 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdv-Attribute: Inconspicuous and Transferable Adversarial Attack on Face Recognition
Oct 13, 2022
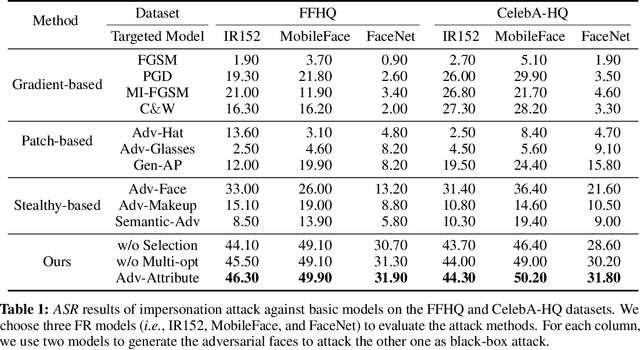
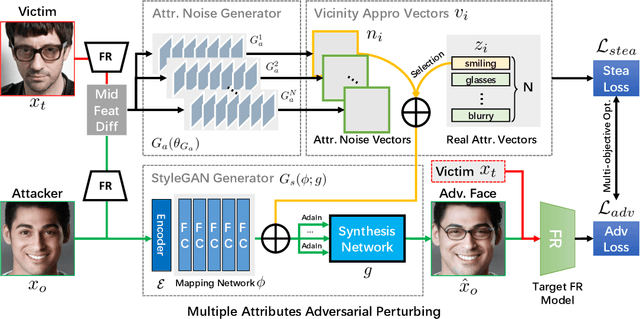
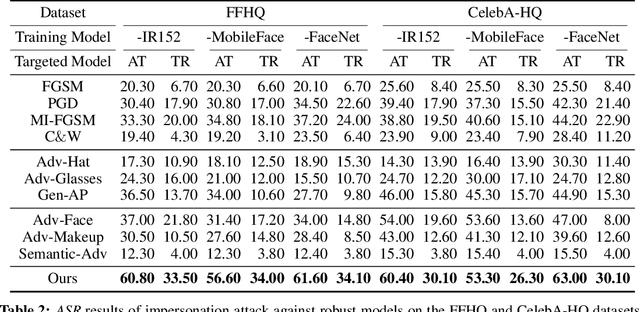
Deep learning models have shown their vulnerability when dealing with adversarial attacks. Existing attacks almost perform on low-level instances, such as pixels and super-pixels, and rarely exploit semantic clues. For face recognition attacks, existing methods typically generate the l_p-norm perturbations on pixels, however, resulting in low attack transferability and high vulnerability to denoising defense models. In this work, instead of performing perturbations on the low-level pixels, we propose to generate attacks through perturbing on the high-level semantics to improve attack transferability. Specifically, a unified flexible framework, Adversarial Attributes (Adv-Attribute), is designed to generate inconspicuous and transferable attacks on face recognition, which crafts the adversarial noise and adds it into different attributes based on the guidance of the difference in face recognition features from the target. Moreover, the importance-aware attribute selection and the multi-objective optimization strategy are introduced to further ensure the balance of stealthiness and attacking strength. Extensive experiments on the FFHQ and CelebA-HQ datasets show that the proposed Adv-Attribute method achieves the state-of-the-art attacking success rates while maintaining better visual effects against recent attack methods.
The Asymmetric Maximum Margin Bias of Quasi-Homogeneous Neural Networks
Oct 07, 2022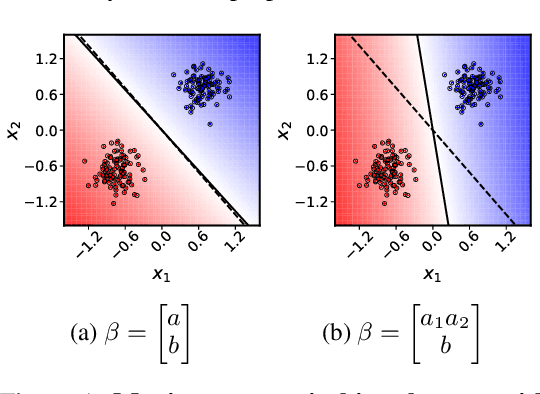
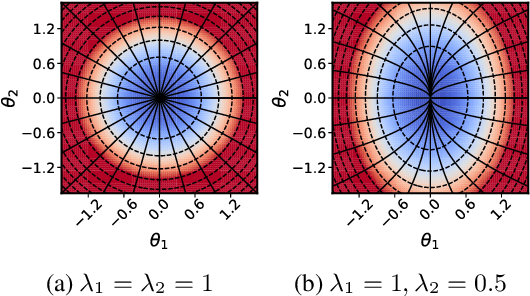
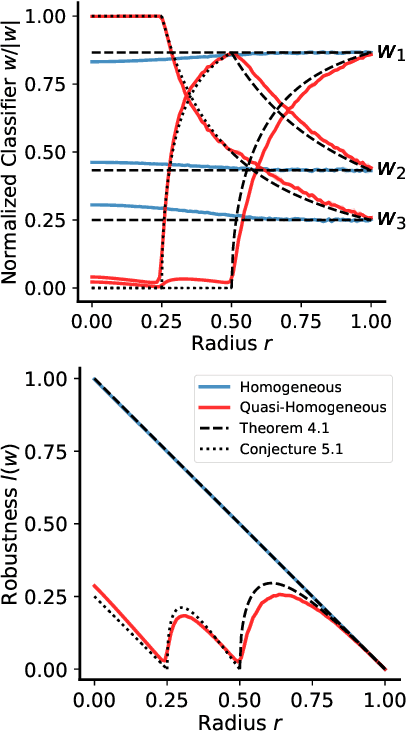
In this work, we explore the maximum-margin bias of quasi-homogeneous neural networks trained with gradient flow on an exponential loss and past a point of separability. We introduce the class of quasi-homogeneous models, which is expressive enough to describe nearly all neural networks with homogeneous activations, even those with biases, residual connections, and normalization layers, while structured enough to enable geometric analysis of its gradient dynamics. Using this analysis, we generalize the existing results of maximum-margin bias for homogeneous networks to this richer class of models. We find that gradient flow implicitly favors a subset of the parameters, unlike in the case of a homogeneous model where all parameters are treated equally. We demonstrate through simple examples how this strong favoritism toward minimizing an asymmetric norm can degrade the robustness of quasi-homogeneous models. On the other hand, we conjecture that this norm-minimization discards, when possible, unnecessary higher-order parameters, reducing the model to a sparser parameterization. Lastly, by applying our theorem to sufficiently expressive neural networks with normalization layers, we reveal a universal mechanism behind the empirical phenomenon of Neural Collapse.
Removing Rain Streaks via Task Transfer Learning
Aug 28, 2022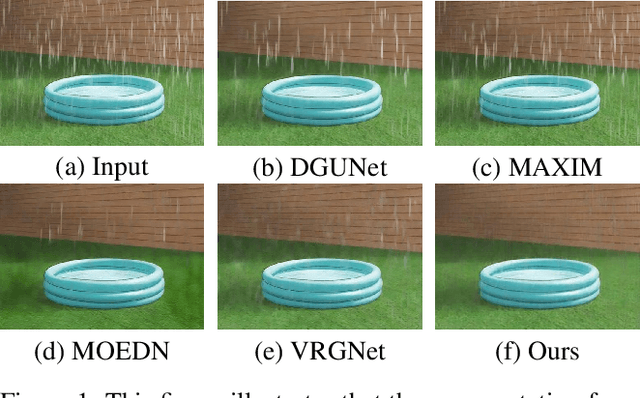
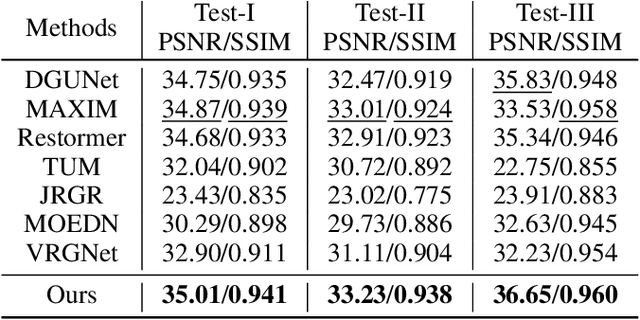

Due to the difficulty in collecting paired real-world training data, image deraining is currently dominated by supervised learning with synthesized data generated by e.g., Photoshop rendering. However, the generalization to real rainy scenes is usually limited due to the gap between synthetic and real-world data. In this paper, we first statistically explore why the supervised deraining models cannot generalize well to real rainy cases, and find the substantial difference of synthetic and real rainy data. Inspired by our studies, we propose to remove rain by learning favorable deraining representations from other connected tasks. In connected tasks, the label for real data can be easily obtained. Hence, our core idea is to learn representations from real data through task transfer to improve deraining generalization. We thus term our learning strategy as \textit{task transfer learning}. If there are more than one connected tasks, we propose to reduce model size by knowledge distillation. The pretrained models for the connected tasks are treated as teachers, all their knowledge is distilled to a student network, so that we reduce the model size, meanwhile preserve effective prior representations from all the connected tasks. At last, the student network is fine-tuned with minority of paired synthetic rainy data to guide the pretrained prior representations to remove rain. Extensive experiments demonstrate that proposed task transfer learning strategy is surprisingly successful and compares favorably with state-of-the-art supervised learning methods and apparently surpass other semi-supervised deraining methods on synthetic data. Particularly, it shows superior generalization over them to real-world scenes.
H2-Stereo: High-Speed, High-Resolution Stereoscopic Video System
Aug 04, 2022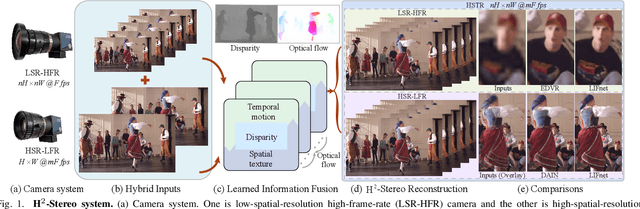



High-speed, high-resolution stereoscopic (H2-Stereo) video allows us to perceive dynamic 3D content at fine granularity. The acquisition of H2-Stereo video, however, remains challenging with commodity cameras. Existing spatial super-resolution or temporal frame interpolation methods provide compromised solutions that lack temporal or spatial details, respectively. To alleviate this problem, we propose a dual camera system, in which one camera captures high-spatial-resolution low-frame-rate (HSR-LFR) videos with rich spatial details, and the other captures low-spatial-resolution high-frame-rate (LSR-HFR) videos with smooth temporal details. We then devise a Learned Information Fusion network (LIFnet) that exploits the cross-camera redundancies to enhance both camera views to high spatiotemporal resolution (HSTR) for reconstructing the H2-Stereo video effectively. We utilize a disparity network to transfer spatiotemporal information across views even in large disparity scenes, based on which, we propose disparity-guided flow-based warping for LSR-HFR view and complementary warping for HSR-LFR view. A multi-scale fusion method in feature domain is proposed to minimize occlusion-induced warping ghosts and holes in HSR-LFR view. The LIFnet is trained in an end-to-end manner using our collected high-quality Stereo Video dataset from YouTube. Extensive experiments demonstrate that our model outperforms existing state-of-the-art methods for both views on synthetic data and camera-captured real data with large disparity. Ablation studies explore various aspects, including spatiotemporal resolution, camera baseline, camera desynchronization, long/short exposures and applications, of our system to fully understand its capability for potential applications.
AiATrack: Attention in Attention for Transformer Visual Tracking
Jul 22, 2022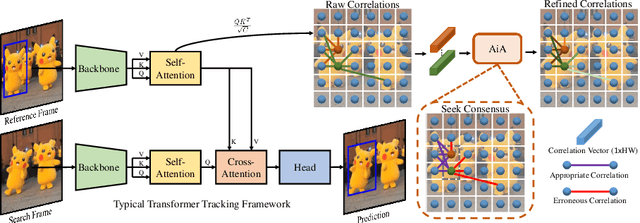
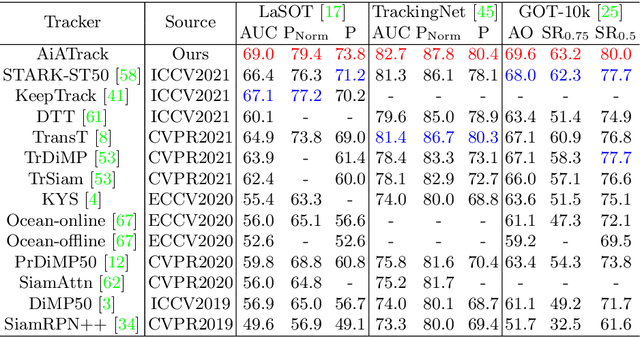
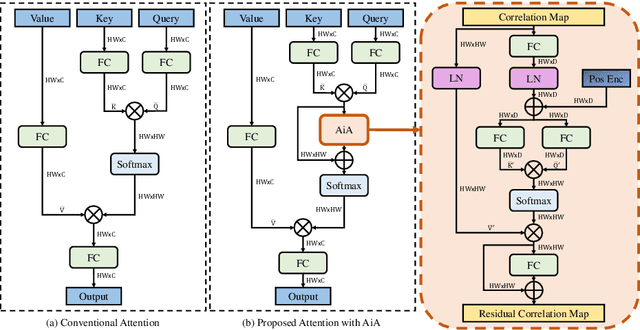
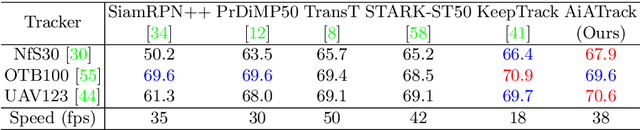
Transformer trackers have achieved impressive advancements recently, where the attention mechanism plays an important role. However, the independent correlation computation in the attention mechanism could result in noisy and ambiguous attention weights, which inhibits further performance improvement. To address this issue, we propose an attention in attention (AiA) module, which enhances appropriate correlations and suppresses erroneous ones by seeking consensus among all correlation vectors. Our AiA module can be readily applied to both self-attention blocks and cross-attention blocks to facilitate feature aggregation and information propagation for visual tracking. Moreover, we propose a streamlined Transformer tracking framework, dubbed AiATrack, by introducing efficient feature reuse and target-background embeddings to make full use of temporal references. Experiments show that our tracker achieves state-of-the-art performance on six tracking benchmarks while running at a real-time speed.
Depth-Adapted CNNs for RGB-D Semantic Segmentation
Jun 08, 2022
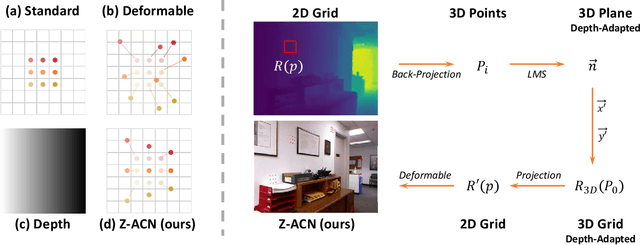
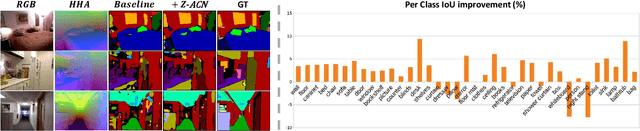
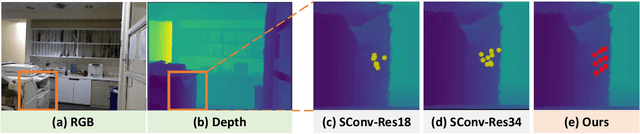
Recent RGB-D semantic segmentation has motivated research interest thanks to the accessibility of complementary modalities from the input side. Existing works often adopt a two-stream architecture that processes photometric and geometric information in parallel, with few methods explicitly leveraging the contribution of depth cues to adjust the sampling position on RGB images. In this paper, we propose a novel framework to incorporate the depth information in the RGB convolutional neural network (CNN), termed Z-ACN (Depth-Adapted CNN). Specifically, our Z-ACN generates a 2D depth-adapted offset which is fully constrained by low-level features to guide the feature extraction on RGB images. With the generated offset, we introduce two intuitive and effective operations to replace basic CNN operators: depth-adapted convolution and depth-adapted average pooling. Extensive experiments on both indoor and outdoor semantic segmentation tasks demonstrate the effectiveness of our approach.
Generalization Error Bounds for Deep Neural Networks Trained by SGD
Jun 07, 2022
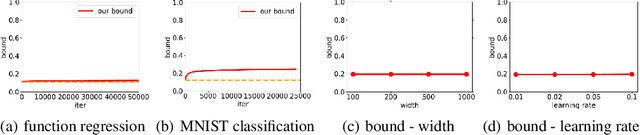
Generalization error bounds for deep neural networks trained by stochastic gradient descent (SGD) are derived by combining a dynamical control of an appropriate parameter norm and the Rademacher complexity estimate based on parameter norms. The bounds explicitly depend on the loss along the training trajectory, and work for a wide range of network architectures including multilayer perceptron (MLP) and convolutional neural networks (CNN). Compared with other algorithm-depending generalization estimates such as uniform stability-based bounds, our bounds do not require $L$-smoothness of the nonconvex loss function, and apply directly to SGD instead of Stochastic Langevin gradient descent (SGLD). Numerical results show that our bounds are non-vacuous and robust with the change of optimizer and network hyperparameters.
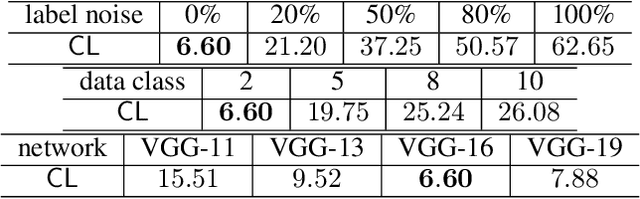
Early Stage Convergence and Global Convergence of Training Mildly Parameterized Neural Networks
Jun 05, 2022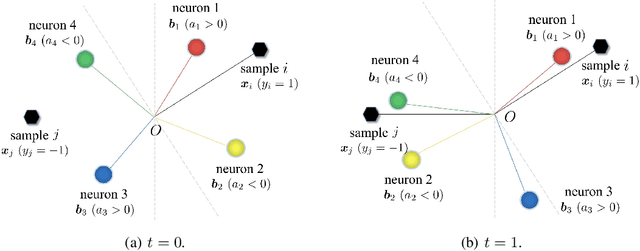
The convergence of GD and SGD when training mildly parameterized neural networks starting from random initialization is studied. For a broad range of models and loss functions, including the most commonly used square loss and cross entropy loss, we prove an ``early stage convergence'' result. We show that the loss is decreased by a significant amount in the early stage of the training, and this decrease is fast. Furthurmore, for exponential type loss functions, and under some assumptions on the training data, we show global convergence of GD. Instead of relying on extreme over-parameterization, our study is based on a microscopic analysis of the activation patterns for the neurons, which helps us derive more powerful lower bounds for the gradient. The results on activation patterns, which we call ``neuron partition'', help build intuitions for understanding the behavior of neural networks' training dynamics, and may be of independent interest.
PillarNet: Real-Time and High-Performance Pillar-based 3D Object Detection
May 19, 2022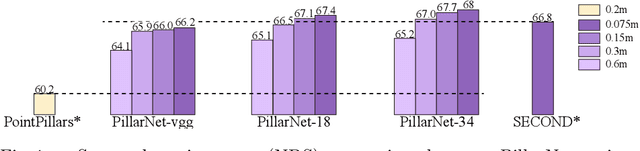
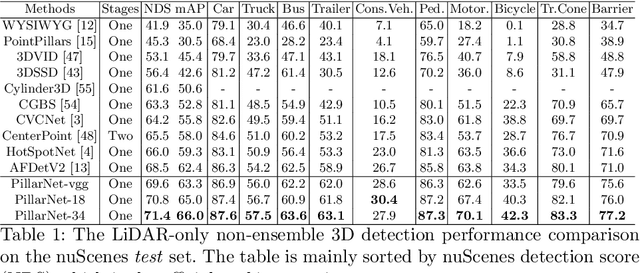
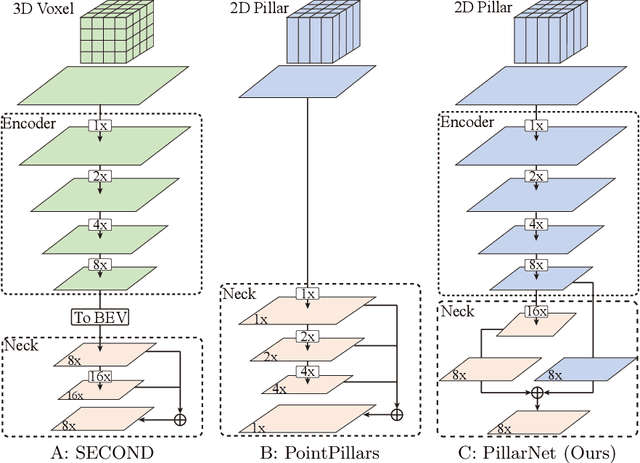

Real-time and high-performance 3D object detection is of critical importance for autonomous driving. Recent top-performing 3D object detectors mainly rely on point-based or 3D voxel-based convolutions, which are both computationally inefficient for onboard deployment. While recent researches focus on point-based or 3D voxel-based convolutions for higher performance, these methods fail to meet latency and power efficiency requirements especially for deployment on embedded devices. In contrast, pillar-based methods use merely 2D convolutions, which consume less computation resources, but they lag far behind their voxel-based counterparts in detection accuracy. However, the superiority of such 3D voxel-based methods over pillar-based methods is still broadly attributed to the effectiveness of 3D convolution neural network (CNN). In this paper, by examining the primary performance gap between pillar- and voxel-based detectors, we develop a real-time and high-performance pillar-based detector, dubbed PillarNet. The proposed PillarNet consists of a powerful encoder network for effective pillar feature learning, a neck network for spatial-semantic feature fusion and the commonly used detect head. Using only 2D convolutions, PillarNet is flexible to an optional pillar size and compatible with classical 2D CNN backbones, such as VGGNet and ResNet. Additionally, PillarNet benefits from our designed orientation-decoupled IoU regression loss along with the IoU-aware prediction branch. Extensive experimental results on large-scale nuScenes Dataset and Waymo Open Dataset demonstrate that the proposed PillarNet performs well over the state-of-the-art 3D detectors in terms of effectiveness and efficiency. Code will be made publicly available.
The Multiscale Structure of Neural Network Loss Functions: The Effect on Optimization and Origin
Apr 24, 2022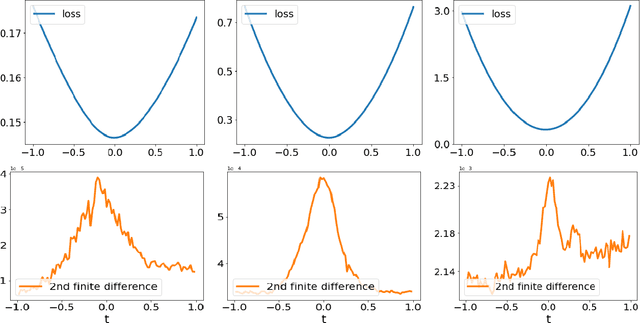
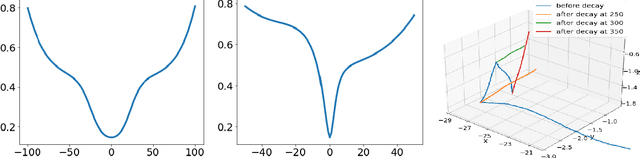
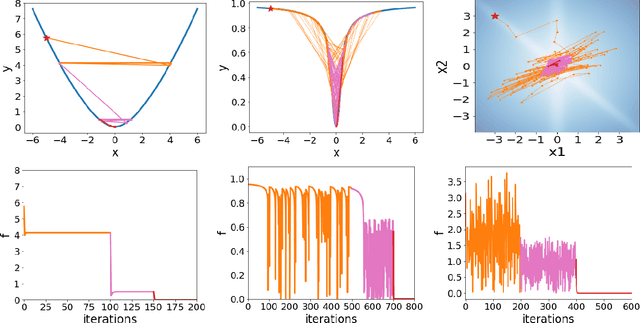
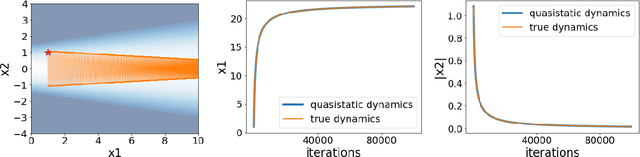
Local quadratic approximation has been extensively used to study the optimization of neural network loss functions around the minimum. Though, it usually holds in a very small neighborhood of the minimum, and cannot explain many phenomena observed during the optimization process. In this work, we study the structure of neural network loss functions and its implication on optimization in a region beyond the reach of good quadratic approximation. Numerically, we observe that neural network loss functions possesses a multiscale structure, manifested in two ways: (1) in a neighborhood of minima, the loss mixes a continuum of scales and grows subquadratically, and (2) in a larger region, the loss shows several separate scales clearly. Using the subquadratic growth, we are able to explain the Edge of Stability phenomenon[4] observed for gradient descent (GD) method. Using the separate scales, we explain the working mechanism of learning rate decay by simple examples. Finally, we study the origin of the multiscale structure and propose that the non-uniformity of training data is one of its cause. By constructing a two-layer neural network problem we show that training data with different magnitudes give rise to different scales of the loss function, producing subquadratic growth or multiple separate scales.