 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoinSeg: Contrast Inter- and Intra- Class Representations for Incremental Segmentation
Oct 10, 2023



Class incremental semantic segmentation aims to strike a balance between the model's stability and plasticity by maintaining old knowledge while adapting to new concepts. However, most state-of-the-art methods use the freeze strategy for stability, which compromises the model's plasticity.In contrast, releasing parameter training for plasticity could lead to the best performance for all categories, but this requires discriminative feature representation.Therefore, we prioritize the model's plasticity and propose the Contrast inter- and intra-class representations for Incremental Segmentation (CoinSeg), which pursues discriminative representations for flexible parameter tuning. Inspired by the Gaussian mixture model that samples from a mixture of Gaussian distributions, CoinSeg emphasizes intra-class diversity with multiple contrastive representation centroids. Specifically, we use mask proposals to identify regions with strong objectness that are likely to be diverse instances/centroids of a category. These mask proposals are then used for contrastive representations to reinforce intra-class diversity. Meanwhile, to avoid bias from intra-class diversity, we also apply category-level pseudo-labels to enhance category-level consistency and inter-category diversity. Additionally, CoinSeg ensures the model's stability and alleviates forgetting through a specific flexible tuning strategy. We validate CoinSeg on Pascal VOC 2012 and ADE20K datasets with multiple incremental scenarios and achieve superior results compared to previous state-of-the-art methods, especially in more challenging and realistic long-term scenarios. Code is available at https://github.com/zkzhang98/CoinSeg.
Dirichlet-based Uncertainty Calibration for Active Domain Adaptation
Feb 27, 2023



Active domain adaptation (DA) aims to maximally boost the model adaptation on a new target domain by actively selecting limited target data to annotate, whereas traditional active learning methods may be less effective since they do not consider the domain shift issue. Despite active DA methods address this by further proposing targetness to measure the representativeness of target domain characteristics, their predictive uncertainty is usually based on the prediction of deterministic models, which can easily be miscalibrated on data with distribution shift. Considering this, we propose a \textit{Dirichlet-based Uncertainty Calibration} (DUC) approach for active DA, which simultaneously achieves the mitigation of miscalibration and the selection of informative target samples. Specifically, we place a Dirichlet prior on the prediction and interpret the prediction as a distribution on the probability simplex, rather than a point estimate like deterministic models. This manner enables us to consider all possible predictions, mitigating the miscalibration of unilateral prediction. Then a two-round selection strategy based on different uncertainty origins is designed to select target samples that are both representative of target domain and conducive to discriminability. Extensive experiments on cross-domain image classification and semantic segmentation validate the superiority of DUC.
FedKNOW: Federated Continual Learning with Signature Task Knowledge Integration at Edge
Dec 04, 2022



Deep Neural Networks (DNNs) have been ubiquitously adopted in internet of things and are becoming an integral of our daily life. When tackling the evolving learning tasks in real world, such as classifying different types of objects, DNNs face the challenge to continually retrain themselves according to the tasks on different edge devices. Federated continual learning is a promising technique that offers partial solutions but yet to overcome the following difficulties: the significant accuracy loss due to the limited on-device processing, the negative knowledge transfer caused by the limited communication of non-IID data, and the limited scalability on the tasks and edge devices. In this paper, we propose FedKNOW, an accurate and scalable federated continual learning framework, via a novel concept of signature task knowledge. FedKNOW is a client side solution that continuously extracts and integrates the knowledge of signature tasks which are highly influenced by the current task. Each client of FedKNOW is composed of a knowledge extractor, a gradient restorer and, most importantly, a gradient integrator. Upon training for a new task, the gradient integrator ensures the prevention of catastrophic forgetting and mitigation of negative knowledge transfer by effectively combining signature tasks identified from the past local tasks and other clients' current tasks through the global model. We implement FedKNOW in PyTorch and extensively evaluate it against state-of-the-art techniques using popular federated continual learning benchmarks. Extensive evaluation results on heterogeneous edge devices show that FedKNOW improves model accuracy by 63.24% without increasing model training time, reduces communication cost by 34.28%, and achieves more improvements under difficult scenarios such as large numbers of tasks or clients, and training different complex networks.
VBLC: Visibility Boosting and Logit-Constraint Learning for Domain Adaptive Semantic Segmentation under Adverse Conditions
Nov 22, 2022



Generalizing models trained on normal visual conditions to target domains under adverse conditions is demanding in the practical systems. One prevalent solution is to bridge the domain gap between clear- and adverse-condition images to make satisfactory prediction on the target. However, previous methods often reckon on additional reference images of the same scenes taken from normal conditions, which are quite tough to collect in reality. Furthermore, most of them mainly focus on individual adverse condition such as nighttime or foggy, weakening the model versatility when encountering other adverse weathers. To overcome the above limitations, we propose a novel framework, Visibility Boosting and Logit-Constraint learning (VBLC), tailored for superior normal-to-adverse adaptation. VBLC explores the potential of getting rid of reference images and resolving the mixture of adverse conditions simultaneously. In detail, we first propose the visibility boost module to dynamically improve target images via certain priors in the image level. Then, we figure out the overconfident drawback in the conventional cross-entropy loss for self-training method and devise the logit-constraint learning, which enforces a constraint on logit outputs during training to mitigate this pain point. To the best of our knowledge, this is a new perspective for tackling such a challenging task. Extensive experiments on two normal-to-adverse domain adaptation benchmarks, i.e., Cityscapes -> ACDC and Cityscapes -> FoggyCityscapes + RainCityscapes, verify the effectiveness of VBLC, where it establishes the new state of the art. Code is available at https://github.com/BIT-DA/VBLC.
Making the Best of Both Worlds: A Domain-Oriented Transformer for Unsupervised Domain Adaptation
Aug 02, 2022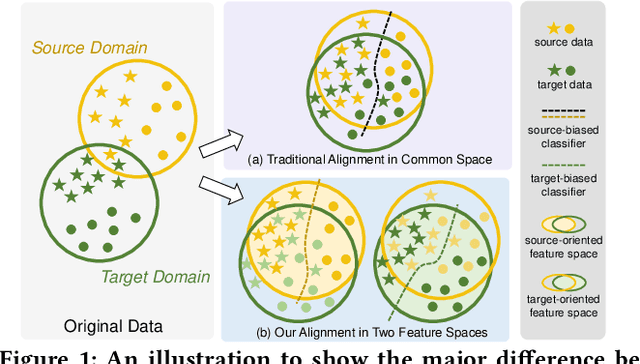
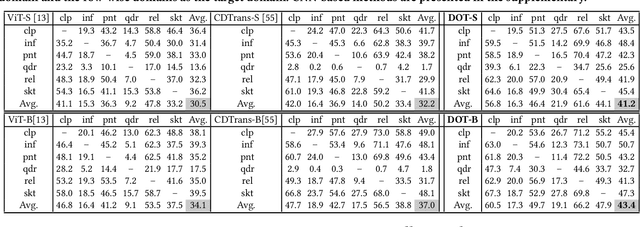
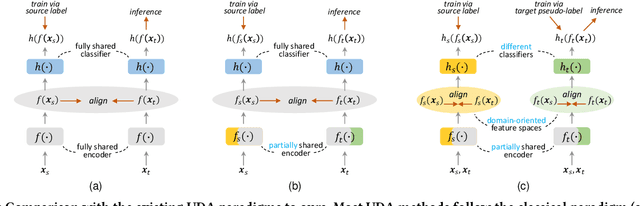
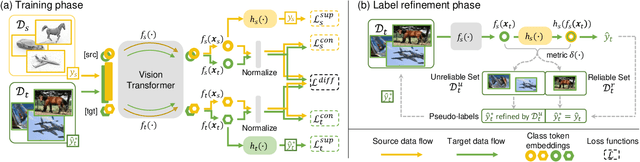
Extensive studies on Unsupervised Domain Adaptation (UDA) have propelled the deployment of deep learning from limited experimental datasets into real-world unconstrained domains. Most UDA approaches align features within a common embedding space and apply a shared classifier for target prediction. However, since a perfectly aligned feature space may not exist when the domain discrepancy is large, these methods suffer from two limitations. First, the coercive domain alignment deteriorates target domain discriminability due to lacking target label supervision. Second, the source-supervised classifier is inevitably biased to source data, thus it may underperform in target domain. To alleviate these issues, we propose to simultaneously conduct feature alignment in two individual spaces focusing on different domains, and create for each space a domain-oriented classifier tailored specifically for that domain. Specifically, we design a Domain-Oriented Transformer (DOT) that has two individual classification tokens to learn different domain-oriented representations, and two classifiers to preserve domain-wise discriminability. Theoretical guaranteed contrastive-based alignment and the source-guided pseudo-label refinement strategy are utilized to explore both domain-invariant and specific information. Comprehensive experiments validate that our method achieves state-of-the-art on several benchmarks.
Improving Transferability for Domain Adaptive Detection Transformers
Apr 29, 2022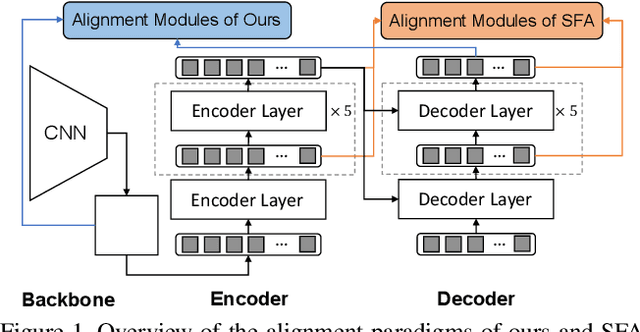
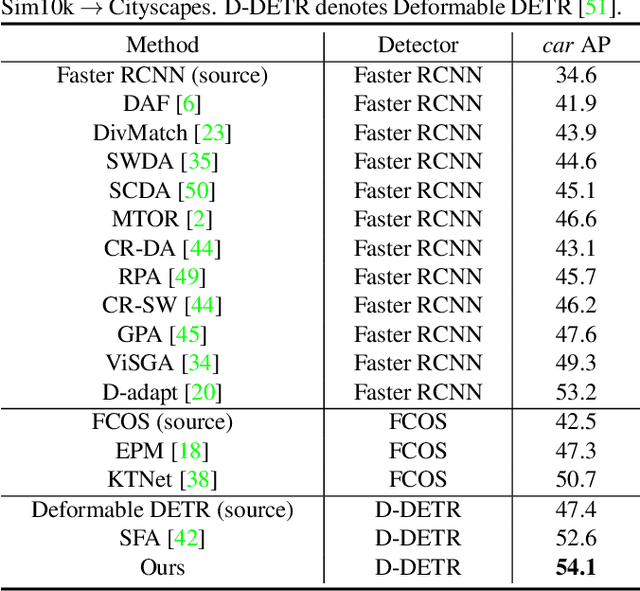
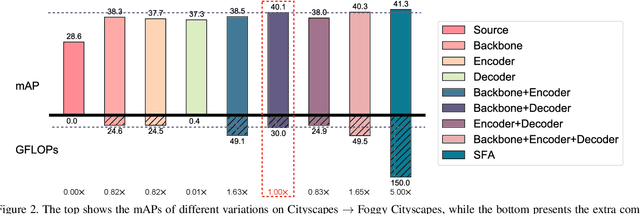
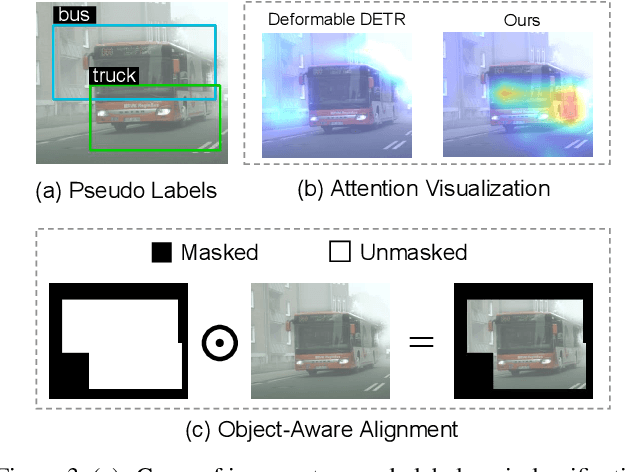
DETR-style detectors stand out amongst in-domain scenarios, but their properties in domain shift settings are under-explored. This paper aims to build a simple but effective baseline with a DETR-style detector on domain shift settings based on two findings. For one, mitigating the domain shift on the backbone and the decoder output features excels in getting favorable results. For another, advanced domain alignment methods in both parts further enhance the performance. Thus, we propose the Object-Aware Alignment (OAA) module and the Optimal Transport based Alignment (OTA) module to achieve comprehensive domain alignment on the outputs of the backbone and the detector. The OAA module aligns the foreground regions identified by pseudo-labels in the backbone outputs, leading to domain-invariant based features. The OTA module utilizes sliced Wasserstein distance to maximize the retention of location information while minimizing the domain gap in the decoder outputs. We implement the findings and the alignment modules into our adaptation method, and it benchmarks the DETR-style detector on the domain shift settings. Experiments on various domain adaptive scenarios validate the effectiveness of our method.
ROMA: Cross-Domain Region Similarity Matching for Unpaired Nighttime Infrared to Daytime Visible Video Translation
Apr 26, 2022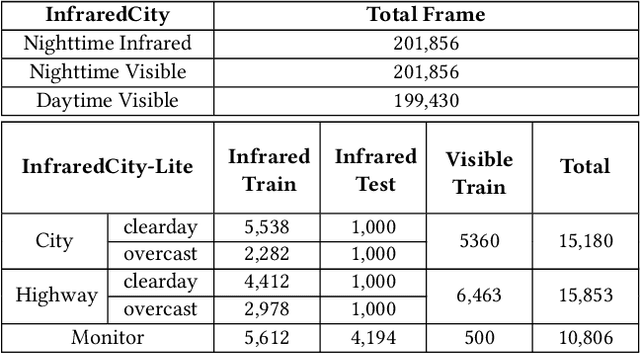
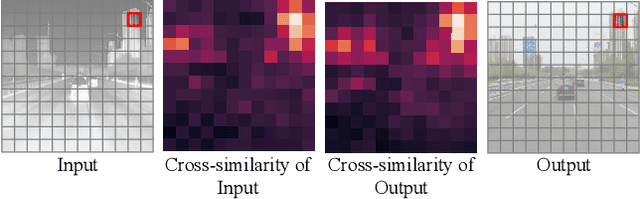
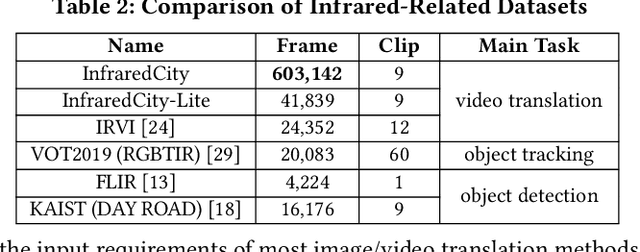
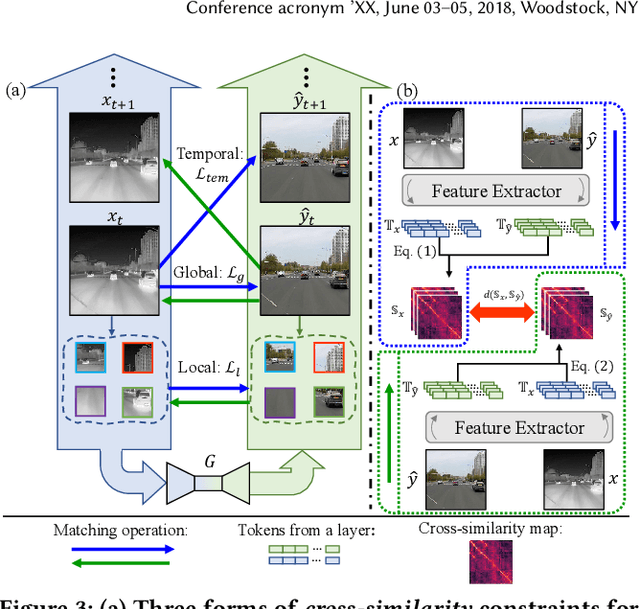
Infrared cameras are often utilized to enhance the night vision since the visible light cameras exhibit inferior efficacy without sufficient illumination. However, infrared data possesses inadequate color contrast and representation ability attributed to its intrinsic heat-related imaging principle. This makes it arduous to capture and analyze information for human beings, meanwhile hindering its application. Although, the domain gaps between unpaired nighttime infrared and daytime visible videos are even huger than paired ones that captured at the same time, establishing an effective translation mapping will greatly contribute to various fields. In this case, the structural knowledge within nighttime infrared videos and semantic information contained in the translated daytime visible pairs could be utilized simultaneously. To this end, we propose a tailored framework ROMA that couples with our introduced cRoss-domain regiOn siMilarity mAtching technique for bridging the huge gaps. To be specific, ROMA could efficiently translate the unpaired nighttime infrared videos into fine-grained daytime visible ones, meanwhile maintain the spatiotemporal consistency via matching the cross-domain region similarity. Furthermore, we design a multiscale region-wise discriminator to distinguish the details from synthesized visible results and real references. Extensive experiments and evaluations for specific applications indicate ROMA outperforms the state-of-the-art methods. Moreover, we provide a new and challenging dataset encouraging further research for unpaired nighttime infrared and daytime visible video translation, named InfraredCity. In particular, it consists of 9 long video clips including City, Highway and Monitor scenarios. All clips could be split into 603,142 frames in total, which are 20 times larger than the recently released daytime infrared-to-visible dataset IRVI.
SePiCo: Semantic-Guided Pixel Contrast for Domain Adaptive Semantic Segmentation
Apr 19, 2022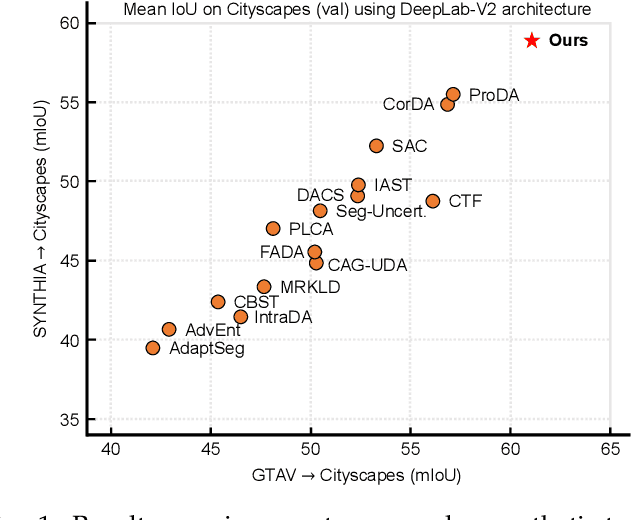
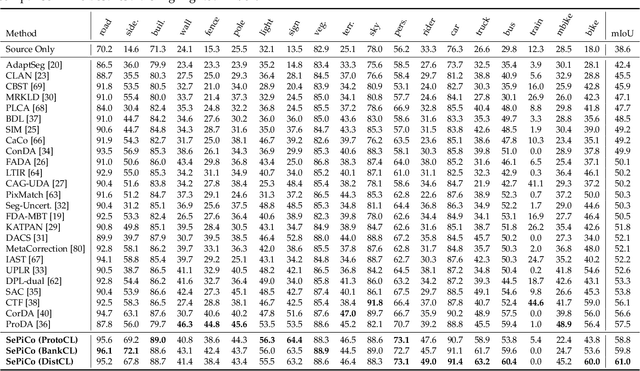
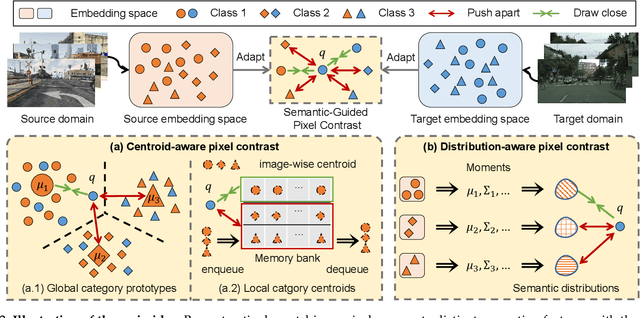
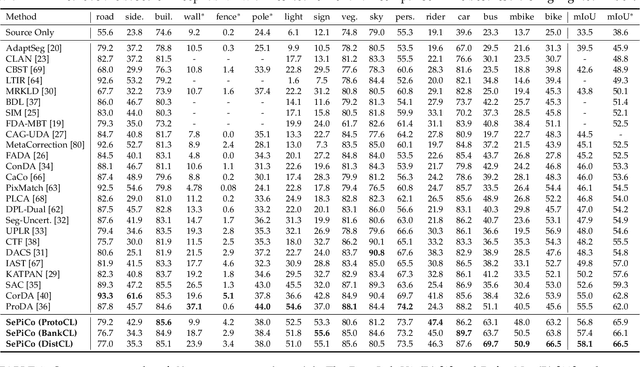
Domain adaptive semantic segmentation attempts to make satisfactory dense predictions on an unlabeled target domain by utilizing the model trained on a labeled source domain. One solution is self-training, which retrains models with target pseudo labels. Many methods tend to alleviate noisy pseudo labels, however, they ignore intrinsic connections among cross-domain pixels with similar semantic concepts. Thus, they would struggle to deal with the semantic variations across domains, leading to less discrimination and poor generalization. In this work, we propose Semantic-Guided Pixel Contrast (SePiCo), a novel one-stage adaptation framework that highlights the semantic concepts of individual pixel to promote learning of class-discriminative and class-balanced pixel embedding space across domains. Specifically, to explore proper semantic concepts, we first investigate a centroid-aware pixel contrast that employs the category centroids of the entire source domain or a single source image to guide the learning of discriminative features. Considering the possible lack of category diversity in semantic concepts, we then blaze a trail of distributional perspective to involve a sufficient quantity of instances, namely distribution-aware pixel contrast, in which we approximate the true distribution of each semantic category from the statistics of labeled source data. Moreover, such an optimization objective can derive a closed-form upper bound by implicitly involving an infinite number of (dis)similar pairs. Extensive experiments show that SePiCo not only helps stabilize training but also yields discriminative features, making significant progress in both daytime and nighttime scenarios. Most notably, SePiCo establishes excellent results on tasks of GTAV/SYNTHIA-to-Cityscapes and Cityscapes-to-Dark Zurich, improving by 12.8, 8.8, and 9.2 mIoUs compared to the previous best method, respectively.
Causality Inspired Representation Learning for Domain Generalization
Mar 27, 2022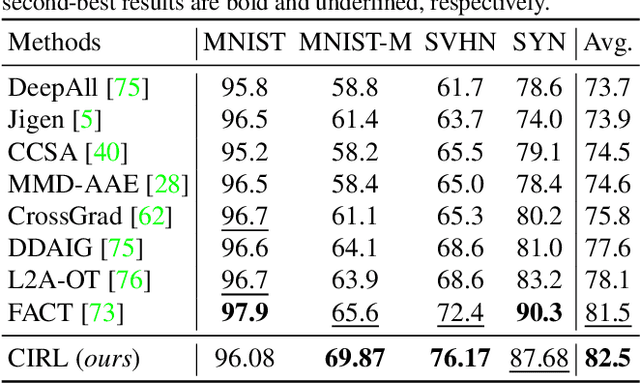

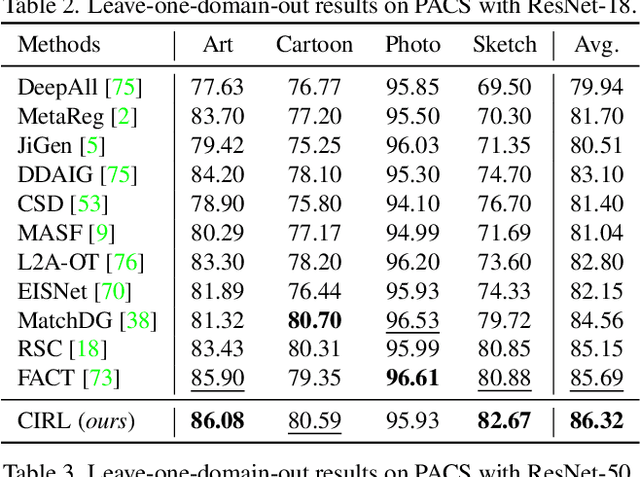
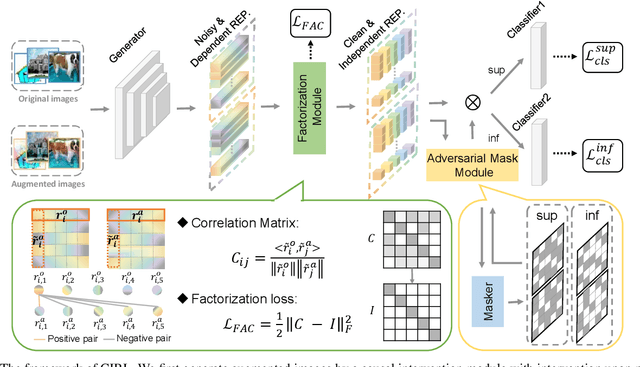
Domain generalization (DG) is essentially an out-of-distribution problem, aiming to generalize the knowledge learned from multiple source domains to an unseen target domain. The mainstream is to leverage statistical models to model the dependence between data and labels, intending to learn representations independent of domain. Nevertheless, the statistical models are superficial descriptions of reality since they are only required to model dependence instead of the intrinsic causal mechanism. When the dependence changes with the target distribution, the statistic models may fail to generalize. In this regard, we introduce a general structural causal model to formalize the DG problem. Specifically, we assume that each input is constructed from a mix of causal factors (whose relationship with the label is invariant across domains) and non-causal factors (category-independent), and only the former cause the classification judgments. Our goal is to extract the causal factors from inputs and then reconstruct the invariant causal mechanisms. However, the theoretical idea is far from practical of DG since the required causal/non-causal factors are unobserved. We highlight that ideal causal factors should meet three basic properties: separated from the non-causal ones, jointly independent, and causally sufficient for the classification. Based on that, we propose a Causality Inspired Representation Learning (CIRL) algorithm that enforces the representations to satisfy the above properties and then uses them to simulate the causal factors, which yields improved generalization ability. Extensive experimental results on several widely used datasets verify the effectiveness of our approach.
CADRE: A Cascade Deep Reinforcement Learning Framework for Vision-based Autonomous Urban Driving
Feb 17, 2022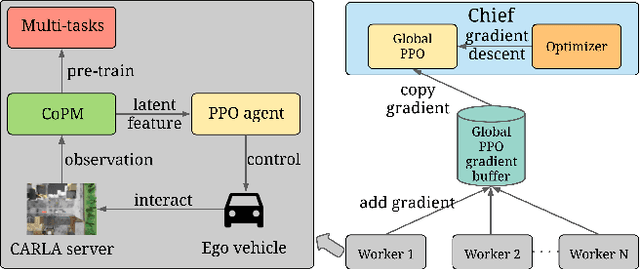
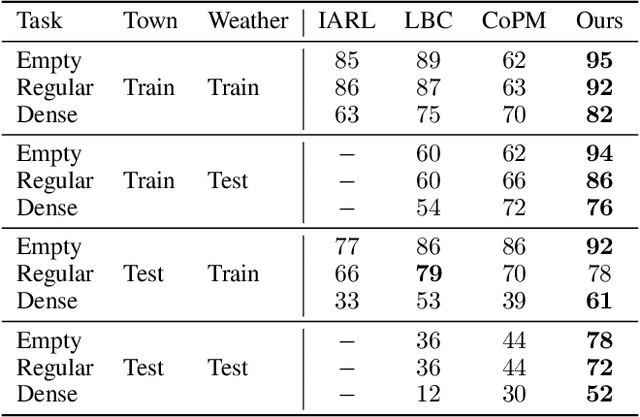
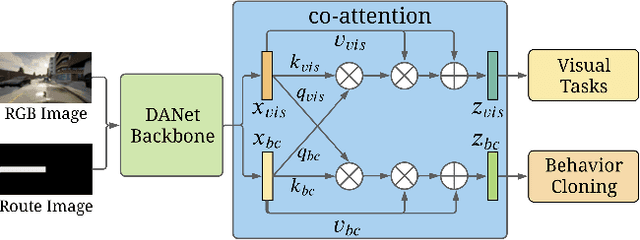
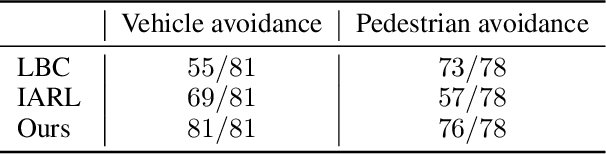
Vision-based autonomous urban driving in dense traffic is quite challenging due to the complicated urban environment and the dynamics of the driving behaviors. Widely-applied methods either heavily rely on hand-crafted rules or learn from limited human experience, which makes them hard to generalize to rare but critical scenarios. In this paper, we present a novel CAscade Deep REinforcement learning framework, CADRE, to achieve model-free vision-based autonomous urban driving. In CADRE, to derive representative latent features from raw observations, we first offline train a Co-attention Perception Module (CoPM) that leverages the co-attention mechanism to learn the inter-relationships between the visual and control information from a pre-collected driving dataset. Cascaded by the frozen CoPM, we then present an efficient distributed proximal policy optimization framework to online learn the driving policy under the guidance of particularly designed reward functions. We perform a comprehensive empirical study with the CARLA NoCrash benchmark as well as specific obstacle avoidance scenarios in autonomous urban driving tasks. The experimental results well justify the effectiveness of CADRE and its superiority over the state-of-the-art by a wide margin.