 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeraCT Scan: Retrieval-Augmented Fake News Detection with Justifiable Reasoning
Jun 12, 2024



The proliferation of fake news poses a significant threat not only by disseminating misleading information but also by undermining the very foundations of democracy. The recent advance of generative artificial intelligence has further exacerbated the challenge of distinguishing genuine news from fabricated stories. In response to this challenge, we introduce VeraCT Scan, a novel retrieval-augmented system for fake news detection. This system operates by extracting the core facts from a given piece of news and subsequently conducting an internet-wide search to identify corroborating or conflicting reports. Then sources' credibility is leveraged for information verification. Besides determining the veracity of news, we also provide transparent evidence and reasoning to support its conclusions, resulting in the interpretability and trust in the results. In addition to GPT-4 Turbo, Llama-2 13B is also fine-tuned for news content understanding, information verification, and reasoning. Both implementations have demonstrated state-of-the-art accuracy in the realm of fake news detection.
RAGTruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models
Dec 31, 2023



Retrieval-augmented generation (RAG) has become a main technique for alleviating hallucinations in large language models (LLMs). Despite the integration of RAG, LLMs may still present unsupported or contradictory claims to the retrieved contents. In order to develop effective hallucination prevention strategies under RAG, it is important to create benchmark datasets that can measure the extent of hallucination. This paper presents RAGTruth, a corpus tailored for analyzing word-level hallucinations in various domains and tasks within the standard RAG frameworks for LLM applications. RAGTruth comprises nearly 18,000 naturally generated responses from diverse LLMs using RAG. These responses have undergone meticulous manual annotations at both the individual cases and word levels, incorporating evaluations of hallucination intensity. We not only benchmark hallucination frequencies across different LLMs, but also critically assess the effectiveness of several existing hallucination detection methodologies. Furthermore, we show that using a high-quality dataset such as RAGTruth, it is possible to finetune a relatively small LLM and achieve a competitive level of performance in hallucination detection when compared to the existing prompt-based approaches using state-of-the-art large language models such as GPT-4.
Diversifying Dialogue Generation with Non-Conversational Text
May 13, 2020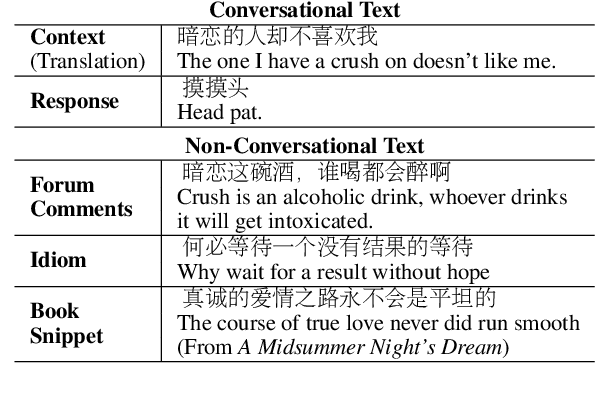
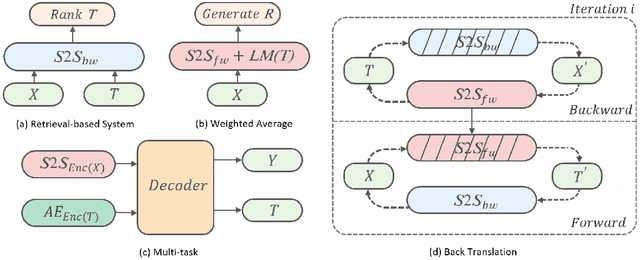
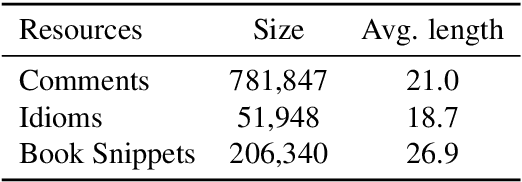
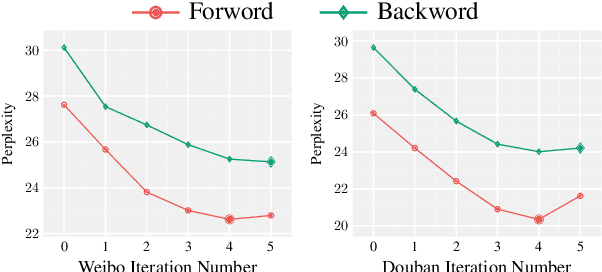
Neural network-based sequence-to-sequence (seq2seq) models strongly suffer from the low-diversity problem when it comes to open-domain dialogue generation. As bland and generic utterances usually dominate the frequency distribution in our daily chitchat, avoiding them to generate more interesting responses requires complex data filtering, sampling techniques or modifying the training objective. In this paper, we propose a new perspective to diversify dialogue generation by leveraging non-conversational text. Compared with bilateral conversations, non-conversational text are easier to obtain, more diverse and cover a much broader range of topics. We collect a large-scale non-conversational corpus from multi sources including forum comments, idioms and book snippets. We further present a training paradigm to effectively incorporate these text via iterative back translation. The resulting model is tested on two conversational datasets and is shown to produce significantly more diverse responses without sacrificing the relevance with context.