 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChao Huang
When MiniBatch SGD Meets SplitFed Learning:Convergence Analysis and Performance Evaluation
Aug 23, 2023
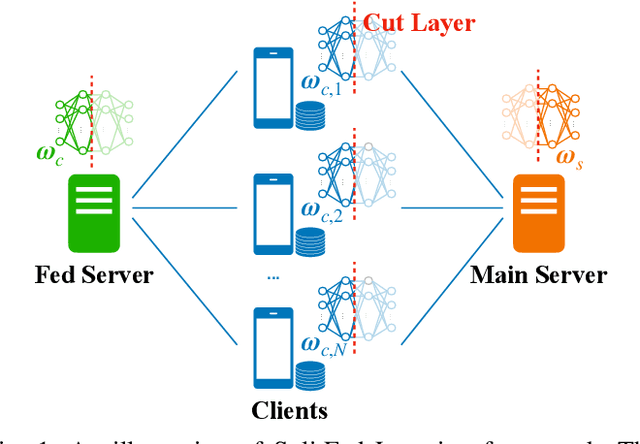
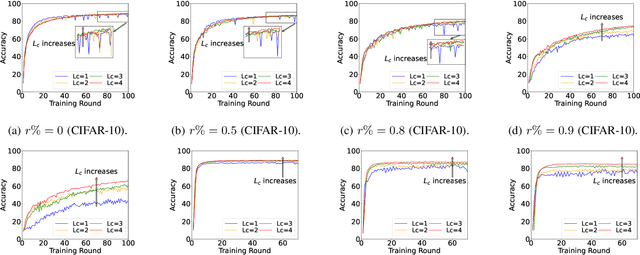
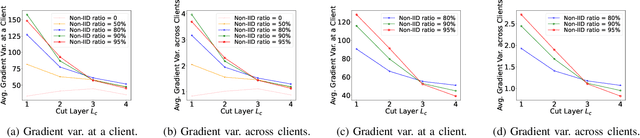
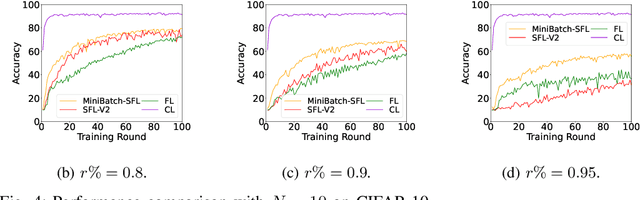
Federated learning (FL) enables collaborative model training across distributed clients (e.g., edge devices) without sharing raw data. Yet, FL can be computationally expensive as the clients need to train the entire model multiple times. SplitFed learning (SFL) is a recent distributed approach that alleviates computation workload at the client device by splitting the model at a cut layer into two parts, where clients only need to train part of the model. However, SFL still suffers from the \textit{client drift} problem when clients' data are highly non-IID. To address this issue, we propose MiniBatch-SFL. This algorithm incorporates MiniBatch SGD into SFL, where the clients train the client-side model in an FL fashion while the server trains the server-side model similar to MiniBatch SGD. We analyze the convergence of MiniBatch-SFL and show that the bound of the expected loss can be obtained by analyzing the expected server-side and client-side model updates, respectively. The server-side updates do not depend on the non-IID degree of the clients' datasets and can potentially mitigate client drift. However, the client-side model relies on the non-IID degree and can be optimized by properly choosing the cut layer. Perhaps counter-intuitive, our empirical result shows that a latter position of the cut layer leads to a smaller average gradient divergence and a better algorithm performance. Moreover, numerical results show that MiniBatch-SFL achieves higher accuracy than conventional SFL and FL. The accuracy improvement can be up to 24.1\% and 17.1\% with highly non-IID data, respectively.
How Expressive are Graph Neural Networks in Recommendation?
Aug 22, 2023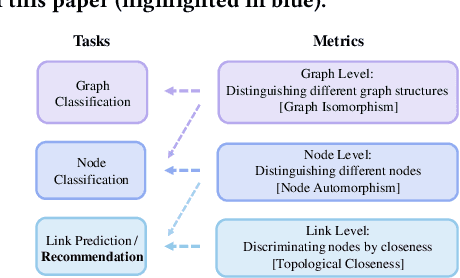
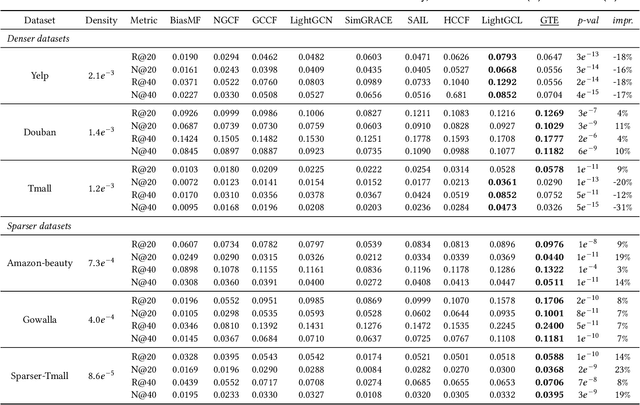
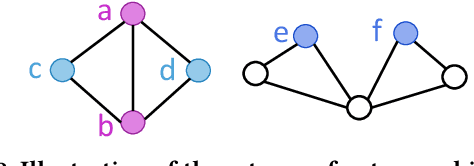
Graph Neural Networks (GNNs) have demonstrated superior performance on various graph learning tasks, including recommendation, where they leverage user-item collaborative filtering signals in graphs. However, theoretical formulations of their capability are scarce, despite their empirical effectiveness in state-of-the-art recommender models. Recently, research has explored the expressiveness of GNNs in general, demonstrating that message passing GNNs are at most as powerful as the Weisfeiler-Lehman test, and that GNNs combined with random node initialization are universal. Nevertheless, the concept of "expressiveness" for GNNs remains vaguely defined. Most existing works adopt the graph isomorphism test as the metric of expressiveness, but this graph-level task may not effectively assess a model's ability in recommendation, where the objective is to distinguish nodes of different closeness. In this paper, we provide a comprehensive theoretical analysis of the expressiveness of GNNs in recommendation, considering three levels of expressiveness metrics: graph isomorphism (graph-level), node automorphism (node-level), and topological closeness (link-level). We propose the topological closeness metric to evaluate GNNs' ability to capture the structural distance between nodes, which aligns closely with the objective of recommendation. To validate the effectiveness of this new metric in evaluating recommendation performance, we introduce a learning-less GNN algorithm that is optimal on the new metric and can be optimal on the node-level metric with suitable modification. We conduct extensive experiments comparing the proposed algorithm against various types of state-of-the-art GNN models to explore the explainability of the new metric in the recommendation task. For reproducibility, implementation codes are available at https://github.com/HKUDS/GTE.
SSLRec: A Self-Supervised Learning Library for Recommendation
Aug 10, 2023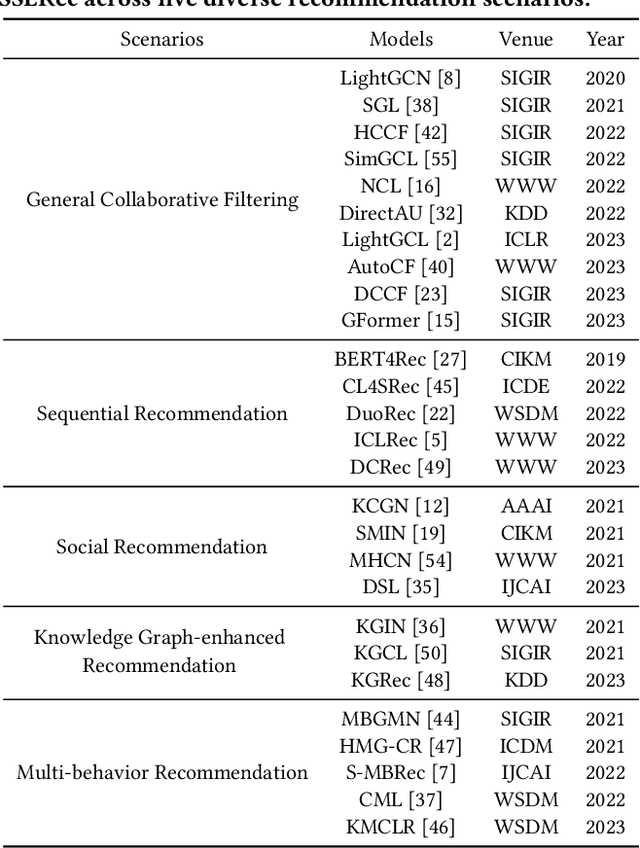
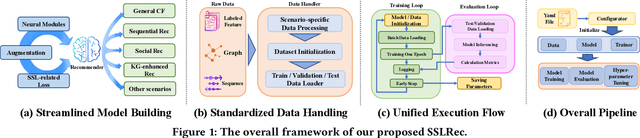
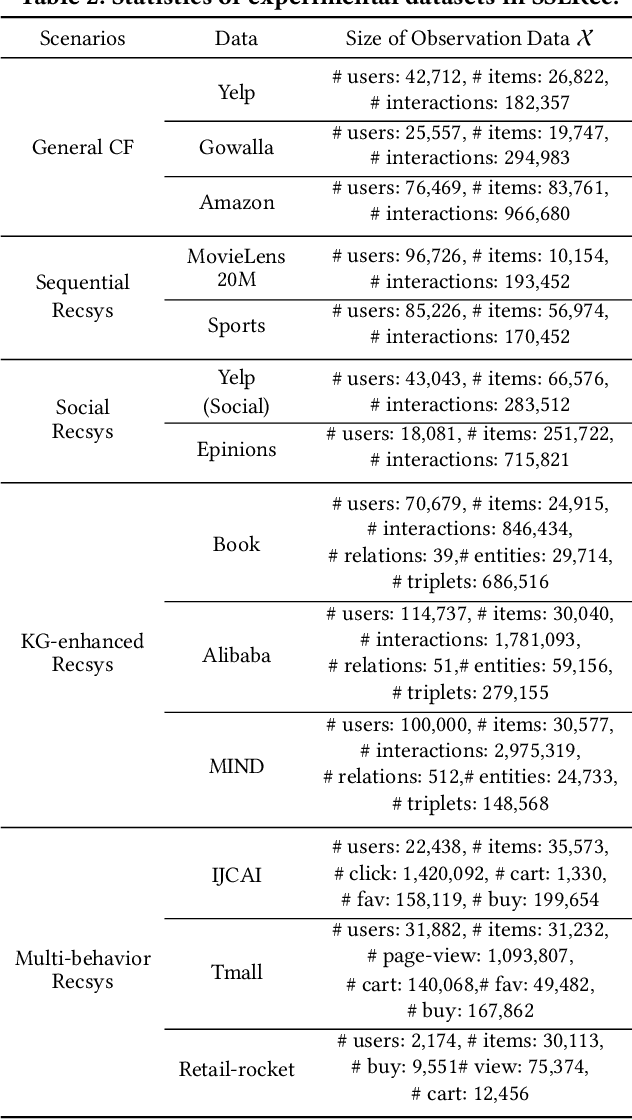
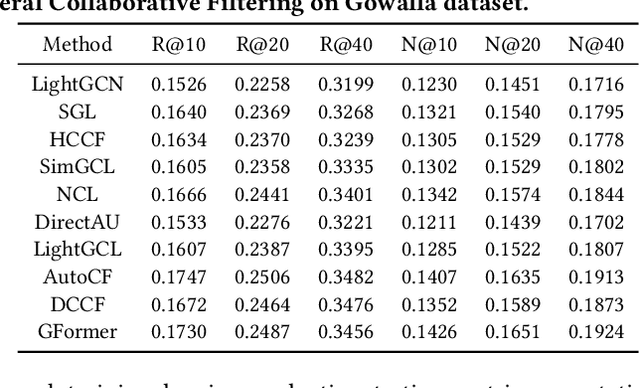
Self-supervised learning (SSL) has gained significant interest in recent years as a solution to address the challenges posed by sparse and noisy data in recommender systems. Despite the growing number of SSL algorithms designed to provide state-of-the-art performance in various recommendation scenarios (e.g., graph collaborative filtering, sequential recommendation, social recommendation, KG-enhanced recommendation), there is still a lack of unified frameworks that integrate recommendation algorithms across different domains. Such a framework could serve as the cornerstone for self-supervised recommendation algorithms, unifying the validation of existing methods and driving the design of new ones. To address this gap, we introduce SSLRec, a novel benchmark platform that provides a standardized, flexible, and comprehensive framework for evaluating various SSL-enhanced recommenders. The SSLRec library features a modular architecture that allows users to easily evaluate state-of-the-art models and a complete set of data augmentation and self-supervised toolkits to help create SSL recommendation models with specific needs. Furthermore, SSLRec simplifies the process of training and evaluating different recommendation models with consistent and fair settings. Our SSLRec platform covers a comprehensive set of state-of-the-art SSL-enhanced recommendation models across different scenarios, enabling researchers to evaluate these cutting-edge models and drive further innovation in the field. Our implemented SSLRec framework is available at the source code repository https://github.com/HKUDS/SSLRec.
DAVIS: High-Quality Audio-Visual Separation with Generative Diffusion Models
Jul 31, 2023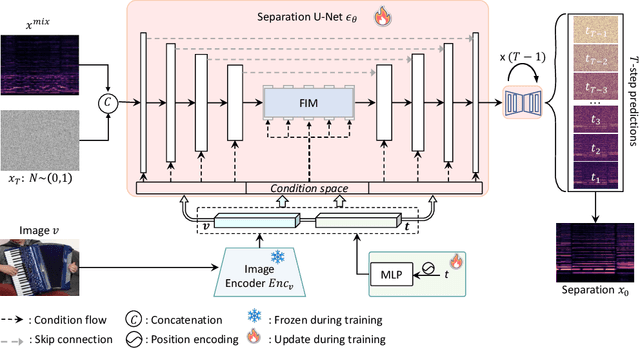
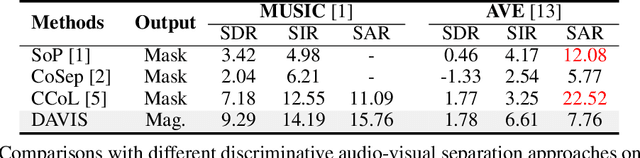
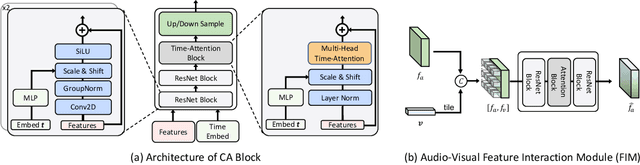
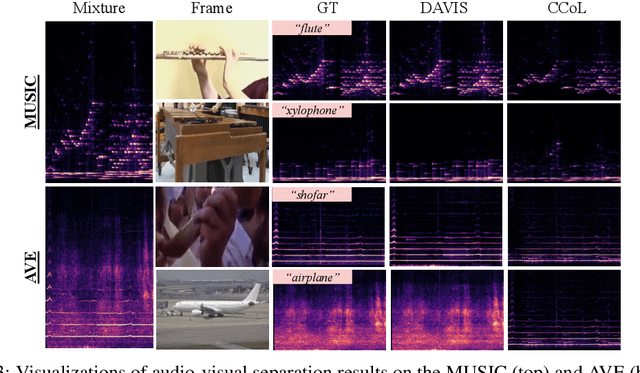
We propose DAVIS, a Diffusion model-based Audio-VIusal Separation framework that solves the audio-visual sound source separation task through a generative manner. While existing discriminative methods that perform mask regression have made remarkable progress in this field, they face limitations in capturing the complex data distribution required for high-quality separation of sounds from diverse categories. In contrast, DAVIS leverages a generative diffusion model and a Separation U-Net to synthesize separated magnitudes starting from Gaussian noises, conditioned on both the audio mixture and the visual footage. With its generative objective, DAVIS is better suited to achieving the goal of high-quality sound separation across diverse categories. We compare DAVIS to existing state-of-the-art discriminative audio-visual separation methods on the domain-specific MUSIC dataset and the open-domain AVE dataset, and results show that DAVIS outperforms other methods in separation quality, demonstrating the advantages of our framework for tackling the audio-visual source separation task.
Feature Importance Measurement based on Decision Tree Sampling
Jul 25, 2023
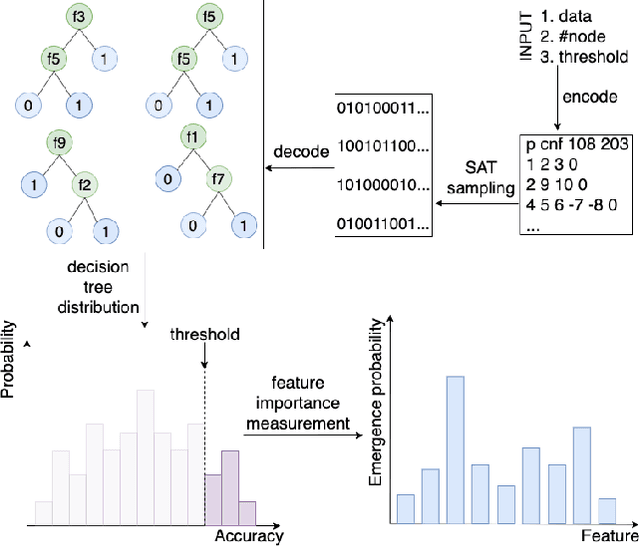
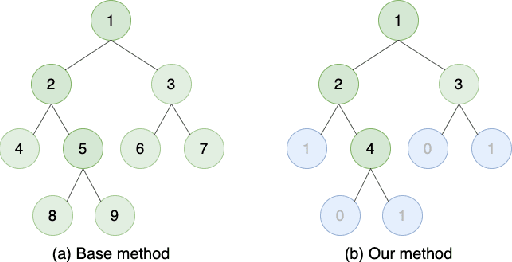
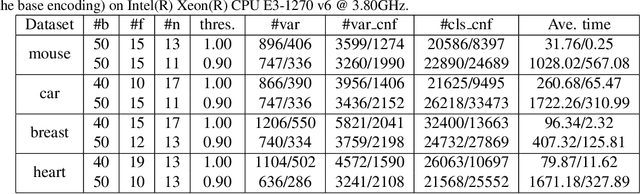
Random forest is effective for prediction tasks but the randomness of tree generation hinders interpretability in feature importance analysis. To address this, we proposed DT-Sampler, a SAT-based method for measuring feature importance in tree-based model. Our method has fewer parameters than random forest and provides higher interpretability and stability for the analysis in real-world problems. An implementation of DT-Sampler is available at https://github.com/tsudalab/DT-sampler.
Knowledge Graph Self-Supervised Rationalization for Recommendation
Jul 06, 2023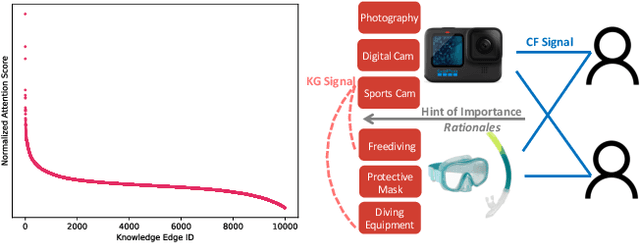
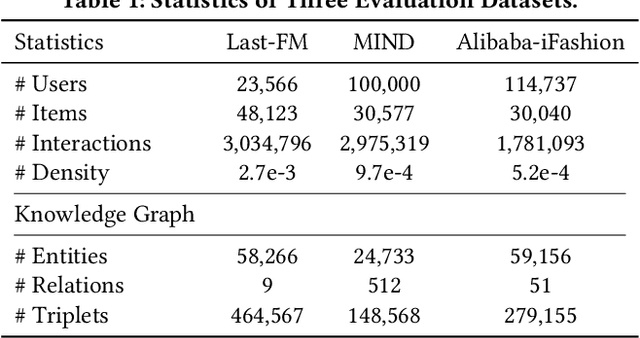
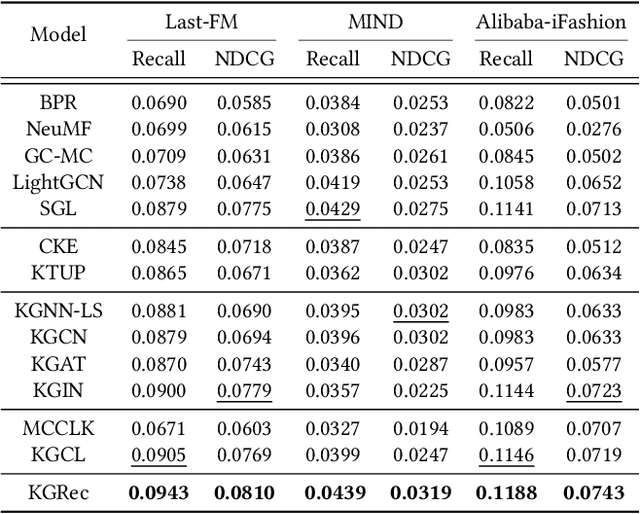
In this paper, we introduce a new self-supervised rationalization method, called KGRec, for knowledge-aware recommender systems. To effectively identify informative knowledge connections, we propose an attentive knowledge rationalization mechanism that generates rational scores for knowledge triplets. With these scores, KGRec integrates generative and contrastive self-supervised tasks for recommendation through rational masking. To highlight rationales in the knowledge graph, we design a novel generative task in the form of masking-reconstructing. By masking important knowledge with high rational scores, KGRec is trained to rebuild and highlight useful knowledge connections that serve as rationales. To further rationalize the effect of collaborative interactions on knowledge graph learning, we introduce a contrastive learning task that aligns signals from knowledge and user-item interaction views. To ensure noise-resistant contrasting, potential noisy edges in both graphs judged by the rational scores are masked. Extensive experiments on three real-world datasets demonstrate that KGRec outperforms state-of-the-art methods. We also provide the implementation codes for our approach at https://github.com/HKUDS/KGRec.
FBA-Net: Foreground and Background Aware Contrastive Learning for Semi-Supervised Atrium Segmentation
Jun 27, 2023Medical image segmentation of gadolinium enhancement magnetic resonance imaging (GE MRI) is an important task in clinical applications. However, manual annotation is time-consuming and requires specialized expertise. Semi-supervised segmentation methods that leverage both labeled and unlabeled data have shown promise, with contrastive learning emerging as a particularly effective approach. In this paper, we propose a contrastive learning strategy of foreground and background representations for semi-supervised 3D medical image segmentation (FBA-Net). Specifically, we leverage the contrastive loss to learn representations of both the foreground and background regions in the images. By training the network to distinguish between foreground-background pairs, we aim to learn a representation that can effectively capture the anatomical structures of interest. Experiments on three medical segmentation datasets demonstrate state-of-the-art performance. Notably, our method achieves a Dice score of 91.31% with only 20% labeled data, which is remarkably close to the 91.62% score of the fully supervised method that uses 100% labeled data on the left atrium dataset. Our framework has the potential to advance the field of semi-supervised 3D medical image segmentation and enable more efficient and accurate analysis of medical images with a limited amount of annotated labels.
Spatial-Temporal Graph Learning with Adversarial Contrastive Adaptation
Jun 19, 2023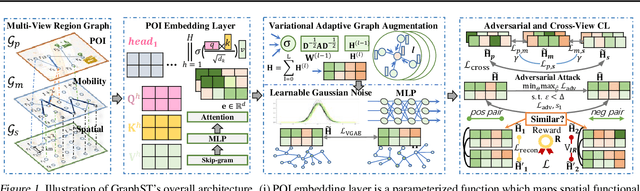
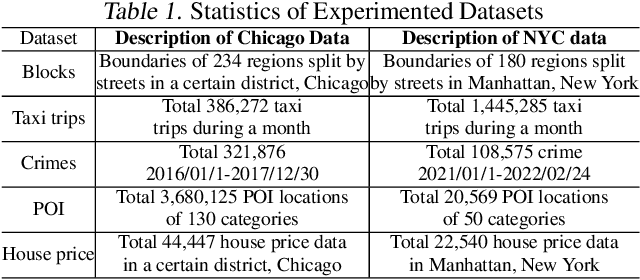
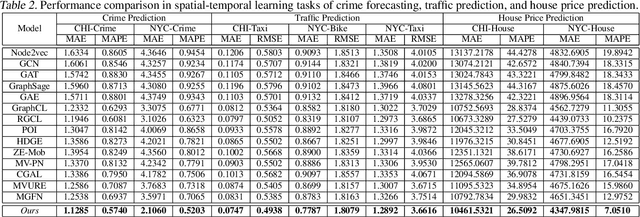
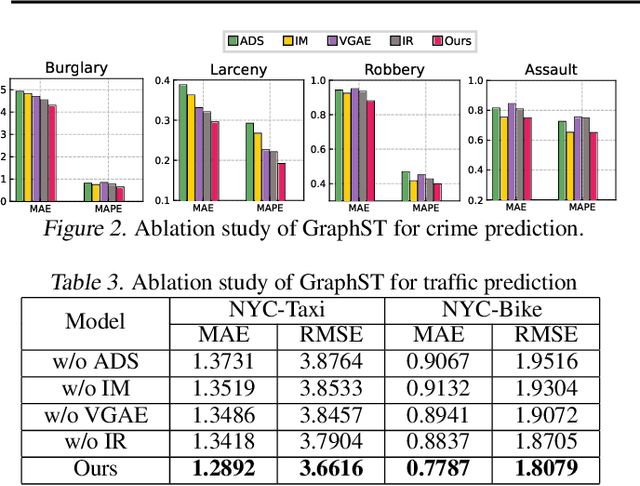
Spatial-temporal graph learning has emerged as a promising solution for modeling structured spatial-temporal data and learning region representations for various urban sensing tasks such as crime forecasting and traffic flow prediction. However, most existing models are vulnerable to the quality of the generated region graph due to the inaccurate graph-structured information aggregation schema. The ubiquitous spatial-temporal data noise and incompleteness in real-life scenarios pose challenges in generating high-quality region representations. To address this challenge, we propose a new spatial-temporal graph learning model (GraphST) for enabling effective self-supervised learning. Our proposed model is an adversarial contrastive learning paradigm that automates the distillation of crucial multi-view self-supervised information for robust spatial-temporal graph augmentation. We empower GraphST to adaptively identify hard samples for better self-supervision, enhancing the representation discrimination ability and robustness. In addition, we introduce a cross-view contrastive learning paradigm to model the inter-dependencies across view-specific region representations and preserve underlying relation heterogeneity. We demonstrate the superiority of our proposed GraphST method in various spatial-temporal prediction tasks on real-life datasets. We release our model implementation via the link: \url{https://github.com/HKUDS/GraphST}.
SaliencyCut: Augmenting Plausible Anomalies for Open-set Fine-Grained Anomaly Detection
Jun 14, 2023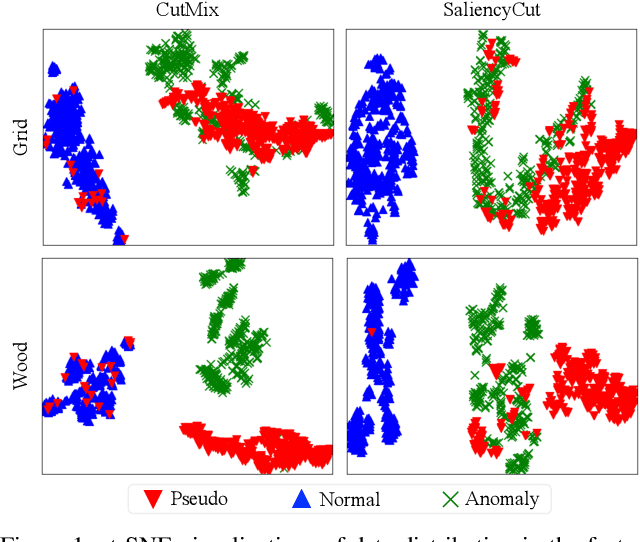
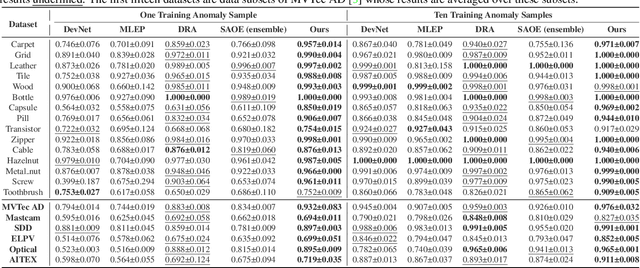
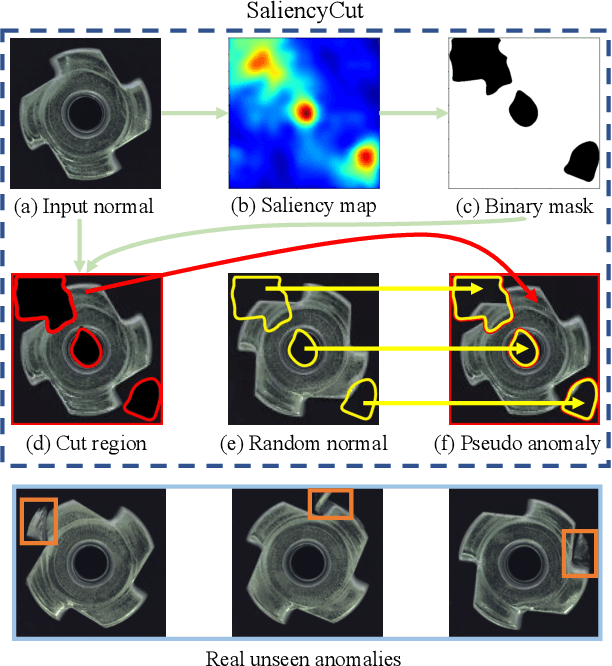
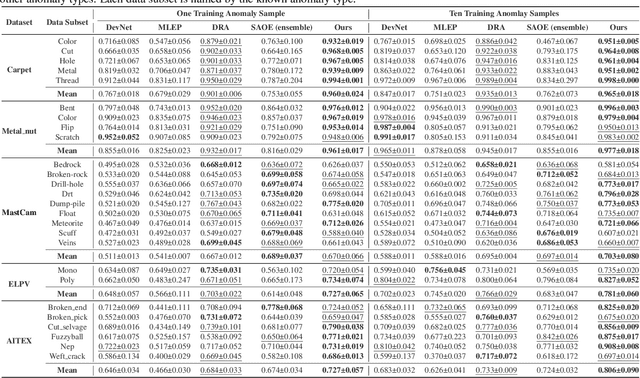
Open-set fine-grained anomaly detection is a challenging task that requires learning discriminative fine-grained features to detect anomalies that were even unseen during training. As a cheap yet effective approach, data augmentation has been widely used to create pseudo anomalies for better training of such models. Recent wisdom of augmentation methods focuses on generating random pseudo instances that may lead to a mixture of augmented instances with seen anomalies, or out of the typical range of anomalies. To address this issue, we propose a novel saliency-guided data augmentation method, SaliencyCut, to produce pseudo but more common anomalies which tend to stay in the plausible range of anomalies. Furthermore, we deploy a two-head learning strategy consisting of normal and anomaly learning heads, to learn the anomaly score of each sample. Theoretical analyses show that this mechanism offers a more tractable and tighter lower bound of the data log-likelihood. We then design a novel patch-wise residual module in the anomaly learning head to extract and assess the fine-grained anomaly features from each sample, facilitating the learning of discriminative representations of anomaly instances. Extensive experiments conducted on six real-world anomaly detection datasets demonstrate the superiority of our method to the baseline and other state-of-the-art methods under various settings.
LargeST: A Benchmark Dataset for Large-Scale Traffic Forecasting
Jun 14, 2023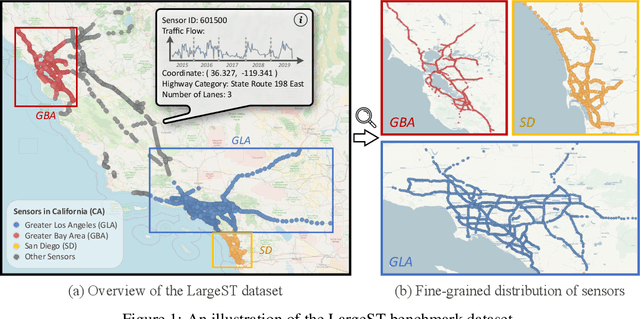
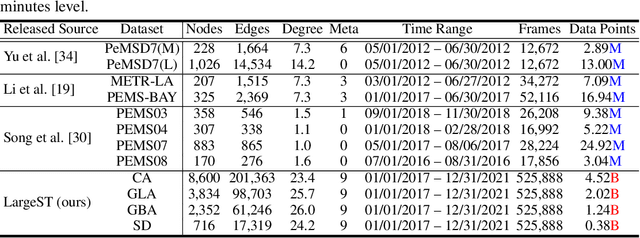

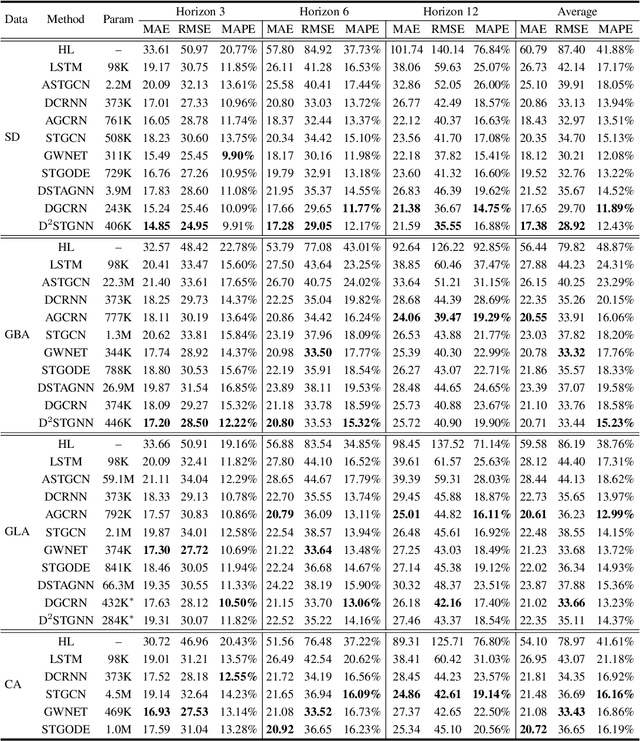
Traffic forecasting plays a critical role in smart city initiatives and has experienced significant advancements thanks to the power of deep learning in capturing non-linear patterns of traffic data. However, the promising results achieved on current public datasets may not be applicable to practical scenarios due to limitations within these datasets. First, the limited sizes of them may not reflect the real-world scale of traffic networks. Second, the temporal coverage of these datasets is typically short, posing hurdles in studying long-term patterns and acquiring sufficient samples for training deep models. Third, these datasets often lack adequate metadata for sensors, which compromises the reliability and interpretability of the data. To mitigate these limitations, we introduce the LargeST benchmark dataset. It encompasses a total number of 8,600 sensors with a 5-year time coverage and includes comprehensive metadata. Using LargeST, we perform in-depth data analysis to extract data insights, benchmark well-known baselines in terms of their performance and efficiency, and identify challenges as well as opportunities for future research. We release the datasets and baseline implementations at: https://github.com/liuxu77/LargeST.