 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGathering Strength, Gathering Storms: The One Hundred Year Study on Artificial Intelligence (AI100) 2021 Study Panel Report
Oct 27, 2022In September 2021, the "One Hundred Year Study on Artificial Intelligence" project (AI100) issued the second report of its planned long-term periodic assessment of artificial intelligence (AI) and its impact on society. It was written by a panel of 17 study authors, each of whom is deeply rooted in AI research, chaired by Michael Littman of Brown University. The report, entitled "Gathering Strength, Gathering Storms," answers a set of 14 questions probing critical areas of AI development addressing the major risks and dangers of AI, its effects on society, its public perception and the future of the field. The report concludes that AI has made a major leap from the lab to people's lives in recent years, which increases the urgency to understand its potential negative effects. The questions were developed by the AI100 Standing Committee, chaired by Peter Stone of the University of Texas at Austin, consisting of a group of AI leaders with expertise in computer science, sociology, ethics, economics, and other disciplines.
Hard Attention Control By Mutual Information Maximization
Mar 10, 2021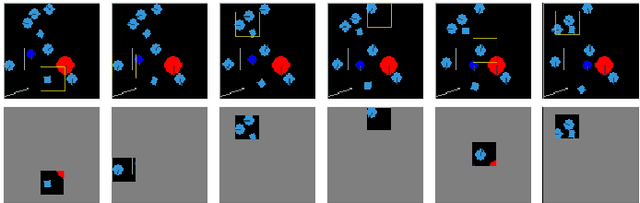

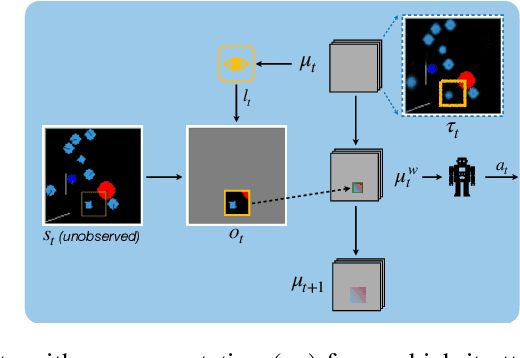
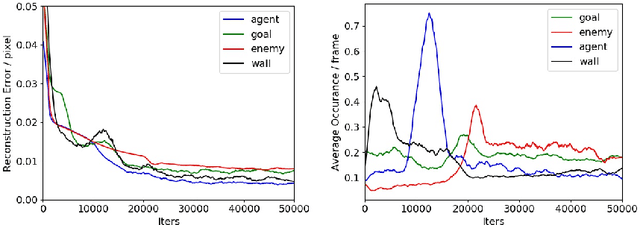
Biological agents have adopted the principle of attention to limit the rate of incoming information from the environment. One question that arises is if an artificial agent has access to only a limited view of its surroundings, how can it control its attention to effectively solve tasks? We propose an approach for learning how to control a hard attention window by maximizing the mutual information between the environment state and the attention location at each step. The agent employs an internal world model to make predictions about its state and focuses attention towards where the predictions may be wrong. Attention is trained jointly with a dynamic memory architecture that stores partial observations and keeps track of the unobserved state. We demonstrate that our approach is effective in predicting the full state from a sequence of partial observations. We also show that the agent's internal representation of the surroundings, a live mental map, can be used for control in two partially observable reinforcement learning tasks. Videos of the trained agent can be found at https://sites.google.com/view/hard-attention-control.
A Bayesian Framework for Nash Equilibrium Inference in Human-Robot Parallel Play
Jun 10, 2020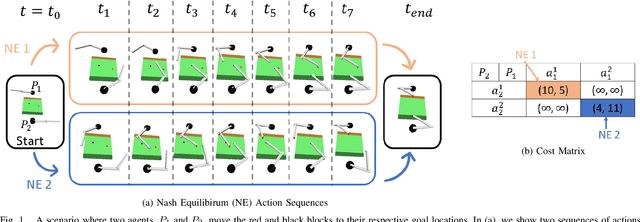
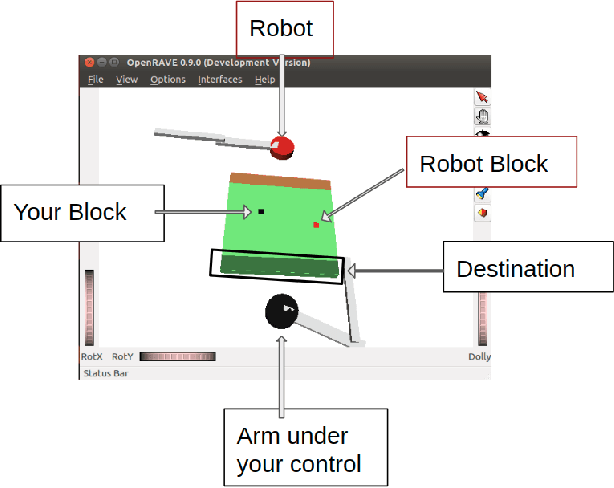
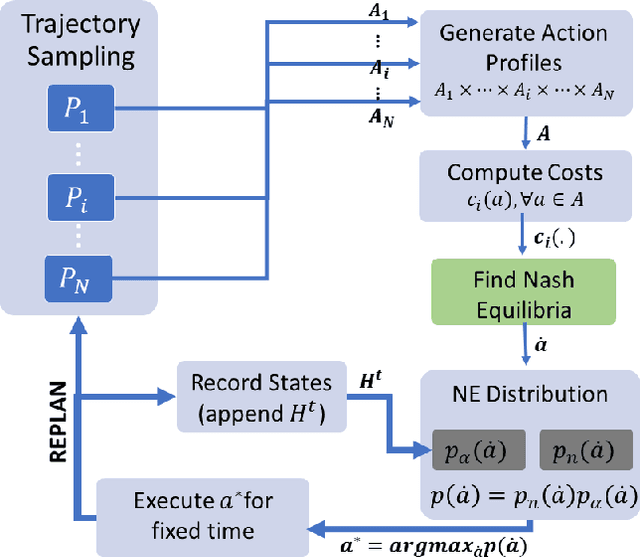
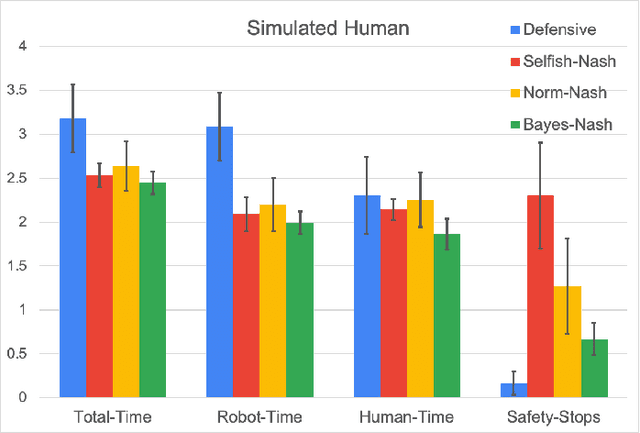
We consider shared workspace scenarios with humans and robots acting to achieve independent goals, termed as parallel play. We model these as general-sum games and construct a framework that utilizes the Nash equilibrium solution concept to consider the interactive effect of both agents while planning. We find multiple Pareto-optimal equilibria in these tasks. We hypothesize that people act by choosing an equilibrium based on social norms and their personalities. To enable coordination, we infer the equilibrium online using a probabilistic model that includes these two factors and use it to select the robot's action. We apply our approach to a close-proximity pick-and-place task involving a robot and a simulated human with three potential behaviors - defensive, selfish, and norm-following. We showed that using a Bayesian approach to infer the equilibrium enables the robot to complete the task with less than half the number of collisions while also reducing the task execution time as compared to the best baseline. We also performed a study with human participants interacting either with other humans or with different robot agents and observed that our proposed approach performs similar to human-human parallel play interactions. The code is available at https://github.com/shray/bayes-nash
Supportive Actions for Manipulation in Human-Robot Coworker Teams
May 02, 2020
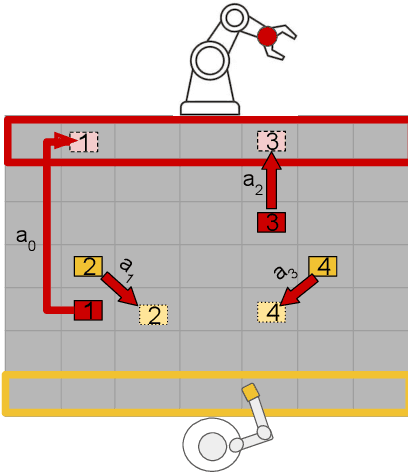
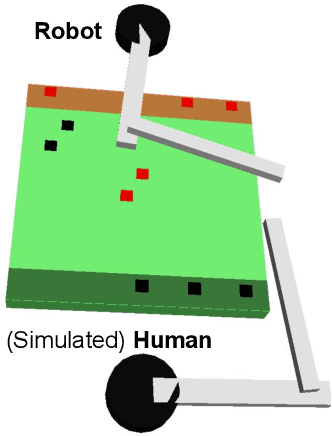

The increasing presence of robots alongside humans, such as in human-robot teams in manufacturing, gives rise to research questions about the kind of behaviors people prefer in their robot counterparts. We term actions that support interaction by reducing future interference with others as supportive robot actions and investigate their utility in a co-located manipulation scenario. We compare two robot modes in a shared table pick-and-place task: (1) Task-oriented: the robot only takes actions to further its own task objective and (2) Supportive: the robot sometimes prefers supportive actions to task-oriented ones when they reduce future goal-conflicts. Our experiments in simulation, using a simplified human model, reveal that supportive actions reduce the interference between agents, especially in more difficult tasks, but also cause the robot to take longer to complete the task. We implemented these modes on a physical robot in a user study where a human and a robot perform object placement on a shared table. Our results show that a supportive robot was perceived as a more favorable coworker by the human and also reduced interference with the human in the more difficult of two scenarios. However, it also took longer to complete the task highlighting an interesting trade-off between task-efficiency and human-preference that needs to be considered before designing robot behavior for close-proximity manipulation scenarios.
Estimating Q(s,s') with Deep Deterministic Dynamics Gradients
Feb 21, 2020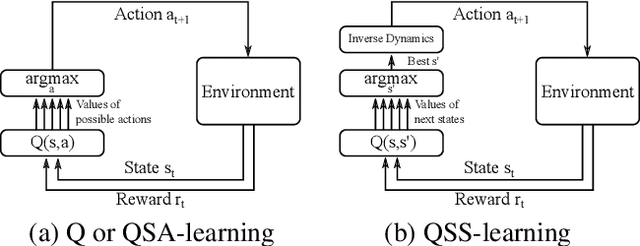
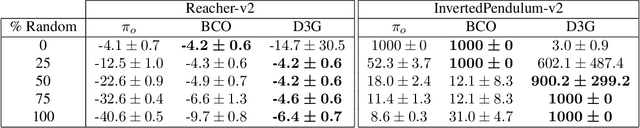
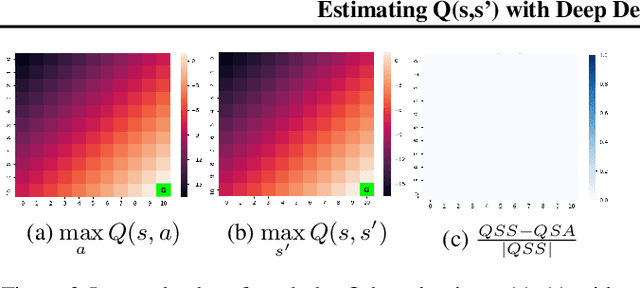
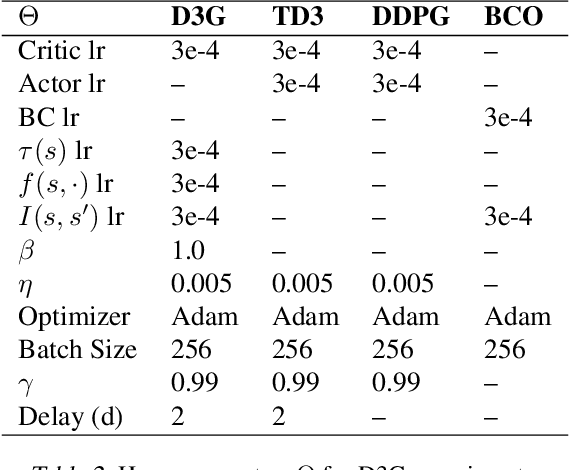
In this paper, we introduce a novel form of value function, $Q(s, s')$, that expresses the utility of transitioning from a state $s$ to a neighboring state $s'$ and then acting optimally thereafter. In order to derive an optimal policy, we develop a forward dynamics model that learns to make next-state predictions that maximize this value. This formulation decouples actions from values while still learning off-policy. We highlight the benefits of this approach in terms of value function transfer, learning within redundant action spaces, and learning off-policy from state observations generated by sub-optimal or completely random policies. Code and videos are available at \url{sites.google.com/view/qss-paper}.
Universal Value Density Estimation for Imitation Learning and Goal-Conditioned Reinforcement Learning
Feb 15, 2020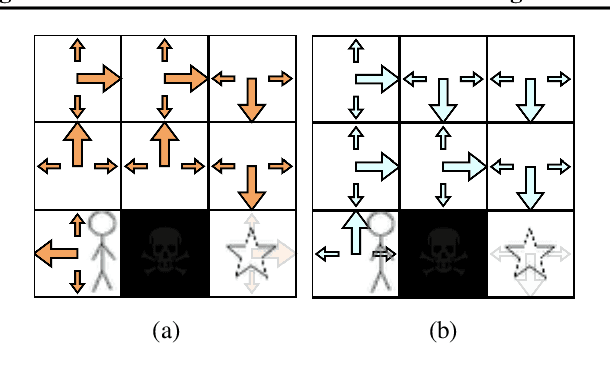
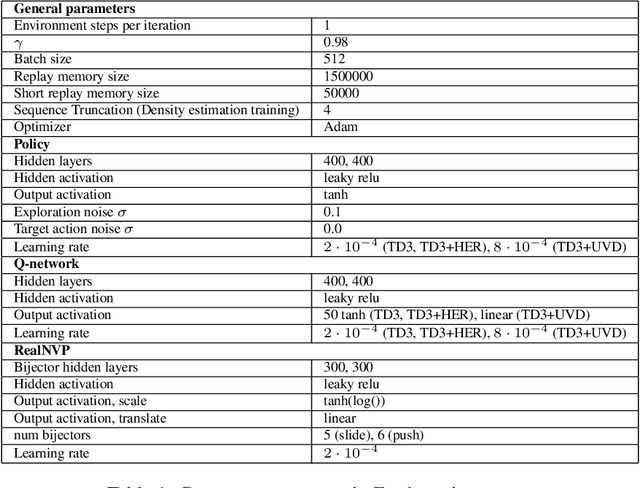
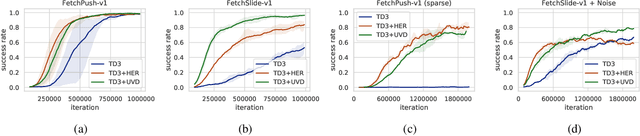
This work considers two distinct settings: imitation learning and goal-conditioned reinforcement learning. In either case, effective solutions require the agent to reliably reach a specified state (a goal), or set of states (a demonstration). Drawing a connection between probabilistic long-term dynamics and the desired value function, this work introduces an approach which utilizes recent advances in density estimation to effectively learn to reach a given state. As our first contribution, we use this approach for goal-conditioned reinforcement learning and show that it is both efficient and does not suffer from hindsight bias in stochastic domains. As our second contribution, we extend the approach to imitation learning and show that it achieves state-of-the art demonstration sample-efficiency on standard benchmark tasks.
Learning to Compose Skills
Nov 30, 2017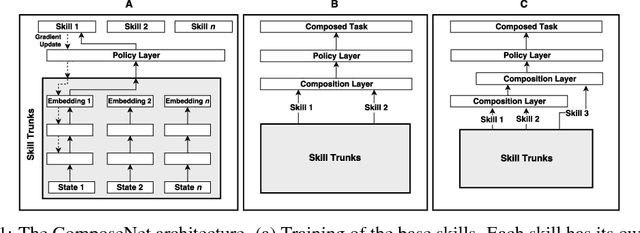
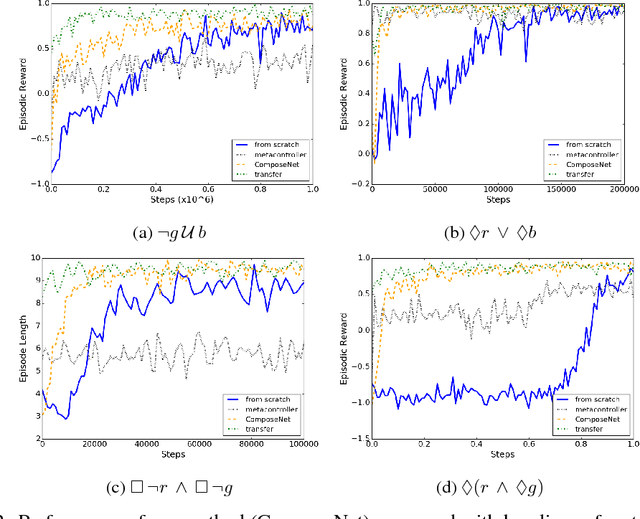
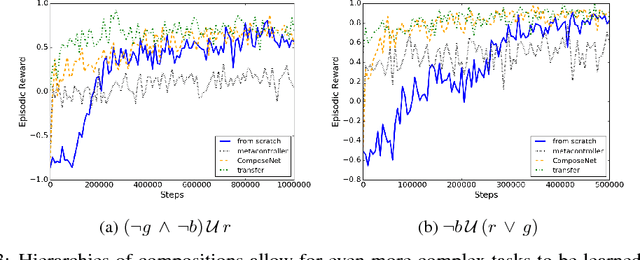
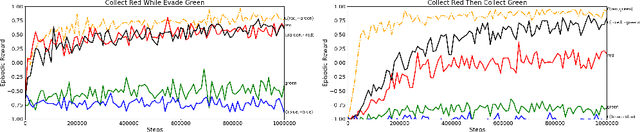
We present a differentiable framework capable of learning a wide variety of compositions of simple policies that we call skills. By recursively composing skills with themselves, we can create hierarchies that display complex behavior. Skill networks are trained to generate skill-state embeddings that are provided as inputs to a trainable composition function, which in turn outputs a policy for the overall task. Our experiments on an environment consisting of multiple collect and evade tasks show that this architecture is able to quickly build complex skills from simpler ones. Furthermore, the learned composition function displays some transfer to unseen combinations of skills, allowing for zero-shot generalizations.
State Space Decomposition and Subgoal Creation for Transfer in Deep Reinforcement Learning
May 24, 2017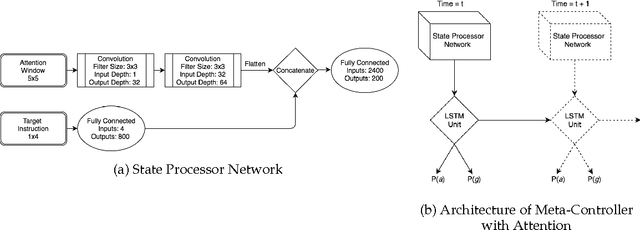
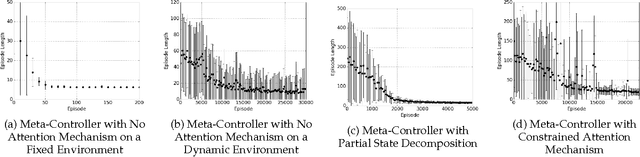
Typical reinforcement learning (RL) agents learn to complete tasks specified by reward functions tailored to their domain. As such, the policies they learn do not generalize even to similar domains. To address this issue, we develop a framework through which a deep RL agent learns to generalize policies from smaller, simpler domains to more complex ones using a recurrent attention mechanism. The task is presented to the agent as an image and an instruction specifying the goal. This meta-controller guides the agent towards its goal by designing a sequence of smaller subtasks on the part of the state space within the attention, effectively decomposing it. As a baseline, we consider a setup without attention as well. Our experiments show that the meta-controller learns to create subgoals within the attention.
Environment-Independent Task Specifications via GLTL
Apr 14, 2017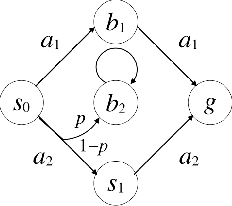
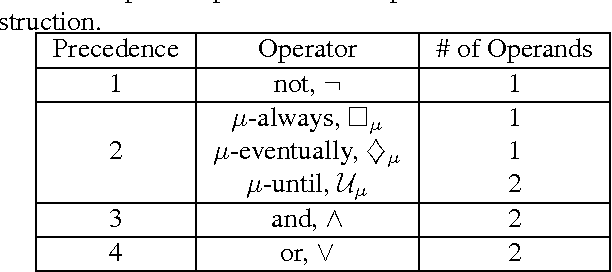
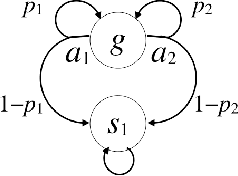
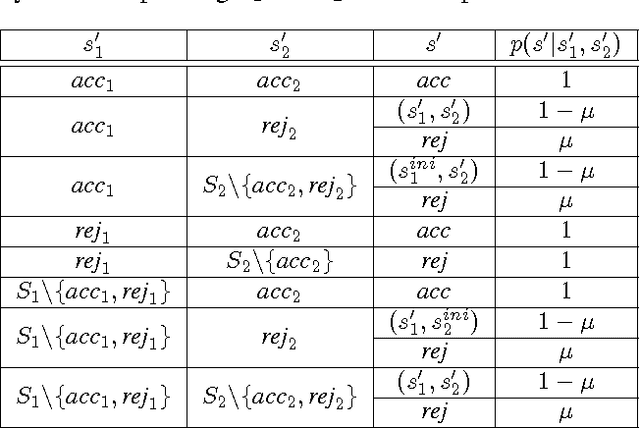
We propose a new task-specification language for Markov decision processes that is designed to be an improvement over reward functions by being environment independent. The language is a variant of Linear Temporal Logic (LTL) that is extended to probabilistic specifications in a way that permits approximations to be learned in finite time. We provide several small environments that demonstrate the advantages of our geometric LTL (GLTL) language and illustrate how it can be used to specify standard reinforcement-learning tasks straightforwardly.
Perceptual Reward Functions
Aug 12, 2016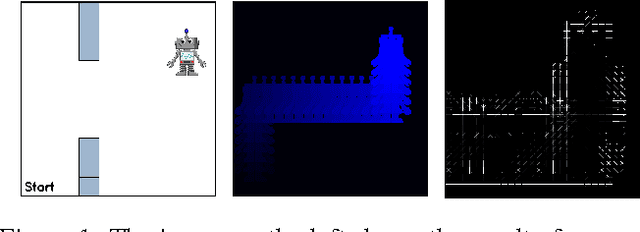


Reinforcement learning problems are often described through rewards that indicate if an agent has completed some task. This specification can yield desirable behavior, however many problems are difficult to specify in this manner, as one often needs to know the proper configuration for the agent. When humans are learning to solve tasks, we often learn from visual instructions composed of images or videos. Such representations motivate our development of Perceptual Reward Functions, which provide a mechanism for creating visual task descriptions. We show that this approach allows an agent to learn from rewards that are based on raw pixels rather than internal parameters.