 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Socio-Temporal Graphs for Multi-Agent Trajectory Prediction
Dec 22, 2023



In order to predict a pedestrian's trajectory in a crowd accurately, one has to take into account her/his underlying socio-temporal interactions with other pedestrians consistently. Unlike existing work that represents the relevant information separately, partially, or implicitly, we propose a complete representation for it to be fully and explicitly captured and analyzed. In particular, we introduce a Directed Acyclic Graph-based structure, which we term Socio-Temporal Graph (STG), to explicitly capture pair-wise socio-temporal interactions among a group of people across both space and time. Our model is built on a time-varying generative process, whose latent variables determine the structure of the STGs. We design an attention-based model named STGformer that affords an end-to-end pipeline to learn the structure of the STGs for trajectory prediction. Our solution achieves overall state-of-the-art prediction accuracy in two large-scale benchmark datasets. Our analysis shows that a person's past trajectory is critical for predicting another person's future path. Our model learns this relationship with a strong notion of socio-temporal localities. Statistics show that utilizing this information explicitly for prediction yields a noticeable performance gain with respect to the trajectory-only approaches.
A Survey of Deep Reinforcement Learning Algorithms for Motion Planning and Control of Autonomous Vehicles
Jun 01, 2021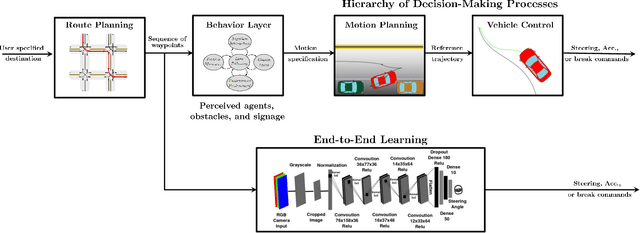
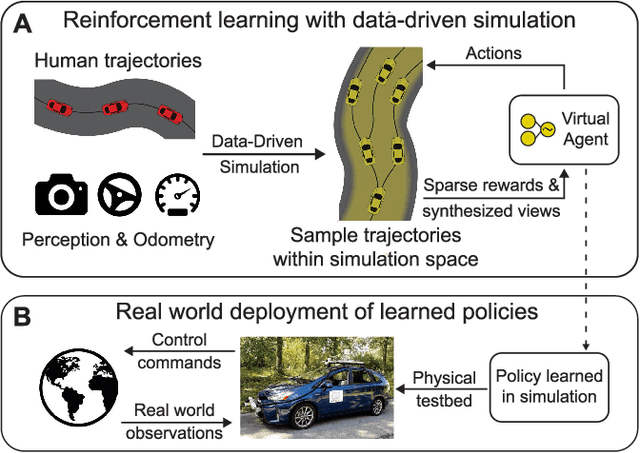

In this survey, we systematically summarize the current literature on studies that apply reinforcement learning (RL) to the motion planning and control of autonomous vehicles. Many existing contributions can be attributed to the pipeline approach, which consists of many hand-crafted modules, each with a functionality selected for the ease of human interpretation. However, this approach does not automatically guarantee maximal performance due to the lack of a system-level optimization. Therefore, this paper also presents a growing trend of work that falls into the end-to-end approach, which typically offers better performance and smaller system scales. However, their performance also suffers from the lack of expert data and generalization issues. Finally, the remaining challenges applying deep RL algorithms on autonomous driving are summarized, and future research directions are also presented to tackle these challenges.
Meta-Adversarial Inverse Reinforcement Learning for Decision-making Tasks
Mar 25, 2021
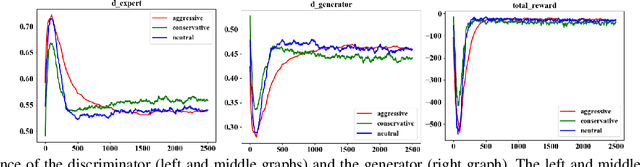
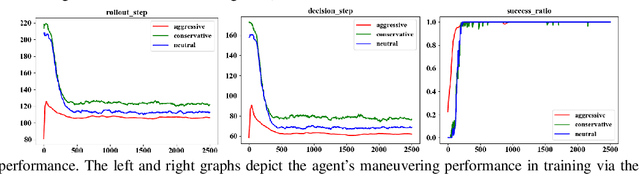
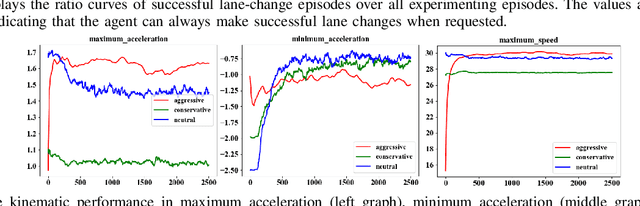
Learning from demonstrations has made great progress over the past few years. However, it is generally data hungry and task specific. In other words, it requires a large amount of data to train a decent model on a particular task, and the model often fails to generalize to new tasks that have a different distribution. In practice, demonstrations from new tasks will be continuously observed and the data might be unlabeled or only partially labeled. Therefore, it is desirable for the trained model to adapt to new tasks that have limited data samples available. In this work, we build an adaptable imitation learning model based on the integration of Meta-learning and Adversarial Inverse Reinforcement Learning (Meta-AIRL). We exploit the adversarial learning and inverse reinforcement learning mechanisms to learn policies and reward functions simultaneously from available training tasks and then adapt them to new tasks with the meta-learning framework. Simulation results show that the adapted policy trained with Meta-AIRL can effectively learn from limited number of demonstrations, and quickly reach the performance comparable to that of the experts on unseen tasks.
Meta Reinforcement Learning-Based Lane Change Strategy for Autonomous Vehicles
Aug 28, 2020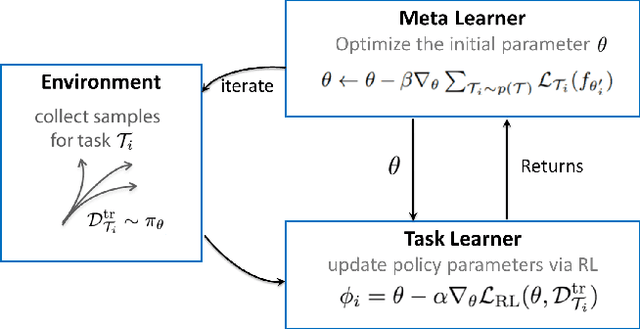
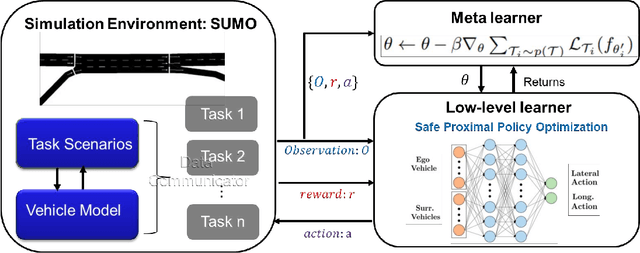
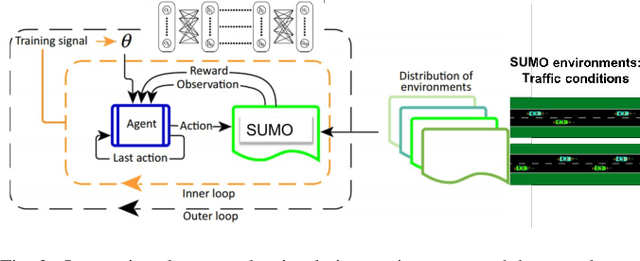
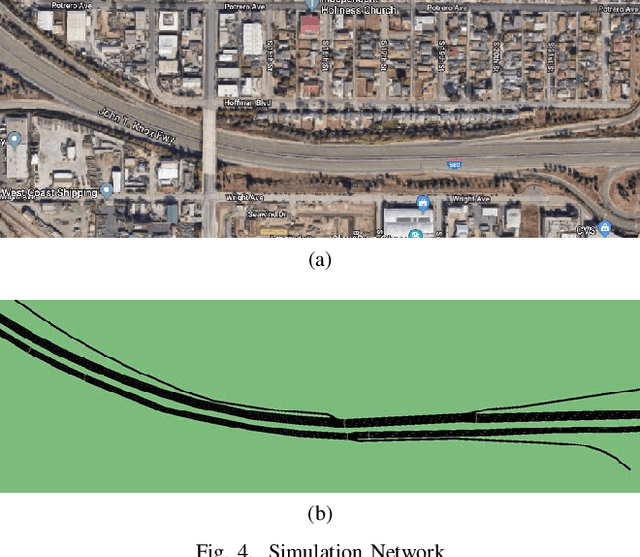
Recent advances in supervised learning and reinforcement learning have provided new opportunities to apply related methodologies to automated driving. However, there are still challenges to achieve automated driving maneuvers in dynamically changing environments. Supervised learning algorithms such as imitation learning can generalize to new environments by training on a large amount of labeled data, however, it can be often impractical or cost-prohibitive to obtain sufficient data for each new environment. Although reinforcement learning methods can mitigate this data-dependency issue by training the agent in a trial-and-error way, they still need to re-train policies from scratch when adapting to new environments. In this paper, we thus propose a meta reinforcement learning (MRL) method to improve the agent's generalization capabilities to make automated lane-changing maneuvers at different traffic environments, which are formulated as different traffic congestion levels. Specifically, we train the model at light to moderate traffic densities and test it at a new heavy traffic density condition. We use both collision rate and success rate to quantify the safety and effectiveness of the proposed model. A benchmark model is developed based on a pretraining method, which uses the same network structure and training tasks as our proposed model for fair comparison. The simulation results shows that the proposed method achieves an overall success rate up to 20% higher than the benchmark model when it is generalized to the new environment of heavy traffic density. The collision rate is also reduced by up to 18% than the benchmark model. Finally, the proposed model shows more stable and efficient generalization capabilities adapting to the new environment, and it can achieve 100% successful rate and 0% collision rate with only a few steps of gradient updates.
Automated Lane Change Strategy using Proximal Policy Optimization-based Deep Reinforcement Learning
Feb 07, 2020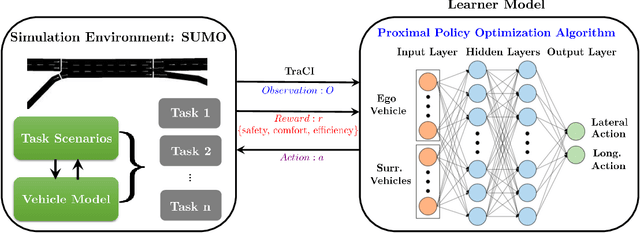
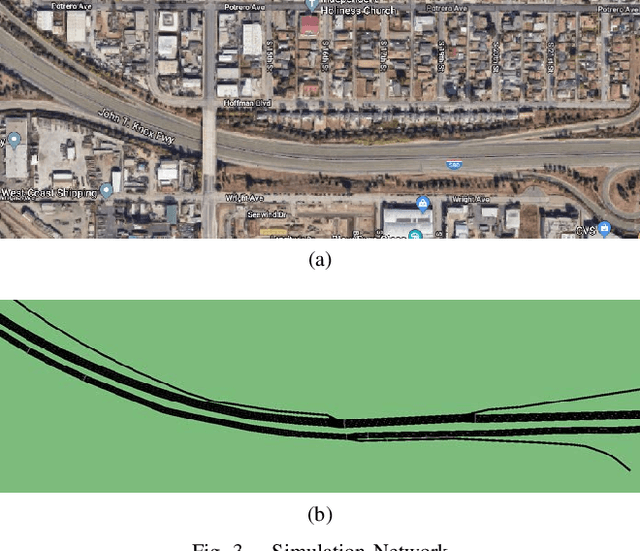
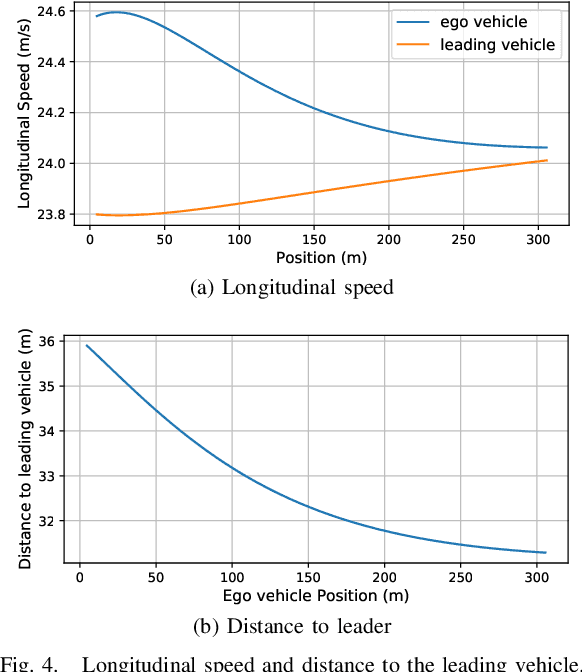
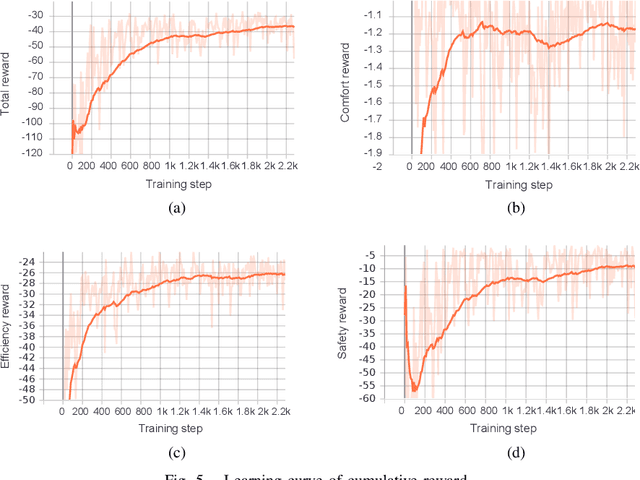
Lane-change maneuvers are commonly executed by drivers to follow a certain routing plan, overtake a slower vehicle, adapt to a merging lane ahead, etc. However, improper lane change behaviors can be a major cause of traffic flow disruptions and even crashes. While many rule-based methods have been proposed to solve lane change problems for autonomous driving, they tend to exhibit limited performance due to the uncertainty and complexity of the driving environment. Machine learning-based methods offer an alternative approach, as Deep reinforcement learning (DRL) has shown promising success in many application domains including robotic manipulation, navigation, and playing video games. However, applying DRL for autonomous driving still faces many practical challenges in terms of slow learning rates, sample inefficiency, and non-stationary trajectories. In this study, we propose an automated lane change strategy using proximal policy optimization-based deep reinforcement learning, which shows great advantage in learning efficiency while maintaining stable performance. The trained agent is able to learn a smooth, safe, and efficient driving policy to determine lane-change decisions (i.e. when and how) even in dense traffic scenarios. The effectiveness of the proposed policy is validated using task success rate and collision rate, which demonstrates the lane change maneuvers can be efficiently learned and executed in a safe, smooth and efficient manner.
Quadratic Q-network for Learning Continuous Control for Autonomous Vehicles
Nov 29, 2019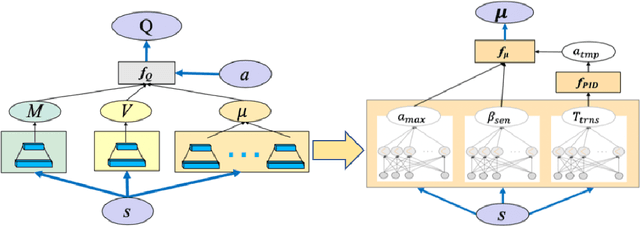

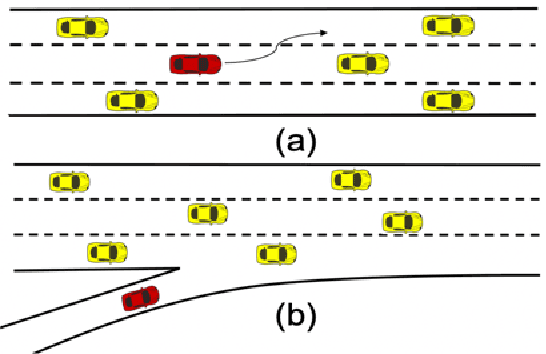

Reinforcement Learning algorithms have recently been proposed to learn time-sequential control policies in the field of autonomous driving. Direct applications of Reinforcement Learning algorithms with discrete action space will yield unsatisfactory results at the operational level of driving where continuous control actions are actually required. In addition, the design of neural networks often fails to incorporate the domain knowledge of the targeting problem such as the classical control theories in our case. In this paper, we propose a hybrid model by combining Q-learning and classic PID (Proportion Integration Differentiation) controller for handling continuous vehicle control problems under dynamic driving environment. Particularly, instead of using a big neural network as Q-function approximation, we design a Quadratic Q-function over actions with multiple simple neural networks for finding optimal values within a continuous space. We also build an action network based on the domain knowledge of the control mechanism of a PID controller to guide the agent to explore optimal actions more efficiently.We test our proposed approach in simulation under two common but challenging driving situations, the lane change scenario and ramp merge scenario. Results show that the autonomous vehicle agent can successfully learn a smooth and efficient driving behavior in both situations.
Adversarial Inverse Reinforcement Learning for Decision Making in Autonomous Driving
Nov 19, 2019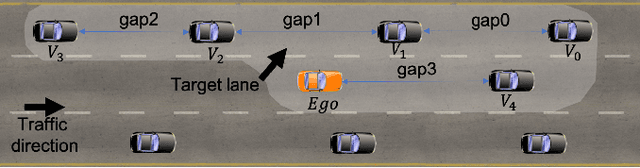
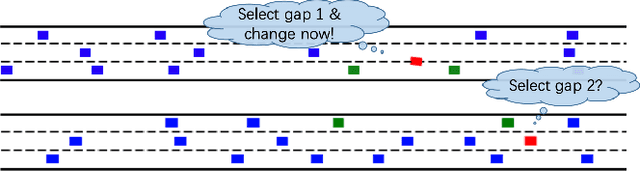
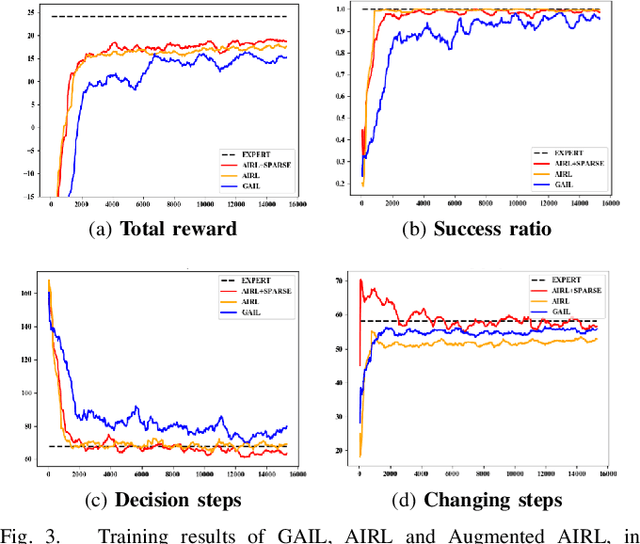
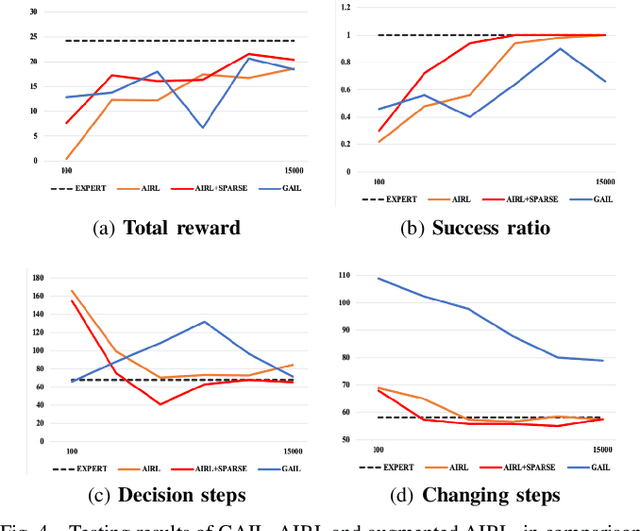
Generative Adversarial Imitation Learning (GAIL) is an efficient way to learn sequential control strategies from demonstration. Adversarial Inverse Reinforcement Learning (AIRL) is similar to GAIL but also learns a reward function at the same time and has better training stability. In previous work, however, AIRL has mostly been demonstrated on robotic control in artificial environments. In this paper, we apply AIRL to a practical and challenging problem -- the decision-making in autonomous driving, and also augment AIRL with a semantic reward to improve its performance. We use four metrics to evaluate its learning performance in a simulated driving environment. Results show that the vehicle agent can learn decent decision-making behaviors from scratch, and can reach a level of performance comparable with that of an expert. Additionally, the comparison with GAIL shows that AIRL converges faster, achieves better and more stable performance than GAIL.
Intention-aware Long Horizon Trajectory Prediction of Surrounding Vehicles using Dual LSTM Networks
Jun 06, 2019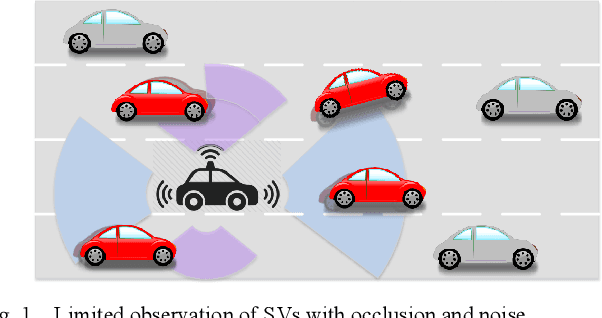
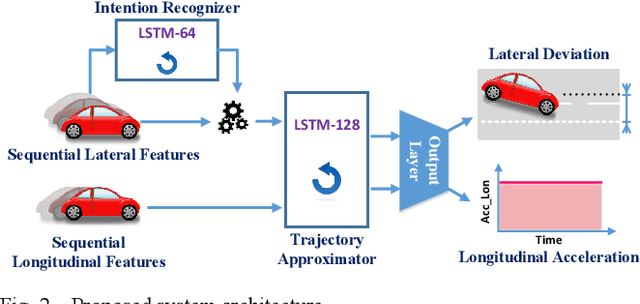
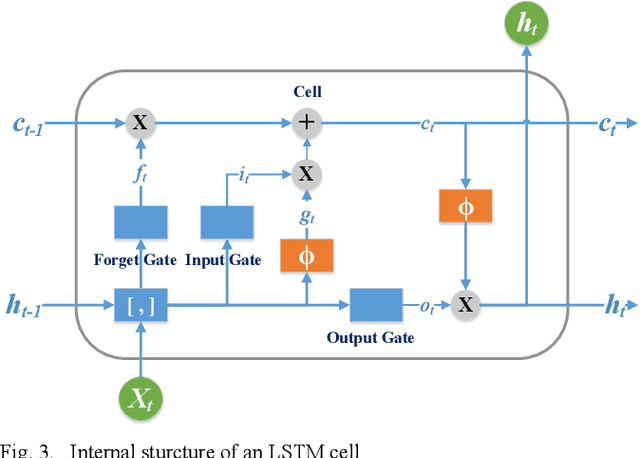
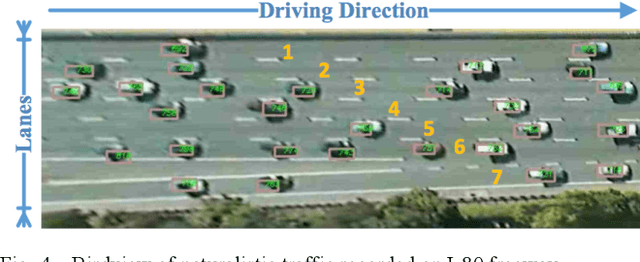
As autonomous vehicles (AVs) need to interact with other road users, it is of importance to comprehensively understand the dynamic traffic environment, especially the future possible trajectories of surrounding vehicles. This paper presents an algorithm for long-horizon trajectory prediction of surrounding vehicles using a dual long short term memory (LSTM) network, which is capable of effectively improving prediction accuracy in strongly interactive driving environments. In contrast to traditional approaches which require trajectory matching and manual feature selection, this method can automatically learn high-level spatial-temporal features of driver behaviors from naturalistic driving data through sequence learning. By employing two blocks of LSTMs, the proposed method feeds the sequential trajectory to the first LSTM for driver intention recognition as an intermediate indicator, which is immediately followed by a second LSTM for future trajectory prediction. Test results from real-world highway driving data show that the proposed method can, in comparison to state-of-art methods, output more accurate and reasonable estimate of different future trajectories over 5s time horizon with root mean square error (RMSE) for longitudinal and lateral prediction less than 5.77m and 0.49m, respectively.
Continuous Control for Automated Lane Change Behavior Based on Deep Deterministic Policy Gradient Algorithm
Jun 05, 2019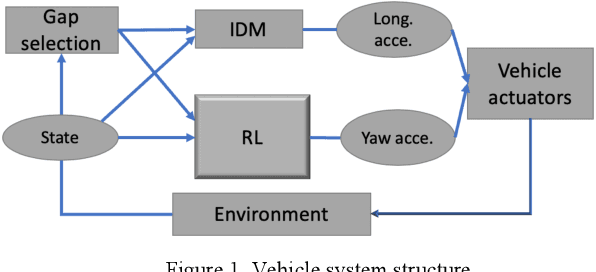
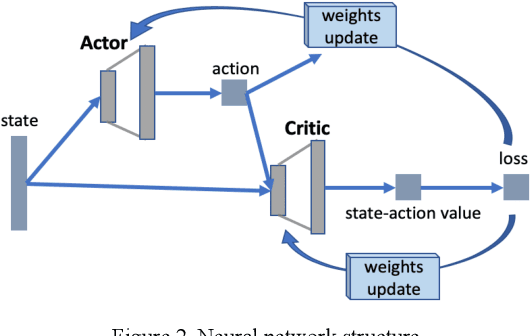
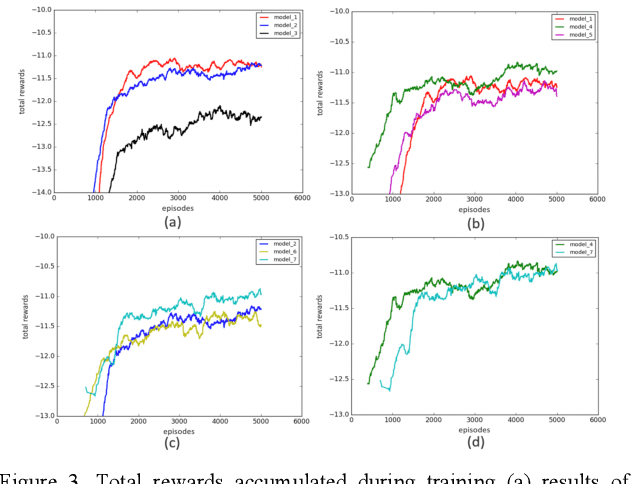
Lane change is a challenging task which requires delicate actions to ensure safety and comfort. Some recent studies have attempted to solve the lane-change control problem with Reinforcement Learning (RL), yet the action is confined to discrete action space. To overcome this limitation, we formulate the lane change behavior with continuous action in a model-free dynamic driving environment based on Deep Deterministic Policy Gradient (DDPG). The reward function, which is critical for learning the optimal policy, is defined by control values, position deviation status, and maneuvering time to provide the RL agent informative signals. The RL agent is trained from scratch without resorting to any prior knowledge of the environment and vehicle dynamics since they are not easy to obtain. Seven models under different hyperparameter settings are compared. A video showing the learning progress of the driving behavior is available. It demonstrates the RL vehicle agent initially runs out of road boundary frequently, but eventually has managed to smoothly and stably change to the target lane with a success rate of 100% under diverse driving situations in simulation.
Behavior Planning of Autonomous Cars with Social Perception
May 02, 2019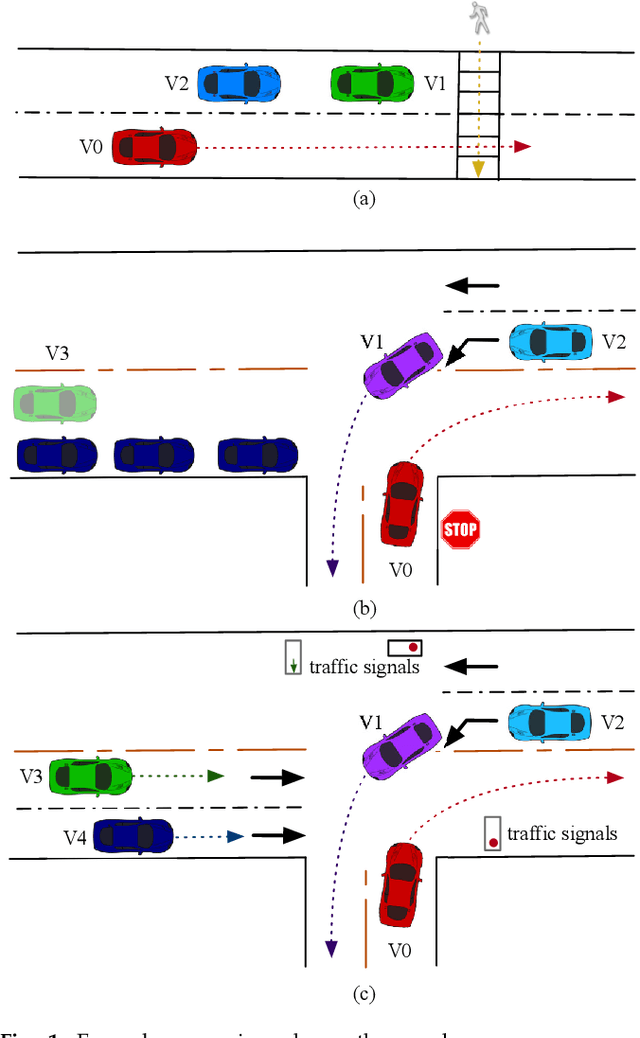
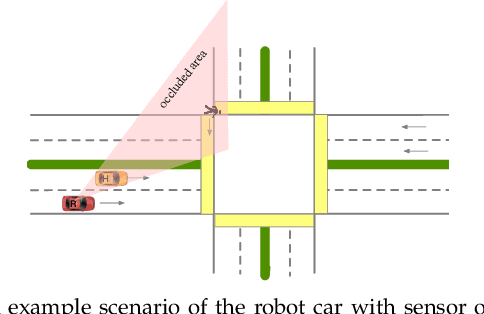
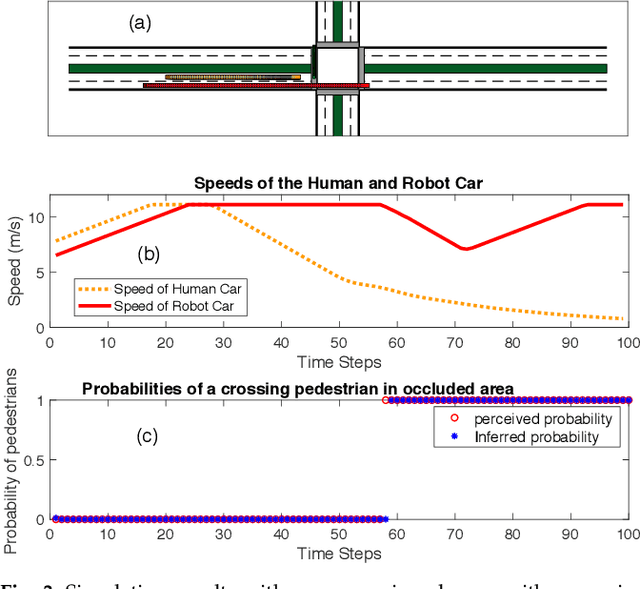
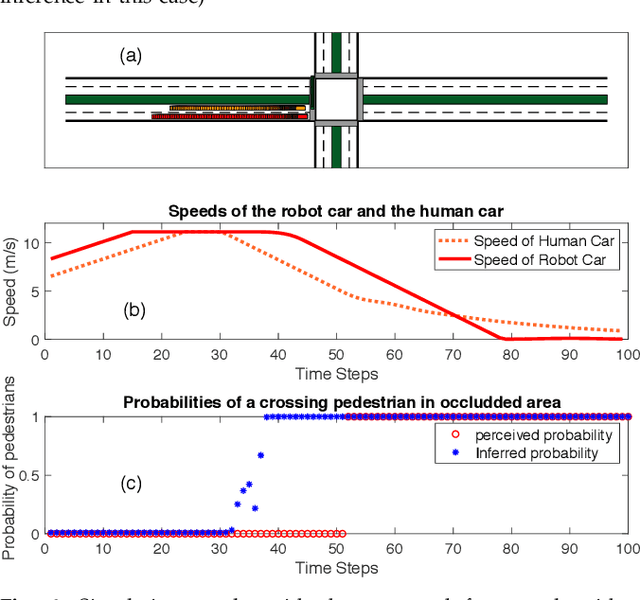
Autonomous cars have to navigate in dynamic environment which can be full of uncertainties. The uncertainties can come either from sensor limitations such as occlusions and limited sensor range, or from probabilistic prediction of other road participants, or from unknown social behavior in a new area. To safely and efficiently drive in the presence of these uncertainties, the decision-making and planning modules of autonomous cars should intelligently utilize all available information and appropriately tackle the uncertainties so that proper driving strategies can be generated. In this paper, we propose a social perception scheme which treats all road participants as distributed sensors in a sensor network. By observing the individual behaviors as well as the group behaviors, uncertainties of the three types can be updated uniformly in a belief space. The updated beliefs from the social perception are then explicitly incorporated into a probabilistic planning framework based on Model Predictive Control (MPC). The cost function of the MPC is learned via inverse reinforcement learning (IRL). Such an integrated probabilistic planning module with socially enhanced perception enables the autonomous vehicles to generate behaviors which are defensive but not overly conservative, and socially compatible. The effectiveness of the proposed framework is verified in simulation on an representative scenario with sensor occlusions.