 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNerfDiff: Single-image View Synthesis with NeRF-guided Distillation from 3D-aware Diffusion
Feb 20, 2023
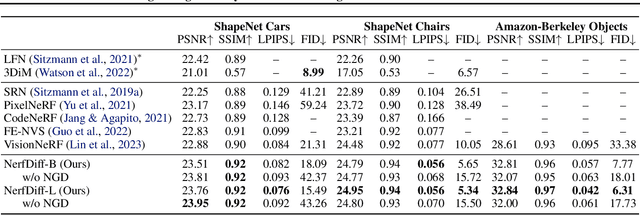
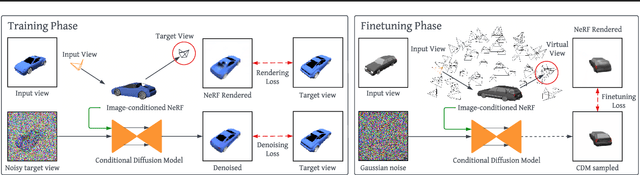
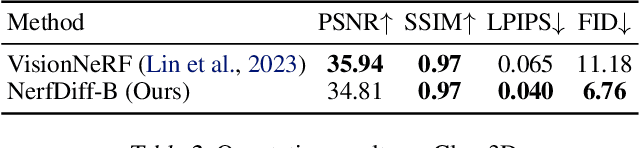
Novel view synthesis from a single image requires inferring occluded regions of objects and scenes whilst simultaneously maintaining semantic and physical consistency with the input. Existing approaches condition neural radiance fields (NeRF) on local image features, projecting points to the input image plane, and aggregating 2D features to perform volume rendering. However, under severe occlusion, this projection fails to resolve uncertainty, resulting in blurry renderings that lack details. In this work, we propose NerfDiff, which addresses this issue by distilling the knowledge of a 3D-aware conditional diffusion model (CDM) into NeRF through synthesizing and refining a set of virtual views at test time. We further propose a novel NeRF-guided distillation algorithm that simultaneously generates 3D consistent virtual views from the CDM samples, and finetunes the NeRF based on the improved virtual views. Our approach significantly outperforms existing NeRF-based and geometry-free approaches on challenging datasets, including ShapeNet, ABO, and Clevr3D.
Scene-Aware 3D Multi-Human Motion Capture from a Single Camera
Jan 12, 2023In this work, we consider the problem of estimating the 3D position of multiple humans in a scene as well as their body shape and articulation from a single RGB video recorded with a static camera. In contrast to expensive marker-based or multi-view systems, our lightweight setup is ideal for private users as it enables an affordable 3D motion capture that is easy to install and does not require expert knowledge. To deal with this challenging setting, we leverage recent advances in computer vision using large-scale pre-trained models for a variety of modalities, including 2D body joints, joint angles, normalized disparity maps, and human segmentation masks. Thus, we introduce the first non-linear optimization-based approach that jointly solves for the absolute 3D position of each human, their articulated pose, their individual shapes as well as the scale of the scene. In particular, we estimate the scene depth and person unique scale from normalized disparity predictions using the 2D body joints and joint angles. Given the per-frame scene depth, we reconstruct a point-cloud of the static scene in 3D space. Finally, given the per-frame 3D estimates of the humans and scene point-cloud, we perform a space-time coherent optimization over the video to ensure temporal, spatial and physical plausibility. We evaluate our method on established multi-person 3D human pose benchmarks where we consistently outperform previous methods and we qualitatively demonstrate that our method is robust to in-the-wild conditions including challenging scenes with people of different sizes.
Imitator: Personalized Speech-driven 3D Facial Animation
Dec 30, 2022Speech-driven 3D facial animation has been widely explored, with applications in gaming, character animation, virtual reality, and telepresence systems. State-of-the-art methods deform the face topology of the target actor to sync the input audio without considering the identity-specific speaking style and facial idiosyncrasies of the target actor, thus, resulting in unrealistic and inaccurate lip movements. To address this, we present Imitator, a speech-driven facial expression synthesis method, which learns identity-specific details from a short input video and produces novel facial expressions matching the identity-specific speaking style and facial idiosyncrasies of the target actor. Specifically, we train a style-agnostic transformer on a large facial expression dataset which we use as a prior for audio-driven facial expressions. Based on this prior, we optimize for identity-specific speaking style based on a short reference video. To train the prior, we introduce a novel loss function based on detected bilabial consonants to ensure plausible lip closures and consequently improve the realism of the generated expressions. Through detailed experiments and a user study, we show that our approach produces temporally coherent facial expressions from input audio while preserving the speaking style of the target actors.
Scene-aware Egocentric 3D Human Pose Estimation
Dec 20, 2022



Egocentric 3D human pose estimation with a single head-mounted fisheye camera has recently attracted attention due to its numerous applications in virtual and augmented reality. Existing methods still struggle in challenging poses where the human body is highly occluded or is closely interacting with the scene. To address this issue, we propose a scene-aware egocentric pose estimation method that guides the prediction of the egocentric pose with scene constraints. To this end, we propose an egocentric depth estimation network to predict the scene depth map from a wide-view egocentric fisheye camera while mitigating the occlusion of the human body with a depth-inpainting network. Next, we propose a scene-aware pose estimation network that projects the 2D image features and estimated depth map of the scene into a voxel space and regresses the 3D pose with a V2V network. The voxel-based feature representation provides the direct geometric connection between 2D image features and scene geometry, and further facilitates the V2V network to constrain the predicted pose based on the estimated scene geometry. To enable the training of the aforementioned networks, we also generated a synthetic dataset, called EgoGTA, and an in-the-wild dataset based on EgoPW, called EgoPW-Scene. The experimental results of our new evaluation sequences show that the predicted 3D egocentric poses are accurate and physically plausible in terms of human-scene interaction, demonstrating that our method outperforms the state-of-the-art methods both quantitatively and qualitatively.
IMoS: Intent-Driven Full-Body Motion Synthesis for Human-Object Interactions
Dec 16, 2022Can we make virtual characters in a scene interact with their surrounding objects through simple instructions? Is it possible to synthesize such motion plausibly with a diverse set of objects and instructions? Inspired by these questions, we present the first framework to synthesize the full-body motion of virtual human characters performing specified actions with 3D objects placed within their reach. Our system takes as input textual instructions specifying the objects and the associated intentions of the virtual characters and outputs diverse sequences of full-body motions. This is in contrast to existing work, where full-body action synthesis methods generally do not consider object interactions, and human-object interaction methods focus mainly on synthesizing hand or finger movements for grasping objects. We accomplish our objective by designing an intent-driven full-body motion generator, which uses a pair of decoupled conditional variational autoencoders (CVAE) to learn the motion of the body parts in an autoregressive manner. We also optimize for the positions of the objects with six degrees of freedom (6DoF) such that they plausibly fit within the hands of the synthesized characters. We compare our proposed method with the existing methods of motion synthesis and establish a new and stronger state-of-the-art for the task of intent-driven motion synthesis. Through a user study, we further show that our synthesized full-body motions appear more realistic to the participants in more than 80% of scenarios compared to the current state-of-the-art methods, and are perceived to be as good as the ground truth on several occasions.
NeuS2: Fast Learning of Neural Implicit Surfaces for Multi-view Reconstruction
Dec 10, 2022



Recent methods for neural surface representation and rendering, for example NeuS, have demonstrated remarkably high-quality reconstruction of static scenes. However, the training of NeuS takes an extremely long time (8 hours), which makes it almost impossible to apply them to dynamic scenes with thousands of frames. We propose a fast neural surface reconstruction approach, called NeuS2, which achieves two orders of magnitude improvement in terms of acceleration without compromising reconstruction quality. To accelerate the training process, we integrate multi-resolution hash encodings into a neural surface representation and implement our whole algorithm in CUDA. We also present a lightweight calculation of second-order derivatives tailored to our networks (i.e., ReLU-based MLPs), which achieves a factor two speed up. To further stabilize training, a progressive learning strategy is proposed to optimize multi-resolution hash encodings from coarse to fine. In addition, we extend our method for reconstructing dynamic scenes with an incremental training strategy. Our experiments on various datasets demonstrate that NeuS2 significantly outperforms the state-of-the-arts in both surface reconstruction accuracy and training speed. The video is available at https://vcai.mpi-inf.mpg.de/projects/NeuS2/ .
MoFusion: A Framework for Denoising-Diffusion-based Motion Synthesis
Dec 08, 2022



Conventional methods for human motion synthesis are either deterministic or struggle with the trade-off between motion diversity and motion quality. In response to these limitations, we introduce MoFusion, i.e., a new denoising-diffusion-based framework for high-quality conditional human motion synthesis that can generate long, temporally plausible, and semantically accurate motions based on a range of conditioning contexts (such as music and text). We also present ways to introduce well-known kinematic losses for motion plausibility within the motion diffusion framework through our scheduled weighting strategy. The learned latent space can be used for several interactive motion editing applications -- like inbetweening, seed conditioning, and text-based editing -- thus, providing crucial abilities for virtual character animation and robotics. Through comprehensive quantitative evaluations and a perceptual user study, we demonstrate the effectiveness of MoFusion compared to the state of the art on established benchmarks in the literature. We urge the reader to watch our supplementary video and visit https://vcai.mpi-inf.mpg.de/projects/MoFusion.
Fast Non-Rigid Radiance Fields from Monocularized Data
Dec 02, 2022



3D reconstruction and novel view synthesis of dynamic scenes from collections of single views recently gained increased attention. Existing work shows impressive results for synthetic setups and forward-facing real-world data, but is severely limited in the training speed and angular range for generating novel views. This paper addresses these limitations and proposes a new method for full 360{\deg} novel view synthesis of non-rigidly deforming scenes. At the core of our method are: 1) An efficient deformation module that decouples the processing of spatial and temporal information for acceleration at training and inference time; and 2) A static module representing the canonical scene as a fast hash-encoded neural radiance field. We evaluate the proposed approach on the established synthetic D-NeRF benchmark, that enables efficient reconstruction from a single monocular view per time-frame randomly sampled from a full hemisphere. We refer to this form of inputs as monocularized data. To prove its practicality for real-world scenarios, we recorded twelve challenging sequences with human actors by sampling single frames from a synchronized multi-view rig. In both cases, our method is trained significantly faster than previous methods (minutes instead of days) while achieving higher visual accuracy for generated novel views. Our source code and data is available at our project page https://graphics.tu-bs.de/publications/kappel2022fast.
NeuralUDF: Learning Unsigned Distance Fields for Multi-view Reconstruction of Surfaces with Arbitrary Topologies
Nov 25, 2022We present a novel method, called NeuralUDF, for reconstructing surfaces with arbitrary topologies from 2D images via volume rendering. Recent advances in neural rendering based reconstruction have achieved compelling results. However, these methods are limited to objects with closed surfaces since they adopt Signed Distance Function (SDF) as surface representation which requires the target shape to be divided into inside and outside. In this paper, we propose to represent surfaces as the Unsigned Distance Function (UDF) and develop a new volume rendering scheme to learn the neural UDF representation. Specifically, a new density function that correlates the property of UDF with the volume rendering scheme is introduced for robust optimization of the UDF fields. Experiments on the DTU and DeepFashion3D datasets show that our method not only enables high-quality reconstruction of non-closed shapes with complex typologies, but also achieves comparable performance to the SDF based methods on the reconstruction of closed surfaces.
GlowGAN: Unsupervised Learning of HDR Images from LDR Images in the Wild
Nov 23, 2022



Most in-the-wild images are stored in Low Dynamic Range (LDR) form, serving as a partial observation of the High Dynamic Range (HDR) visual world. Despite limited dynamic range, these LDR images are often captured with different exposures, implicitly containing information about the underlying HDR image distribution. Inspired by this intuition, in this work we present, to the best of our knowledge, the first method for learning a generative model of HDR images from in-the-wild LDR image collections in a fully unsupervised manner. The key idea is to train a generative adversarial network (GAN) to generate HDR images which, when projected to LDR under various exposures, are indistinguishable from real LDR images. The projection from HDR to LDR is achieved via a camera model that captures the stochasticity in exposure and camera response function. Experiments show that our method GlowGAN can synthesize photorealistic HDR images in many challenging cases such as landscapes, lightning, or windows, where previous supervised generative models produce overexposed images. We further demonstrate the new application of unsupervised inverse tone mapping (ITM) enabled by GlowGAN. Our ITM method does not need HDR images or paired multi-exposure images for training, yet it reconstructs more plausible information for overexposed regions than state-of-the-art supervised learning models trained on such data.