 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthVSR: Scaling Up Visual Speech Recognition With Synthetic Supervision
Apr 03, 2023



Recently reported state-of-the-art results in visual speech recognition (VSR) often rely on increasingly large amounts of video data, while the publicly available transcribed video datasets are limited in size. In this paper, for the first time, we study the potential of leveraging synthetic visual data for VSR. Our method, termed SynthVSR, substantially improves the performance of VSR systems with synthetic lip movements. The key idea behind SynthVSR is to leverage a speech-driven lip animation model that generates lip movements conditioned on the input speech. The speech-driven lip animation model is trained on an unlabeled audio-visual dataset and could be further optimized towards a pre-trained VSR model when labeled videos are available. As plenty of transcribed acoustic data and face images are available, we are able to generate large-scale synthetic data using the proposed lip animation model for semi-supervised VSR training. We evaluate the performance of our approach on the largest public VSR benchmark - Lip Reading Sentences 3 (LRS3). SynthVSR achieves a WER of 43.3% with only 30 hours of real labeled data, outperforming off-the-shelf approaches using thousands of hours of video. The WER is further reduced to 27.9% when using all 438 hours of labeled data from LRS3, which is on par with the state-of-the-art self-supervised AV-HuBERT method. Furthermore, when combined with large-scale pseudo-labeled audio-visual data SynthVSR yields a new state-of-the-art VSR WER of 16.9% using publicly available data only, surpassing the recent state-of-the-art approaches trained with 29 times more non-public machine-transcribed video data (90,000 hours). Finally, we perform extensive ablation studies to understand the effect of each component in our proposed method.
Streaming Audio-Visual Speech Recognition with Alignment Regularization
Nov 03, 2022Recognizing a word shortly after it is spoken is an important requirement for automatic speech recognition (ASR) systems in real-world scenarios. As a result, a large body of work on streaming audio-only ASR models has been presented in the literature. However, streaming audio-visual automatic speech recognition (AV-ASR) has received little attention in earlier works. In this work, we propose a streaming AV-ASR system based on a hybrid connectionist temporal classification (CTC)/attention neural network architecture. The audio and the visual encoder neural networks are both based on the conformer architecture, which is made streamable using chunk-wise self-attention (CSA) and causal convolution. Streaming recognition with a decoder neural network is realized by using the triggered attention technique, which performs time-synchronous decoding with joint CTC/attention scoring. For frame-level ASR criteria, such as CTC, a synchronized response from the audio and visual encoders is critical for a joint AV decision making process. In this work, we propose a novel alignment regularization technique that promotes synchronization of the audio and visual encoder, which in turn results in better word error rates (WERs) at all SNR levels for streaming and offline AV-ASR models. The proposed AV-ASR model achieves WERs of 2.0% and 2.6% on the Lip Reading Sentences 3 (LRS3) dataset in an offline and online setup, respectively, which both present state-of-the-art results when no external training data are used.
An Investigation of Monotonic Transducers for Large-Scale Automatic Speech Recognition
Apr 19, 2022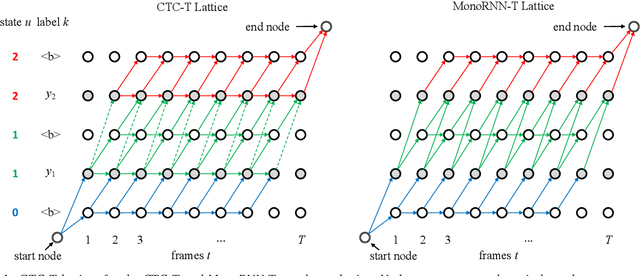
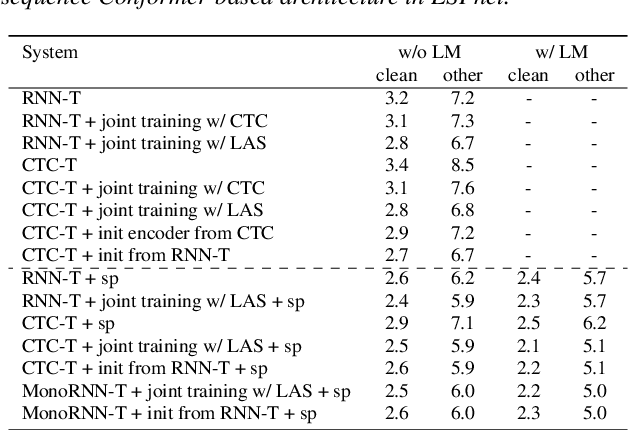
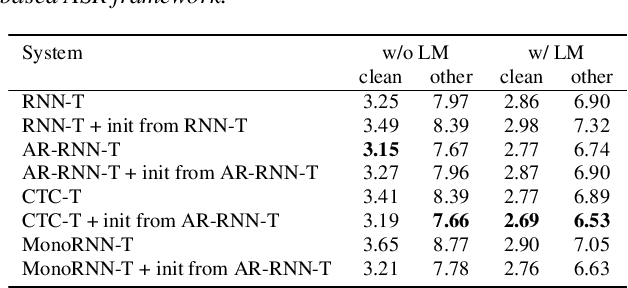
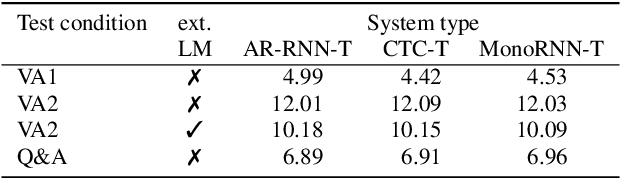
The two most popular loss functions for streaming end-to-end automatic speech recognition (ASR) are the RNN-Transducer (RNN-T) and the connectionist temporal classification (CTC) objectives. Both perform an alignment-free training by marginalizing over all possible alignments, but use different transition rules. Between these two loss types we can classify the monotonic RNN-T (MonoRNN-T) and the recently proposed CTC-like Transducer (CTC-T), which both can be realized using the graph temporal classification-transducer (GTC-T) loss function. Monotonic transducers have a few advantages. First, RNN-T can suffer from runaway hallucination, where a model keeps emitting non-blank symbols without advancing in time, often in an infinite loop. Secondly, monotonic transducers consume exactly one model score per time step and are therefore more compatible and unifiable with traditional FST-based hybrid ASR decoders. However, the MonoRNN-T so far has been found to have worse accuracy than RNN-T. It does not have to be that way, though: By regularizing the training - via joint LAS training or parameter initialization from RNN-T - both MonoRNN-T and CTC-T perform as well - or better - than RNN-T. This is demonstrated for LibriSpeech and for a large-scale in-house data set.
Scaling ASR Improves Zero and Few Shot Learning
Nov 29, 2021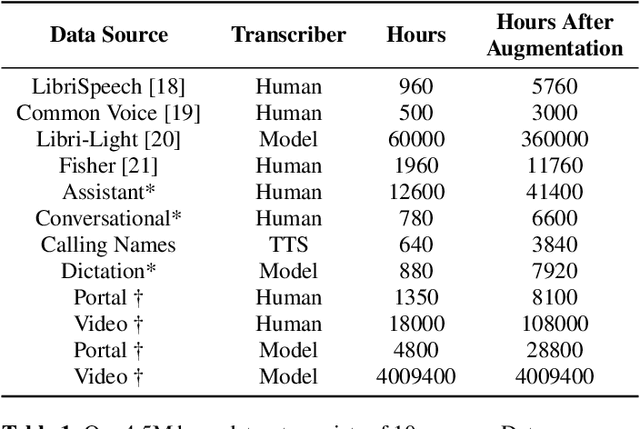
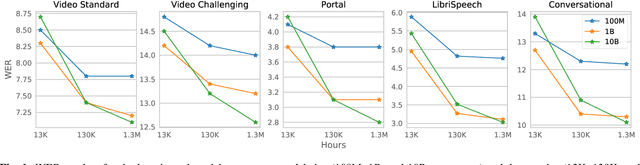
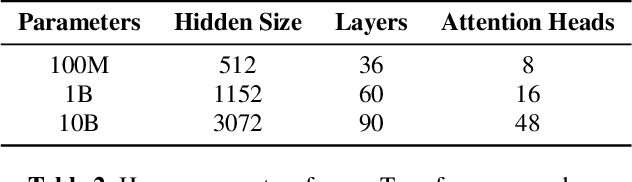
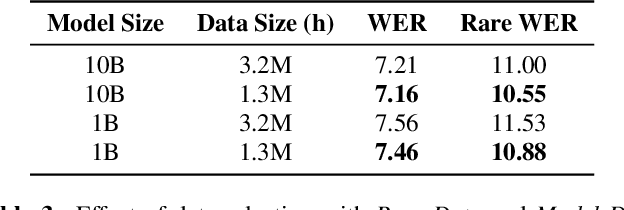
With 4.5 million hours of English speech from 10 different sources across 120 countries and models of up to 10 billion parameters, we explore the frontiers of scale for automatic speech recognition. We propose data selection techniques to efficiently scale training data to find the most valuable samples in massive datasets. To efficiently scale model sizes, we leverage various optimizations such as sparse transducer loss and model sharding. By training 1-10B parameter universal English ASR models, we push the limits of speech recognition performance across many domains. Furthermore, our models learn powerful speech representations with zero and few-shot capabilities on novel domains and styles of speech, exceeding previous results across multiple in-house and public benchmarks. For speakers with disorders due to brain damage, our best zero-shot and few-shot models achieve 22% and 60% relative improvement on the AphasiaBank test set, respectively, while realizing the best performance on public social media videos. Furthermore, the same universal model reaches equivalent performance with 500x less in-domain data on the SPGISpeech financial-domain dataset.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
Evaluating User Perception of Speech Recognition System Quality with Semantic Distance Metric
Oct 11, 2021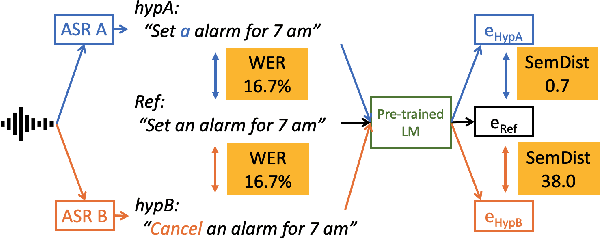
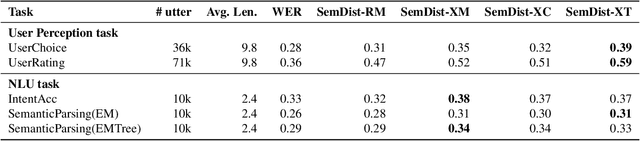
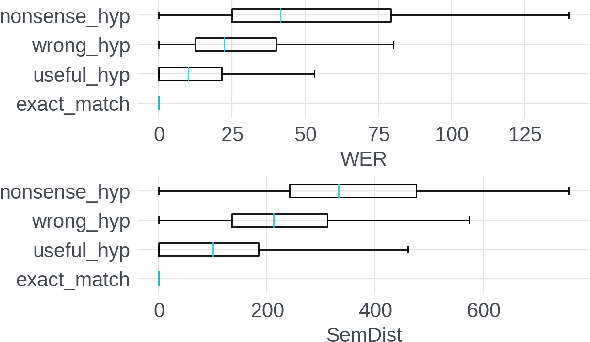
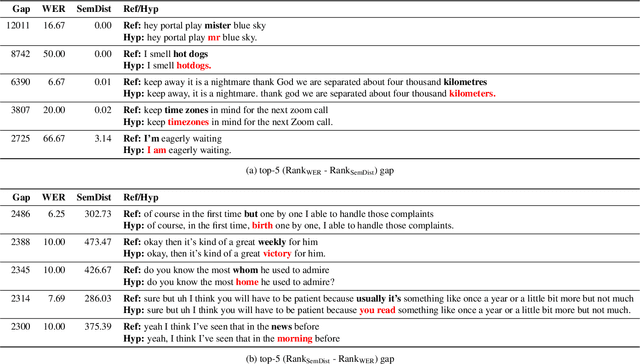
Measuring automatic speech recognition (ASR) system quality is critical for creating user-satisfying voice-driven applications. Word Error Rate (WER) has been traditionally used to evaluate ASR system quality; however, it sometimes correlates poorly with user perception of transcription quality. This is because WER weighs every word equally and does not consider semantic correctness which has a higher impact on user perception. In this work, we propose evaluating ASR output hypotheses quality with SemDist that can measure semantic correctness by using the distance between the semantic vectors of the reference and hypothesis extracted from a pre-trained language model. Our experimental results of 71K and 36K user annotated ASR output quality show that SemDist achieves higher correlation with user perception than WER. We also show that SemDist has higher correlation with downstream NLU tasks than WER.
Do sound event representations generalize to other audio tasks? A case study in audio transfer learning
Jun 21, 2021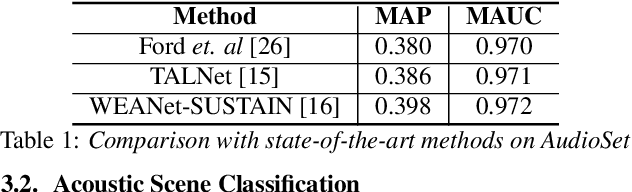
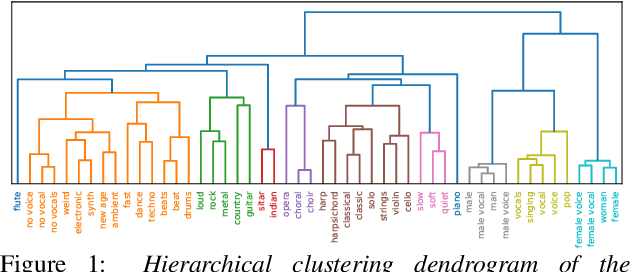
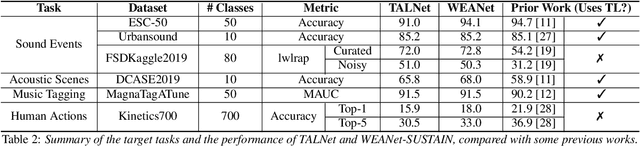
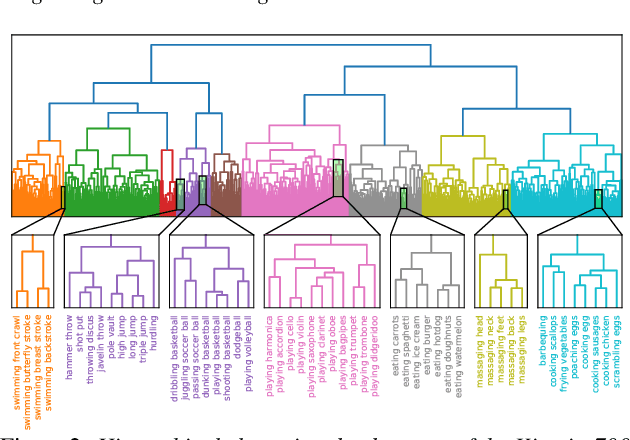
Transfer learning is critical for efficient information transfer across multiple related learning problems. A simple, yet effective transfer learning approach utilizes deep neural networks trained on a large-scale task for feature extraction. Such representations are then used to learn related downstream tasks. In this paper, we investigate transfer learning capacity of audio representations obtained from neural networks trained on a large-scale sound event detection dataset. We build and evaluate these representations across a wide range of other audio tasks, via a simple linear classifier transfer mechanism. We show that such simple linear transfer is already powerful enough to achieve high performance on the downstream tasks. We also provide insights into the attributes of sound event representations that enable such efficient information transfer.
Flexi-Transducer: Optimizing Latency, Accuracy and Compute forMulti-Domain On-Device Scenarios
Apr 06, 2021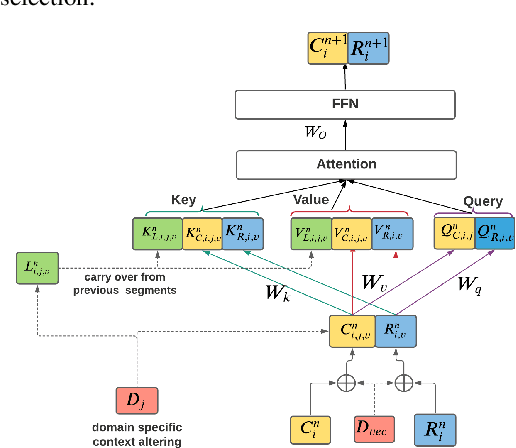
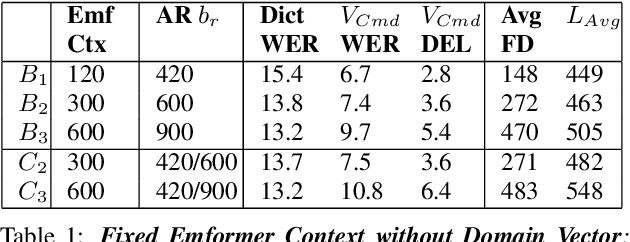
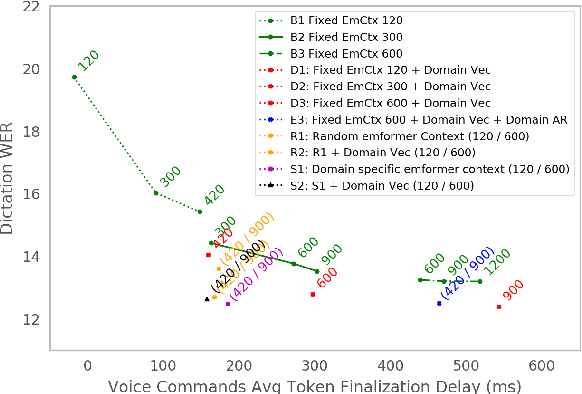
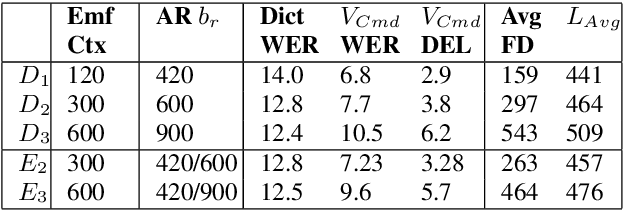
Often, the storage and computational constraints of embeddeddevices demand that a single on-device ASR model serve multiple use-cases / domains. In this paper, we propose aFlexibleTransducer(FlexiT) for on-device automatic speech recognition to flexibly deal with multiple use-cases / domains with different accuracy and latency requirements. Specifically, using a single compact model, FlexiT provides a fast response for voice commands, and accurate transcription but with more latency for dictation. In order to achieve flexible and better accuracy and latency trade-offs, the following techniques are used. Firstly, we propose using domain-specific altering of segment size for Emformer encoder that enables FlexiT to achieve flexible de-coding. Secondly, we use Alignment Restricted RNNT loss to achieve flexible fine-grained control on token emission latency for different domains. Finally, we add a domain indicator vector as an additional input to the FlexiT model. Using the combination of techniques, we show that a single model can be used to improve WERs and real time factor for dictation scenarios while maintaining optimal latency for voice commands use-cases
Dissecting User-Perceived Latency of On-Device E2E Speech Recognition
Apr 06, 2021
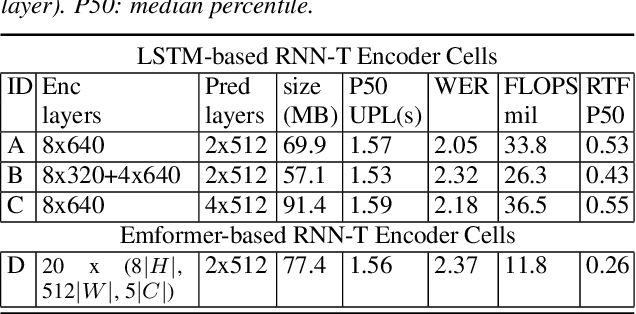
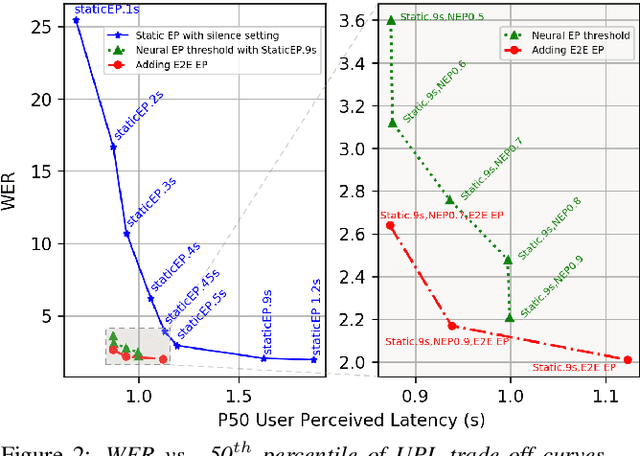
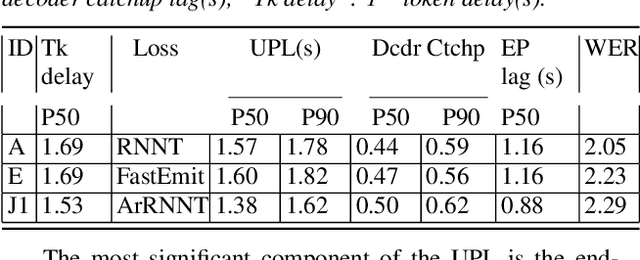
As speech-enabled devices such as smartphones and smart speakers become increasingly ubiquitous, there is growing interest in building automatic speech recognition (ASR) systems that can run directly on-device; end-to-end (E2E) speech recognition models such as recurrent neural network transducers and their variants have recently emerged as prime candidates for this task. Apart from being accurate and compact, such systems need to decode speech with low user-perceived latency (UPL), producing words as soon as they are spoken. This work examines the impact of various techniques -- model architectures, training criteria, decoding hyperparameters, and endpointer parameters -- on UPL. Our analyses suggest that measures of model size (parameters, input chunk sizes), or measures of computation (e.g., FLOPS, RTF) that reflect the model's ability to process input frames are not always strongly correlated with observed UPL. Thus, conventional algorithmic latency measurements might be inadequate in accurately capturing latency observed when models are deployed on embedded devices. Instead, we find that factors affecting token emission latency, and endpointing behavior significantly impact on UPL. We achieve the best trade-off between latency and word error rate when performing ASR jointly with endpointing, and using the recently proposed alignment regularization.
Contextualized Streaming End-to-End Speech Recognition with Trie-Based Deep Biasing and Shallow Fusion
Apr 05, 2021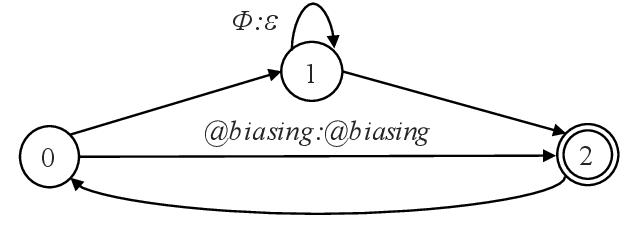
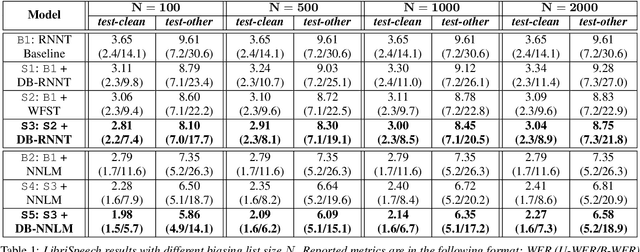
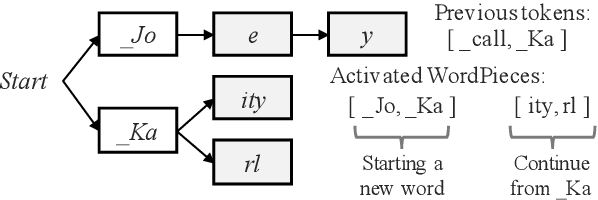
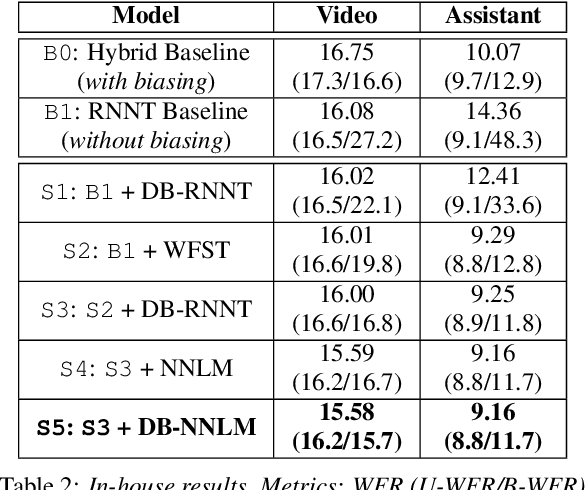
How to leverage dynamic contextual information in end-to-end speech recognition has remained an active research area. Previous solutions to this problem were either designed for specialized use cases that did not generalize well to open-domain scenarios, did not scale to large biasing lists, or underperformed on rare long-tail words. We address these limitations by proposing a novel solution that combines shallow fusion, trie-based deep biasing, and neural network language model contextualization. These techniques result in significant 19.5% relative Word Error Rate improvement over existing contextual biasing approaches and 5.4%-9.3% improvement compared to a strong hybrid baseline on both open-domain and constrained contextualization tasks, where the targets consist of mostly rare long-tail words. Our final system remains lightweight and modular, allowing for quick modification without model re-training.