 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Investigation on Deep Learning-Based Omnidirectional Image and Video Super-Resolution
Jun 07, 2025Omnidirectional image and video super-resolution is a crucial research topic in low-level vision, playing an essential role in virtual reality and augmented reality applications. Its goal is to reconstruct high-resolution images or video frames from low-resolution inputs, thereby enhancing detail preservation and enabling more accurate scene analysis and interpretation. In recent years, numerous innovative and effective approaches have been proposed, predominantly based on deep learning techniques, involving diverse network architectures, loss functions, projection strategies, and training datasets. This paper presents a systematic review of recent progress in omnidirectional image and video super-resolution, focusing on deep learning-based methods. Given that existing datasets predominantly rely on synthetic degradation and fall short in capturing real-world distortions, we introduce a new dataset, 360Insta, that comprises authentically degraded omnidirectional images and videos collected under diverse conditions, including varying lighting, motion, and exposure settings. This dataset addresses a critical gap in current omnidirectional benchmarks and enables more robust evaluation of the generalization capabilities of omnidirectional super-resolution methods. We conduct comprehensive qualitative and quantitative evaluations of existing methods on both public datasets and our proposed dataset. Furthermore, we provide a systematic overview of the current status of research and discuss promising directions for future exploration. All datasets, methods, and evaluation metrics introduced in this work are publicly available and will be regularly updated. Project page: https://github.com/nqian1/Survey-on-ODISR-and-ODVSR.
3D-UIR: 3D Gaussian for Underwater 3D Scene Reconstruction via Physics Based Appearance-Medium Decoupling
May 29, 2025Novel view synthesis for underwater scene reconstruction presents unique challenges due to complex light-media interactions. Optical scattering and absorption in water body bring inhomogeneous medium attenuation interference that disrupts conventional volume rendering assumptions of uniform propagation medium. While 3D Gaussian Splatting (3DGS) offers real-time rendering capabilities, it struggles with underwater inhomogeneous environments where scattering media introduce artifacts and inconsistent appearance. In this study, we propose a physics-based framework that disentangles object appearance from water medium effects through tailored Gaussian modeling. Our approach introduces appearance embeddings, which are explicit medium representations for backscatter and attenuation, enhancing scene consistency. In addition, we propose a distance-guided optimization strategy that leverages pseudo-depth maps as supervision with depth regularization and scale penalty terms to improve geometric fidelity. By integrating the proposed appearance and medium modeling components via an underwater imaging model, our approach achieves both high-quality novel view synthesis and physically accurate scene restoration. Experiments demonstrate our significant improvements in rendering quality and restoration accuracy over existing methods. The project page is available at https://bilityniu.github.io/3D-UIR.
DIPO: Dual-State Images Controlled Articulated Object Generation Powered by Diverse Data
May 28, 2025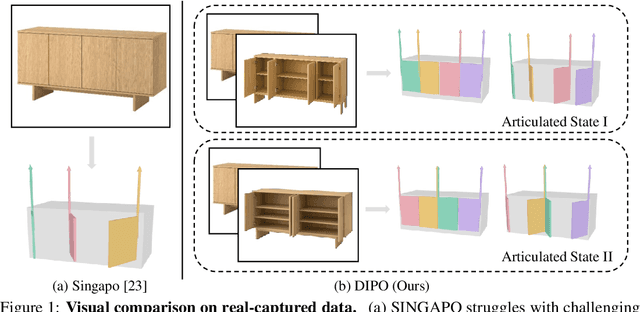
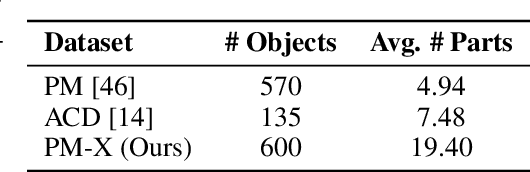
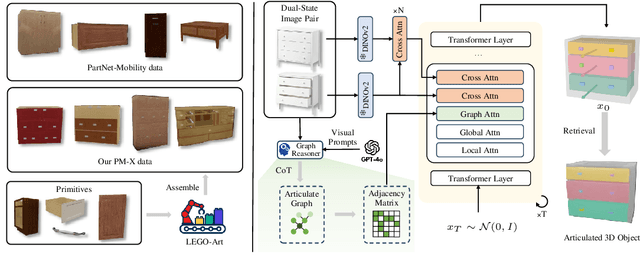
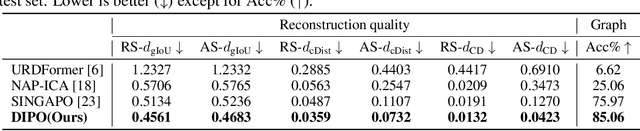
We present DIPO, a novel framework for the controllable generation of articulated 3D objects from a pair of images: one depicting the object in a resting state and the other in an articulated state. Compared to the single-image approach, our dual-image input imposes only a modest overhead for data collection, but at the same time provides important motion information, which is a reliable guide for predicting kinematic relationships between parts. Specifically, we propose a dual-image diffusion model that captures relationships between the image pair to generate part layouts and joint parameters. In addition, we introduce a Chain-of-Thought (CoT) based graph reasoner that explicitly infers part connectivity relationships. To further improve robustness and generalization on complex articulated objects, we develop a fully automated dataset expansion pipeline, name LEGO-Art, that enriches the diversity and complexity of PartNet-Mobility dataset. We propose PM-X, a large-scale dataset of complex articulated 3D objects, accompanied by rendered images, URDF annotations, and textual descriptions. Extensive experiments demonstrate that DIPO significantly outperforms existing baselines in both the resting state and the articulated state, while the proposed PM-X dataset further enhances generalization to diverse and structurally complex articulated objects. Our code and dataset will be released to the community upon publication.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
NTIRE 2025 Challenge on Efficient Burst HDR and Restoration: Datasets, Methods, and Results
May 17, 2025



This paper reviews the NTIRE 2025 Efficient Burst HDR and Restoration Challenge, which aims to advance efficient multi-frame high dynamic range (HDR) and restoration techniques. The challenge is based on a novel RAW multi-frame fusion dataset, comprising nine noisy and misaligned RAW frames with various exposure levels per scene. Participants were tasked with developing solutions capable of effectively fusing these frames while adhering to strict efficiency constraints: fewer than 30 million model parameters and a computational budget under 4.0 trillion FLOPs. A total of 217 participants registered, with six teams finally submitting valid solutions. The top-performing approach achieved a PSNR of 43.22 dB, showcasing the potential of novel methods in this domain. This paper provides a comprehensive overview of the challenge, compares the proposed solutions, and serves as a valuable reference for researchers and practitioners in efficient burst HDR and restoration.
Classic Video Denoising in a Machine Learning World: Robust, Fast, and Controllable
Apr 04, 2025Denoising is a crucial step in many video processing pipelines such as in interactive editing, where high quality, speed, and user control are essential. While recent approaches achieve significant improvements in denoising quality by leveraging deep learning, they are prone to unexpected failures due to discrepancies between training data distributions and the wide variety of noise patterns found in real-world videos. These methods also tend to be slow and lack user control. In contrast, traditional denoising methods perform reliably on in-the-wild videos and run relatively quickly on modern hardware. However, they require manually tuning parameters for each input video, which is not only tedious but also requires skill. We bridge the gap between these two paradigms by proposing a differentiable denoising pipeline based on traditional methods. A neural network is then trained to predict the optimal denoising parameters for each specific input, resulting in a robust and efficient approach that also supports user control.
A Diffusion-Based Framework for Occluded Object Movement
Apr 02, 2025Seamlessly moving objects within a scene is a common requirement for image editing, but it is still a challenge for existing editing methods. Especially for real-world images, the occlusion situation further increases the difficulty. The main difficulty is that the occluded portion needs to be completed before movement can proceed. To leverage the real-world knowledge embedded in the pre-trained diffusion models, we propose a Diffusion-based framework specifically designed for Occluded Object Movement, named DiffOOM. The proposed DiffOOM consists of two parallel branches that perform object de-occlusion and movement simultaneously. The de-occlusion branch utilizes a background color-fill strategy and a continuously updated object mask to focus the diffusion process on completing the obscured portion of the target object. Concurrently, the movement branch employs latent optimization to place the completed object in the target location and adopts local text-conditioned guidance to integrate the object into new surroundings appropriately. Extensive evaluations demonstrate the superior performance of our method, which is further validated by a comprehensive user study.
DiT4SR: Taming Diffusion Transformer for Real-World Image Super-Resolution
Mar 30, 2025



Large-scale pre-trained diffusion models are becoming increasingly popular in solving the Real-World Image Super-Resolution (Real-ISR) problem because of their rich generative priors. The recent development of diffusion transformer (DiT) has witnessed overwhelming performance over the traditional UNet-based architecture in image generation, which also raises the question: Can we adopt the advanced DiT-based diffusion model for Real-ISR? To this end, we propose our DiT4SR, one of the pioneering works to tame the large-scale DiT model for Real-ISR. Instead of directly injecting embeddings extracted from low-resolution (LR) images like ControlNet, we integrate the LR embeddings into the original attention mechanism of DiT, allowing for the bidirectional flow of information between the LR latent and the generated latent. The sufficient interaction of these two streams allows the LR stream to evolve with the diffusion process, producing progressively refined guidance that better aligns with the generated latent at each diffusion step. Additionally, the LR guidance is injected into the generated latent via a cross-stream convolution layer, compensating for DiT's limited ability to capture local information. These simple but effective designs endow the DiT model with superior performance in Real-ISR, which is demonstrated by extensive experiments. Project Page: https://adam-duan.github.io/projects/dit4sr/.
Iterative Predictor-Critic Code Decoding for Real-World Image Dehazing
Mar 17, 2025



We propose a novel Iterative Predictor-Critic Code Decoding framework for real-world image dehazing, abbreviated as IPC-Dehaze, which leverages the high-quality codebook prior encapsulated in a pre-trained VQGAN. Apart from previous codebook-based methods that rely on one-shot decoding, our method utilizes high-quality codes obtained in the previous iteration to guide the prediction of the Code-Predictor in the subsequent iteration, improving code prediction accuracy and ensuring stable dehazing performance. Our idea stems from the observations that 1) the degradation of hazy images varies with haze density and scene depth, and 2) clear regions play crucial cues in restoring dense haze regions. However, it is non-trivial to progressively refine the obtained codes in subsequent iterations, owing to the difficulty in determining which codes should be retained or replaced at each iteration. Another key insight of our study is to propose Code-Critic to capture interrelations among codes. The Code-Critic is used to evaluate code correlations and then resample a set of codes with the highest mask scores, i.e., a higher score indicates that the code is more likely to be rejected, which helps retain more accurate codes and predict difficult ones. Extensive experiments demonstrate the superiority of our method over state-of-the-art methods in real-world dehazing.
FaceMe: Robust Blind Face Restoration with Personal Identification
Jan 10, 2025Blind face restoration is a highly ill-posed problem due to the lack of necessary context. Although existing methods produce high-quality outputs, they often fail to faithfully preserve the individual's identity. In this paper, we propose a personalized face restoration method, FaceMe, based on a diffusion model. Given a single or a few reference images, we use an identity encoder to extract identity-related features, which serve as prompts to guide the diffusion model in restoring high-quality and identity-consistent facial images. By simply combining identity-related features, we effectively minimize the impact of identity-irrelevant features during training and support any number of reference image inputs during inference. Additionally, thanks to the robustness of the identity encoder, synthesized images can be used as reference images during training, and identity changing during inference does not require fine-tuning the model. We also propose a pipeline for constructing a reference image training pool that simulates the poses and expressions that may appear in real-world scenarios. Experimental results demonstrate that our FaceMe can restore high-quality facial images while maintaining identity consistency, achieving excellent performance and robustness.