 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2Z-10M+: Geometric Deep Learning with A-to-Z BRep Annotations for AI-Assisted CAD Modeling and Reverse Engineering
Mar 13, 2026Reverse engineering and rapid prototyping of computer-aided design (CAD) models from 3D scans, sketches, or simple text prompts are vital in industrial product design. However, recent advances in geometric deep learning techniques lack a multi-modal understanding of parametric CAD features stored in their boundary representation (BRep). This study presents the largest compilation of 10 million multi-modal annotations and metadata for 1 million ABC CAD models, namely A2Z, to unlock an unprecedented level of BRep learning. A2Z comprises (i) high-resolution meshes with salient 3D scanning features, (ii) 3D hand-drawn sketches equipped with (iii) geometric and topological information about BRep co-edges, corners, and surfaces, and (iv) textual captions and tags describing the product in the mechanical world. Creating such carefully structured, large-scale data, which requires nearly 5 terabytes of storage to leverage unparalleled CAD learning/retrieval tasks, is very challenging. The scale, quality, and diversity of our multi-modal annotations are assessed using novel metrics, GPT-5, Gemini, and extensive human feedback mechanisms. To this end, we also merge an additional 25,000 CAD models of electronic enclosures (e.g., tablets, ports) designed by skilled professionals with our A2Z dataset. Subsequently, we train and benchmark a foundation model on a subset of 150K CAD models to detect BRep co-edges and corner vertices from 3D scans, a key downstream task in CAD reverse engineering. The annotated dataset, metrics, and checkpoints will be publicly released to support numerous research directions.
MARVEL-40M+: Multi-Level Visual Elaboration for High-Fidelity Text-to-3D Content Creation
Nov 26, 2024Generating high-fidelity 3D content from text prompts remains a significant challenge in computer vision due to the limited size, diversity, and annotation depth of the existing datasets. To address this, we introduce MARVEL-40M+, an extensive dataset with 40 million text annotations for over 8.9 million 3D assets aggregated from seven major 3D datasets. Our contribution is a novel multi-stage annotation pipeline that integrates open-source pretrained multi-view VLMs and LLMs to automatically produce multi-level descriptions, ranging from detailed (150-200 words) to concise semantic tags (10-20 words). This structure supports both fine-grained 3D reconstruction and rapid prototyping. Furthermore, we incorporate human metadata from source datasets into our annotation pipeline to add domain-specific information in our annotation and reduce VLM hallucinations. Additionally, we develop MARVEL-FX3D, a two-stage text-to-3D pipeline. We fine-tune Stable Diffusion with our annotations and use a pretrained image-to-3D network to generate 3D textured meshes within 15s. Extensive evaluations show that MARVEL-40M+ significantly outperforms existing datasets in annotation quality and linguistic diversity, achieving win rates of 72.41% by GPT-4 and 73.40% by human evaluators.
Text2CAD: Generating Sequential CAD Models from Beginner-to-Expert Level Text Prompts
Sep 25, 2024



Prototyping complex computer-aided design (CAD) models in modern softwares can be very time-consuming. This is due to the lack of intelligent systems that can quickly generate simpler intermediate parts. We propose Text2CAD, the first AI framework for generating text-to-parametric CAD models using designer-friendly instructions for all skill levels. Furthermore, we introduce a data annotation pipeline for generating text prompts based on natural language instructions for the DeepCAD dataset using Mistral and LLaVA-NeXT. The dataset contains $\sim170$K models and $\sim660$K text annotations, from abstract CAD descriptions (e.g., generate two concentric cylinders) to detailed specifications (e.g., draw two circles with center $(x,y)$ and radius $r_{1}$, $r_{2}$, and extrude along the normal by $d$...). Within the Text2CAD framework, we propose an end-to-end transformer-based auto-regressive network to generate parametric CAD models from input texts. We evaluate the performance of our model through a mixture of metrics, including visual quality, parametric precision, and geometrical accuracy. Our proposed framework shows great potential in AI-aided design applications. Our source code and annotations will be publicly available.
BRep Boundary and Junction Detection for CAD Reverse Engineering
Sep 21, 2024



In machining process, 3D reverse engineering of the mechanical system is an integral, highly important, and yet time consuming step to obtain parametric CAD models from 3D scans. Therefore, deep learning-based Scan-to-CAD modeling can offer designers enormous editability to quickly modify CAD model, being able to parse all its structural compositions and design steps. In this paper, we propose a supervised boundary representation (BRep) detection network BRepDetNet from 3D scans of CC3D and ABC dataset. We have carefully annotated the 50K and 45K scans of both the datasets with appropriate topological relations (e.g., next, mate, previous) between the geometrical primitives (i.e., boundaries, junctions, loops, faces) of their BRep data structures. The proposed solution decomposes the Scan-to-CAD problem in Scan-to-BRep ensuring the right step towards feature-based modeling, and therefore, leveraging other existing BRep-to-CAD modeling methods. Our proposed Scan-to-BRep neural network learns to detect BRep boundaries and junctions by minimizing focal-loss and non-maximal suppression (NMS) during training time. Experimental results show that our BRepDetNet with NMS-Loss achieves impressive results.
CAD-SIGNet: CAD Language Inference from Point Clouds using Layer-wise Sketch Instance Guided Attention
Feb 27, 2024Reverse engineering in the realm of Computer-Aided Design (CAD) has been a longstanding aspiration, though not yet entirely realized. Its primary aim is to uncover the CAD process behind a physical object given its 3D scan. We propose CAD-SIGNet, an end-to-end trainable and auto-regressive architecture to recover the design history of a CAD model represented as a sequence of sketch-and-extrusion from an input point cloud. Our model learns visual-language representations by layer-wise cross-attention between point cloud and CAD language embedding. In particular, a new Sketch instance Guided Attention (SGA) module is proposed in order to reconstruct the fine-grained details of the sketches. Thanks to its auto-regressive nature, CAD-SIGNet not only reconstructs a unique full design history of the corresponding CAD model given an input point cloud but also provides multiple plausible design choices. This allows for an interactive reverse engineering scenario by providing designers with multiple next-step choices along with the design process. Extensive experiments on publicly available CAD datasets showcase the effectiveness of our approach against existing baseline models in two settings, namely, full design history recovery and conditional auto-completion from point clouds.
SHARP Challenge 2023: Solving CAD History and pArameters Recovery from Point clouds and 3D scans. Overview, Datasets, Metrics, and Baselines
Aug 30, 2023



Recent breakthroughs in geometric Deep Learning (DL) and the availability of large Computer-Aided Design (CAD) datasets have advanced the research on learning CAD modeling processes and relating them to real objects. In this context, 3D reverse engineering of CAD models from 3D scans is considered to be one of the most sought-after goals for the CAD industry. However, recent efforts assume multiple simplifications limiting the applications in real-world settings. The SHARP Challenge 2023 aims at pushing the research a step closer to the real-world scenario of CAD reverse engineering through dedicated datasets and tracks. In this paper, we define the proposed SHARP 2023 tracks, describe the provided datasets, and propose a set of baseline methods along with suitable evaluation metrics to assess the performance of the track solutions. All proposed datasets along with useful routines and the evaluation metrics are publicly available.
DELO: Deep Evidential LiDAR Odometry using Partial Optimal Transport
Aug 14, 2023



Accurate, robust, and real-time LiDAR-based odometry (LO) is imperative for many applications like robot navigation, globally consistent 3D scene map reconstruction, or safe motion-planning. Though LiDAR sensor is known for its precise range measurement, the non-uniform and uncertain point sampling density induce structural inconsistencies. Hence, existing supervised and unsupervised point set registration methods fail to establish one-to-one matching correspondences between LiDAR frames. We introduce a novel deep learning-based real-time (approx. 35-40ms per frame) LO method that jointly learns accurate frame-to-frame correspondences and model's predictive uncertainty (PU) as evidence to safe-guard LO predictions. In this work, we propose (i) partial optimal transportation of LiDAR feature descriptor for robust LO estimation, (ii) joint learning of predictive uncertainty while learning odometry over driving sequences, and (iii) demonstrate how PU can serve as evidence for necessary pose-graph optimization when LO network is either under or over confident. We evaluate our method on KITTI dataset and show competitive performance, even superior generalization ability over recent state-of-the-art approaches. Source codes are available.
CADOps-Net: Jointly Learning CAD Operation Types and Steps from Boundary-Representations
Aug 22, 2022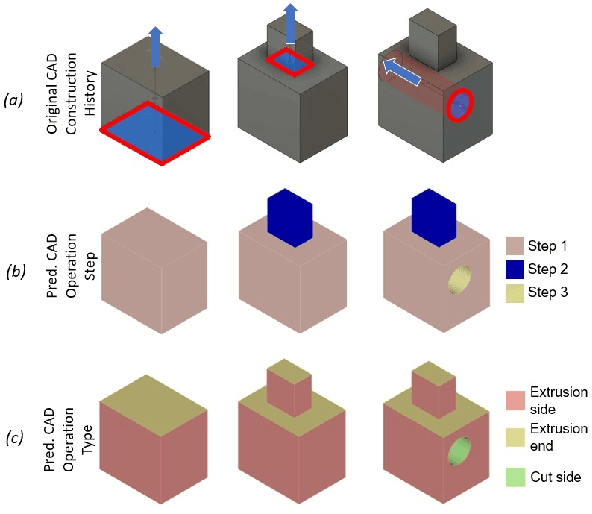


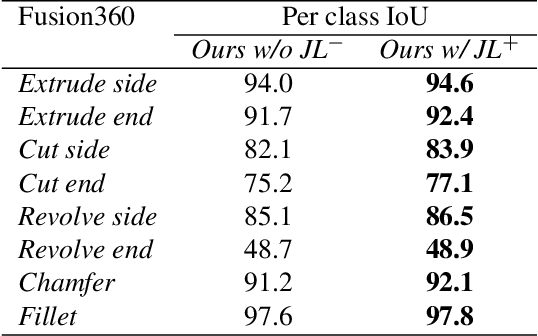
3D reverse engineering is a long sought-after, yet not completely achieved goal in the Computer-Aided Design (CAD) industry. The objective is to recover the construction history of a CAD model. Starting from a Boundary Representation (B-Rep) of a CAD model, this paper proposes a new deep neural network, CADOps-Net, that jointly learns the CAD operation types and the decomposition into different CAD operation steps. This joint learning allows to divide a B-Rep into parts that were created by various types of CAD operations at the same construction step; therefore providing relevant information for further recovery of the design history. Furthermore, we propose the novel CC3D-Ops dataset that includes over $37k$ CAD models annotated with CAD operation type labels and step labels. Compared to existing datasets, the complexity and variety of CC3D-Ops models are closer to those used for industrial purposes. Our experiments, conducted on the proposed CC3D-Ops and the publicly available Fusion360 datasets, demonstrate the competitive performance of CADOps-Net with respect to state-of-the-art, and confirm the importance of the joint learning of CAD operation types and steps.
TSCom-Net: Coarse-to-Fine 3D Textured Shape Completion Network
Aug 22, 2022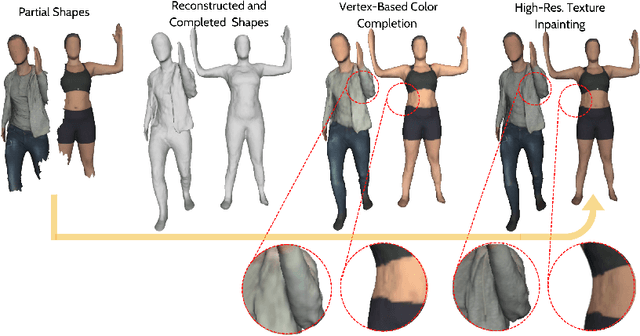
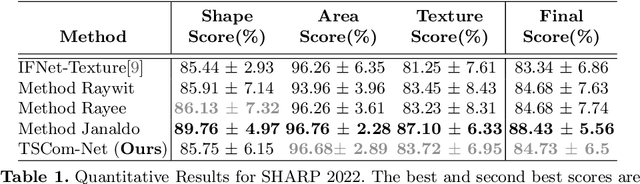
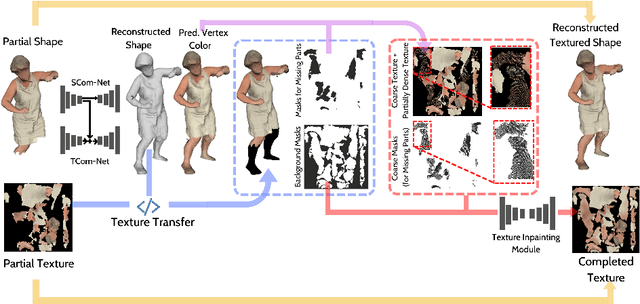

Reconstructing 3D human body shapes from 3D partial textured scans remains a fundamental task for many computer vision and graphics applications -- e.g., body animation, and virtual dressing. We propose a new neural network architecture for 3D body shape and high-resolution texture completion -- BCom-Net -- that can reconstruct the full geometry from mid-level to high-level partial input scans. We decompose the overall reconstruction task into two stages - first, a joint implicit learning network (SCom-Net and TCom-Net) that takes a voxelized scan and its occupancy grid as input to reconstruct the full body shape and predict vertex textures. Second, a high-resolution texture completion network, that utilizes the predicted coarse vertex textures to inpaint the missing parts of the partial 'texture atlas'. A thorough experimental evaluation on 3DBodyTex.V2 dataset shows that our method achieves competitive results with respect to the state-of-the-art while generalizing to different types and levels of partial shapes. The proposed method has also ranked second in the track1 of SHApe Recovery from Partial textured 3D scans (SHARP [38,1]) 2022 challenge1.
HandVoxNet++: 3D Hand Shape and Pose Estimation using Voxel-Based Neural Networks
Jul 02, 2021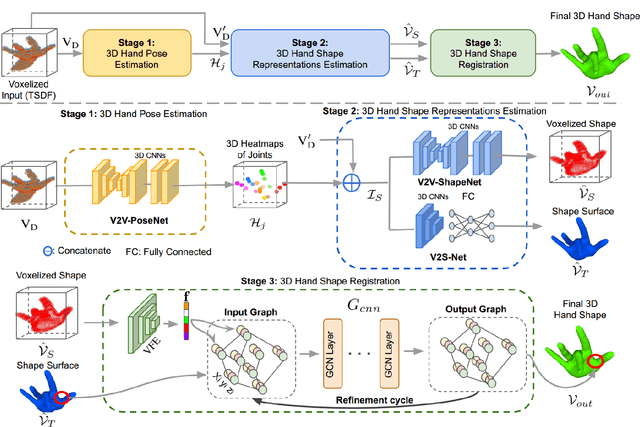
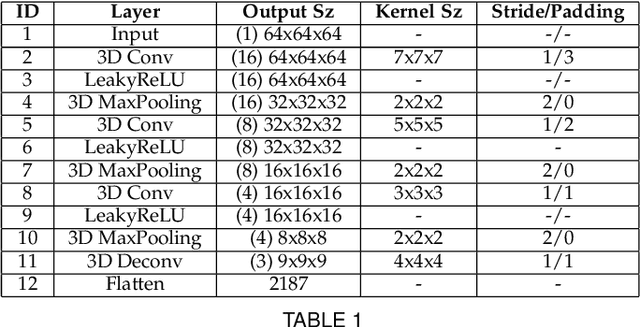

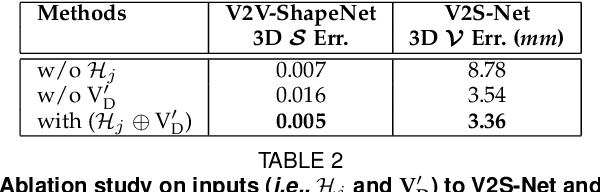
3D hand shape and pose estimation from a single depth map is a new and challenging computer vision problem with many applications. Existing methods addressing it directly regress hand meshes via 2D convolutional neural networks, which leads to artifacts due to perspective distortions in the images. To address the limitations of the existing methods, we develop HandVoxNet++, i.e., a voxel-based deep network with 3D and graph convolutions trained in a fully supervised manner. The input to our network is a 3D voxelized-depth-map-based on the truncated signed distance function (TSDF). HandVoxNet++ relies on two hand shape representations. The first one is the 3D voxelized grid of hand shape, which does not preserve the mesh topology and which is the most accurate representation. The second representation is the hand surface that preserves the mesh topology. We combine the advantages of both representations by aligning the hand surface to the voxelized hand shape either with a new neural Graph-Convolutions-based Mesh Registration (GCN-MeshReg) or classical segment-wise Non-Rigid Gravitational Approach (NRGA++) which does not rely on training data. In extensive evaluations on three public benchmarks, i.e., SynHand5M, depth-based HANDS19 challenge and HO-3D, the proposed HandVoxNet++ achieves the state-of-the-art performance. In this journal extension of our previous approach presented at CVPR 2020, we gain 41.09% and 13.7% higher shape alignment accuracy on SynHand5M and HANDS19 datasets, respectively. Our method is ranked first on the HANDS19 challenge dataset (Task 1: Depth-Based 3D Hand Pose Estimation) at the moment of the submission of our results to the portal in August 2020.