 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Few-Shot Early Rumor Detection with Imitation Agent
Dec 20, 2025Early Rumor Detection (EARD) aims to identify the earliest point at which a claim can be accurately classified based on a sequence of social media posts. This is especially challenging in data-scarce settings. While Large Language Models (LLMs) perform well in few-shot NLP tasks, they are not well-suited for time-series data and are computationally expensive for both training and inference. In this work, we propose a novel EARD framework that combines an autonomous agent and an LLM-based detection model, where the agent acts as a reliable decision-maker for \textit{early time point determination}, while the LLM serves as a powerful \textit{rumor detector}. This approach offers the first solution for few-shot EARD, necessitating only the training of a lightweight agent and allowing the LLM to remain training-free. Extensive experiments on four real-world datasets show our approach boosts performance across LLMs and surpasses existing EARD methods in accuracy and earliness.
RAG-RL: Advancing Retrieval-Augmented Generation via RL and Curriculum Learning
Mar 17, 2025Recent research highlights the challenges retrieval models face in retrieving useful contexts and the limitations of generation models in effectively utilizing those contexts in retrieval-augmented generation (RAG) settings. To address these challenges, we introduce RAG-RL, the first reasoning language model (RLM) specifically trained for RAG. RAG-RL demonstrates that stronger answer generation models can identify relevant contexts within larger sets of retrieved information -- thereby alleviating the burden on retrievers -- while also being able to utilize those contexts more effectively. Moreover, we show that curriculum design in the reinforcement learning (RL) post-training process is a powerful approach to enhancing model performance. We benchmark our method on two open-domain question-answering datasets and achieve state-of-the-art results, surpassing previous SOTA generative reader models. In addition, we offers empirical insights into various curriculum learning strategies, providing a deeper understanding of their impact on model performance.
VeraCT Scan: Retrieval-Augmented Fake News Detection with Justifiable Reasoning
Jun 12, 2024



The proliferation of fake news poses a significant threat not only by disseminating misleading information but also by undermining the very foundations of democracy. The recent advance of generative artificial intelligence has further exacerbated the challenge of distinguishing genuine news from fabricated stories. In response to this challenge, we introduce VeraCT Scan, a novel retrieval-augmented system for fake news detection. This system operates by extracting the core facts from a given piece of news and subsequently conducting an internet-wide search to identify corroborating or conflicting reports. Then sources' credibility is leveraged for information verification. Besides determining the veracity of news, we also provide transparent evidence and reasoning to support its conclusions, resulting in the interpretability and trust in the results. In addition to GPT-4 Turbo, Llama-2 13B is also fine-tuned for news content understanding, information verification, and reasoning. Both implementations have demonstrated state-of-the-art accuracy in the realm of fake news detection.
Enhancing Dialogue State Tracking Models through LLM-backed User-Agents Simulation
May 17, 2024Dialogue State Tracking (DST) is designed to monitor the evolving dialogue state in the conversations and plays a pivotal role in developing task-oriented dialogue systems. However, obtaining the annotated data for the DST task is usually a costly endeavor. In this paper, we focus on employing LLMs to generate dialogue data to reduce dialogue collection and annotation costs. Specifically, GPT-4 is used to simulate the user and agent interaction, generating thousands of dialogues annotated with DST labels. Then a two-stage fine-tuning on LLaMA 2 is performed on the generated data and the real data for the DST prediction. Experimental results on two public DST benchmarks show that with the generated dialogue data, our model performs better than the baseline trained solely on real data. In addition, our approach is also capable of adapting to the dynamic demands in real-world scenarios, generating dialogues in new domains swiftly. After replacing dialogue segments in any domain with the corresponding generated ones, the model achieves comparable performance to the model trained on real data.
Enhancing Weakly Supervised Semantic Segmentation with Multi-modal Foundation Models: An End-to-End Approach
May 10, 2024



Semantic segmentation is a core computer vision problem, but the high costs of data annotation have hindered its wide application. Weakly-Supervised Semantic Segmentation (WSSS) offers a cost-efficient workaround to extensive labeling in comparison to fully-supervised methods by using partial or incomplete labels. Existing WSSS methods have difficulties in learning the boundaries of objects leading to poor segmentation results. We propose a novel and effective framework that addresses these issues by leveraging visual foundation models inside the bounding box. Adopting a two-stage WSSS framework, our proposed network consists of a pseudo-label generation module and a segmentation module. The first stage leverages Segment Anything Model (SAM) to generate high-quality pseudo-labels. To alleviate the problem of delineating precise boundaries, we adopt SAM inside the bounding box with the help of another pre-trained foundation model (e.g., Grounding-DINO). Furthermore, we eliminate the necessity of using the supervision of image labels, by employing CLIP in classification. Then in the second stage, the generated high-quality pseudo-labels are used to train an off-the-shelf segmenter that achieves the state-of-the-art performance on PASCAL VOC 2012 and MS COCO 2014.
RAGTruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models
Dec 31, 2023



Retrieval-augmented generation (RAG) has become a main technique for alleviating hallucinations in large language models (LLMs). Despite the integration of RAG, LLMs may still present unsupported or contradictory claims to the retrieved contents. In order to develop effective hallucination prevention strategies under RAG, it is important to create benchmark datasets that can measure the extent of hallucination. This paper presents RAGTruth, a corpus tailored for analyzing word-level hallucinations in various domains and tasks within the standard RAG frameworks for LLM applications. RAGTruth comprises nearly 18,000 naturally generated responses from diverse LLMs using RAG. These responses have undergone meticulous manual annotations at both the individual cases and word levels, incorporating evaluations of hallucination intensity. We not only benchmark hallucination frequencies across different LLMs, but also critically assess the effectiveness of several existing hallucination detection methodologies. Furthermore, we show that using a high-quality dataset such as RAGTruth, it is possible to finetune a relatively small LLM and achieve a competitive level of performance in hallucination detection when compared to the existing prompt-based approaches using state-of-the-art large language models such as GPT-4.
A Contextual Hierarchical Attention Network with Adaptive Objective for Dialogue State Tracking
Jun 02, 2020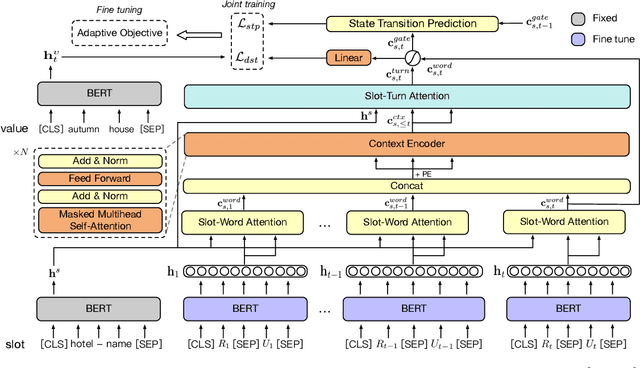
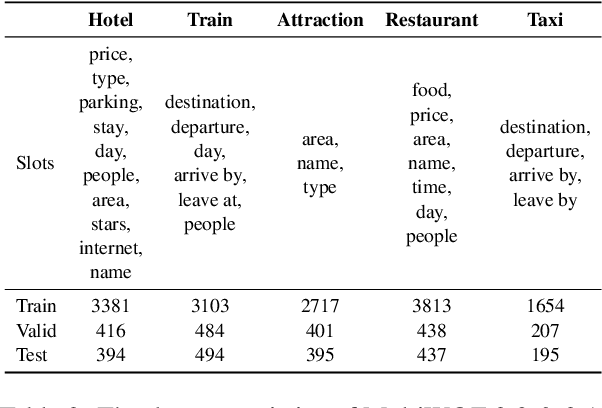
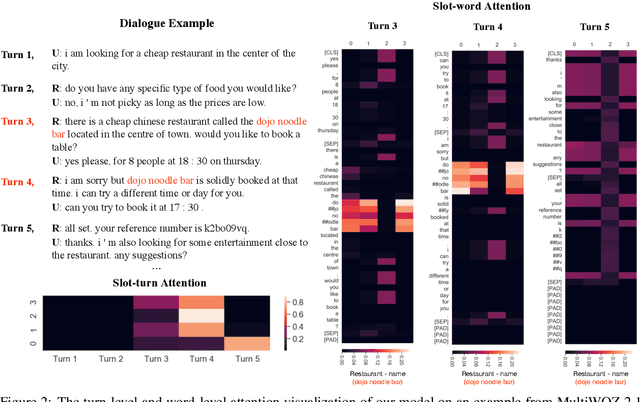
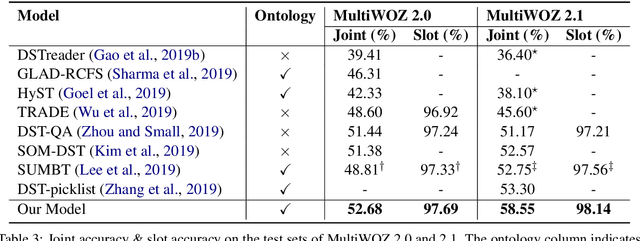
Recent studies in dialogue state tracking (DST) leverage historical information to determine states which are generally represented as slot-value pairs. However, most of them have limitations to efficiently exploit relevant context due to the lack of a powerful mechanism for modeling interactions between the slot and the dialogue history. Besides, existing methods usually ignore the slot imbalance problem and treat all slots indiscriminately, which limits the learning of hard slots and eventually hurts overall performance. In this paper, we propose to enhance the DST through employing a contextual hierarchical attention network to not only discern relevant information at both word level and turn level but also learn contextual representations. We further propose an adaptive objective to alleviate the slot imbalance problem by dynamically adjust weights of different slots during training. Experimental results show that our approach reaches 52.68% and 58.55% joint accuracy on MultiWOZ 2.0 and MultiWOZ 2.1 datasets respectively and achieves new state-of-the-art performance with considerable improvements (+1.24% and +5.98%).
Diversifying Dialogue Generation with Non-Conversational Text
May 13, 2020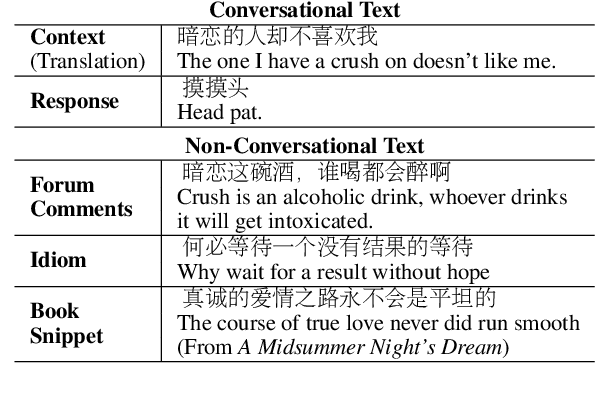
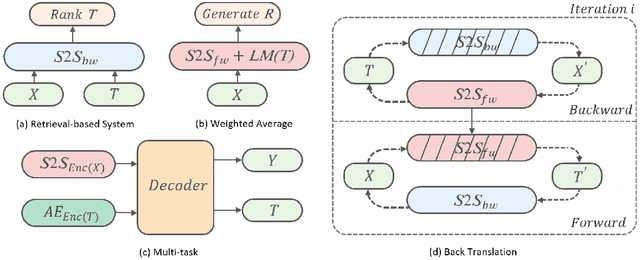
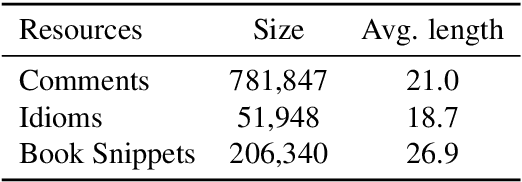
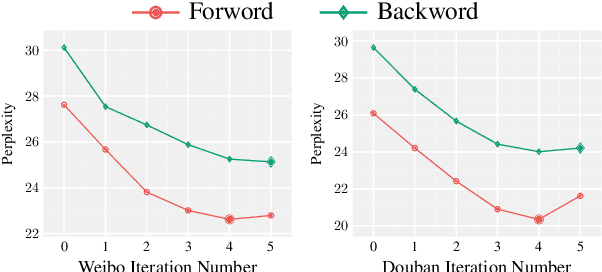
Neural network-based sequence-to-sequence (seq2seq) models strongly suffer from the low-diversity problem when it comes to open-domain dialogue generation. As bland and generic utterances usually dominate the frequency distribution in our daily chitchat, avoiding them to generate more interesting responses requires complex data filtering, sampling techniques or modifying the training objective. In this paper, we propose a new perspective to diversify dialogue generation by leveraging non-conversational text. Compared with bilateral conversations, non-conversational text are easier to obtain, more diverse and cover a much broader range of topics. We collect a large-scale non-conversational corpus from multi sources including forum comments, idioms and book snippets. We further present a training paradigm to effectively incorporate these text via iterative back translation. The resulting model is tested on two conversational datasets and is shown to produce significantly more diverse responses without sacrificing the relevance with context.
Towards Multimodal Response Generation with Exemplar Augmentation and Curriculum Optimization
Apr 26, 2020
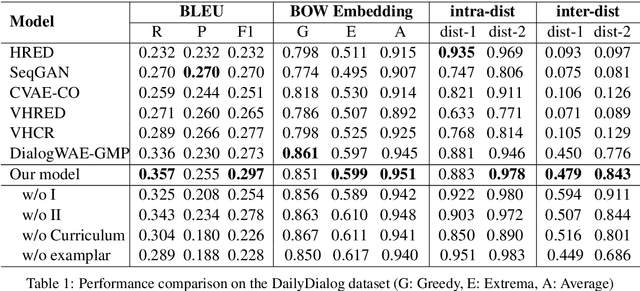
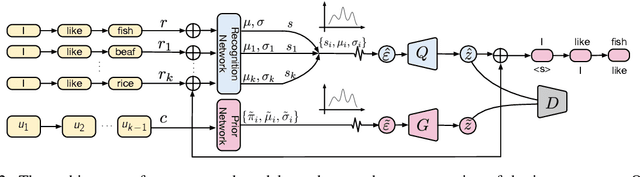
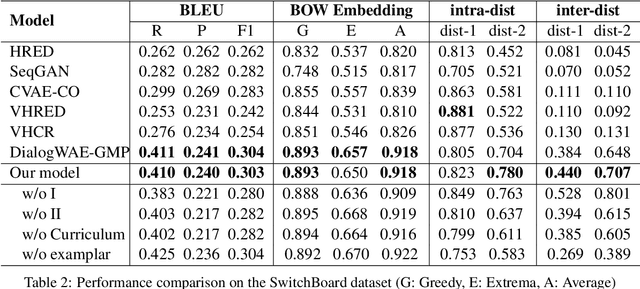
Recently, variational auto-encoder (VAE) based approaches have made impressive progress on improving the diversity of generated responses. However, these methods usually suffer the cost of decreased relevance accompanied by diversity improvements. In this paper, we propose a novel multimodal response generation framework with exemplar augmentation and curriculum optimization to enhance relevance and diversity of generated responses. First, unlike existing VAE-based models that usually approximate a simple Gaussian posterior distribution, we present a Gaussian mixture posterior distribution (i.e, multimodal) to further boost response diversity, which helps capture complex semantics of responses. Then, to ensure that relevance does not decrease while diversity increases, we fully exploit similar examples (exemplars) retrieved from the training data into posterior distribution modeling to augment response relevance. Furthermore, to facilitate the convergence of Gaussian mixture prior and posterior distributions, we devise a curriculum optimization strategy to progressively train the model under multiple training criteria from easy to hard. Experimental results on widely used SwitchBoard and DailyDialog datasets demonstrate that our model achieves significant improvements compared to strong baselines in terms of diversity and relevance.
Learning to Encode Evolutionary Knowledge for Automatic Commenting Long Novels
Apr 21, 2020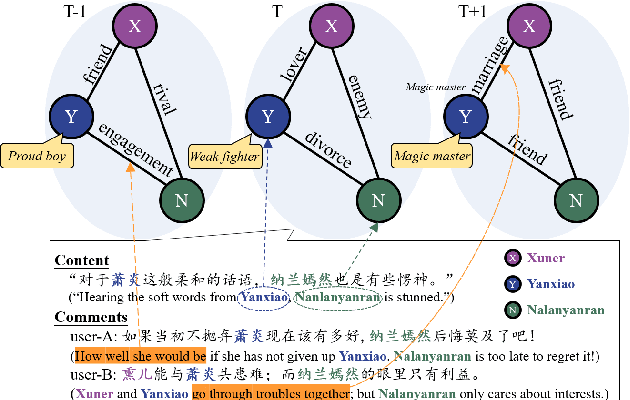
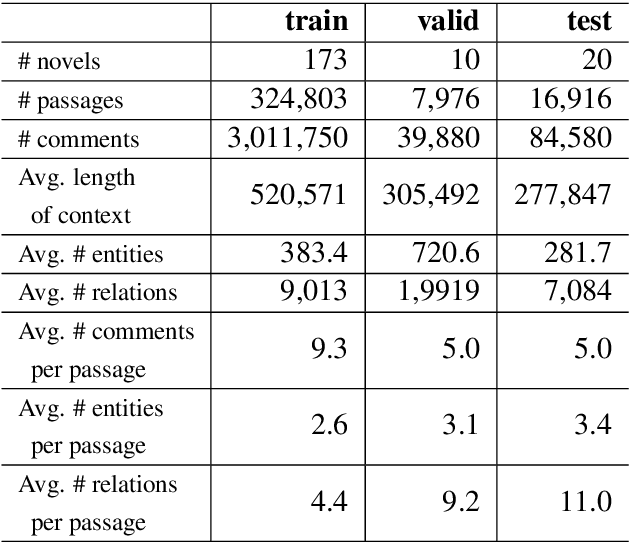
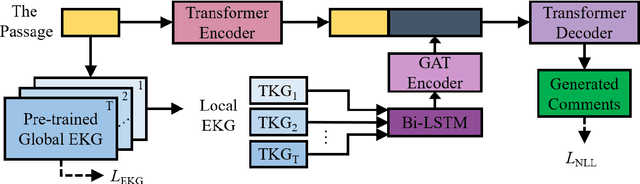
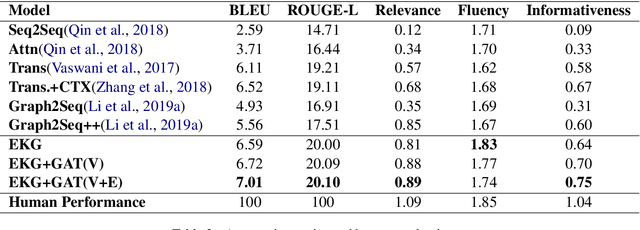
Static knowledge graph has been incorporated extensively into sequence-to-sequence framework for text generation. While effectively representing structured context, static knowledge graph failed to represent knowledge evolution, which is required in modeling dynamic events. In this paper, an automatic commenting task is proposed for long novels, which involves understanding context of more than tens of thousands of words. To model the dynamic storyline, especially the transitions of the characters and their relations, Evolutionary Knowledge Graph(EKG) is proposed and learned within a multi-task framework. Given a specific passage to comment, sequential modeling is used to incorporate historical and future embedding for context representation. Further, a graph-to-sequence model is designed to utilize the EKG for comment generation. Extensive experimental results show that our EKG-based method is superior to several strong baselines on both automatic and human evaluations.