 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowDA: All-in-One Knowledge Mixture Model for Data Augmentation in Few-Shot NLP
Jun 21, 2022
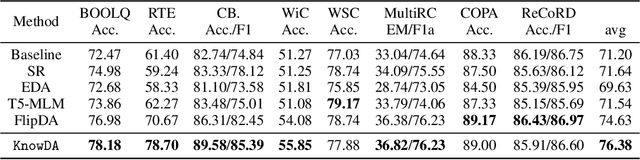
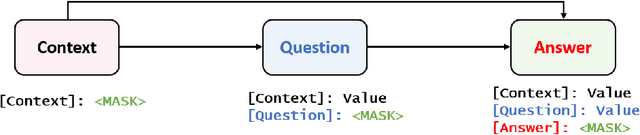
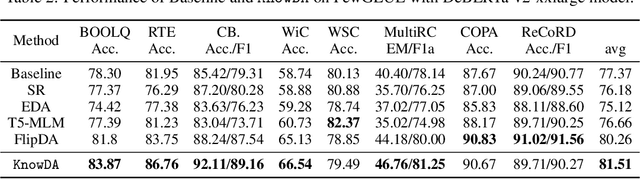
This paper focuses on text data augmentation for few-shot NLP tasks. The existing data augmentation algorithms either leverage task-independent heuristic rules (e.g., Synonym Replacement) or fine-tune general-purpose pre-trained language models (e.g., GPT2) using a small training set to produce new synthetic data. Consequently, these methods have trivial task-specific knowledge and are limited to yielding low-quality synthetic data for weak baselines in simple tasks. To combat this issue, we propose the Knowledge Mixture Data Augmentation Model (KnowDA): an encoder-decoder LM pretrained on a mixture of diverse NLP tasks using Knowledge Mixture Training (KoMT). KoMT is a training procedure that reformulates input examples from various heterogeneous NLP tasks into a unified text-to-text format and employs denoising objectives in different granularity to learn to generate partial or complete samples. With the aid of KoMT, KnowDA could combine required task-specific knowledge implicitly from the learned mixture of tasks and quickly grasp the inherent synthesis law of the target task through a few given instances. To the best of our knowledge, we are the first attempt to scale the number of tasks to 100+ in multi-task co-training for data augmentation. Extensive experiments show that i) KnowDA successfully improves the performance of Albert and Deberta by a large margin on the FewGLUE benchmark, outperforming previous state-of-the-art data augmentation baselines; ii) KnowDA could also improve the model performance on the few-shot NER tasks, a held-out task type not included in KoMT.
Towards Robust Ranker for Text Retrieval
Jun 16, 2022
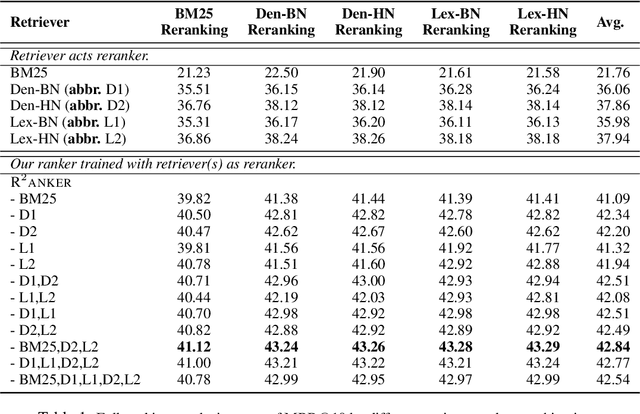
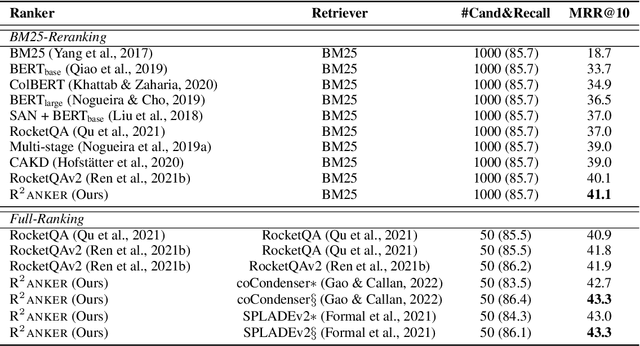
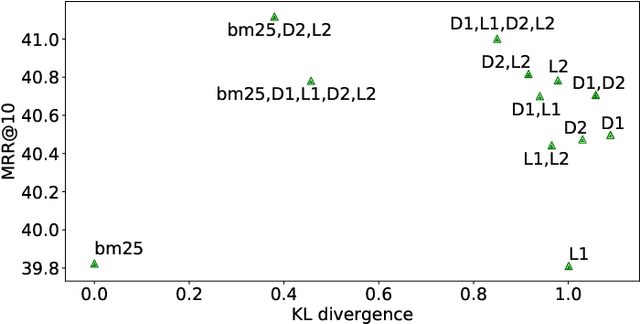
A ranker plays an indispensable role in the de facto 'retrieval & rerank' pipeline, but its training still lags behind -- learning from moderate negatives or/and serving as an auxiliary module for a retriever. In this work, we first identify two major barriers to a robust ranker, i.e., inherent label noises caused by a well-trained retriever and non-ideal negatives sampled for a high-capable ranker. Thereby, we propose multiple retrievers as negative generators improve the ranker's robustness, where i) involving extensive out-of-distribution label noises renders the ranker against each noise distribution, and ii) diverse hard negatives from a joint distribution are relatively close to the ranker's negative distribution, leading to more challenging thus effective training. To evaluate our robust ranker (dubbed R$^2$anker), we conduct experiments in various settings on the popular passage retrieval benchmark, including BM25-reranking, full-ranking, retriever distillation, etc. The empirical results verify the new state-of-the-art effectiveness of our model.
UnifieR: A Unified Retriever for Large-Scale Retrieval
May 23, 2022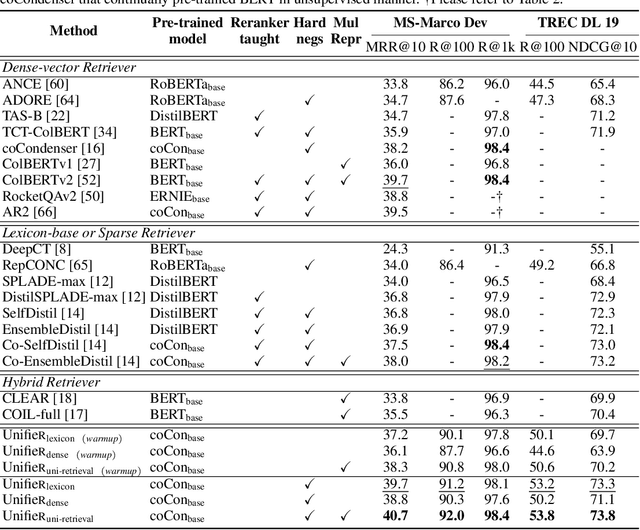
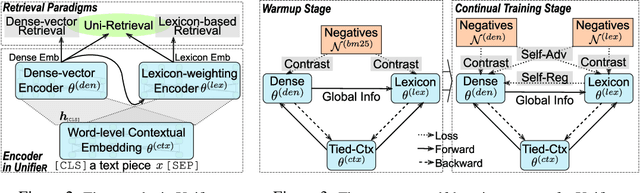
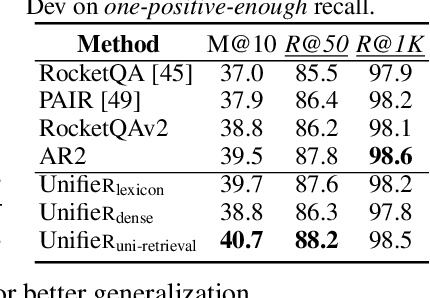
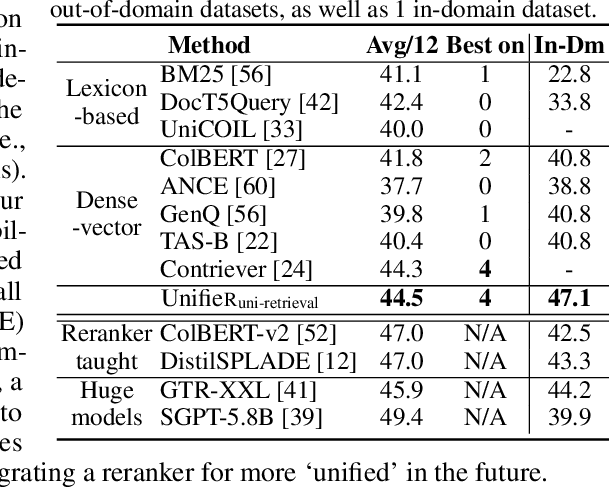
Large-scale retrieval is to recall relevant documents from a huge collection given a query. It relies on representation learning to embed documents and queries into a common semantic encoding space. According to the encoding space, recent retrieval methods based on pre-trained language models (PLM) can be coarsely categorized into either dense-vector or lexicon-based paradigms. These two paradigms unveil the PLMs' representation capability in different granularities, i.e., global sequence-level compression and local word-level contexts, respectively. Inspired by their complementary global-local contextualization and distinct representing views, we propose a new learning framework, UnifieR, which unifies dense-vector and lexicon-based retrieval in one model with a dual-representing capability. Experiments on passage retrieval benchmarks verify its effectiveness in both paradigms. A uni-retrieval scheme is further presented with even better retrieval quality. We lastly evaluate the model on BEIR benchmark to verify its transferability.
Learning to Express in Knowledge-Grounded Conversation
Apr 12, 2022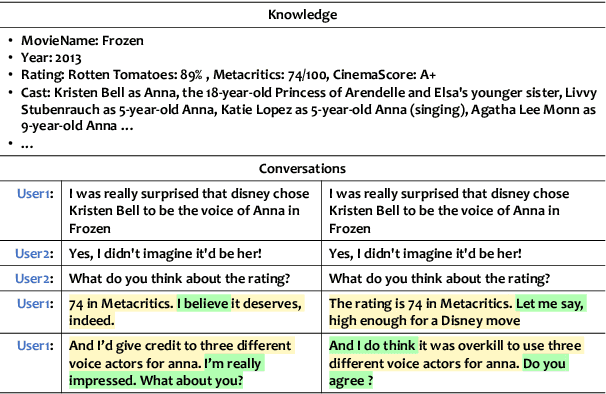
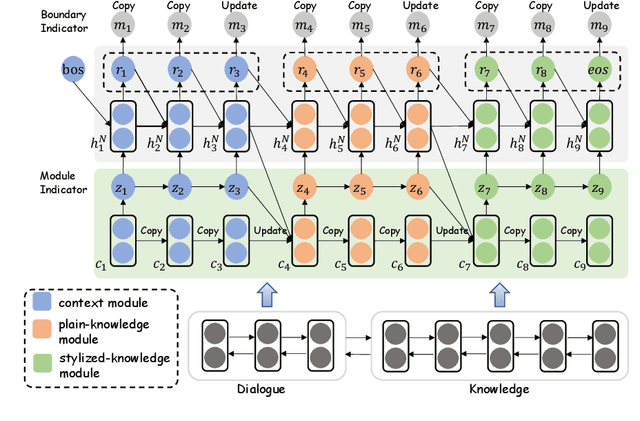
Grounding dialogue generation by extra knowledge has shown great potentials towards building a system capable of replying with knowledgeable and engaging responses. Existing studies focus on how to synthesize a response with proper knowledge, yet neglect that the same knowledge could be expressed differently by speakers even under the same context. In this work, we mainly consider two aspects of knowledge expression, namely the structure of the response and style of the content in each part. We therefore introduce two sequential latent variables to represent the structure and the content style respectively. We propose a segmentation-based generation model and optimize the model by a variational approach to discover the underlying pattern of knowledge expression in a response. Evaluation results on two benchmarks indicate that our model can learn the structure style defined by a few examples and generate responses in desired content style.
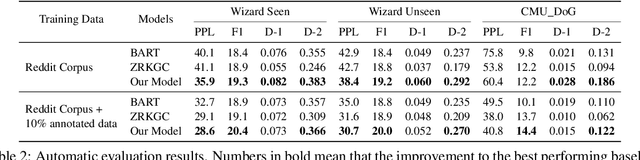
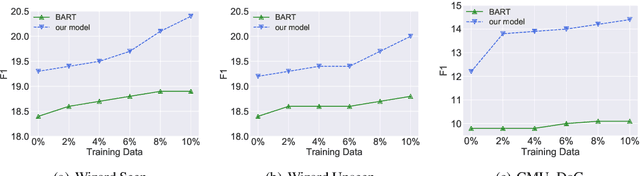
There Are a Thousand Hamlets in a Thousand People's Eyes: Enhancing Knowledge-grounded Dialogue with Personal Memory
Apr 06, 2022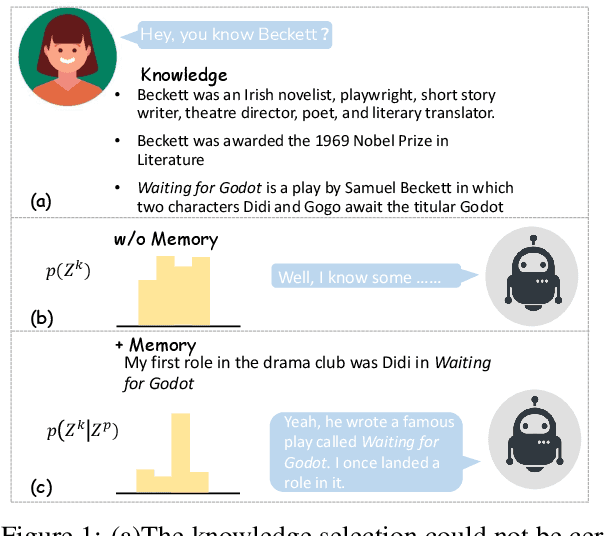
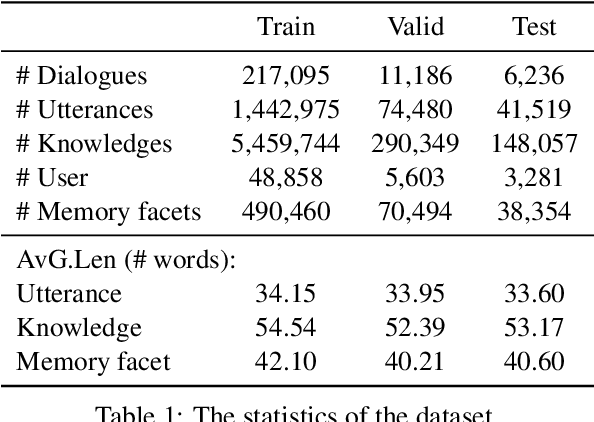
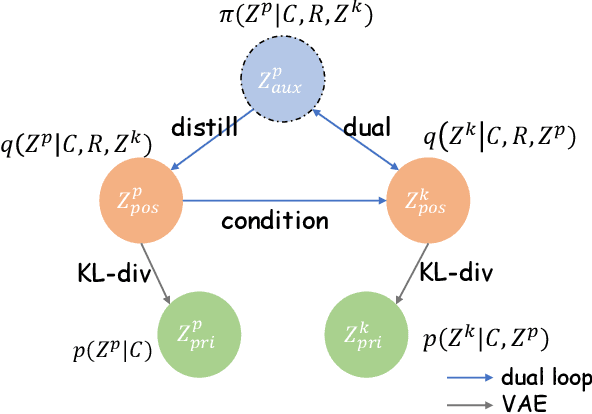
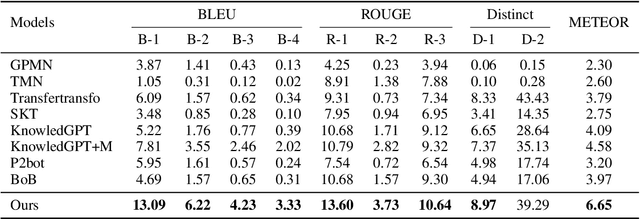
Knowledge-grounded conversation (KGC) shows great potential in building an engaging and knowledgeable chatbot, and knowledge selection is a key ingredient in it. However, previous methods for knowledge selection only concentrate on the relevance between knowledge and dialogue context, ignoring the fact that age, hobby, education and life experience of an interlocutor have a major effect on his or her personal preference over external knowledge. Without taking the personalization issue into account, it is difficult to select the proper knowledge and generate persona-consistent responses. In this work, we introduce personal memory into knowledge selection in KGC to address the personalization issue. We propose a variational method to model the underlying relationship between one's personal memory and his or her selection of knowledge, and devise a learning scheme in which the forward mapping from personal memory to knowledge and its inverse mapping is included in a closed loop so that they could teach each other. Experiment results show that our method outperforms existing KGC methods significantly on both automatic evaluation and human evaluation.
PromDA: Prompt-based Data Augmentation for Low-Resource NLU Tasks
Mar 17, 2022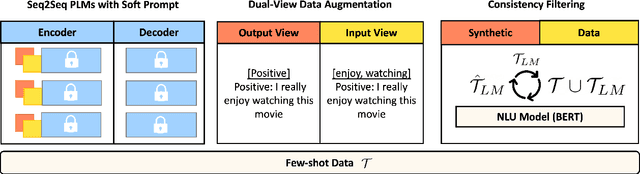
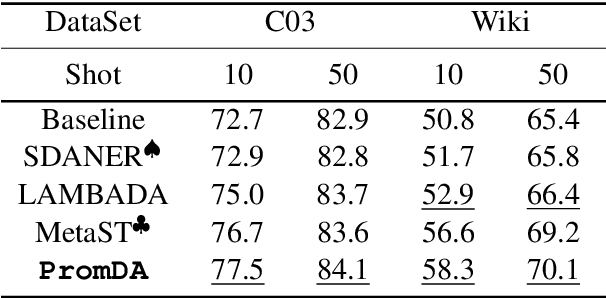
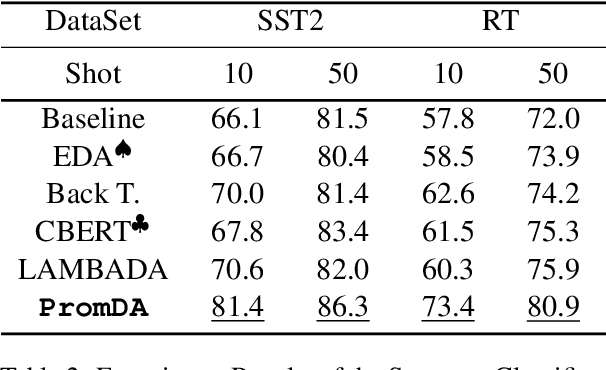

This paper focuses on the Data Augmentation for low-resource Natural Language Understanding (NLU) tasks. We propose Prompt-based D}ata Augmentation model (PromDA) which only trains small-scale Soft Prompt (i.e., a set of trainable vectors) in the frozen Pre-trained Language Models (PLMs). This avoids human effort in collecting unlabeled in-domain data and maintains the quality of generated synthetic data. In addition, PromDA generates synthetic data via two different views and filters out the low-quality data using NLU models. Experiments on four benchmarks show that synthetic data produced by PromDA successfully boost up the performance of NLU models which consistently outperform several competitive baseline models, including a state-of-the-art semi-supervised model using unlabeled in-domain data. The synthetic data from PromDA are also complementary with unlabeled in-domain data. The NLU models can be further improved when they are combined for training.
TegTok: Augmenting Text Generation via Task-specific and Open-world Knowledge
Mar 16, 2022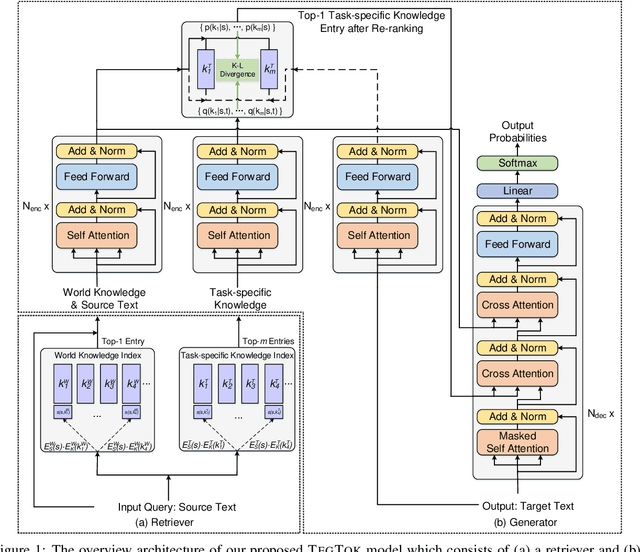
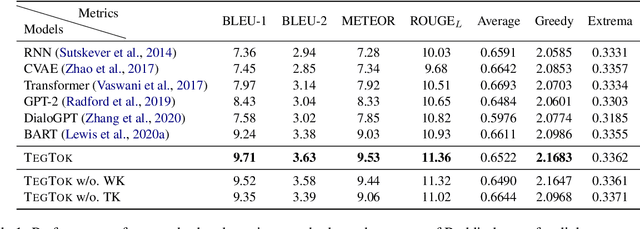
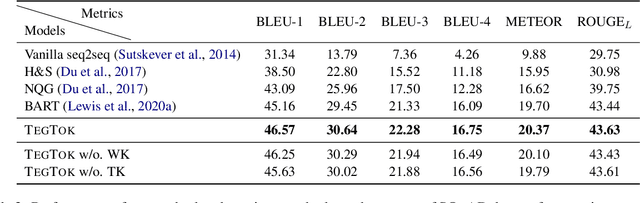
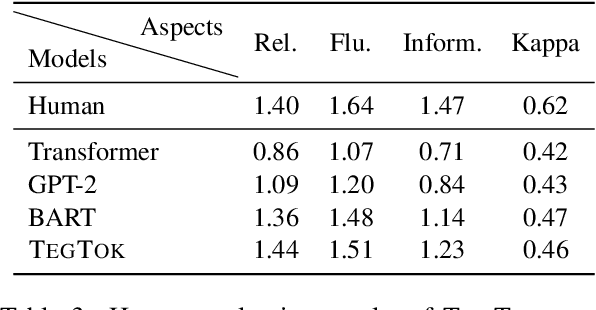
Generating natural and informative texts has been a long-standing problem in NLP. Much effort has been dedicated into incorporating pre-trained language models (PLMs) with various open-world knowledge, such as knowledge graphs or wiki pages. However, their ability to access and manipulate the task-specific knowledge is still limited on downstream tasks, as this type of knowledge is usually not well covered in PLMs and is hard to acquire. To address the problem, we propose augmenting TExt Generation via Task-specific and Open-world Knowledge (TegTok) in a unified framework. Our model selects knowledge entries from two types of knowledge sources through dense retrieval and then injects them into the input encoding and output decoding stages respectively on the basis of PLMs. With the help of these two types of knowledge, our model can learn what and how to generate. Experiments on two text generation tasks of dialogue generation and question generation, and on two datasets show that our method achieves better performance than various baseline models.
HeterMPC: A Heterogeneous Graph Neural Network for Response Generation in Multi-Party Conversations
Mar 16, 2022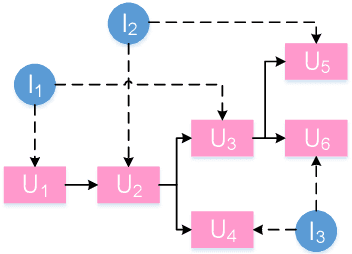
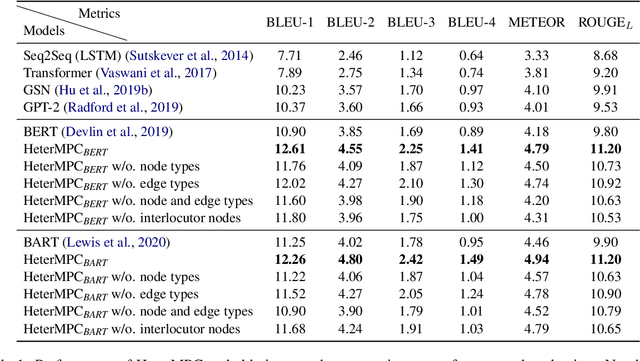
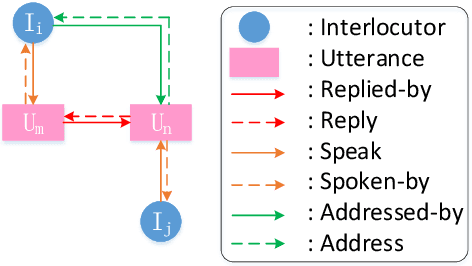
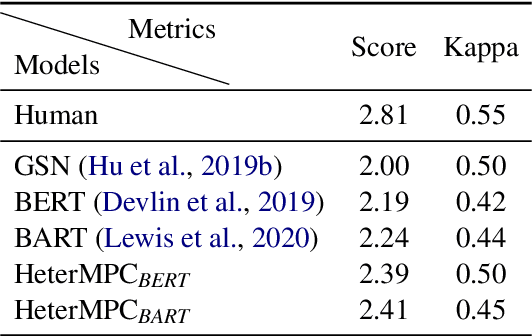
Recently, various response generation models for two-party conversations have achieved impressive improvements, but less effort has been paid to multi-party conversations (MPCs) which are more practical and complicated. Compared with a two-party conversation where a dialogue context is a sequence of utterances, building a response generation model for MPCs is more challenging, since there exist complicated context structures and the generated responses heavily rely on both interlocutors (i.e., speaker and addressee) and history utterances. To address these challenges, we present HeterMPC, a heterogeneous graph-based neural network for response generation in MPCs which models the semantics of utterances and interlocutors simultaneously with two types of nodes in a graph. Besides, we also design six types of meta relations with node-edge-type-dependent parameters to characterize the heterogeneous interactions within the graph. Through multi-hop updating, HeterMPC can adequately utilize the structural knowledge of conversations for response generation. Experimental results on the Ubuntu Internet Relay Chat (IRC) channel benchmark show that HeterMPC outperforms various baseline models for response generation in MPCs.
PCL: Peer-Contrastive Learning with Diverse Augmentations for Unsupervised Sentence Embeddings
Jan 28, 2022
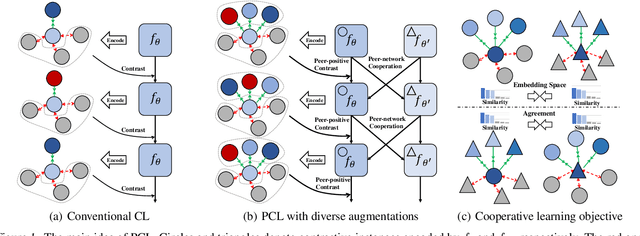
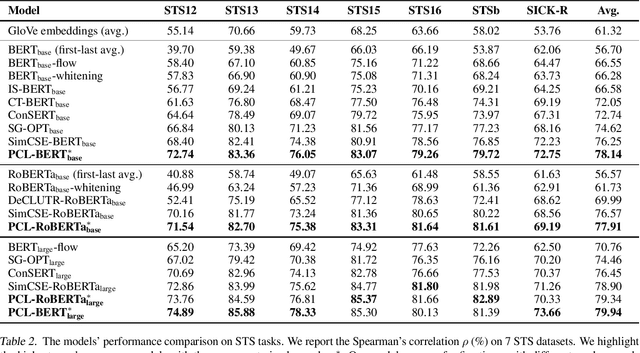
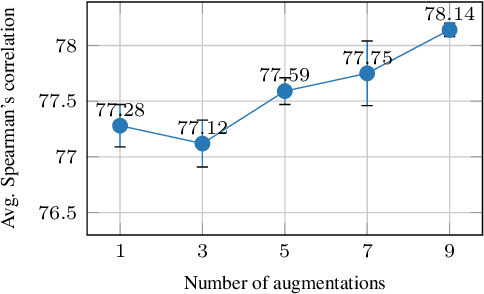
Learning sentence embeddings in an unsupervised manner is fundamental in natural language processing. Recent common practice is to couple pre-trained language models with unsupervised contrastive learning, whose success relies on augmenting a sentence with a semantically-close positive instance to construct contrastive pairs. Nonetheless, existing approaches usually depend on a mono-augmenting strategy, which causes learning shortcuts towards the augmenting biases and thus corrupts the quality of sentence embeddings. A straightforward solution is resorting to more diverse positives from a multi-augmenting strategy, while an open question remains about how to unsupervisedly learn from the diverse positives but with uneven augmenting qualities in the text field. As one answer, we propose a novel Peer-Contrastive Learning (PCL) with diverse augmentations. PCL constructs diverse contrastive positives and negatives at the group level for unsupervised sentence embeddings. PCL can perform peer-positive contrast as well as peer-network cooperation, which offers an inherent anti-bias ability and an effective way to learn from diverse augmentations. Experiments on STS benchmarks verify the effectiveness of our PCL against its competitors in unsupervised sentence embeddings.
Building an Efficient and Effective Retrieval-based Dialogue System via Mutual Learning
Oct 01, 2021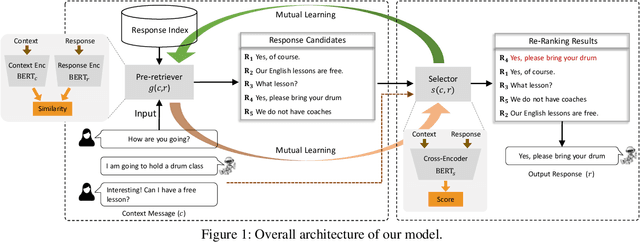
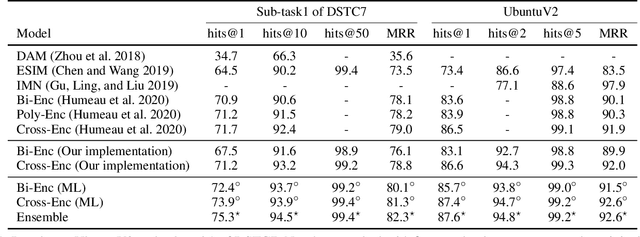
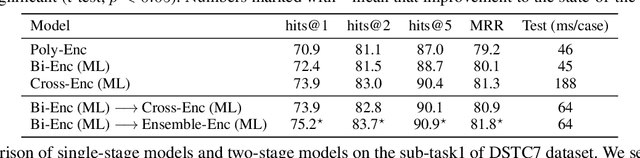
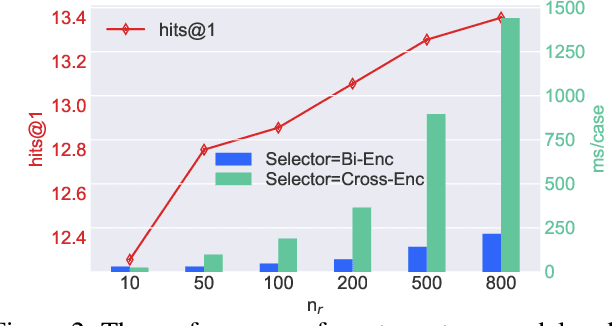
Establishing retrieval-based dialogue systems that can select appropriate responses from the pre-built index has gained increasing attention from researchers. For this task, the adoption of pre-trained language models (such as BERT) has led to remarkable progress in a number of benchmarks. There exist two common approaches, including cross-encoders which perform full attention over the inputs, and bi-encoders that encode the context and response separately. The former gives considerable improvements in accuracy but is often inapplicable in practice for large-scale retrieval given the cost of the full attention required for each sample at test time. The latter is efficient for billions of indexes but suffers from sub-optimal performance. In this work, we propose to combine the best of both worlds to build a retrieval system. Specifically, we employ a fast bi-encoder to replace the traditional feature-based pre-retrieval model (such as BM25) and set the response re-ranking model as a more complicated architecture (such as cross-encoder). To further improve the effectiveness of our framework, we train the pre-retrieval model and the re-ranking model at the same time via mutual learning, which enables two models to learn from each other throughout the training process. We conduct experiments on two benchmarks and evaluation results demonstrate the efficiency and effectiveness of our proposed framework.