 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021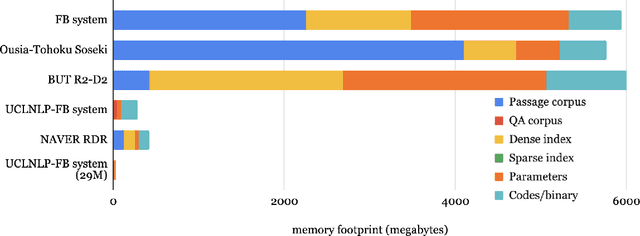
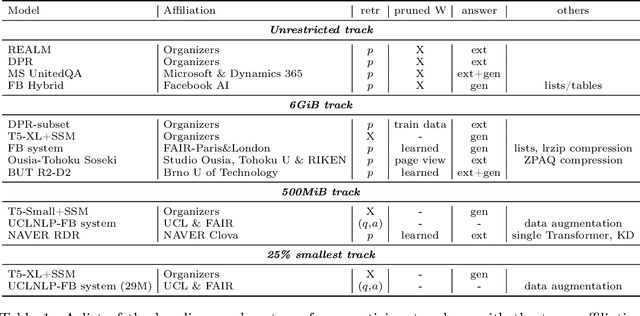
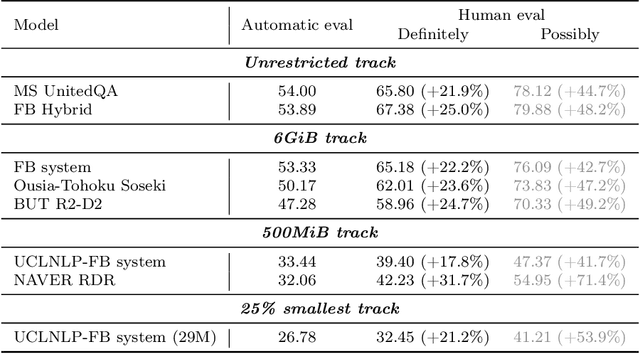
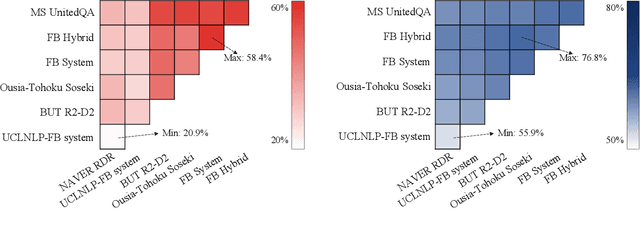
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
Data Weighted Training Strategies for Grammatical Error Correction
Sep 09, 2020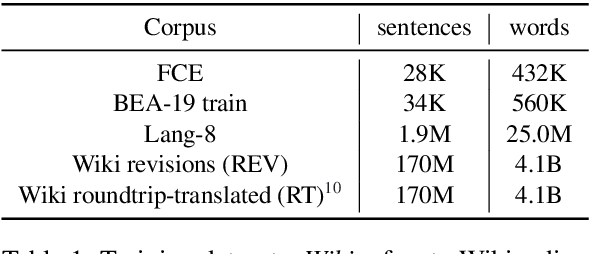
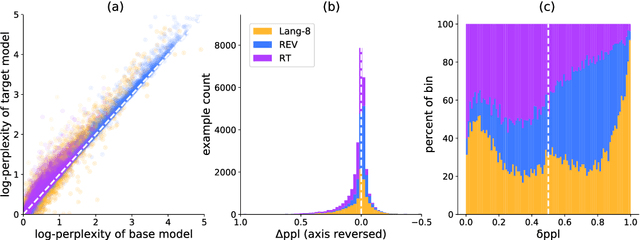
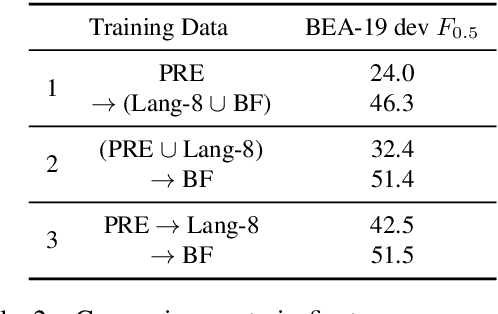
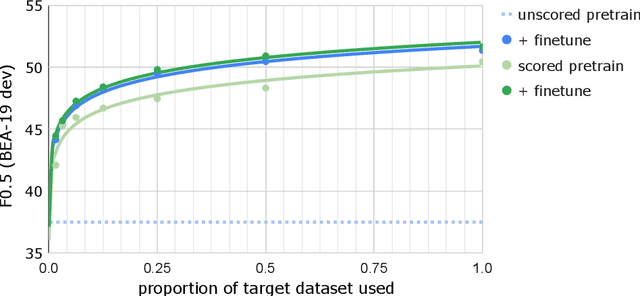
Recent progress in the task of Grammatical Error Correction (GEC) has been driven by addressing data sparsity, both through new methods for generating large and noisy pretraining data and through the publication of small and higher-quality finetuning data in the BEA-2019 shared task. Building upon recent work in Neural Machine Translation (NMT), we make use of both kinds of data by deriving example-level scores on our large pretraining data based on a smaller, higher-quality dataset. In this work, we perform an empirical study to discover how to best incorporate delta-log-perplexity, a type of example scoring, into a training schedule for GEC. In doing so, we perform experiments that shed light on the function and applicability of delta-log-perplexity. Models trained on scored data achieve state-of-the-art results on common GEC test sets.
QED: A Framework and Dataset for Explanations in Question Answering
Sep 08, 2020
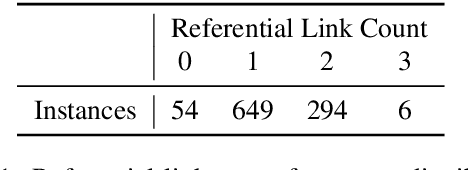
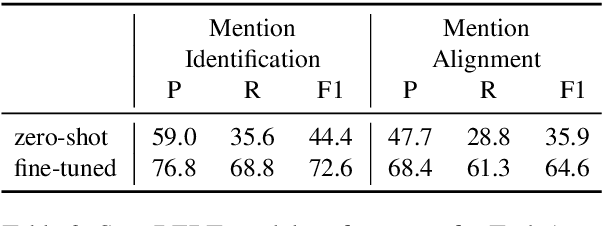

A question answering system that in addition to providing an answer provides an explanation of the reasoning that leads to that answer has potential advantages in terms of debuggability, extensibility and trust. To this end, we propose QED, a linguistically informed, extensible framework for explanations in question answering. A QED explanation specifies the relationship between a question and answer according to formal semantic notions such as referential equality, sentencehood, and entailment. We describe and publicly release an expert-annotated dataset of QED explanations built upon a subset of the Google Natural Questions dataset, and report baseline models on two tasks -- post-hoc explanation generation given an answer, and joint question answering and explanation generation. In the joint setting, a promising result suggests that training on a relatively small amount of QED data can improve question answering. In addition to describing the formal, language-theoretic motivations for the QED approach, we describe a large user study showing that the presence of QED explanations significantly improves the ability of untrained raters to spot errors made by a strong neural QA baseline.
Big Bird: Transformers for Longer Sequences
Jul 28, 2020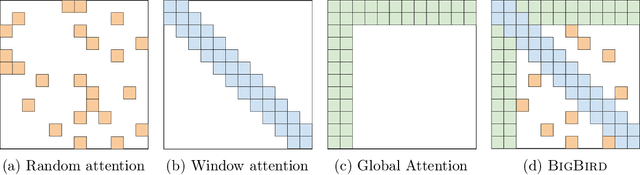
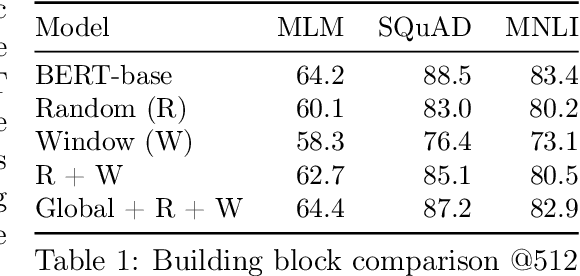

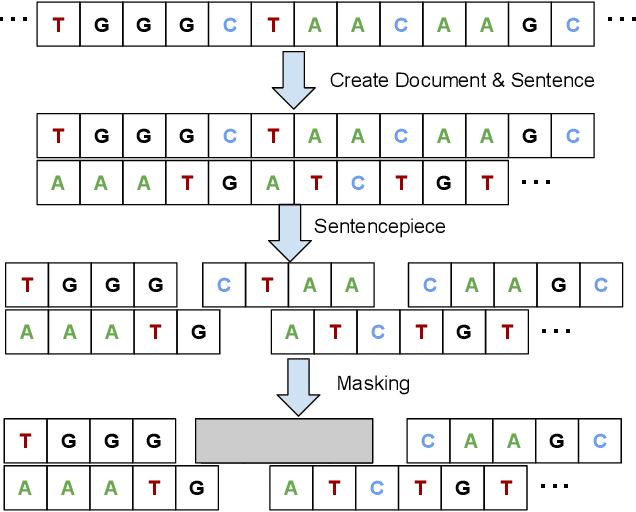
Transformers-based models, such as BERT, have been one of the most successful deep learning models for NLP. Unfortunately, one of their core limitations is the quadratic dependency (mainly in terms of memory) on the sequence length due to their full attention mechanism. To remedy this, we propose, BigBird, a sparse attention mechanism that reduces this quadratic dependency to linear. We show that BigBird is a universal approximator of sequence functions and is Turing complete, thereby preserving these properties of the quadratic, full attention model. Along the way, our theoretical analysis reveals some of the benefits of having $O(1)$ global tokens (such as CLS), that attend to the entire sequence as part of the sparse attention mechanism. The proposed sparse attention can handle sequences of length up to 8x of what was previously possible using similar hardware. As a consequence of the capability to handle longer context, BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also propose novel applications to genomics data.
ETC: Encoding Long and Structured Data in Transformers
Apr 21, 2020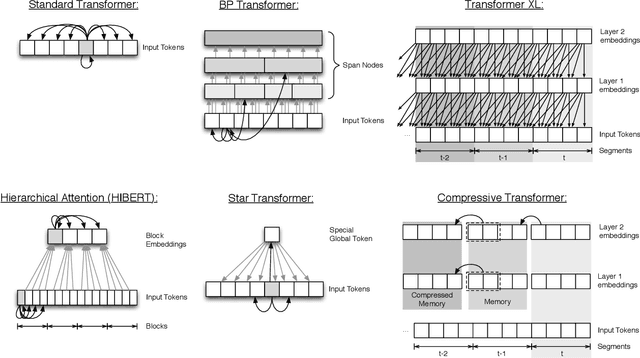
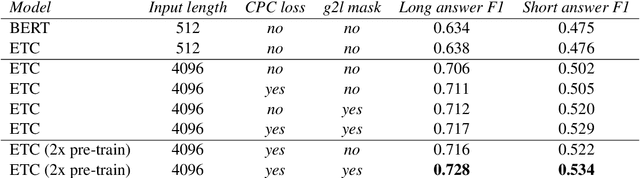
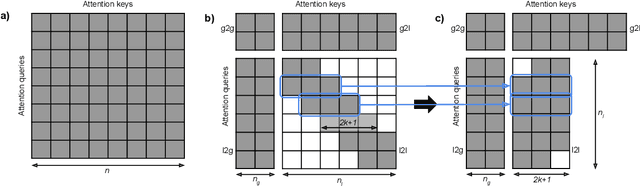
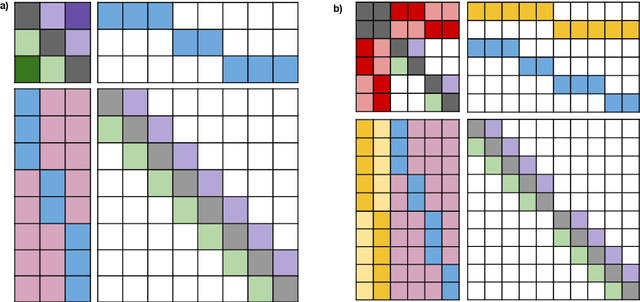
Transformer-based models have pushed the state of the art in many natural language processing tasks. However, one of their main limitations is the quadratic computational and memory cost of the standard attention mechanism. In this paper, we present a new family of Transformer models, which we call the Extended Transformer Construction (ETC), that allows for significant increases in input sequence length by introducing a new global-local attention mechanism between a global memory and the standard input tokens. We also show that combining global-local attention with relative position encodings allows ETC to handle structured data with ease. Empirical results on the Natural Questions data set show the promise of the approach.
Fusion of Detected Objects in Text for Visual Question Answering
Aug 14, 2019

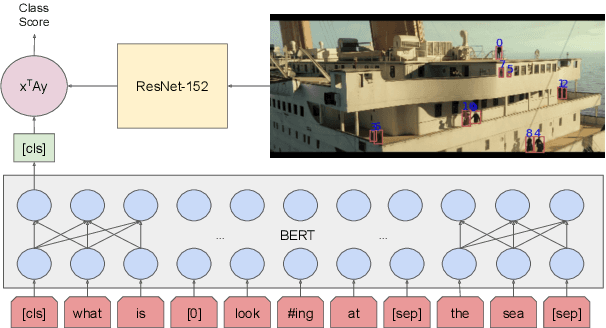
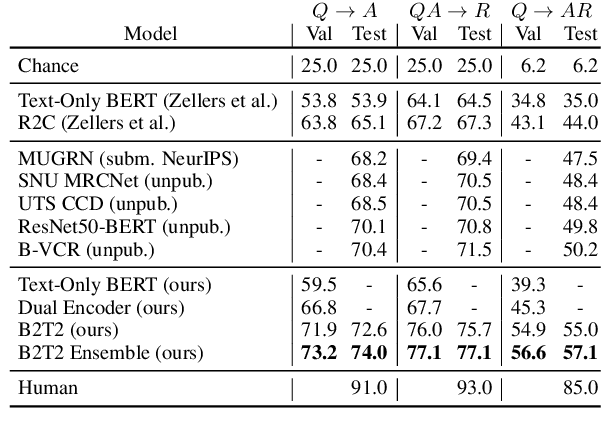
To advance models of multimodal context, we introduce a simple yet powerful neural architecture for data that combines vision and natural language. The "Bounding Boxes in Text Transformer" (B2T2) also leverages referential information binding words to portions of the image in a single unified architecture. B2T2 is highly effective on the Visual Commonsense Reasoning benchmark (visualcommonsense.com), achieving a new state-of-the-art with a 25% relative reduction in error rate compared to published baselines and obtaining the best performance to date on the public leaderboard (as of May 13, 2019). A detailed ablation analysis shows that the early integration of the visual features into the text analysis is key to the effectiveness of the new architecture.
Synthetic QA Corpora Generation with Roundtrip Consistency
Jun 12, 2019
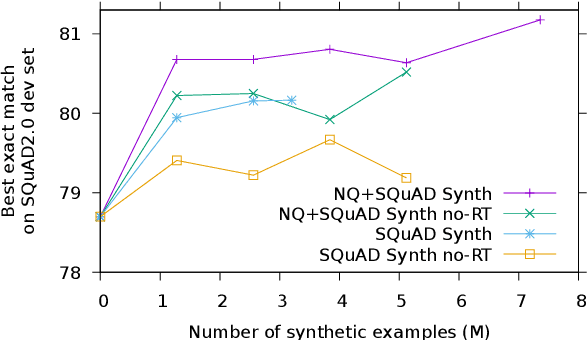
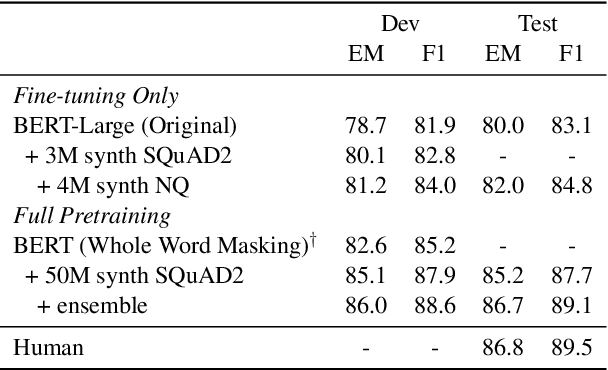
We introduce a novel method of generating synthetic question answering corpora by combining models of question generation and answer extraction, and by filtering the results to ensure roundtrip consistency. By pretraining on the resulting corpora we obtain significant improvements on SQuAD2 and NQ, establishing a new state-of-the-art on the latter. Our synthetic data generation models, for both question generation and answer extraction, can be fully reproduced by finetuning a publicly available BERT model on the extractive subsets of SQuAD2 and NQ. We also describe a more powerful variant that does full sequence-to-sequence pretraining for question generation, obtaining exact match and F1 at less than 0.1% and 0.4% from human performance on SQuAD2.
Corpora Generation for Grammatical Error Correction
Apr 10, 2019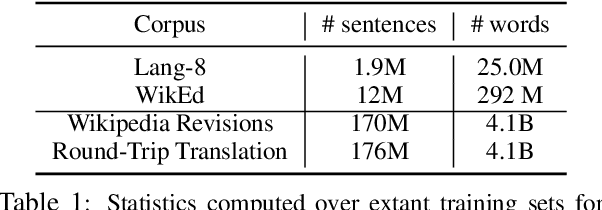
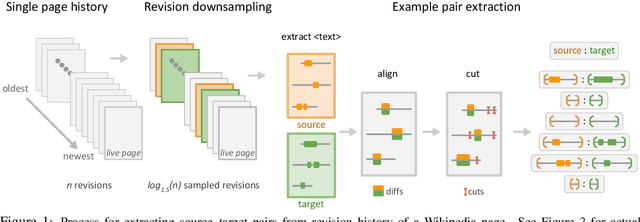
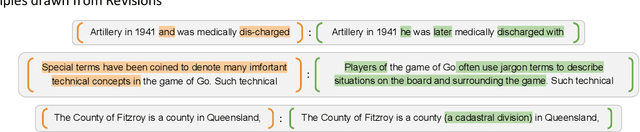

Grammatical Error Correction (GEC) has been recently modeled using the sequence-to-sequence framework. However, unlike sequence transduction problems such as machine translation, GEC suffers from the lack of plentiful parallel data. We describe two approaches for generating large parallel datasets for GEC using publicly available Wikipedia data. The first method extracts source-target pairs from Wikipedia edit histories with minimal filtration heuristics, while the second method introduces noise into Wikipedia sentences via round-trip translation through bridge languages. Both strategies yield similar sized parallel corpora containing around 4B tokens. We employ an iterative decoding strategy that is tailored to the loosely supervised nature of our constructed corpora. We demonstrate that neural GEC models trained using either type of corpora give similar performance. Fine-tuning these models on the Lang-8 corpus and ensembling allows us to surpass the state of the art on both the CoNLL-2014 benchmark and the JFLEG task. We provide systematic analysis that compares the two approaches to data generation and highlights the effectiveness of ensembling.
A BERT Baseline for the Natural Questions
Jan 24, 2019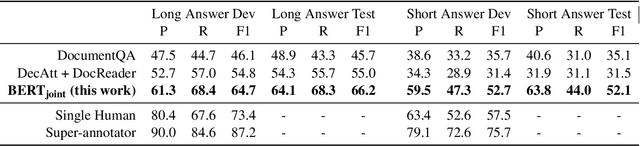
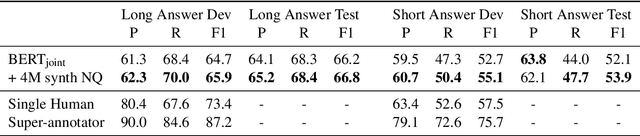
This technical note describes a new baseline for the Natural Questions. Our model is based on BERT and reduces the gap between the model F1 scores reported in the original dataset paper and the human upper bound by 30% and 50% relative for the long and short answer tasks respectively. This baseline has been submitted to the official NQ leaderboard at ai.google.com/research/NaturalQuestions and we plan to opensource the code for it in the near future.
SyntaxNet Models for the CoNLL 2017 Shared Task
Mar 15, 2017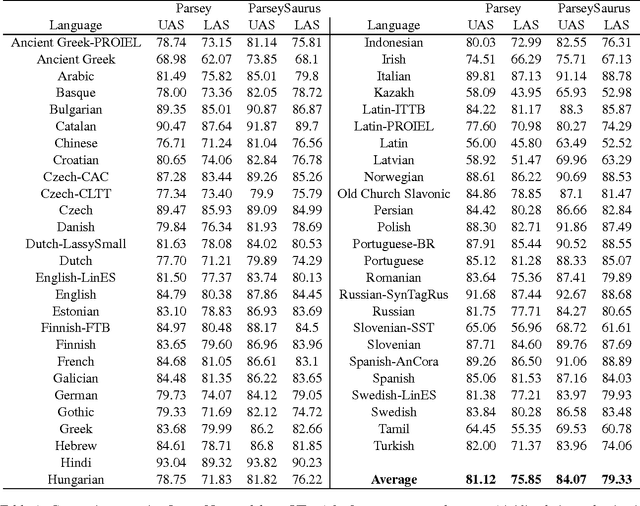
We describe a baseline dependency parsing system for the CoNLL2017 Shared Task. This system, which we call "ParseySaurus," uses the DRAGNN framework [Kong et al, 2017] to combine transition-based recurrent parsing and tagging with character-based word representations. On the v1.3 Universal Dependencies Treebanks, the new system outpeforms the publicly available, state-of-the-art "Parsey's Cousins" models by 3.47% absolute Labeled Accuracy Score (LAS) across 52 treebanks.