 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTT: Soft Template Tuning for Few-Shot Adaptation
Jul 18, 2022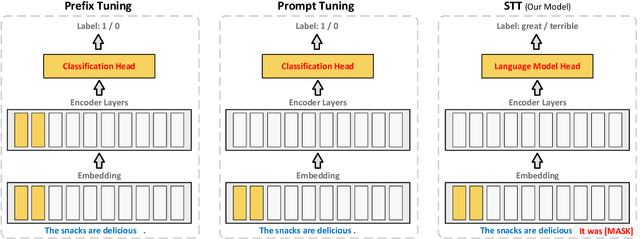
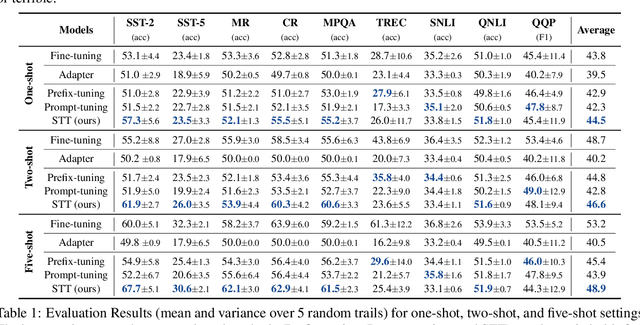
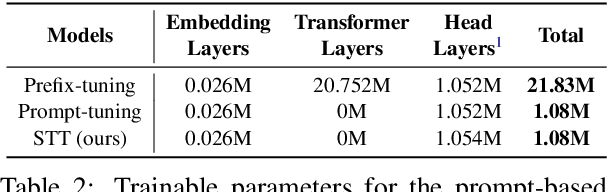
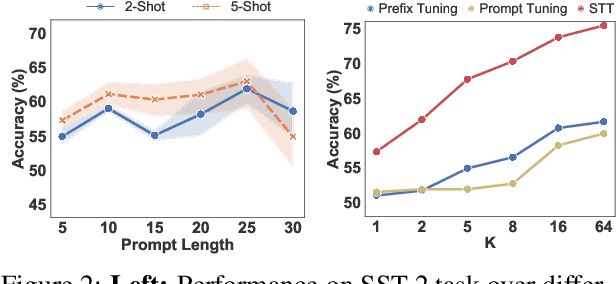
Prompt tuning has been an extremely effective tool to adapt a pre-trained model to downstream tasks. However, standard prompt-based methods mainly consider the case of sufficient data of downstream tasks. It is still unclear whether the advantage can be transferred to the few-shot regime, where only limited data are available for each downstream task. Although some works have demonstrated the potential of prompt-tuning under the few-shot setting, the main stream methods via searching discrete prompts or tuning soft prompts with limited data are still very challenging. Through extensive empirical studies, we find that there is still a gap between prompt tuning and fully fine-tuning for few-shot learning. To bridge the gap, we propose a new prompt-tuning framework, called Soft Template Tuning (STT). STT combines manual and auto prompts, and treats downstream classification tasks as a masked language modeling task. Comprehensive evaluation on different settings suggests STT can close the gap between fine-tuning and prompt-based methods without introducing additional parameters. Significantly, it can even outperform the time- and resource-consuming fine-tuning method on sentiment classification tasks.
LAFITE: Towards Language-Free Training for Text-to-Image Generation
Dec 13, 2021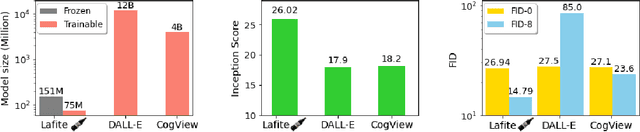
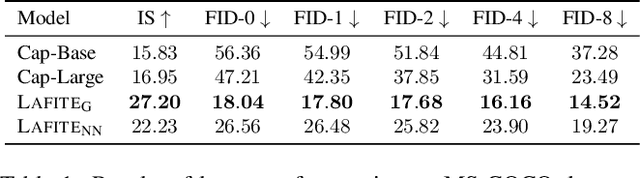
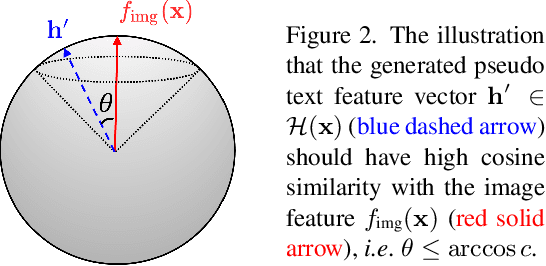
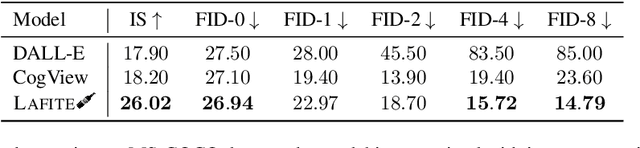
One of the major challenges in training text-to-image generation models is the need of a large number of high-quality image-text pairs. While image samples are often easily accessible, the associated text descriptions typically require careful human captioning, which is particularly time- and cost-consuming. In this paper, we propose the first work to train text-to-image generation models without any text data. Our method leverages the well-aligned multi-modal semantic space of the powerful pre-trained CLIP model: the requirement of text-conditioning is seamlessly alleviated via generating text features from image features. Extensive experiments are conducted to illustrate the effectiveness of the proposed method. We obtain state-of-the-art results in the standard text-to-image generation tasks. Importantly, the proposed language-free model outperforms most existing models trained with full image-text pairs. Furthermore, our method can be applied in fine-tuning pre-trained models, which saves both training time and cost in training text-to-image generation models. Our pre-trained model obtains competitive results in zero-shot text-to-image generation on the MS-COCO dataset, yet with around only 1% of the model size and training data size relative to the recently proposed large DALL-E model.
A Generic Approach for Enhancing GANs by Regularized Latent Optimization
Dec 07, 2021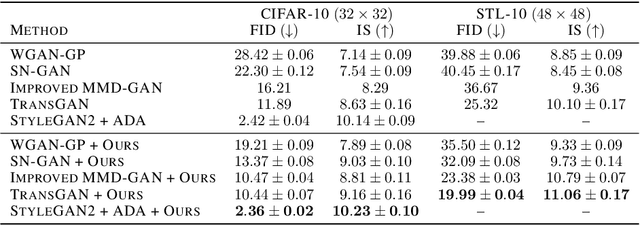

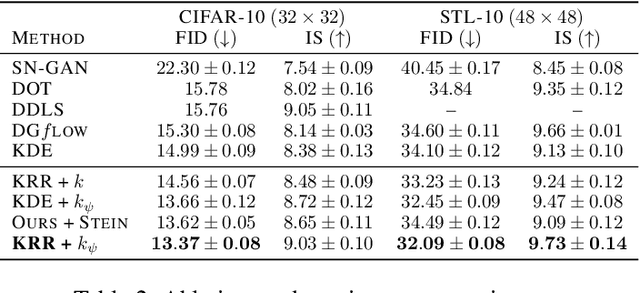

With the rapidly growing model complexity and data volume, training deep generative models (DGMs) for better performance has becoming an increasingly more important challenge. Previous research on this problem has mainly focused on improving DGMs by either introducing new objective functions or designing more expressive model architectures. However, such approaches often introduce significantly more computational and/or designing overhead. To resolve such issues, we introduce in this paper a generic framework called {\em generative-model inference} that is capable of enhancing pre-trained GANs effectively and seamlessly in a variety of application scenarios. Our basic idea is to efficiently infer the optimal latent distribution for the given requirements using Wasserstein gradient flow techniques, instead of re-training or fine-tuning pre-trained model parameters. Extensive experimental results on applications like image generation, image translation, text-to-image generation, image inpainting, and text-guided image editing suggest the effectiveness and superiority of our proposed framework.
Using Sampling to Estimate and Improve Performance of Automated Scoring Systems with Guarantees
Nov 17, 2021
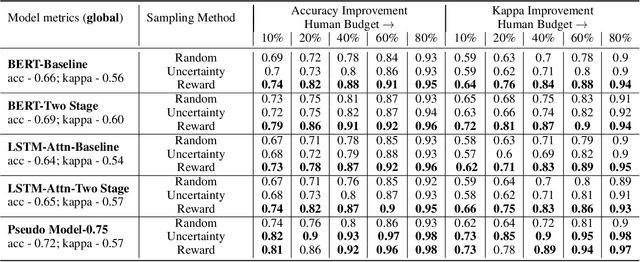
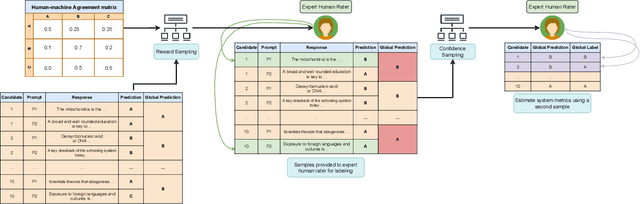
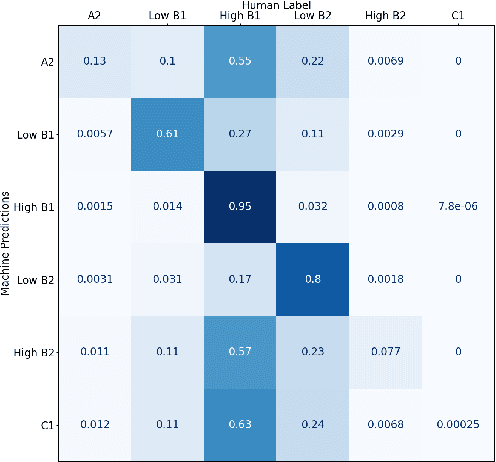
Automated Scoring (AS), the natural language processing task of scoring essays and speeches in an educational testing setting, is growing in popularity and being deployed across contexts from government examinations to companies providing language proficiency services. However, existing systems either forgo human raters entirely, thus harming the reliability of the test, or score every response by both human and machine thereby increasing costs. We target the spectrum of possible solutions in between, making use of both humans and machines to provide a higher quality test while keeping costs reasonable to democratize access to AS. In this work, we propose a combination of the existing paradigms, sampling responses to be scored by humans intelligently. We propose reward sampling and observe significant gains in accuracy (19.80% increase on average) and quadratic weighted kappa (QWK) (25.60% on average) with a relatively small human budget (30% samples) using our proposed sampling. The accuracy increase observed using standard random and importance sampling baselines are 8.6% and 12.2% respectively. Furthermore, we demonstrate the system's model agnostic nature by measuring its performance on a variety of models currently deployed in an AS setting as well as pseudo models. Finally, we propose an algorithm to estimate the accuracy/QWK with statistical guarantees (Our code is available at https://git.io/J1IOy).
AES Systems Are Both Overstable And Oversensitive: Explaining Why And Proposing Defenses
Oct 14, 2021

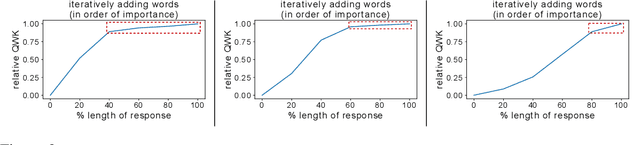
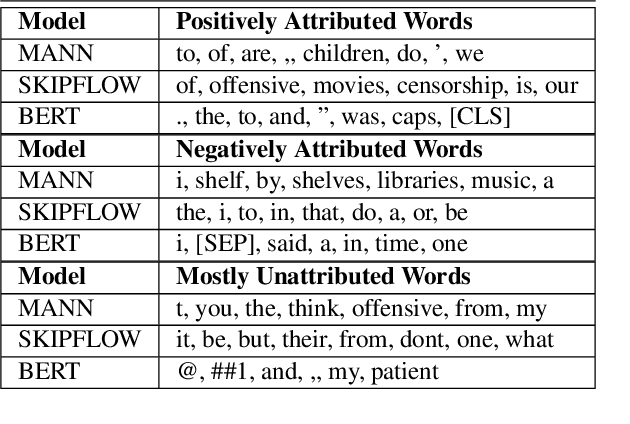
Deep-learning based Automatic Essay Scoring (AES) systems are being actively used by states and language testing agencies alike to evaluate millions of candidates for life-changing decisions ranging from college applications to visa approvals. However, little research has been put to understand and interpret the black-box nature of deep-learning based scoring algorithms. Previous studies indicate that scoring models can be easily fooled. In this paper, we explore the reason behind their surprising adversarial brittleness. We utilize recent advances in interpretability to find the extent to which features such as coherence, content, vocabulary, and relevance are important for automated scoring mechanisms. We use this to investigate the oversensitivity i.e., large change in output score with a little change in input essay content) and overstability i.e., little change in output scores with large changes in input essay content) of AES. Our results indicate that autoscoring models, despite getting trained as "end-to-end" models with rich contextual embeddings such as BERT, behave like bag-of-words models. A few words determine the essay score without the requirement of any context making the model largely overstable. This is in stark contrast to recent probing studies on pre-trained representation learning models, which show that rich linguistic features such as parts-of-speech and morphology are encoded by them. Further, we also find that the models have learnt dataset biases, making them oversensitive. To deal with these issues, we propose detection-based protection models that can detect oversensitivity and overstability causing samples with high accuracies. We find that our proposed models are able to detect unusual attribution patterns and flag adversarial samples successfully.
Perception Point: Identifying Critical Learning Periods in Speech for Bilingual Networks
Oct 13, 2021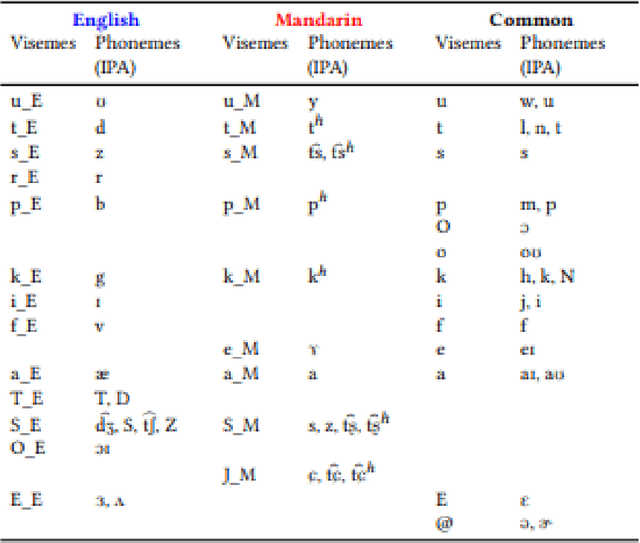



Recent studies in speech perception have been closely linked to fields of cognitive psychology, phonology, and phonetics in linguistics. During perceptual attunement, a critical and sensitive developmental trajectory has been examined in bilingual and monolingual infants where they can best discriminate common phonemes. In this paper, we compare and identify these cognitive aspects on deep neural-based visual lip-reading models. We conduct experiments on the two most extensive public visual speech recognition datasets for English and Mandarin. Through our experimental results, we observe a strong correlation between these theories in cognitive psychology and our unique modeling. We inspect how these computational models develop similar phases in speech perception and acquisitions.
MINIMAL: Mining Models for Data Free Universal Adversarial Triggers
Sep 25, 2021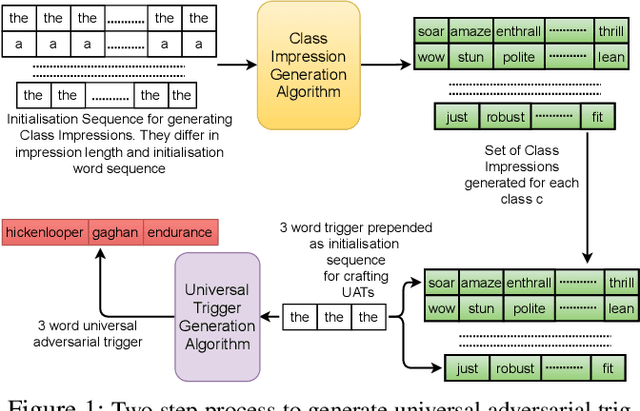
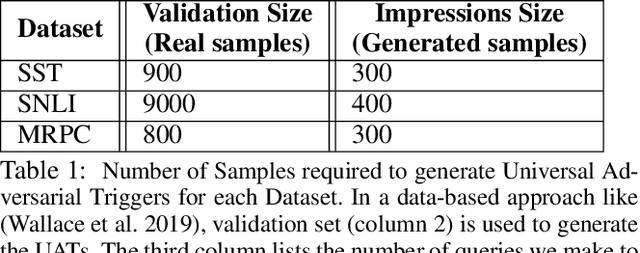
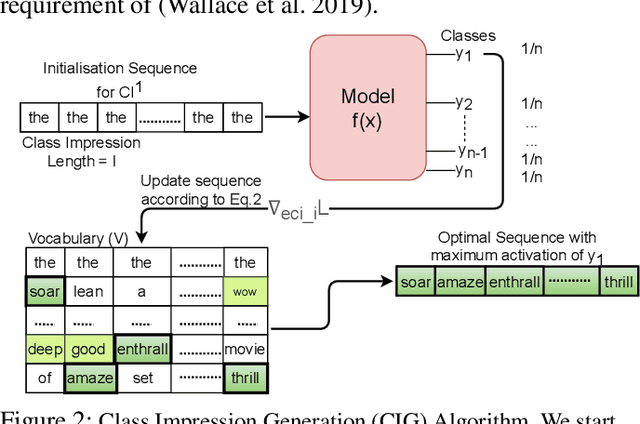
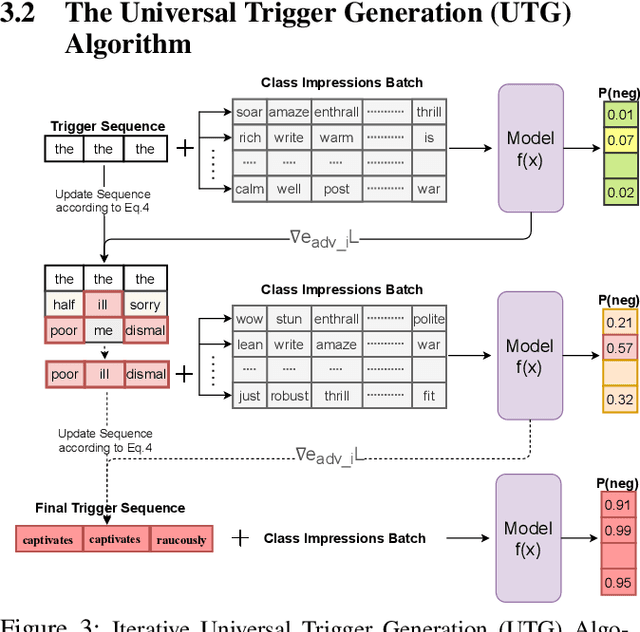
It is well known that natural language models are vulnerable to adversarial attacks, which are mostly input-specific in nature. Recently, it has been shown that there also exist input-agnostic attacks in NLP models, called universal adversarial triggers. However, existing methods to craft universal triggers are data intensive. They require large amounts of data samples to generate adversarial triggers, which are typically inaccessible by attackers. For instance, previous works take 3000 data samples per class for the SNLI dataset to generate adversarial triggers. In this paper, we present a novel data-free approach, MINIMAL, to mine input-agnostic adversarial triggers from models. Using the triggers produced with our data-free algorithm, we reduce the accuracy of Stanford Sentiment Treebank's positive class from 93.6% to 9.6%. Similarly, for the Stanford Natural Language Inference (SNLI), our single-word trigger reduces the accuracy of the entailment class from 90.95% to less than 0.6\%. Despite being completely data-free, we get equivalent accuracy drops as data-dependent methods.
Speaker-Conditioned Hierarchical Modeling for Automated Speech Scoring
Aug 30, 2021
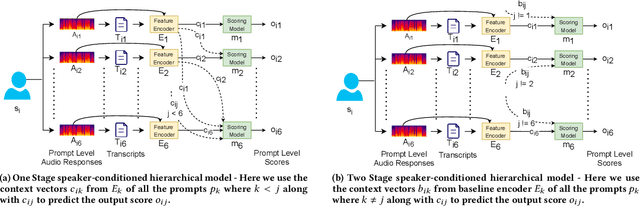

Automatic Speech Scoring (ASS) is the computer-assisted evaluation of a candidate's speaking proficiency in a language. ASS systems face many challenges like open grammar, variable pronunciations, and unstructured or semi-structured content. Recent deep learning approaches have shown some promise in this domain. However, most of these approaches focus on extracting features from a single audio, making them suffer from the lack of speaker-specific context required to model such a complex task. We propose a novel deep learning technique for non-native ASS, called speaker-conditioned hierarchical modeling. In our technique, we take advantage of the fact that oral proficiency tests rate multiple responses for a candidate. We extract context vectors from these responses and feed them as additional speaker-specific context to our network to score a particular response. We compare our technique with strong baselines and find that such modeling improves the model's average performance by 6.92% (maximum = 12.86%, minimum = 4.51%). We further show both quantitative and qualitative insights into the importance of this additional context in solving the problem of ASS.
Integrating Semantics and Neighborhood Information with Graph-Driven Generative Models for Document Retrieval
May 27, 2021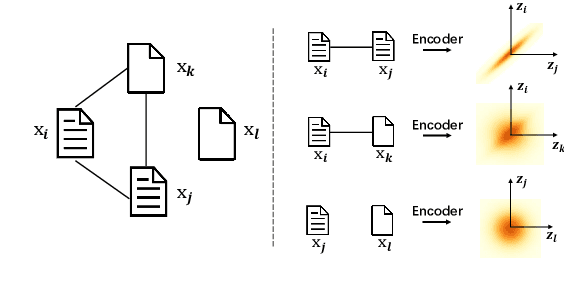
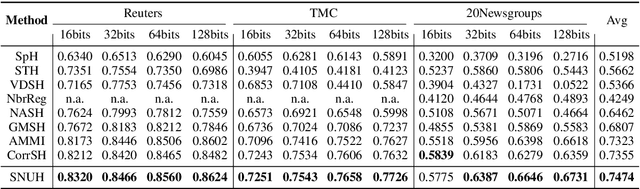
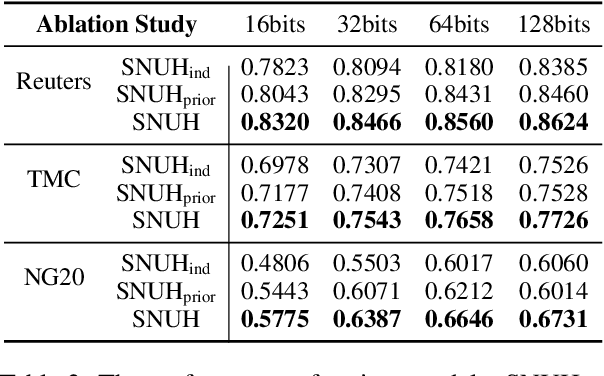
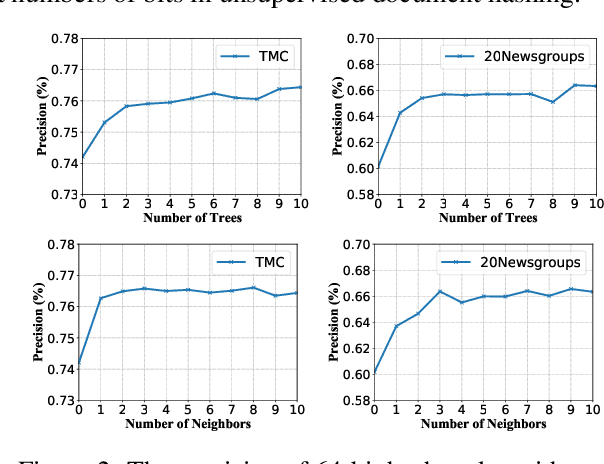
With the need of fast retrieval speed and small memory footprint, document hashing has been playing a crucial role in large-scale information retrieval. To generate high-quality hashing code, both semantics and neighborhood information are crucial. However, most existing methods leverage only one of them or simply combine them via some intuitive criteria, lacking a theoretical principle to guide the integration process. In this paper, we encode the neighborhood information with a graph-induced Gaussian distribution, and propose to integrate the two types of information with a graph-driven generative model. To deal with the complicated correlations among documents, we further propose a tree-structured approximation method for learning. Under the approximation, we prove that the training objective can be decomposed into terms involving only singleton or pairwise documents, enabling the model to be trained as efficiently as uncorrelated ones. Extensive experimental results on three benchmark datasets show that our method achieves superior performance over state-of-the-art methods, demonstrating the effectiveness of the proposed model for simultaneously preserving semantic and neighborhood information.\
Unsupervised Hashing with Contrastive Information Bottleneck
May 19, 2021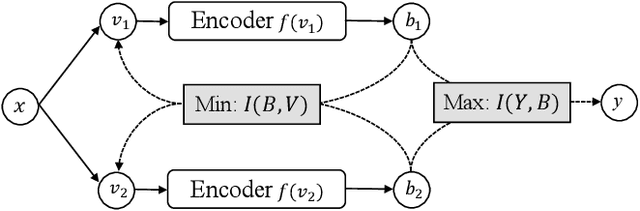
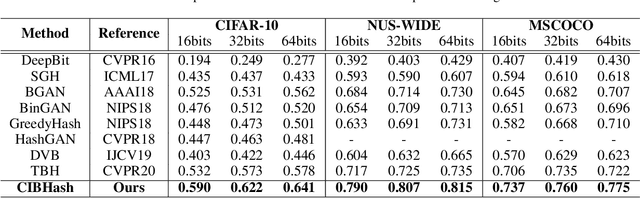
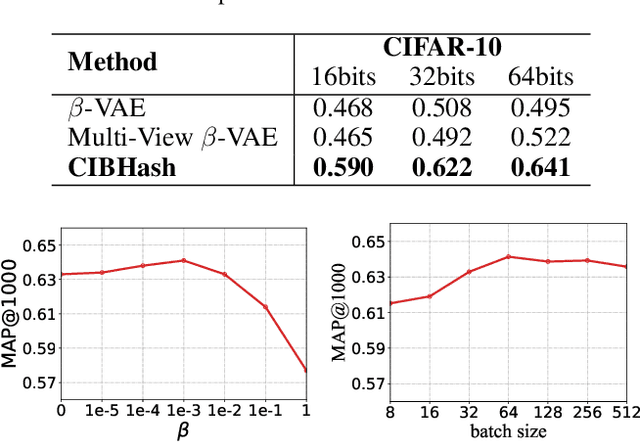
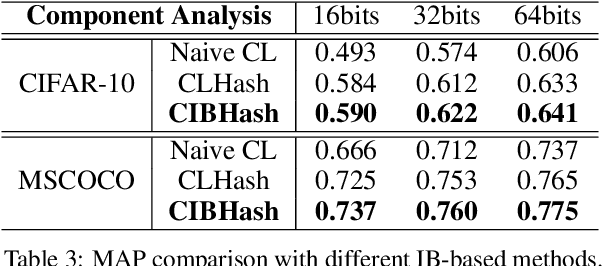
Many unsupervised hashing methods are implicitly established on the idea of reconstructing the input data, which basically encourages the hashing codes to retain as much information of original data as possible. However, this requirement may force the models spending lots of their effort on reconstructing the unuseful background information, while ignoring to preserve the discriminative semantic information that is more important for the hashing task. To tackle this problem, inspired by the recent success of contrastive learning in learning continuous representations, we propose to adapt this framework to learn binary hashing codes. Specifically, we first propose to modify the objective function to meet the specific requirement of hashing and then introduce a probabilistic binary representation layer into the model to facilitate end-to-end training of the entire model. We further prove the strong connection between the proposed contrastive-learning-based hashing method and the mutual information, and show that the proposed model can be considered under the broader framework of the information bottleneck (IB). Under this perspective, a more general hashing model is naturally obtained. Extensive experimental results on three benchmark image datasets demonstrate that the proposed hashing method significantly outperforms existing baselines.