 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINGeo: Accelerating Instant Neural Scene Reconstruction with Noisy Geometry Priors
Dec 05, 2022



We present a method that accelerates reconstruction of 3D scenes and objects, aiming to enable instant reconstruction on edge devices such as mobile phones and AR/VR headsets. While recent works have accelerated scene reconstruction training to minute/second-level on high-end GPUs, there is still a large gap to the goal of instant training on edge devices which is yet highly desired in many emerging applications such as immersive AR/VR. To this end, this work aims to further accelerate training by leveraging geometry priors of the target scene. Our method proposes strategies to alleviate the noise of the imperfect geometry priors to accelerate the training speed on top of the highly optimized Instant-NGP. On the NeRF Synthetic dataset, our work uses half of the training iterations to reach an average test PSNR of >30.
ViTALiTy: Unifying Low-rank and Sparse Approximation for Vision Transformer Acceleration with a Linear Taylor Attention
Nov 09, 2022Vision Transformer (ViT) has emerged as a competitive alternative to convolutional neural networks for various computer vision applications. Specifically, ViT multi-head attention layers make it possible to embed information globally across the overall image. Nevertheless, computing and storing such attention matrices incurs a quadratic cost dependency on the number of patches, limiting its achievable efficiency and scalability and prohibiting more extensive real-world ViT applications on resource-constrained devices. Sparse attention has been shown to be a promising direction for improving hardware acceleration efficiency for NLP models. However, a systematic counterpart approach is still missing for accelerating ViT models. To close the above gap, we propose a first-of-its-kind algorithm-hardware codesigned framework, dubbed ViTALiTy, for boosting the inference efficiency of ViTs. Unlike sparsity-based Transformer accelerators for NLP, ViTALiTy unifies both low-rank and sparse components of the attention in ViTs. At the algorithm level, we approximate the dot-product softmax operation via first-order Taylor attention with row-mean centering as the low-rank component to linearize the cost of attention blocks and further boost the accuracy by incorporating a sparsity-based regularization. At the hardware level, we develop a dedicated accelerator to better leverage the resulting workload and pipeline from ViTALiTy's linear Taylor attention which requires the execution of only the low-rank component, to further boost the hardware efficiency. Extensive experiments and ablation studies validate that ViTALiTy offers boosted end-to-end efficiency (e.g., $3\times$ faster and $3\times$ energy-efficient) under comparable accuracy, with respect to the state-of-the-art solution.
ViTCoD: Vision Transformer Acceleration via Dedicated Algorithm and Accelerator Co-Design
Oct 18, 2022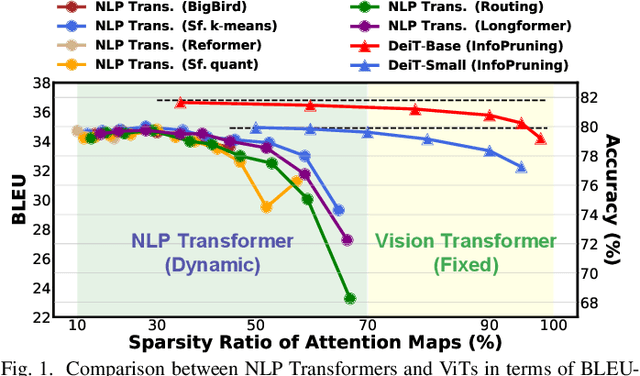
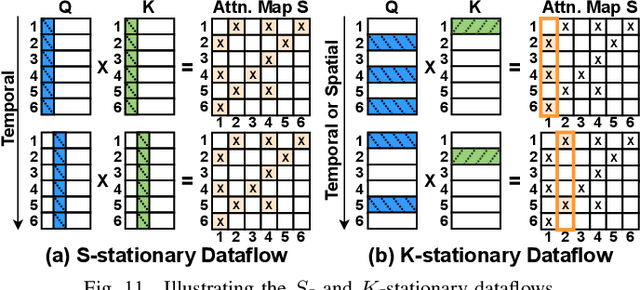
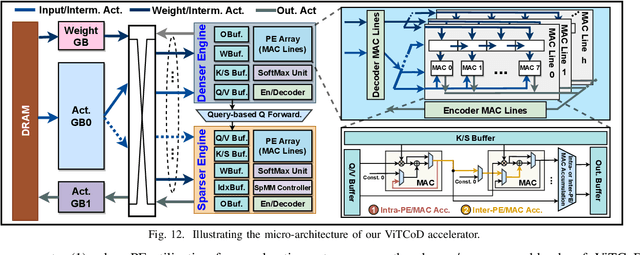
Vision Transformers (ViTs) have achieved state-of-the-art performance on various vision tasks. However, ViTs' self-attention module is still arguably a major bottleneck, limiting their achievable hardware efficiency. Meanwhile, existing accelerators dedicated to NLP Transformers are not optimal for ViTs. This is because there is a large difference between ViTs and NLP Transformers: ViTs have a relatively fixed number of input tokens, whose attention maps can be pruned by up to 90% even with fixed sparse patterns; while NLP Transformers need to handle input sequences of varying numbers of tokens and rely on on-the-fly predictions of dynamic sparse attention patterns for each input to achieve a decent sparsity (e.g., >=50%). To this end, we propose a dedicated algorithm and accelerator co-design framework dubbed ViTCoD for accelerating ViTs. Specifically, on the algorithm level, ViTCoD prunes and polarizes the attention maps to have either denser or sparser fixed patterns for regularizing two levels of workloads without hurting the accuracy, largely reducing the attention computations while leaving room for alleviating the remaining dominant data movements; on top of that, we further integrate a lightweight and learnable auto-encoder module to enable trading the dominant high-cost data movements for lower-cost computations. On the hardware level, we develop a dedicated accelerator to simultaneously coordinate the enforced denser/sparser workloads and encoder/decoder engines for boosted hardware utilization. Extensive experiments and ablation studies validate that ViTCoD largely reduces the dominant data movement costs, achieving speedups of up to 235.3x, 142.9x, 86.0x, 10.1x, and 6.8x over general computing platforms CPUs, EdgeGPUs, GPUs, and prior-art Transformer accelerators SpAtten and Sanger under an attention sparsity of 90%, respectively.
MIA-Former: Efficient and Robust Vision Transformers via Multi-grained Input-Adaptation
Dec 21, 2021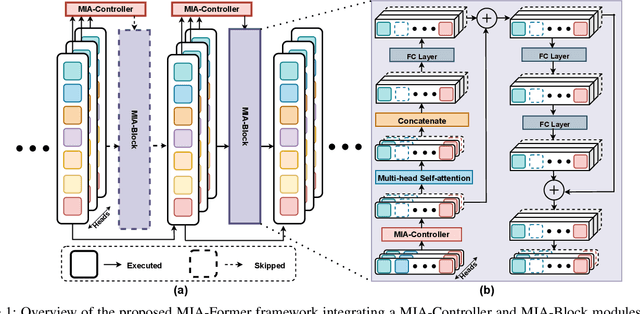
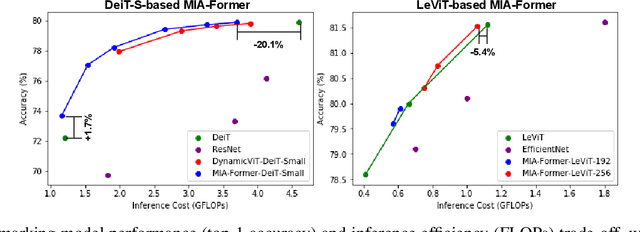
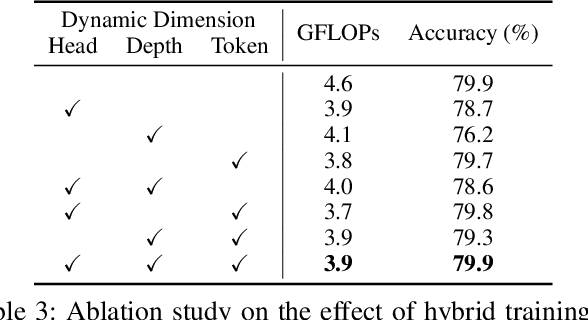
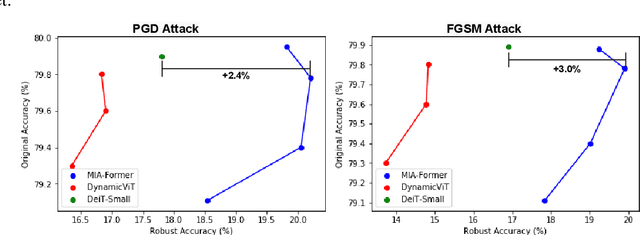
ViTs are often too computationally expensive to be fitted onto real-world resource-constrained devices, due to (1) their quadratically increased complexity with the number of input tokens and (2) their overparameterized self-attention heads and model depth. In parallel, different images are of varied complexity and their different regions can contain various levels of visual information, indicating that treating all regions/tokens equally in terms of model complexity is unnecessary while such opportunities for trimming down ViTs' complexity have not been fully explored. To this end, we propose a Multi-grained Input-adaptive Vision Transformer framework dubbed MIA-Former that can input-adaptively adjust the structure of ViTs at three coarse-to-fine-grained granularities (i.e., model depth and the number of model heads/tokens). In particular, our MIA-Former adopts a low-cost network trained with a hybrid supervised and reinforcement training method to skip unnecessary layers, heads, and tokens in an input adaptive manner, reducing the overall computational cost. Furthermore, an interesting side effect of our MIA-Former is that its resulting ViTs are naturally equipped with improved robustness against adversarial attacks over their static counterparts, because MIA-Former's multi-grained dynamic control improves the model diversity similar to the effect of ensemble and thus increases the difficulty of adversarial attacks against all its sub-models. Extensive experiments and ablation studies validate that the proposed MIA-Former framework can effectively allocate computation budgets adaptive to the difficulty of input images meanwhile increase robustness, achieving state-of-the-art (SOTA) accuracy-efficiency trade-offs, e.g., 20% computation savings with the same or even a higher accuracy compared with SOTA dynamic transformer models.
FBNetV5: Neural Architecture Search for Multiple Tasks in One Run
Nov 30, 2021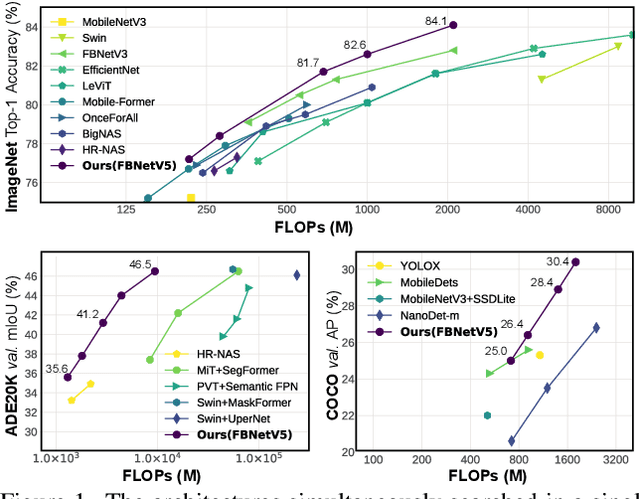
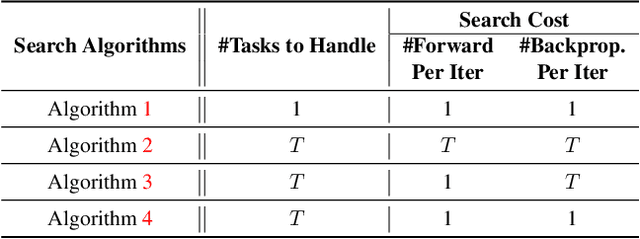
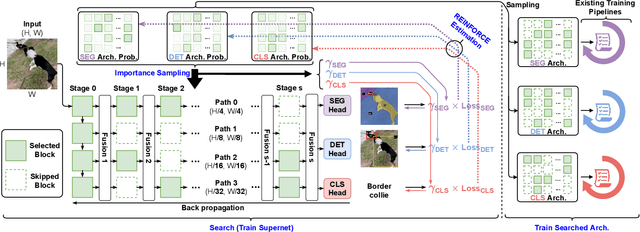
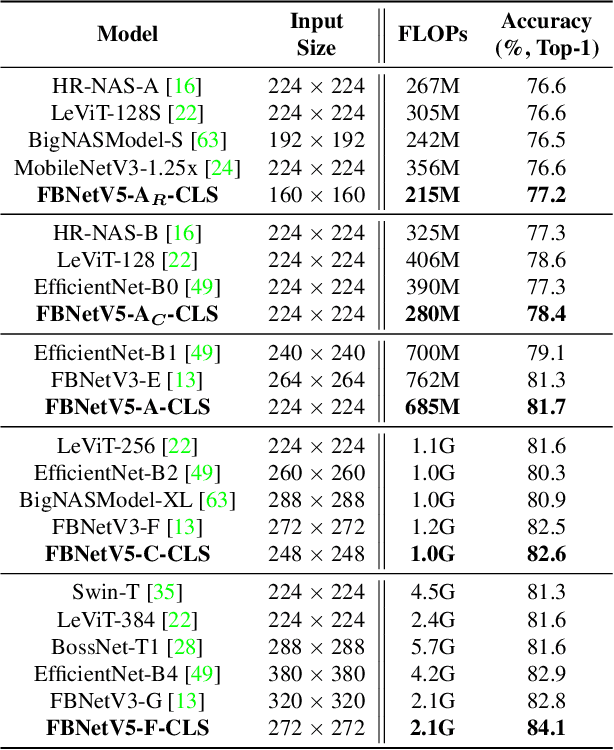
Neural Architecture Search (NAS) has been widely adopted to design accurate and efficient image classification models. However, applying NAS to a new computer vision task still requires a huge amount of effort. This is because 1) previous NAS research has been over-prioritized on image classification while largely ignoring other tasks; 2) many NAS works focus on optimizing task-specific components that cannot be favorably transferred to other tasks; and 3) existing NAS methods are typically designed to be "proxyless" and require significant effort to be integrated with each new task's training pipelines. To tackle these challenges, we propose FBNetV5, a NAS framework that can search for neural architectures for a variety of vision tasks with much reduced computational cost and human effort. Specifically, we design 1) a search space that is simple yet inclusive and transferable; 2) a multitask search process that is disentangled with target tasks' training pipeline; and 3) an algorithm to simultaneously search for architectures for multiple tasks with a computational cost agnostic to the number of tasks. We evaluate the proposed FBNetV5 targeting three fundamental vision tasks -- image classification, object detection, and semantic segmentation. Models searched by FBNetV5 in a single run of search have outperformed the previous stateof-the-art in all the three tasks: image classification (e.g., +1.3% ImageNet top-1 accuracy under the same FLOPs as compared to FBNetV3), semantic segmentation (e.g., +1.8% higher ADE20K val. mIoU than SegFormer with 3.6x fewer FLOPs), and object detection (e.g., +1.1% COCO val. mAP with 1.2x fewer FLOPs as compared to YOLOX).
2-in-1 Accelerator: Enabling Random Precision Switch for Winning Both Adversarial Robustness and Efficiency
Sep 21, 2021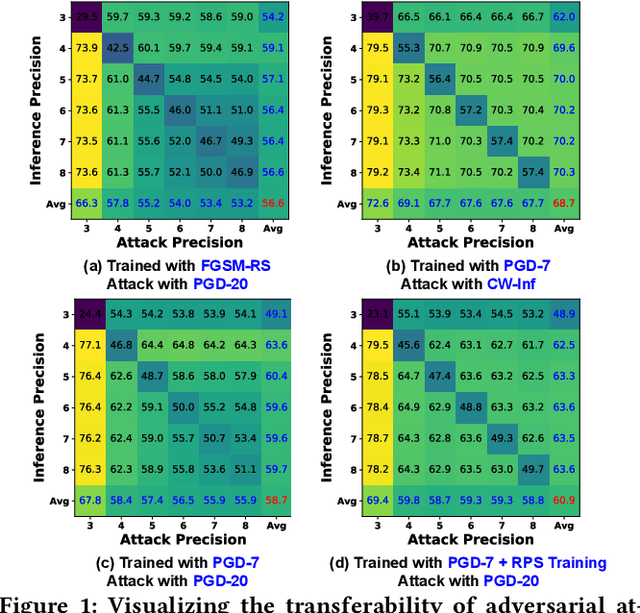
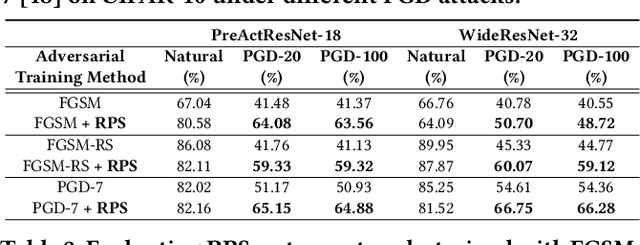
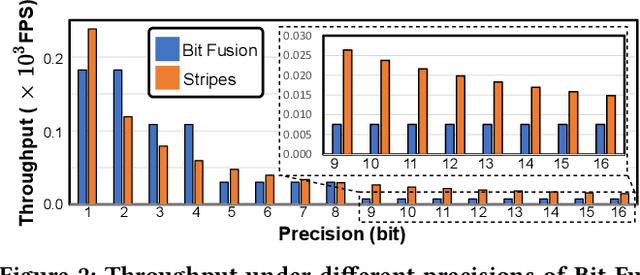
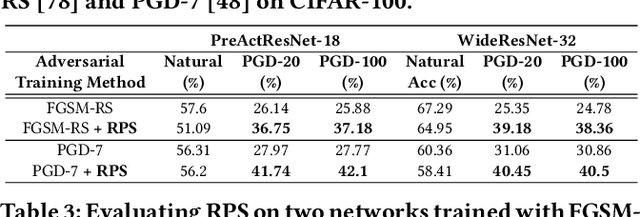
The recent breakthroughs of deep neural networks (DNNs) and the advent of billions of Internet of Things (IoT) devices have excited an explosive demand for intelligent IoT devices equipped with domain-specific DNN accelerators. However, the deployment of DNN accelerator enabled intelligent functionality into real-world IoT devices still remains particularly challenging. First, powerful DNNs often come at prohibitive complexities, whereas IoT devices often suffer from stringent resource constraints. Second, while DNNs are vulnerable to adversarial attacks especially on IoT devices exposed to complex real-world environments, many IoT applications require strict security. Existing DNN accelerators mostly tackle only one of the two aforementioned challenges (i.e., efficiency or adversarial robustness) while neglecting or even sacrificing the other. To this end, we propose a 2-in-1 Accelerator, an integrated algorithm-accelerator co-design framework aiming at winning both the adversarial robustness and efficiency of DNN accelerators. Specifically, we first propose a Random Precision Switch (RPS) algorithm that can effectively defend DNNs against adversarial attacks by enabling random DNN quantization as an in-situ model switch. Furthermore, we propose a new precision-scalable accelerator featuring (1) a new precision-scalable MAC unit architecture which spatially tiles the temporal MAC units to boost both the achievable efficiency and flexibility and (2) a systematically optimized dataflow that is searched by our generic accelerator optimizer. Extensive experiments and ablation studies validate that our 2-in-1 Accelerator can not only aggressively boost both the adversarial robustness and efficiency of DNN accelerators under various attacks, but also naturally support instantaneous robustness-efficiency trade-offs adapting to varied resources without the necessity of DNN retraining.
DANCE: DAta-Network Co-optimization for Efficient Segmentation Model Training and Inference
Jul 16, 2021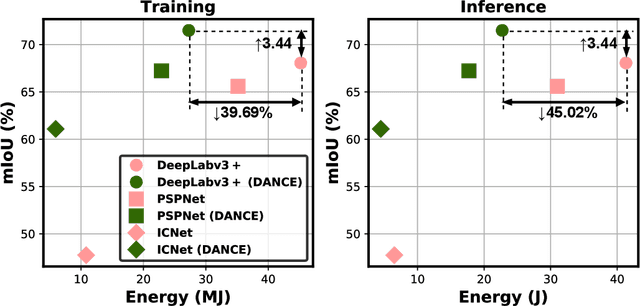
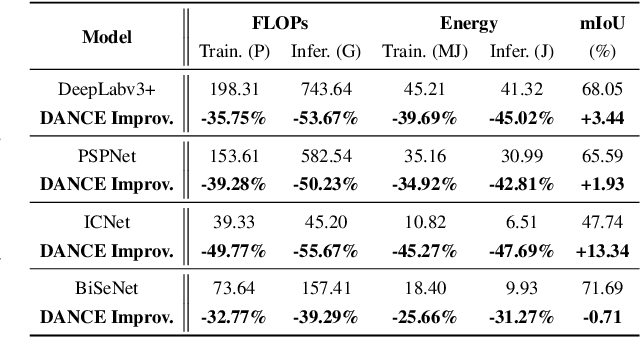
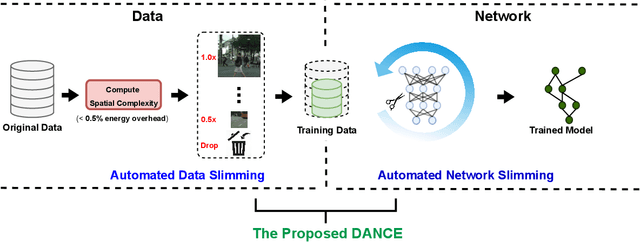
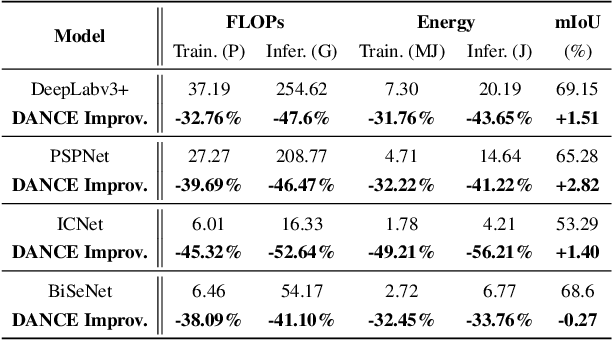
Semantic segmentation for scene understanding is nowadays widely demanded, raising significant challenges for the algorithm efficiency, especially its applications on resource-limited platforms. Current segmentation models are trained and evaluated on massive high-resolution scene images ("data level") and suffer from the expensive computation arising from the required multi-scale aggregation("network level"). In both folds, the computational and energy costs in training and inference are notable due to the often desired large input resolutions and heavy computational burden of segmentation models. To this end, we propose DANCE, general automated DAta-Network Co-optimization for Efficient segmentation model training and inference. Distinct from existing efficient segmentation approaches that focus merely on light-weight network design, DANCE distinguishes itself as an automated simultaneous data-network co-optimization via both input data manipulation and network architecture slimming. Specifically, DANCE integrates automated data slimming which adaptively downsamples/drops input images and controls their corresponding contribution to the training loss guided by the images' spatial complexity. Such a downsampling operation, in addition to slimming down the cost associated with the input size directly, also shrinks the dynamic range of input object and context scales, therefore motivating us to also adaptively slim the network to match the downsampled data. Extensive experiments and ablating studies (on four SOTA segmentation models with three popular segmentation datasets under two training settings) demonstrate that DANCE can achieve "all-win" towards efficient segmentation(reduced training cost, less expensive inference, and better mean Intersection-over-Union (mIoU)).
A3C-S: Automated Agent Accelerator Co-Search towards Efficient Deep Reinforcement Learning
Jun 11, 2021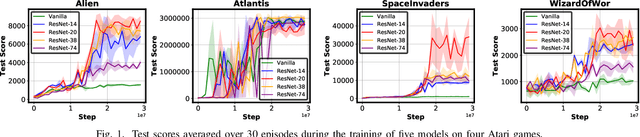
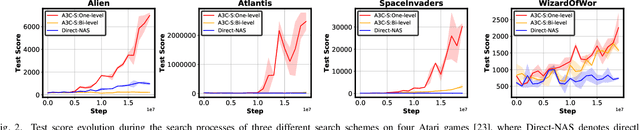
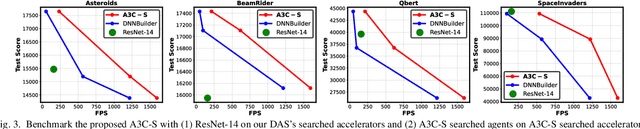
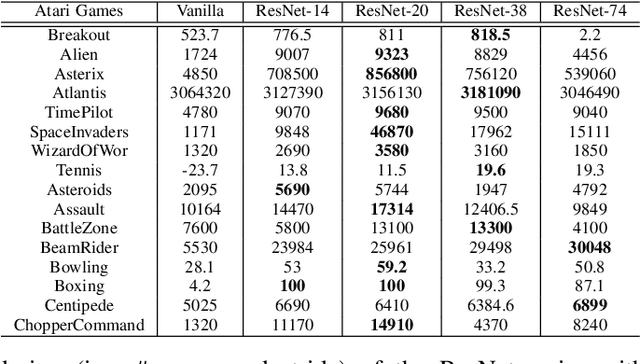
Driven by the explosive interest in applying deep reinforcement learning (DRL) agents to numerous real-time control and decision-making applications, there has been a growing demand to deploy DRL agents to empower daily-life intelligent devices, while the prohibitive complexity of DRL stands at odds with limited on-device resources. In this work, we propose an Automated Agent Accelerator Co-Search (A3C-S) framework, which to our best knowledge is the first to automatically co-search the optimally matched DRL agents and accelerators that maximize both test scores and hardware efficiency. Extensive experiments consistently validate the superiority of our A3C-S over state-of-the-art techniques.
InstantNet: Automated Generation and Deployment of Instantaneously Switchable-Precision Networks
Apr 22, 2021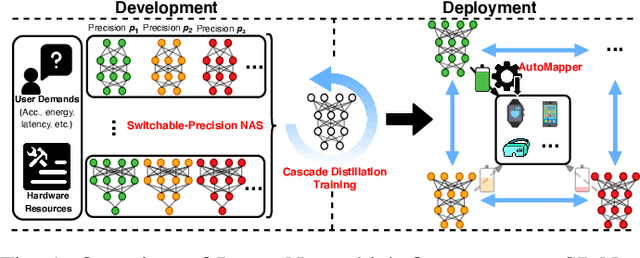
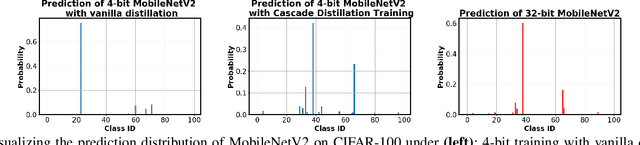
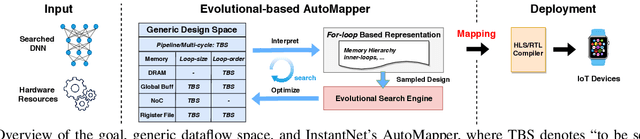
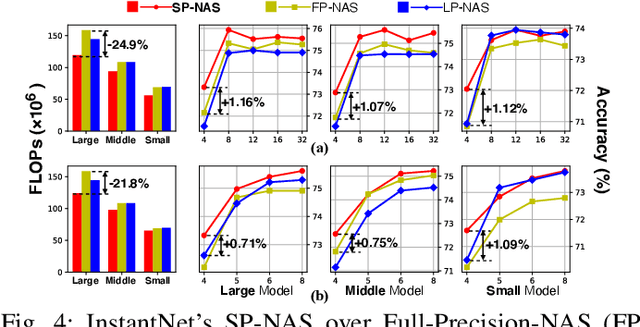
The promise of Deep Neural Network (DNN) powered Internet of Thing (IoT) devices has motivated a tremendous demand for automated solutions to enable fast development and deployment of efficient (1) DNNs equipped with instantaneous accuracy-efficiency trade-off capability to accommodate the time-varying resources at IoT devices and (2) dataflows to optimize DNNs' execution efficiency on different devices. Therefore, we propose InstantNet to automatically generate and deploy instantaneously switchable-precision networks which operate at variable bit-widths. Extensive experiments show that the proposed InstantNet consistently outperforms state-of-the-art designs.
HW-NAS-Bench:Hardware-Aware Neural Architecture Search Benchmark
Mar 19, 2021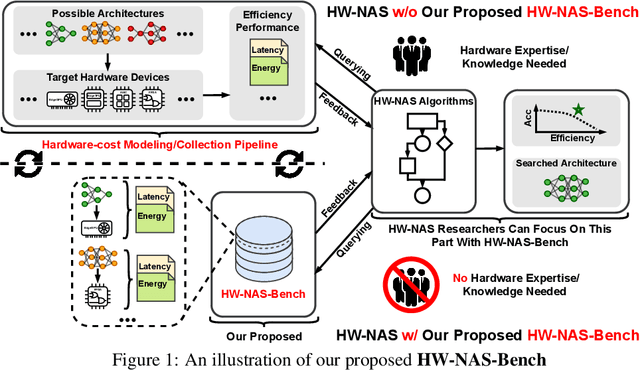
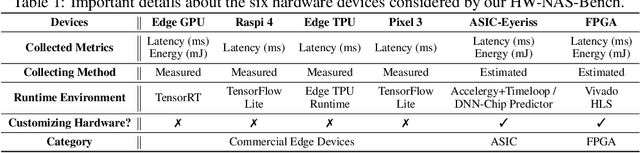
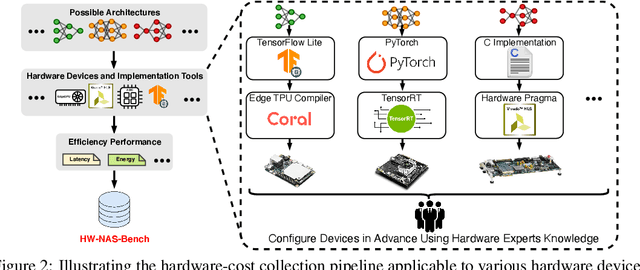

HardWare-aware Neural Architecture Search (HW-NAS) has recently gained tremendous attention by automating the design of DNNs deployed in more resource-constrained daily life devices. Despite its promising performance, developing optimal HW-NAS solutions can be prohibitively challenging as it requires cross-disciplinary knowledge in the algorithm, micro-architecture, and device-specific compilation. First, to determine the hardware-cost to be incorporated into the NAS process, existing works mostly adopt either pre-collected hardware-cost look-up tables or device-specific hardware-cost models. Both of them limit the development of HW-NAS innovations and impose a barrier-to-entry to non-hardware experts. Second, similar to generic NAS, it can be notoriously difficult to benchmark HW-NAS algorithms due to their significant required computational resources and the differences in adopted search spaces, hyperparameters, and hardware devices. To this end, we develop HW-NAS-Bench, the first public dataset for HW-NAS research which aims to democratize HW-NAS research to non-hardware experts and make HW-NAS research more reproducible and accessible. To design HW-NAS-Bench, we carefully collected the measured/estimated hardware performance of all the networks in the search spaces of both NAS-Bench-201 and FBNet, on six hardware devices that fall into three categories (i.e., commercial edge devices, FPGA, and ASIC). Furthermore, we provide a comprehensive analysis of the collected measurements in HW-NAS-Bench to provide insights for HW-NAS research. Finally, we demonstrate exemplary user cases to (1) show that HW-NAS-Bench allows non-hardware experts to perform HW-NAS by simply querying it and (2) verify that dedicated device-specific HW-NAS can indeed lead to optimal accuracy-cost trade-offs. The codes and all collected data are available at https://github.com/RICE-EIC/HW-NAS-Bench.