 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapGuide: A Simple yet Effective Method to Reconstruct Continuous Language from Brain Activities
Apr 02, 2024



Decoding continuous language from brain activity is a formidable yet promising field of research. It is particularly significant for aiding people with speech disabilities to communicate through brain signals. This field addresses the complex task of mapping brain signals to text. The previous best attempt reverse-engineered this process in an indirect way: it began by learning to encode brain activity from text and then guided text generation by aligning with predicted brain responses. In contrast, we propose a simple yet effective method that guides text reconstruction by directly comparing them with the predicted text embeddings mapped from brain activities. Comprehensive experiments reveal that our method significantly outperforms the current state-of-the-art model, showing average improvements of 77% and 54% on BLEU and METEOR scores. We further validate the proposed modules through detailed ablation studies and case analyses and highlight a critical correlation: the more precisely we map brain activities to text embeddings, the better the text reconstruction results. Such insight can simplify the task of reconstructing language from brain activities for future work, emphasizing the importance of improving brain-to-text-embedding mapping techniques.
Computational Models to Study Language Processing in the Human Brain: A Survey
Mar 20, 2024



Despite differing from the human language processing mechanism in implementation and algorithms, current language models demonstrate remarkable human-like or surpassing language capabilities. Should computational language models be employed in studying the brain, and if so, when and how? To delve into this topic, this paper reviews efforts in using computational models for brain research, highlighting emerging trends. To ensure a fair comparison, the paper evaluates various computational models using consistent metrics on the same dataset. Our analysis reveals that no single model outperforms others on all datasets, underscoring the need for rich testing datasets and rigid experimental control to draw robust conclusions in studies involving computational models.
MulCogBench: A Multi-modal Cognitive Benchmark Dataset for Evaluating Chinese and English Computational Language Models
Mar 02, 2024Pre-trained computational language models have recently made remarkable progress in harnessing the language abilities which were considered unique to humans. Their success has raised interest in whether these models represent and process language like humans. To answer this question, this paper proposes MulCogBench, a multi-modal cognitive benchmark dataset collected from native Chinese and English participants. It encompasses a variety of cognitive data, including subjective semantic ratings, eye-tracking, functional magnetic resonance imaging (fMRI), and magnetoencephalography (MEG). To assess the relationship between language models and cognitive data, we conducted a similarity-encoding analysis which decodes cognitive data based on its pattern similarity with textual embeddings. Results show that language models share significant similarities with human cognitive data and the similarity patterns are modulated by the data modality and stimuli complexity. Specifically, context-aware models outperform context-independent models as language stimulus complexity increases. The shallow layers of context-aware models are better aligned with the high-temporal-resolution MEG signals whereas the deeper layers show more similarity with the high-spatial-resolution fMRI. These results indicate that language models have a delicate relationship with brain language representations. Moreover, the results between Chinese and English are highly consistent, suggesting the generalizability of these findings across languages.
MoDS: Model-oriented Data Selection for Instruction Tuning
Nov 27, 2023



Instruction tuning has become the de facto method to equip large language models (LLMs) with the ability of following user instructions. Usually, hundreds of thousands or millions of instruction-following pairs are employed to fine-tune the foundation LLMs. Recently, some studies show that a small number of high-quality instruction data is enough. However, how to select appropriate instruction data for a given LLM is still an open problem. To address this problem, in this paper we present a model-oriented data selection (MoDS) approach, which selects instruction data based on a new criteria considering three aspects: quality, coverage and necessity. First, our approach utilizes a quality evaluation model to filter out the high-quality subset from the original instruction dataset, and then designs an algorithm to further select from the high-quality subset a seed instruction dataset with good coverage. The seed dataset is applied to fine-tune the foundation LLM to obtain an initial instruction-following LLM. Finally, we develop a necessity evaluation model to find out the instruction data which are performed badly in the initial instruction-following LLM and consider them necessary instructions to further improve the LLMs. In this way, we can get a small high-quality, broad-coverage and high-necessity subset from the original instruction datasets. Experimental results show that, the model fine-tuned with 4,000 instruction pairs selected by our approach could perform better than the model fine-tuned with the full original dataset which includes 214k instruction data.
Align after Pre-train: Improving Multilingual Generative Models with Cross-lingual Alignment
Nov 14, 2023Multilingual generative models obtain remarkable cross-lingual capabilities through pre-training on large-scale corpora. However, they still exhibit a performance bias toward high-resource languages, and learn isolated distributions of sentence representations across languages. To bridge this gap, we propose a simple yet effective alignment framework exploiting pairs of translation sentences. It aligns the internal sentence representations across different languages via multilingual contrastive learning and aligns model outputs by answering prompts in different languages. Experimental results demonstrate that even with less than 0.1 {\textperthousand} of pre-training tokens, our alignment framework significantly boosts the cross-lingual abilities of generative models and mitigates the performance gap. Further analysis reveals that it results in a better internal multilingual representation distribution of multilingual models.
ChineseWebText: Large-scale High-quality Chinese Web Text Extracted with Effective Evaluation Model
Nov 10, 2023During the development of large language models (LLMs), the scale and quality of the pre-training data play a crucial role in shaping LLMs' capabilities. To accelerate the research of LLMs, several large-scale datasets, such as C4 [1], Pile [2], RefinedWeb [3] and WanJuan [4], have been released to the public. However, most of the released corpus focus mainly on English, and there is still lack of complete tool-chain for extracting clean texts from web data. Furthermore, fine-grained information of the corpus, e.g. the quality of each text, is missing. To address these challenges, we propose in this paper a new complete tool-chain EvalWeb to extract Chinese clean texts from noisy web data. First, similar to previous work, manually crafted rules are employed to discard explicit noisy texts from the raw crawled web contents. Second, a well-designed evaluation model is leveraged to assess the remaining relatively clean data, and each text is assigned a specific quality score. Finally, we can easily utilize an appropriate threshold to select the high-quality pre-training data for Chinese. Using our proposed approach, we release the largest and latest large-scale high-quality Chinese web text ChineseWebText, which consists of 1.42 TB and each text is associated with a quality score, facilitating the LLM researchers to choose the data according to the desired quality thresholds. We also release a much cleaner subset of 600 GB Chinese data with the quality exceeding 90%.
Interpreting and Exploiting Functional Specialization in Multi-Head Attention under Multi-task Learning
Oct 16, 2023



Transformer-based models, even though achieving super-human performance on several downstream tasks, are often regarded as a black box and used as a whole. It is still unclear what mechanisms they have learned, especially their core module: multi-head attention. Inspired by functional specialization in the human brain, which helps to efficiently handle multiple tasks, this work attempts to figure out whether the multi-head attention module will evolve similar function separation under multi-tasking training. If it is, can this mechanism further improve the model performance? To investigate these questions, we introduce an interpreting method to quantify the degree of functional specialization in multi-head attention. We further propose a simple multi-task training method to increase functional specialization and mitigate negative information transfer in multi-task learning. Experimental results on seven pre-trained transformer models have demonstrated that multi-head attention does evolve functional specialization phenomenon after multi-task training which is affected by the similarity of tasks. Moreover, the multi-task training strategy based on functional specialization boosts performance in both multi-task learning and transfer learning without adding any parameters.
BLSP: Bootstrapping Language-Speech Pre-training via Behavior Alignment of Continuation Writing
Sep 02, 2023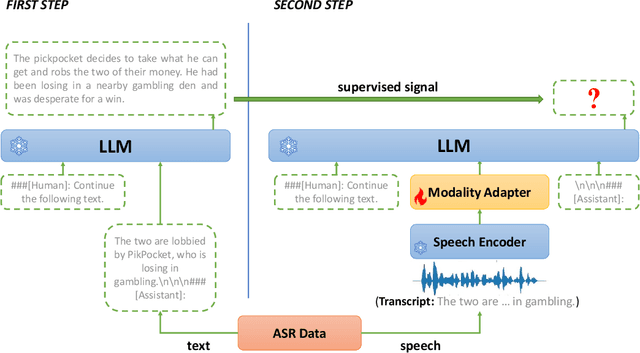


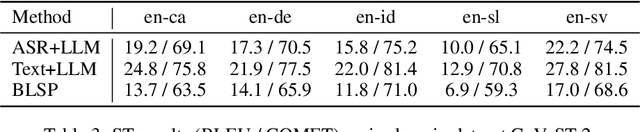
The emergence of large language models (LLMs) has sparked significant interest in extending their remarkable language capabilities to speech. However, modality alignment between speech and text still remains an open problem. Current solutions can be categorized into two strategies. One is a cascaded approach where outputs (tokens or states) of a separately trained speech recognition system are used as inputs for LLMs, which limits their potential in modeling alignment between speech and text. The other is an end-to-end approach that relies on speech instruction data, which is very difficult to collect in large quantities. In this paper, we address these issues and propose the BLSP approach that Bootstraps Language-Speech Pre-training via behavior alignment of continuation writing. We achieve this by learning a lightweight modality adapter between a frozen speech encoder and an LLM, ensuring that the LLM exhibits the same generation behavior regardless of the modality of input: a speech segment or its transcript. The training process can be divided into two steps. The first step prompts an LLM to generate texts with speech transcripts as prefixes, obtaining text continuations. In the second step, these continuations are used as supervised signals to train the modality adapter in an end-to-end manner. We demonstrate that this straightforward process can extend the capabilities of LLMs to speech, enabling speech recognition, speech translation, spoken language understanding, and speech conversation, even in zero-shot cross-lingual scenarios.
CFSum: A Coarse-to-Fine Contribution Network for Multimodal Summarization
Jul 06, 2023



Multimodal summarization usually suffers from the problem that the contribution of the visual modality is unclear. Existing multimodal summarization approaches focus on designing the fusion methods of different modalities, while ignoring the adaptive conditions under which visual modalities are useful. Therefore, we propose a novel Coarse-to-Fine contribution network for multimodal Summarization (CFSum) to consider different contributions of images for summarization. First, to eliminate the interference of useless images, we propose a pre-filter module to abandon useless images. Second, to make accurate use of useful images, we propose two levels of visual complement modules, word level and phrase level. Specifically, image contributions are calculated and are adopted to guide the attention of both textual and visual modalities. Experimental results have shown that CFSum significantly outperforms multiple strong baselines on the standard benchmark. Furthermore, the analysis verifies that useful images can even help generate non-visual words which are implicitly represented in the image.
BigTrans: Augmenting Large Language Models with Multilingual Translation Capability over 100 Languages
May 29, 2023Large language models (LLMs) demonstrate promising translation performance among various natural languages. However, many LLMs especially the open-sourced ones, such as BLOOM and LLaMA, are English-dominant and support only dozens of natural languages, making the potential of LLMs on language translation less explored. In this work, we present BigTrans which adapts LLaMA that covers only 20 languages and enhances it with multilingual translation capability on more than 100 languages. BigTrans is built upon LLaMA-13B and it is optimized in three steps. First, we continue training LLaMA with massive Chinese monolingual data. Second, we continue training the model with a large-scale parallel dataset that covers 102 natural languages. Third, we instruct-tune the foundation model with multilingual translation instructions, leading to our BigTrans model. The preliminary experiments on multilingual translation show that BigTrans performs comparably with ChatGPT and Google Translate in many languages and even outperforms ChatGPT in 8 language pairs. We release the BigTrans model and hope it can advance the research progress.