 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASAP: Interpretable Analysis and Summarization of AI-generated Image Patterns at Scale
Apr 03, 2024



Generative image models have emerged as a promising technology to produce realistic images. Despite potential benefits, concerns grow about its misuse, particularly in generating deceptive images that could raise significant ethical, legal, and societal issues. Consequently, there is growing demand to empower users to effectively discern and comprehend patterns of AI-generated images. To this end, we developed ASAP, an interactive visualization system that automatically extracts distinct patterns of AI-generated images and allows users to interactively explore them via various views. To uncover fake patterns, ASAP introduces a novel image encoder, adapted from CLIP, which transforms images into compact "distilled" representations, enriched with information for differentiating authentic and fake images. These representations generate gradients that propagate back to the attention maps of CLIP's transformer block. This process quantifies the relative importance of each pixel to image authenticity or fakeness, exposing key deceptive patterns. ASAP enables the at scale interactive analysis of these patterns through multiple, coordinated visualizations. This includes a representation overview with innovative cell glyphs to aid in the exploration and qualitative evaluation of fake patterns across a vast array of images, as well as a pattern view that displays authenticity-indicating patterns in images and quantifies their impact. ASAP supports the analysis of cutting-edge generative models with the latest architectures, including GAN-based models like proGAN and diffusion models like the latent diffusion model. We demonstrate ASAP's usefulness through two usage scenarios using multiple fake image detection benchmark datasets, revealing its ability to identify and understand hidden patterns in AI-generated images, especially in detecting fake human faces produced by diffusion-based techniques.
Is Synthetic Image Useful for Transfer Learning? An Investigation into Data Generation, Volume, and Utilization
Apr 02, 2024



Synthetic image data generation represents a promising avenue for training deep learning models, particularly in the realm of transfer learning, where obtaining real images within a specific domain can be prohibitively expensive due to privacy and intellectual property considerations. This work delves into the generation and utilization of synthetic images derived from text-to-image generative models in facilitating transfer learning paradigms. Despite the high visual fidelity of the generated images, we observe that their naive incorporation into existing real-image datasets does not consistently enhance model performance due to the inherent distribution gap between synthetic and real images. To address this issue, we introduce a novel two-stage framework called bridged transfer, which initially employs synthetic images for fine-tuning a pre-trained model to improve its transferability and subsequently uses real data for rapid adaptation. Alongside, We propose dataset style inversion strategy to improve the stylistic alignment between synthetic and real images. Our proposed methods are evaluated across 10 different datasets and 5 distinct models, demonstrating consistent improvements, with up to 30% accuracy increase on classification tasks. Intriguingly, we note that the enhancements were not yet saturated, indicating that the benefits may further increase with an expanded volume of synthetic data.
BAMM: Bidirectional Autoregressive Motion Model
Apr 01, 2024



Generating human motion from text has been dominated by denoising motion models either through diffusion or generative masking process. However, these models face great limitations in usability by requiring prior knowledge of the motion length. Conversely, autoregressive motion models address this limitation by adaptively predicting motion endpoints, at the cost of degraded generation quality and editing capabilities. To address these challenges, we propose Bidirectional Autoregressive Motion Model (BAMM), a novel text-to-motion generation framework. BAMM consists of two key components: (1) a motion tokenizer that transforms 3D human motion into discrete tokens in latent space, and (2) a masked self-attention transformer that autoregressively predicts randomly masked tokens via a hybrid attention masking strategy. By unifying generative masked modeling and autoregressive modeling, BAMM captures rich and bidirectional dependencies among motion tokens, while learning the probabilistic mapping from textual inputs to motion outputs with dynamically-adjusted motion sequence length. This feature enables BAMM to simultaneously achieving high-quality motion generation with enhanced usability and built-in motion editability. Extensive experiments on HumanML3D and KIT-ML datasets demonstrate that BAMM surpasses current state-of-the-art methods in both qualitative and quantitative measures. Our project page is available at https://exitudio.github.io/BAMM-page
Towards Memorization-Free Diffusion Models
Apr 01, 2024Pretrained diffusion models and their outputs are widely accessible due to their exceptional capacity for synthesizing high-quality images and their open-source nature. The users, however, may face litigation risks owing to the models' tendency to memorize and regurgitate training data during inference. To address this, we introduce Anti-Memorization Guidance (AMG), a novel framework employing three targeted guidance strategies for the main causes of memorization: image and caption duplication, and highly specific user prompts. Consequently, AMG ensures memorization-free outputs while maintaining high image quality and text alignment, leveraging the synergy of its guidance methods, each indispensable in its own right. AMG also features an innovative automatic detection system for potential memorization during each step of inference process, allows selective application of guidance strategies, minimally interfering with the original sampling process to preserve output utility. We applied AMG to pretrained Denoising Diffusion Probabilistic Models (DDPM) and Stable Diffusion across various generation tasks. The results demonstrate that AMG is the first approach to successfully eradicates all instances of memorization with no or marginal impacts on image quality and text-alignment, as evidenced by FID and CLIP scores.
Threats, Attacks, and Defenses in Machine Unlearning: A Survey
Mar 26, 2024



Machine Unlearning (MU) has gained considerable attention recently for its potential to achieve Safe AI by removing the influence of specific data from trained machine learning models. This process, known as knowledge removal, addresses AI governance concerns of training data such as quality, sensitivity, copyright restrictions, and obsolescence. This capability is also crucial for ensuring compliance with privacy regulations such as the Right To Be Forgotten. Furthermore, effective knowledge removal mitigates the risk of harmful outcomes, safeguarding against biases, misinformation, and unauthorized data exploitation, thereby enhancing the safe and responsible use of AI systems. Efforts have been made to design efficient unlearning approaches, with MU services being examined for integration with existing machine learning as a service, allowing users to submit requests to remove specific data from the training corpus. However, recent research highlights vulnerabilities in machine unlearning systems, such as information leakage and malicious unlearning requests, that can lead to significant security and privacy concerns. Moreover, extensive research indicates that unlearning methods and prevalent attacks fulfill diverse roles within MU systems. For instance, unlearning can act as a mechanism to recover models from backdoor attacks, while backdoor attacks themselves can serve as an evaluation metric for unlearning effectiveness. This underscores the intricate relationship and complex interplay among these mechanisms in maintaining system functionality and safety. This survey aims to fill the gap between the extensive number of studies on threats, attacks, and defenses in machine unlearning and the absence of a comprehensive review that categorizes their taxonomy, methods, and solutions, thus offering valuable insights for future research directions and practical implementations.
Robust and Scalable Model Editing for Large Language Models
Mar 26, 2024



Large language models (LLMs) can make predictions using parametric knowledge--knowledge encoded in the model weights--or contextual knowledge--knowledge presented in the context. In many scenarios, a desirable behavior is that LLMs give precedence to contextual knowledge when it conflicts with the parametric knowledge, and fall back to using their parametric knowledge when the context is irrelevant. This enables updating and correcting the model's knowledge by in-context editing instead of retraining. Previous works have shown that LLMs are inclined to ignore contextual knowledge and fail to reliably fall back to parametric knowledge when presented with irrelevant context. In this work, we discover that, with proper prompting methods, instruction-finetuned LLMs can be highly controllable by contextual knowledge and robust to irrelevant context. Utilizing this feature, we propose EREN (Edit models by REading Notes) to improve the scalability and robustness of LLM editing. To better evaluate the robustness of model editors, we collect a new dataset, that contains irrelevant questions that are more challenging than the ones in existing datasets. Empirical results show that our method outperforms current state-of-the-art methods by a large margin. Unlike existing techniques, it can integrate knowledge from multiple edits, and correctly respond to syntactically similar but semantically unrelated inputs (and vice versa). The source code can be found at https://github.com/thunlp/EREN.
Large Language Model-informed ECG Dual Attention Network for Heart Failure Risk Prediction
Mar 22, 2024



Heart failure (HF) poses a significant public health challenge, with a rising global mortality rate. Early detection and prevention of HF could significantly reduce its impact. We introduce a novel methodology for predicting HF risk using 12-lead electrocardiograms (ECGs). We present a novel, lightweight dual-attention ECG network designed to capture complex ECG features essential for early HF risk prediction, despite the notable imbalance between low and high-risk groups. This network incorporates a cross-lead attention module and twelve lead-specific temporal attention modules, focusing on cross-lead interactions and each lead's local dynamics. To further alleviate model overfitting, we leverage a large language model (LLM) with a public ECG-Report dataset for pretraining on an ECG-report alignment task. The network is then fine-tuned for HF risk prediction using two specific cohorts from the UK Biobank study, focusing on patients with hypertension (UKB-HYP) and those who have had a myocardial infarction (UKB-MI).The results reveal that LLM-informed pre-training substantially enhances HF risk prediction in these cohorts. The dual-attention design not only improves interpretability but also predictive accuracy, outperforming existing competitive methods with C-index scores of 0.6349 for UKB-HYP and 0.5805 for UKB-MI. This demonstrates our method's potential in advancing HF risk assessment with clinical complex ECG data.
FedMef: Towards Memory-efficient Federated Dynamic Pruning
Mar 21, 2024Federated learning (FL) promotes decentralized training while prioritizing data confidentiality. However, its application on resource-constrained devices is challenging due to the high demand for computation and memory resources to train deep learning models. Neural network pruning techniques, such as dynamic pruning, could enhance model efficiency, but directly adopting them in FL still poses substantial challenges, including post-pruning performance degradation, high activation memory usage, etc. To address these challenges, we propose FedMef, a novel and memory-efficient federated dynamic pruning framework. FedMef comprises two key components. First, we introduce the budget-aware extrusion that maintains pruning efficiency while preserving post-pruning performance by salvaging crucial information from parameters marked for pruning within a given budget. Second, we propose scaled activation pruning to effectively reduce activation memory footprints, which is particularly beneficial for deploying FL to memory-limited devices. Extensive experiments demonstrate the effectiveness of our proposed FedMef. In particular, it achieves a significant reduction of 28.5% in memory footprint compared to state-of-the-art methods while obtaining superior accuracy.
Multimodal Variational Autoencoder for Low-cost Cardiac Hemodynamics Instability Detection
Mar 20, 2024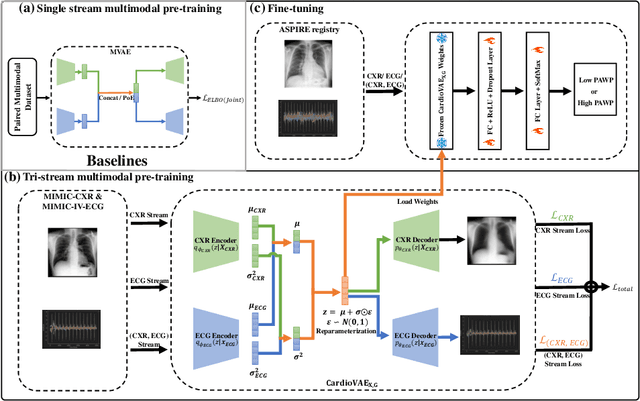
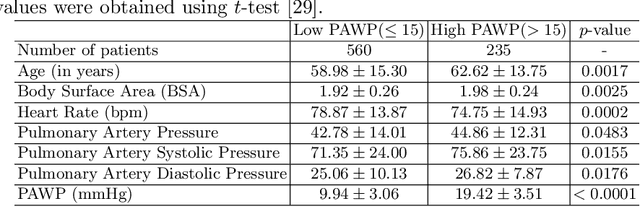
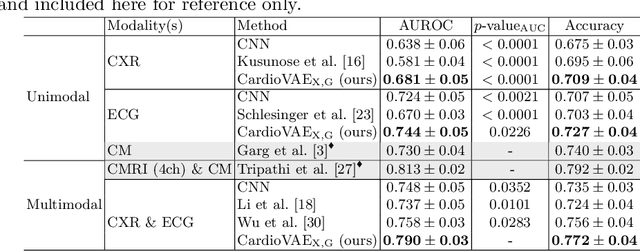
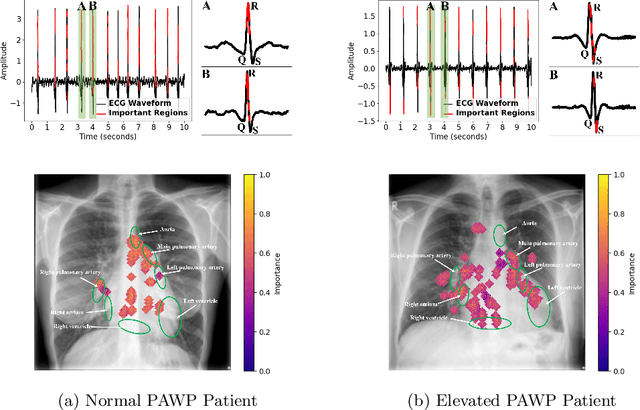
Recent advancements in non-invasive detection of cardiac hemodynamic instability (CHDI) primarily focus on applying machine learning techniques to a single data modality, e.g. cardiac magnetic resonance imaging (MRI). Despite their potential, these approaches often fall short especially when the size of labeled patient data is limited, a common challenge in the medical domain. Furthermore, only a few studies have explored multimodal methods to study CHDI, which mostly rely on costly modalities such as cardiac MRI and echocardiogram. In response to these limitations, we propose a novel multimodal variational autoencoder ($\text{CardioVAE}_\text{X,G}$) to integrate low-cost chest X-ray (CXR) and electrocardiogram (ECG) modalities with pre-training on a large unlabeled dataset. Specifically, $\text{CardioVAE}_\text{X,G}$ introduces a novel tri-stream pre-training strategy to learn both shared and modality-specific features, thus enabling fine-tuning with both unimodal and multimodal datasets. We pre-train $\text{CardioVAE}_\text{X,G}$ on a large, unlabeled dataset of $50,982$ subjects from a subset of MIMIC database and then fine-tune the pre-trained model on a labeled dataset of $795$ subjects from the ASPIRE registry. Comprehensive evaluations against existing methods show that $\text{CardioVAE}_\text{X,G}$ offers promising performance (AUROC $=0.79$ and Accuracy $=0.77$), representing a significant step forward in non-invasive prediction of CHDI. Our model also excels in producing fine interpretations of predictions directly associated with clinical features, thereby supporting clinical decision-making.
A Dual-Augmentor Framework for Domain Generalization in 3D Human Pose Estimation
Mar 20, 2024



3D human pose data collected in controlled laboratory settings present challenges for pose estimators that generalize across diverse scenarios. To address this, domain generalization is employed. Current methodologies in domain generalization for 3D human pose estimation typically utilize adversarial training to generate synthetic poses for training. Nonetheless, these approaches exhibit several limitations. First, the lack of prior information about the target domain complicates the application of suitable augmentation through a single pose augmentor, affecting generalization on target domains. Moreover, adversarial training's discriminator tends to enforce similarity between source and synthesized poses, impeding the exploration of out-of-source distributions. Furthermore, the pose estimator's optimization is not exposed to domain shifts, limiting its overall generalization ability. To address these limitations, we propose a novel framework featuring two pose augmentors: the weak and the strong augmentors. Our framework employs differential strategies for generation and discrimination processes, facilitating the preservation of knowledge related to source poses and the exploration of out-of-source distributions without prior information about target poses. Besides, we leverage meta-optimization to simulate domain shifts in the optimization process of the pose estimator, thereby improving its generalization ability. Our proposed approach significantly outperforms existing methods, as demonstrated through comprehensive experiments on various benchmark datasets.Our code will be released at \url{https://github.com/davidpengucf/DAF-DG}.