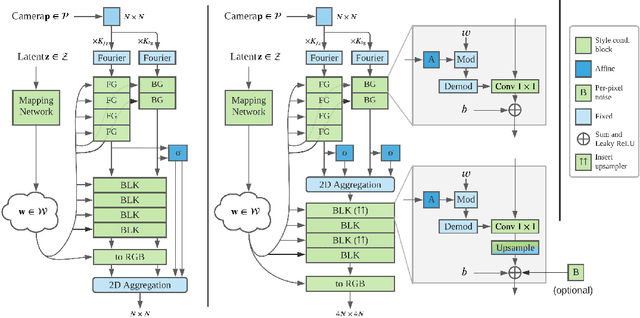
We propose StyleNeRF, a 3D-aware generative model for photo-realistic high-resolution image synthesis with high multi-view consistency, which can be trained on unstructured 2D images. Existing approaches either cannot synthesize high-resolution images with fine details or yield noticeable 3D-inconsistent artifacts. In addition, many of them lack control over style attributes and explicit 3D camera poses. StyleNeRF integrates the neural radiance field (NeRF) into a style-based generator to tackle the aforementioned challenges, i.e., improving rendering efficiency and 3D consistency for high-resolution image generation. We perform volume rendering only to produce a low-resolution feature map and progressively apply upsampling in 2D to address the first issue. To mitigate the inconsistencies caused by 2D upsampling, we propose multiple designs, including a better upsampler and a new regularization loss. With these designs, StyleNeRF can synthesize high-resolution images at interactive rates while preserving 3D consistency at high quality. StyleNeRF also enables control of camera poses and different levels of styles, which can generalize to unseen views. It also supports challenging tasks, including zoom-in and-out, style mixing, inversion, and semantic editing.
Gravity-Aware Monocular 3D Human-Object Reconstruction
Aug 19, 2021

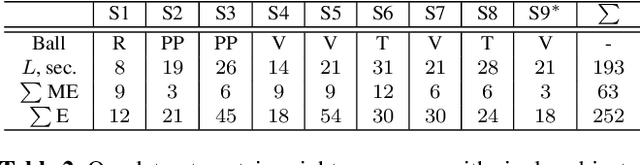
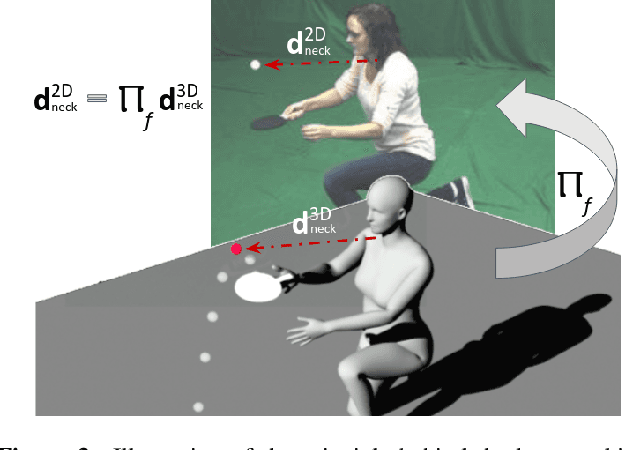
This paper proposes GraviCap, i.e., a new approach for joint markerless 3D human motion capture and object trajectory estimation from monocular RGB videos. We focus on scenes with objects partially observed during a free flight. In contrast to existing monocular methods, we can recover scale, object trajectories as well as human bone lengths in meters and the ground plane's orientation, thanks to the awareness of the gravity constraining object motions. Our objective function is parametrised by the object's initial velocity and position, gravity direction and focal length, and jointly optimised for one or several free flight episodes. The proposed human-object interaction constraints ensure geometric consistency of the 3D reconstructions and improved physical plausibility of human poses compared to the unconstrained case. We evaluate GraviCap on a new dataset with ground-truth annotations for persons and different objects undergoing free flights. In the experiments, our approach achieves state-of-the-art accuracy in 3D human motion capture on various metrics. We urge the reader to watch our supplementary video. Both the source code and the dataset are released; see http://4dqv.mpi-inf.mpg.de/GraviCap/.
* 12 pages, six figures, five tables; project webpage: http://4dqv.mpi-inf.mpg.de/GraviCap/
Neural Rays for Occlusion-aware Image-based Rendering
Jul 28, 2021
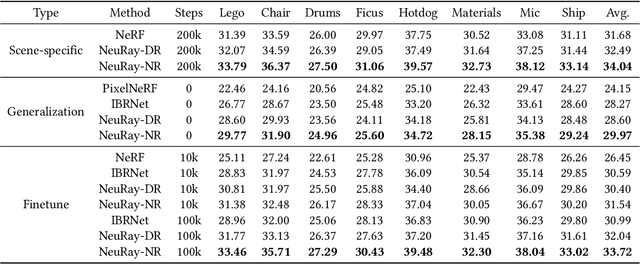
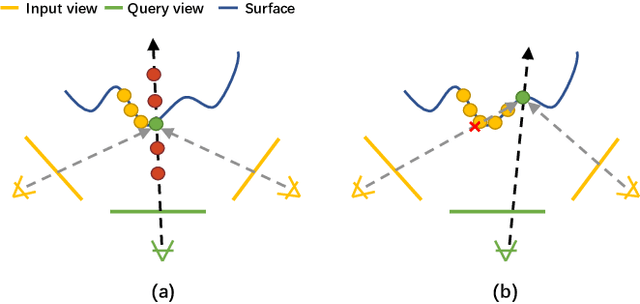
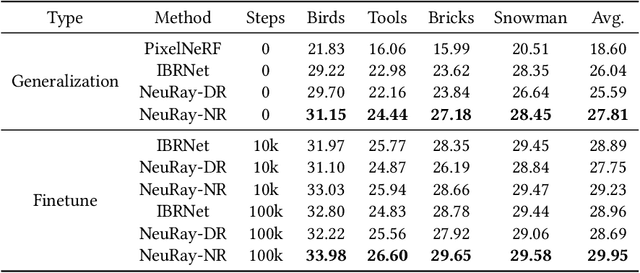
We present a new neural representation, called Neural Ray (NeuRay), for the novel view synthesis (NVS) task with multi-view images as input. Existing neural scene representations for solving the NVS problem, such as NeRF, cannot generalize to new scenes and take an excessively long time on training on each new scene from scratch. The other subsequent neural rendering methods based on stereo matching, such as PixelNeRF, SRF and IBRNet are designed to generalize to unseen scenes but suffer from view inconsistency in complex scenes with self-occlusions. To address these issues, our NeuRay method represents every scene by encoding the visibility of rays associated with the input views. This neural representation can efficiently be initialized from depths estimated by external MVS methods, which is able to generalize to new scenes and achieves satisfactory rendering images without any training on the scene. Then, the initialized NeuRay can be further optimized on every scene with little training timing to enforce spatial coherence to ensure view consistency in the presence of severe self-occlusion. Experiments demonstrate that NeuRay can quickly generate high-quality novel view images of unseen scenes with little finetuning and can handle complex scenes with severe self-occlusions which previous methods struggle with.
StyleVideoGAN: A Temporal Generative Model using a Pretrained StyleGAN
Jul 15, 2021

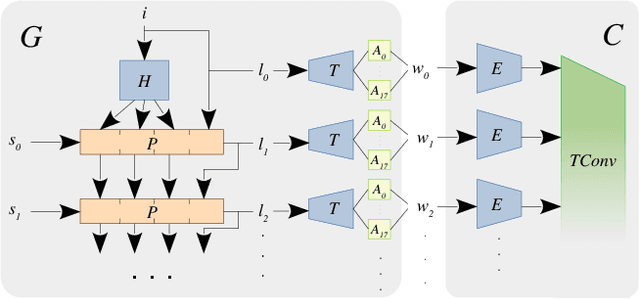
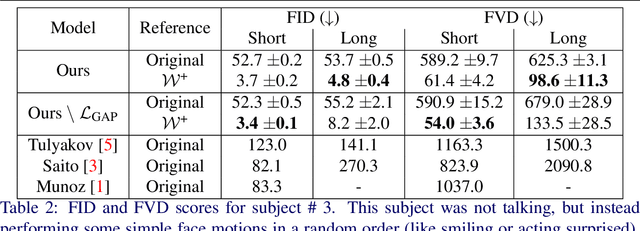
Generative adversarial models (GANs) continue to produce advances in terms of the visual quality of still images, as well as the learning of temporal correlations. However, few works manage to combine these two interesting capabilities for the synthesis of video content: Most methods require an extensive training dataset in order to learn temporal correlations, while being rather limited in the resolution and visual quality of their output frames. In this paper, we present a novel approach to the video synthesis problem that helps to greatly improve visual quality and drastically reduce the amount of training data and resources necessary for generating video content. Our formulation separates the spatial domain, in which individual frames are synthesized, from the temporal domain, in which motion is generated. For the spatial domain we make use of a pre-trained StyleGAN network, the latent space of which allows control over the appearance of the objects it was trained for. The expressive power of this model allows us to embed our training videos in the StyleGAN latent space. Our temporal architecture is then trained not on sequences of RGB frames, but on sequences of StyleGAN latent codes. The advantageous properties of the StyleGAN space simplify the discovery of temporal correlations. We demonstrate that it suffices to train our temporal architecture on only 10 minutes of footage of 1 subject for about 6 hours. After training, our model can not only generate new portrait videos for the training subject, but also for any random subject which can be embedded in the StyleGAN space.
NRST: Non-rigid Surface Tracking from Monocular Video
Jul 12, 2021

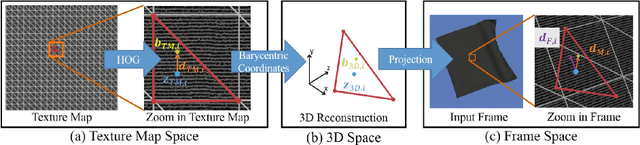

We propose an efficient method for non-rigid surface tracking from monocular RGB videos. Given a video and a template mesh, our algorithm sequentially registers the template non-rigidly to each frame. We formulate the per-frame registration as an optimization problem that includes a novel texture term specifically tailored towards tracking objects with uniform texture but fine-scale structure, such as the regular micro-structural patterns of fabric. Our texture term exploits the orientation information in the micro-structures of the objects, e.g., the yarn patterns of fabrics. This enables us to accurately track uniformly colored materials that have these high frequency micro-structures, for which traditional photometric terms are usually less effective. The results demonstrate the effectiveness of our method on both general textured non-rigid objects and monochromatic fabrics.
Adiabatic Quantum Graph Matching with Permutation Matrix Constraints
Jul 08, 2021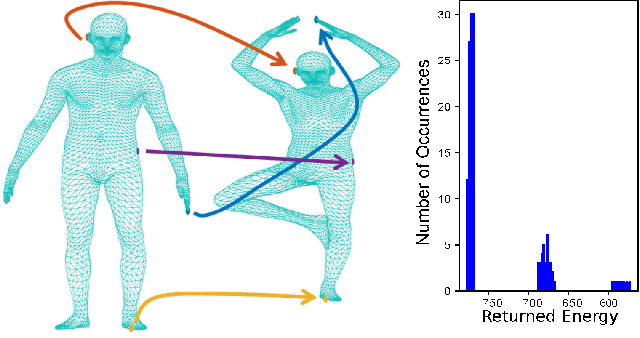
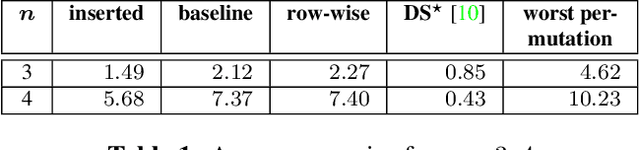
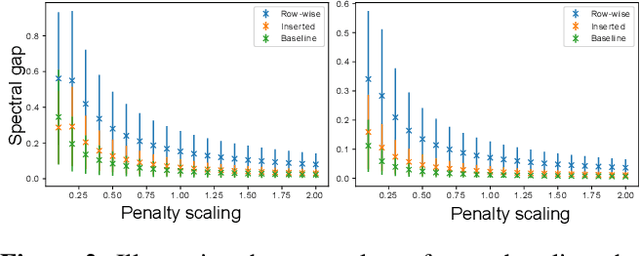
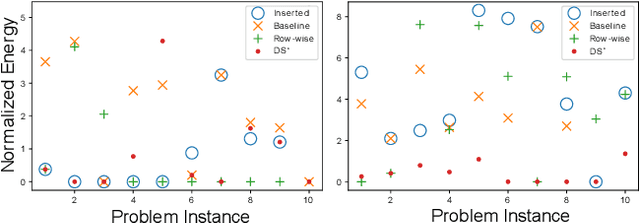
Matching problems on 3D shapes and images are challenging as they are frequently formulated as combinatorial quadratic assignment problems (QAPs) with permutation matrix constraints, which are NP-hard. In this work, we address such problems with emerging quantum computing technology and propose several reformulations of QAPs as unconstrained problems suitable for efficient execution on quantum hardware. We investigate several ways to inject permutation matrix constraints in a quadratic unconstrained binary optimization problem which can be mapped to quantum hardware. We focus on obtaining a sufficient spectral gap, which further increases the probability to measure optimal solutions and valid permutation matrices in a single run. We perform our experiments on the quantum computer D-Wave 2000Q (2^11 qubits, adiabatic). Despite the observed discrepancy between simulated adiabatic quantum computing and execution on real quantum hardware, our reformulation of permutation matrix constraints increases the robustness of the numerical computations over other penalty approaches in our experiments. The proposed algorithm has the potential to scale to higher dimensions on future quantum computing architectures, which opens up multiple new directions for solving matching problems in 3D computer vision and graphics.
* 18 pages, 14 figures, 2 tables; project webpage: http://gvv.mpi-inf.mpg.de/projects/QGM/
Egocentric Videoconferencing
Jul 07, 2021

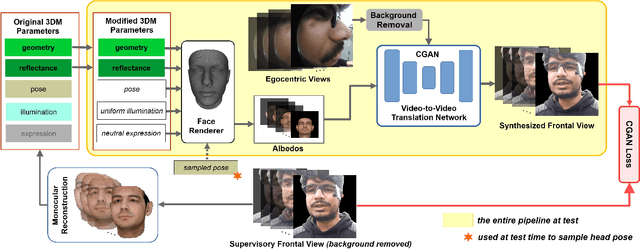

We introduce a method for egocentric videoconferencing that enables hands-free video calls, for instance by people wearing smart glasses or other mixed-reality devices. Videoconferencing portrays valuable non-verbal communication and face expression cues, but usually requires a front-facing camera. Using a frontal camera in a hands-free setting when a person is on the move is impractical. Even holding a mobile phone camera in the front of the face while sitting for a long duration is not convenient. To overcome these issues, we propose a low-cost wearable egocentric camera setup that can be integrated into smart glasses. Our goal is to mimic a classical video call, and therefore, we transform the egocentric perspective of this camera into a front facing video. To this end, we employ a conditional generative adversarial neural network that learns a transition from the highly distorted egocentric views to frontal views common in videoconferencing. Our approach learns to transfer expression details directly from the egocentric view without using a complex intermediate parametric expressions model, as it is used by related face reenactment methods. We successfully handle subtle expressions, not easily captured by parametric blendshape-based solutions, e.g., tongue movement, eye movements, eye blinking, strong expressions and depth varying movements. To get control over the rigid head movements in the target view, we condition the generator on synthetic renderings of a moving neutral face. This allows us to synthesis results at different head poses. Our technique produces temporally smooth video-realistic renderings in real-time using a video-to-video translation network in conjunction with a temporal discriminator. We demonstrate the improved capabilities of our technique by comparing against related state-of-the art approaches.
* Mohamed Elgharib and Mohit Mendiratta contributed equally to this work. http://gvv.mpi-inf.mpg.de/projects/EgoChat/
Self-supervised Outdoor Scene Relighting
Jul 07, 2021
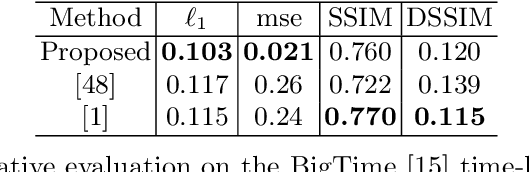
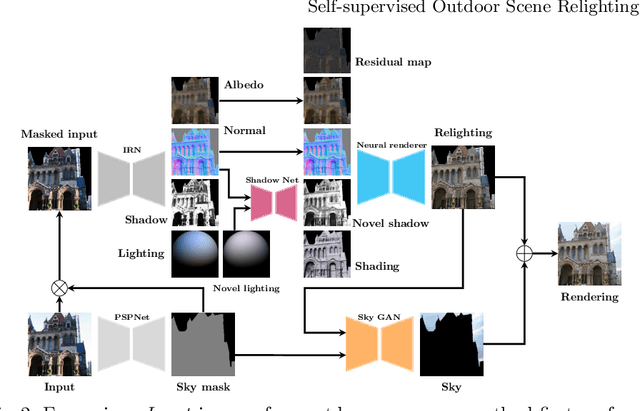
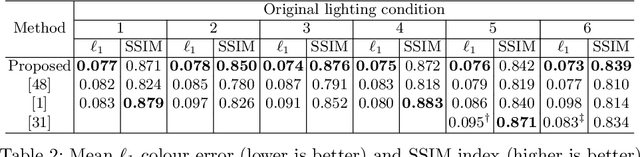
Outdoor scene relighting is a challenging problem that requires good understanding of the scene geometry, illumination and albedo. Current techniques are completely supervised, requiring high quality synthetic renderings to train a solution. Such renderings are synthesized using priors learned from limited data. In contrast, we propose a self-supervised approach for relighting. Our approach is trained only on corpora of images collected from the internet without any user-supervision. This virtually endless source of training data allows training a general relighting solution. Our approach first decomposes an image into its albedo, geometry and illumination. A novel relighting is then produced by modifying the illumination parameters. Our solution capture shadow using a dedicated shadow prediction map, and does not rely on accurate geometry estimation. We evaluate our technique subjectively and objectively using a new dataset with ground-truth relighting. Results show the ability of our technique to produce photo-realistic and physically plausible results, that generalizes to unseen scenes.
HandVoxNet++: 3D Hand Shape and Pose Estimation using Voxel-Based Neural Networks
Jul 02, 2021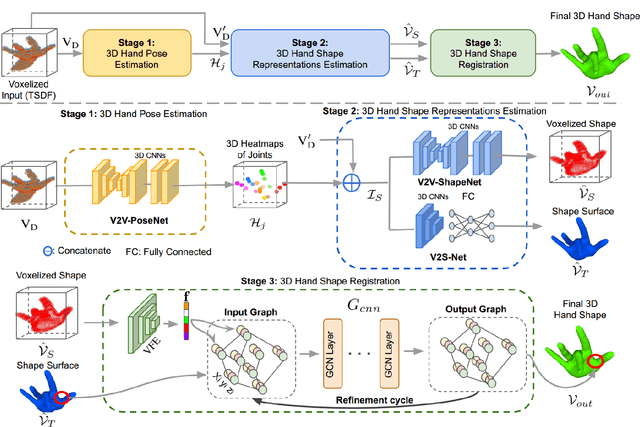
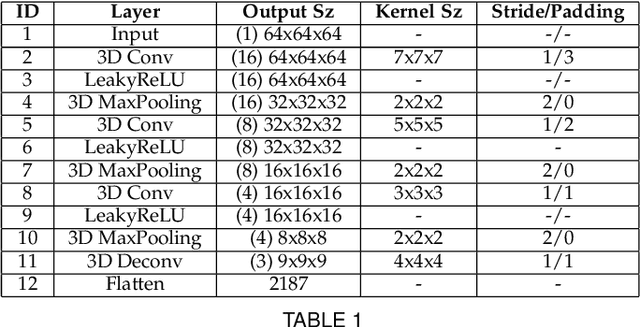

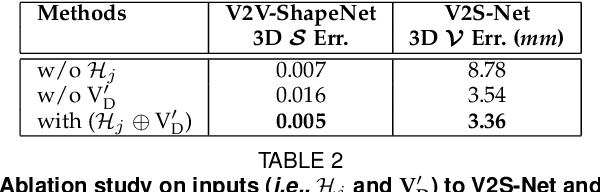
3D hand shape and pose estimation from a single depth map is a new and challenging computer vision problem with many applications. Existing methods addressing it directly regress hand meshes via 2D convolutional neural networks, which leads to artifacts due to perspective distortions in the images. To address the limitations of the existing methods, we develop HandVoxNet++, i.e., a voxel-based deep network with 3D and graph convolutions trained in a fully supervised manner. The input to our network is a 3D voxelized-depth-map-based on the truncated signed distance function (TSDF). HandVoxNet++ relies on two hand shape representations. The first one is the 3D voxelized grid of hand shape, which does not preserve the mesh topology and which is the most accurate representation. The second representation is the hand surface that preserves the mesh topology. We combine the advantages of both representations by aligning the hand surface to the voxelized hand shape either with a new neural Graph-Convolutions-based Mesh Registration (GCN-MeshReg) or classical segment-wise Non-Rigid Gravitational Approach (NRGA++) which does not rely on training data. In extensive evaluations on three public benchmarks, i.e., SynHand5M, depth-based HANDS19 challenge and HO-3D, the proposed HandVoxNet++ achieves the state-of-the-art performance. In this journal extension of our previous approach presented at CVPR 2020, we gain 41.09% and 13.7% higher shape alignment accuracy on SynHand5M and HANDS19 datasets, respectively. Our method is ranked first on the HANDS19 challenge dataset (Task 1: Depth-Based 3D Hand Pose Estimation) at the moment of the submission of our results to the portal in August 2020.