 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Long-context End-to-end Speech Recognition Using Context-expanded Transformers
Apr 19, 2021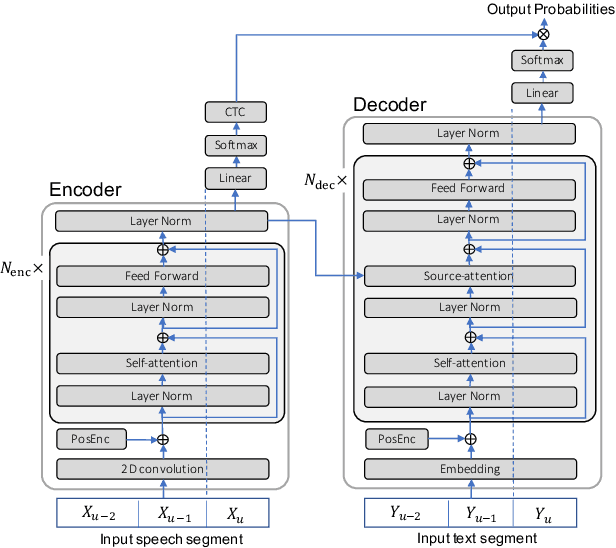
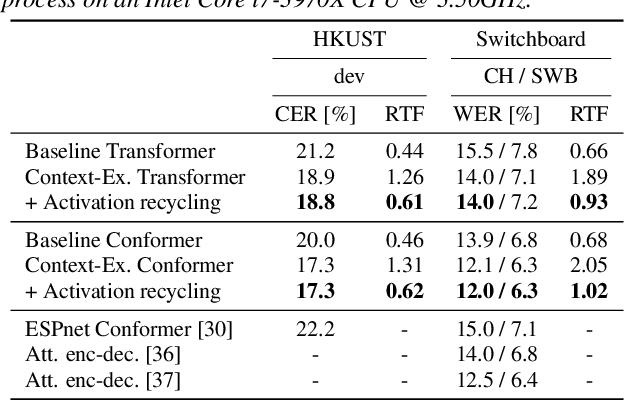
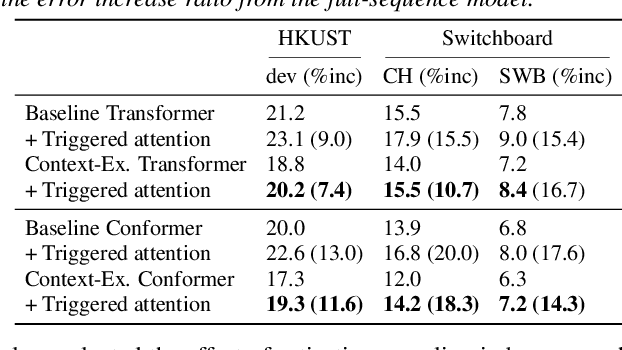
This paper addresses end-to-end automatic speech recognition (ASR) for long audio recordings such as lecture and conversational speeches. Most end-to-end ASR models are designed to recognize independent utterances, but contextual information (e.g., speaker or topic) over multiple utterances is known to be useful for ASR. In our prior work, we proposed a context-expanded Transformer that accepts multiple consecutive utterances at the same time and predicts an output sequence for the last utterance, achieving 5-15% relative error reduction from utterance-based baselines in lecture and conversational ASR benchmarks. Although the results have shown remarkable performance gain, there is still potential to further improve the model architecture and the decoding process. In this paper, we extend our prior work by (1) introducing the Conformer architecture to further improve the accuracy, (2) accelerating the decoding process with a novel activation recycling technique, and (3) enabling streaming decoding with triggered attention. We demonstrate that the extended Transformer provides state-of-the-art end-to-end ASR performance, obtaining a 17.3% character error rate for the HKUST dataset and 12.0%/6.3% word error rates for the Switchboard-300 Eval2000 CallHome/Switchboard test sets. The new decoding method reduces decoding time by more than 50% and further enables streaming ASR with limited accuracy degradation.
Multi-Pass Transformer for Machine Translation
Sep 23, 2020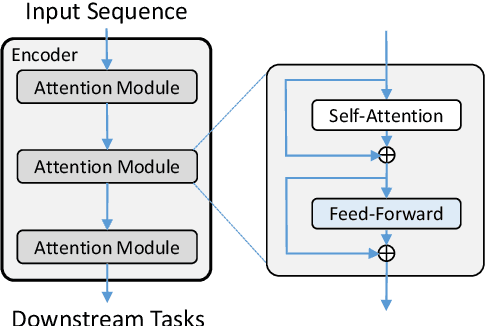
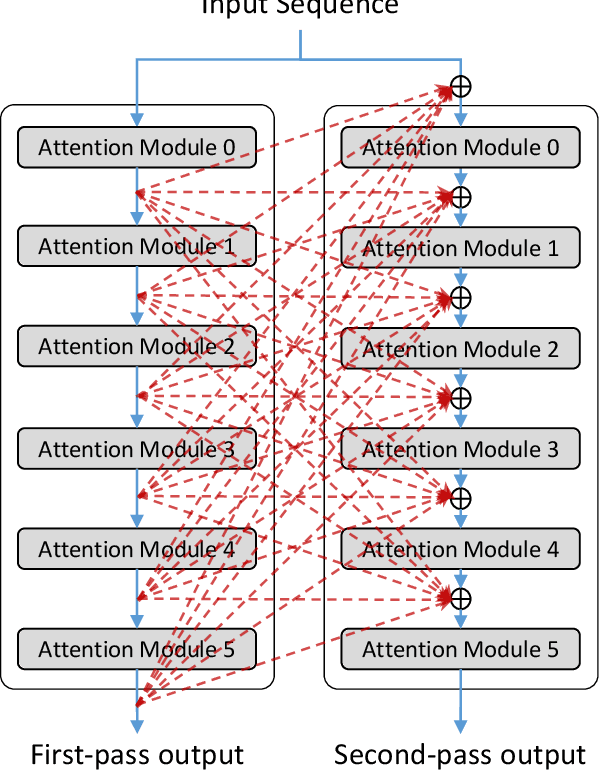
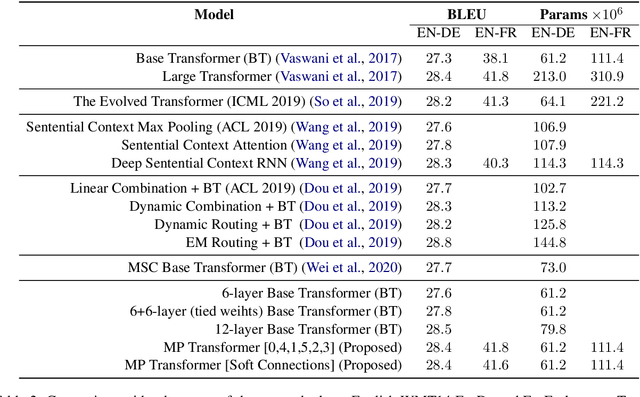
In contrast with previous approaches where information flows only towards deeper layers of a stack, we consider a multi-pass transformer (MPT) architecture in which earlier layers are allowed to process information in light of the output of later layers. To maintain a directed acyclic graph structure, the encoder stack of a transformer is repeated along a new multi-pass dimension, keeping the parameters tied, and information is allowed to proceed unidirectionally both towards deeper layers within an encoder stack and towards any layer of subsequent stacks. We consider both soft (i.e., continuous) and hard (i.e., discrete) connections between parallel encoder stacks, relying on a neural architecture search to find the best connection pattern in the hard case. We perform an extensive ablation study of the proposed MPT architecture and compare it with other state-of-the-art transformer architectures. Surprisingly, Base Transformer equipped with MPT can surpass the performance of Large Transformer on the challenging machine translation En-De and En-Fr datasets. In the hard connection case, the optimal connection pattern found for En-De also leads to improved performance for En-Fr.
Spatio-Temporal Scene Graphs for Video Dialog
Jul 08, 2020
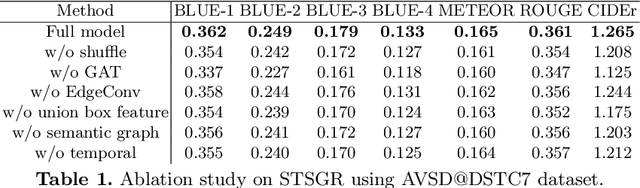
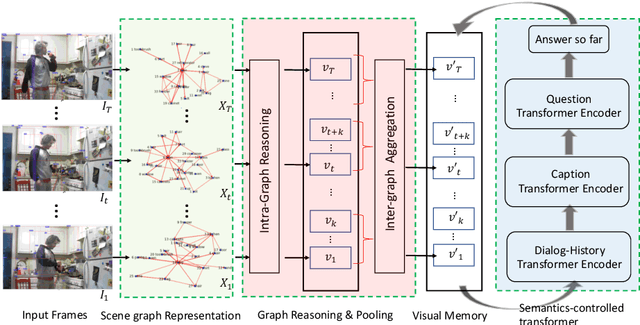
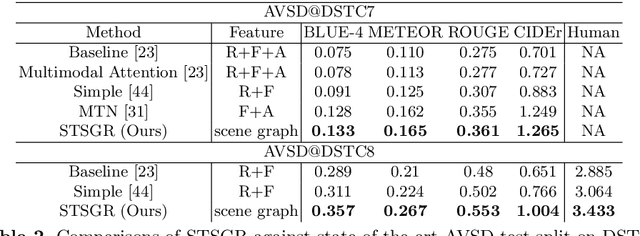
The Audio-Visual Scene-aware Dialog (AVSD) task requires an agent to indulge in a natural conversation with a human about a given video. Specifically, apart from the video frames, the agent receives the audio, brief captions, and a dialog history, and the task is to produce the correct answer to a question about the video. Due to the diversity in the type of inputs, this task poses a very challenging multimodal reasoning problem. Current approaches to AVSD either use global video-level features or those from a few sampled frames, and thus lack the ability to explicitly capture relevant visual regions or their interactions for answer generation. To this end, we propose a novel spatio-temporal scene graph representation (STSGR) modeling fine-grained information flows within videos. Specifically, on an input video sequence, STSGR (i) creates a two-stream visual and semantic scene graph on every frame, (ii) conducts intra-graph reasoning using node and edge convolutions generating visual memories, and (iii) applies inter-graph aggregation to capture their temporal evolutions. These visual memories are then combined with other modalities and the question embeddings using a novel semantics-controlled multi-head shuffled transformer, which then produces the answer recursively. Our entire pipeline is trained end-to-end. We present experiments on the AVSD dataset and demonstrate state-of-the-art results. A human evaluation on the quality of our generated answers shows 12% relative improvement against prior methods.
Multi-Layer Content Interaction Through Quaternion Product For Visual Question Answering
Feb 16, 2020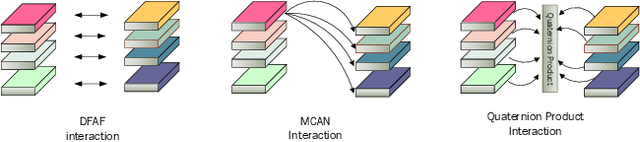
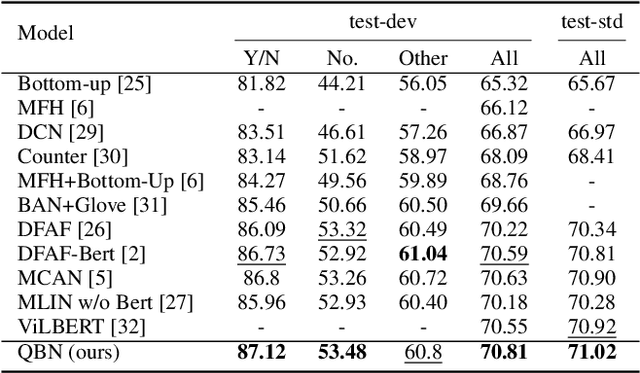
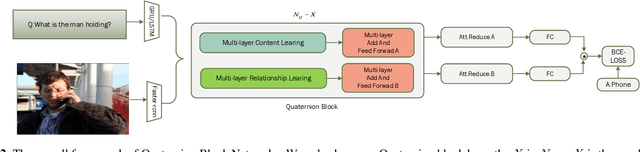
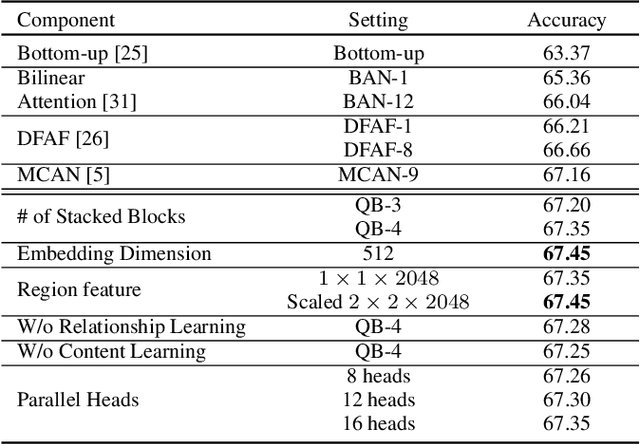
Multi-modality fusion technologies have greatly improved the performance of neural network-based Video Description/Caption, Visual Question Answering (VQA) and Audio Visual Scene-aware Dialog (AVSD) over the recent years. Most previous approaches only explore the last layers of multiple layer feature fusion while omitting the importance of intermediate layers. To solve the issue for the intermediate layers, we propose an efficient Quaternion Block Network (QBN) to learn interaction not only for the last layer but also for all intermediate layers simultaneously. In our proposed QBN, we use the holistic text features to guide the update of visual features. In the meantime, Hamilton quaternion products can efficiently perform information flow from higher layers to lower layers for both visual and text modalities. The evaluation results show our QBN improved the performance on VQA 2.0, even though using surpass large scale BERT or visual BERT pre-trained models. Extensive ablation study has been carried out to testify the influence of each proposed module in this study.
Spatio-Temporal Ranked-Attention Networks for Video Captioning
Jan 17, 2020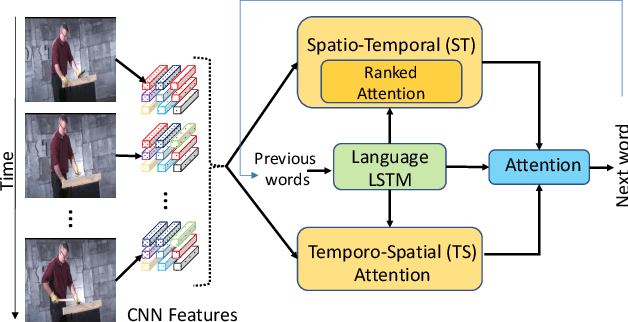
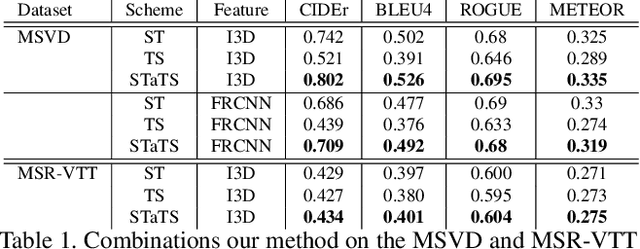
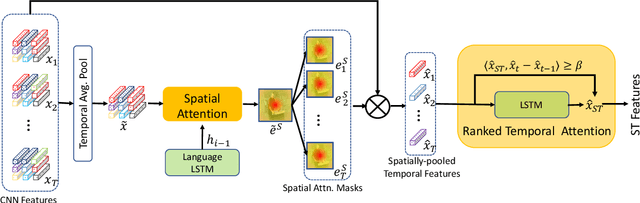
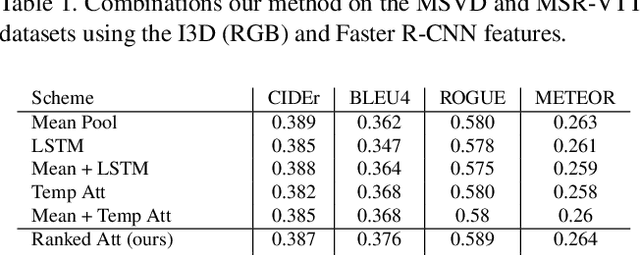
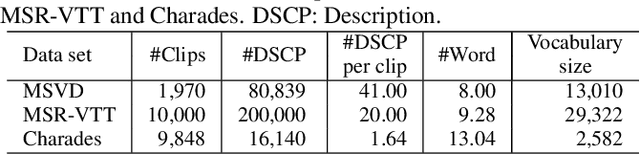
Generating video descriptions automatically is a challenging task that involves a complex interplay between spatio-temporal visual features and language models. Given that videos consist of spatial (frame-level) features and their temporal evolutions, an effective captioning model should be able to attend to these different cues selectively. To this end, we propose a Spatio-Temporal and Temporo-Spatial (STaTS) attention model which, conditioned on the language state, hierarchically combines spatial and temporal attention to videos in two different orders: (i) a spatio-temporal (ST) sub-model, which first attends to regions that have temporal evolution, then temporally pools the features from these regions; and (ii) a temporo-spatial (TS) sub-model, which first decides a single frame to attend to, then applies spatial attention within that frame. We propose a novel LSTM-based temporal ranking function, which we call ranked attention, for the ST model to capture action dynamics. Our entire framework is trained end-to-end. We provide experiments on two benchmark datasets: MSVD and MSR-VTT. Our results demonstrate the synergy between the ST and TS modules, outperforming recent state-of-the-art methods.
The Eighth Dialog System Technology Challenge
Nov 14, 2019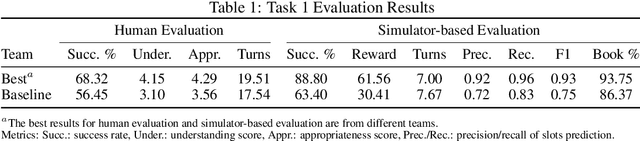
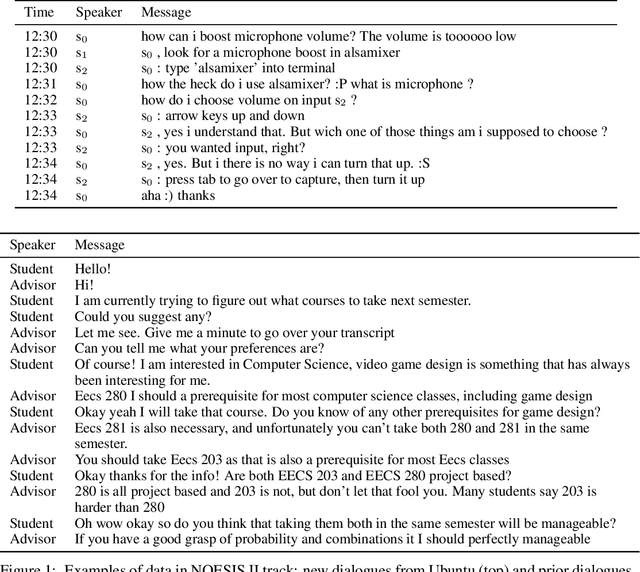
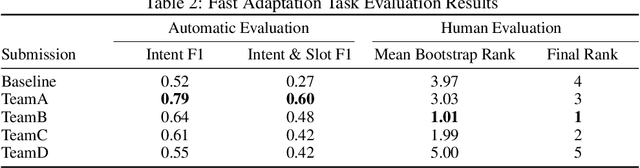
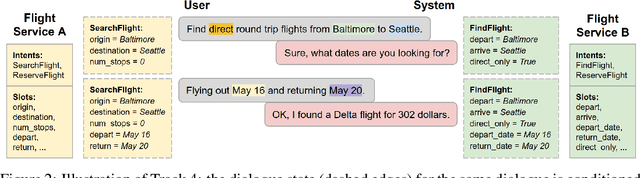
This paper introduces the Eighth Dialog System Technology Challenge. In line with recent challenges, the eighth edition focuses on applying end-to-end dialog technologies in a pragmatic way for multi-domain task-completion, noetic response selection, audio visual scene-aware dialog, and schema-guided dialog state tracking tasks. This paper describes the task definition, provided datasets, and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
Audio-Visual Scene-Aware Dialog
Jan 25, 2019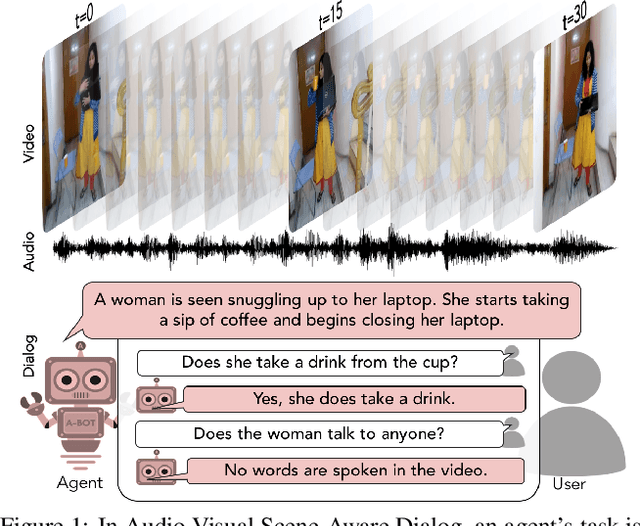
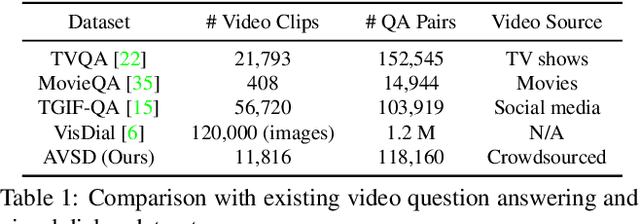


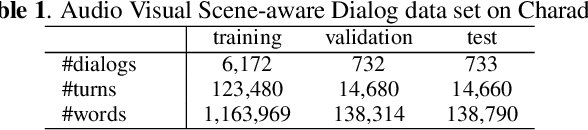
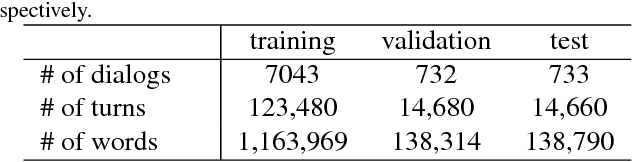
We introduce the task of scene-aware dialog. Given a follow-up question in an ongoing dialog about a video, our goal is to generate a complete and natural response to a question given (a) an input video, and (b) the history of previous turns in the dialog. To succeed, agents must ground the semantics in the video and leverage contextual cues from the history of the dialog to answer the question. To benchmark this task, we introduce the Audio Visual Scene-Aware Dialog (AVSD) dataset. For each of more than 11,000 videos of human actions for the Charades dataset. Our dataset contains a dialog about the video, plus a final summary of the video by one of the dialog participants. We train several baseline systems for this task and evaluate the performance of the trained models using several qualitative and quantitative metrics. Our results indicate that the models must comprehend all the available inputs (video, audio, question and dialog history) to perform well on this dataset.
Dialog System Technology Challenge 7
Jan 11, 2019

This paper introduces the Seventh Dialog System Technology Challenges (DSTC), which use shared datasets to explore the problem of building dialog systems. Recently, end-to-end dialog modeling approaches have been applied to various dialog tasks. The seventh DSTC (DSTC7) focuses on developing technologies related to end-to-end dialog systems for (1) sentence selection, (2) sentence generation and (3) audio visual scene aware dialog. This paper summarizes the overall setup and results of DSTC7, including detailed descriptions of the different tracks and provided datasets. We also describe overall trends in the submitted systems and the key results. Each track introduced new datasets and participants achieved impressive results using state-of-the-art end-to-end technologies.
End-to-End Audio Visual Scene-Aware Dialog using Multimodal Attention-Based Video Features
Jun 30, 2018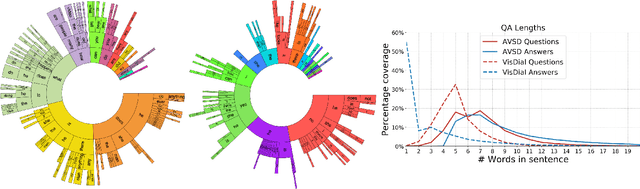
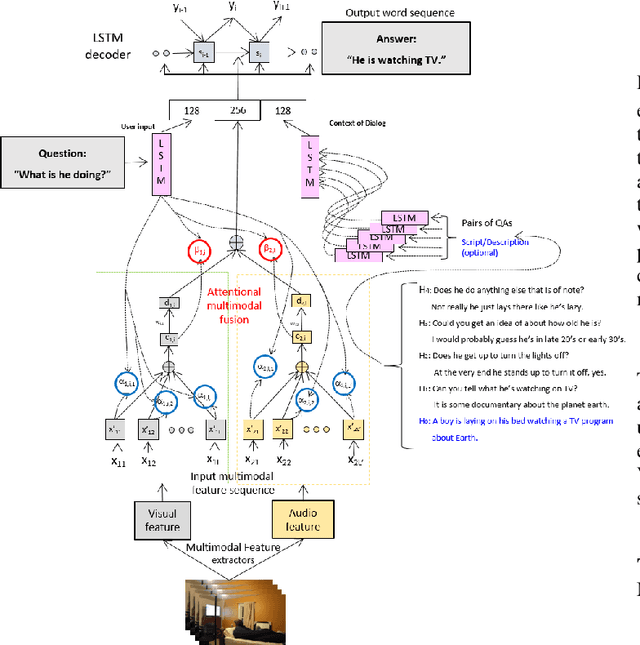
Dialog systems need to understand dynamic visual scenes in order to have conversations with users about the objects and events around them. Scene-aware dialog systems for real-world applications could be developed by integrating state-of-the-art technologies from multiple research areas, including: end-to-end dialog technologies, which generate system responses using models trained from dialog data; visual question answering (VQA) technologies, which answer questions about images using learned image features; and video description technologies, in which descriptions/captions are generated from videos using multimodal information. We introduce a new dataset of dialogs about videos of human behaviors. Each dialog is a typed conversation that consists of a sequence of 10 question-and-answer(QA) pairs between two Amazon Mechanical Turk (AMT) workers. In total, we collected dialogs on roughly 9,000 videos. Using this new dataset for Audio Visual Scene-aware dialog (AVSD), we trained an end-to-end conversation model that generates responses in a dialog about a video. Our experiments demonstrate that using multimodal features that were developed for multimodal attention-based video description enhances the quality of generated dialog about dynamic scenes (videos). Our dataset, model code and pretrained models will be publicly available for a new Video Scene-Aware Dialog challenge.
Audio Visual Scene-Aware Dialog Challenge at DSTC7
Jun 01, 2018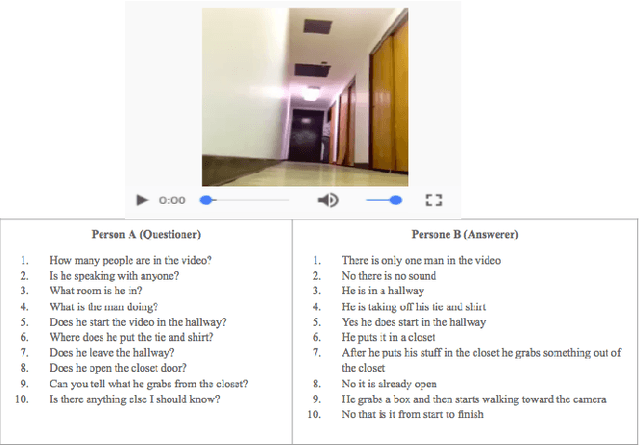
Scene-aware dialog systems will be able to have conversations with users about the objects and events around them. Progress on such systems can be made by integrating state-of-the-art technologies from multiple research areas including end-to-end dialog systems visual dialog, and video description. We introduce the Audio Visual Scene Aware Dialog (AVSD) challenge and dataset. In this challenge, which is one track of the 7th Dialog System Technology Challenges (DSTC7) workshop1, the task is to build a system that generates responses in a dialog about an input video