 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Collaborate
Aug 19, 2021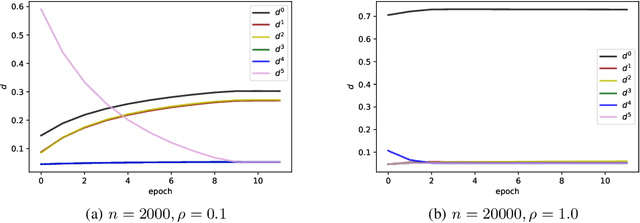
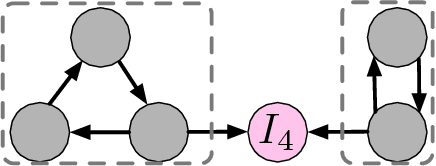
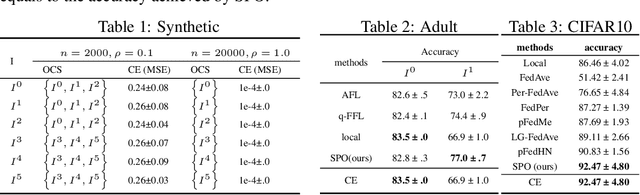
In this paper, we focus on effective learning over a collaborative research network involving multiple clients. Each client has its own sample population which may not be shared with other clients due to privacy concerns. The goal is to learn a model for each client, which behaves better than the one learned from its own data, through secure collaborations with other clients in the network. Due to the discrepancies of the sample distributions across different clients, it is not necessarily that collaborating with everyone will lead to the best local models. We propose a learning to collaborate framework, where each client can choose to collaborate with certain members in the network to achieve a "collaboration equilibrium", where smaller collaboration coalitions are formed within the network so that each client can obtain the model with the best utility. We propose the concept of benefit graph which describes how each client can benefit from collaborating with other clients and develop a Pareto optimization approach to obtain it. Finally the collaboration coalitions can be derived from it based on graph operations. Our framework provides a new way of setting up collaborations in a research network. Experiments on both synthetic and real world data sets are provided to demonstrate the effectiveness of our method.
Fair and Consistent Federated Learning
Aug 19, 2021
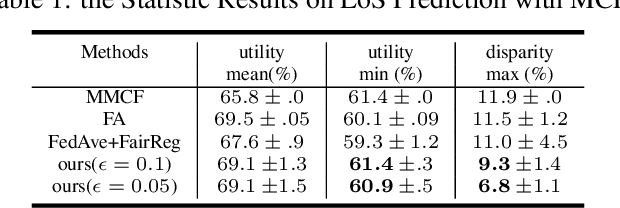
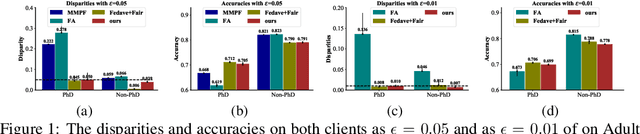
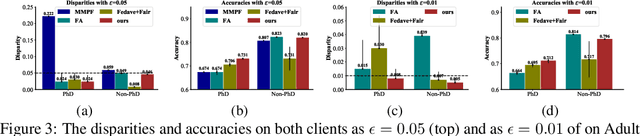
Federated learning (FL) has gain growing interests for its capability of learning from distributed data sources collectively without the need of accessing the raw data samples across different sources. So far FL research has mostly focused on improving the performance, how the algorithmic disparity will be impacted for the model learned from FL and the impact of algorithmic disparity on the utility inconsistency are largely unexplored. In this paper, we propose an FL framework to jointly consider performance consistency and algorithmic fairness across different local clients (data sources). We derive our framework from a constrained multi-objective optimization perspective, in which we learn a model satisfying fairness constraints on all clients with consistent performance. Specifically, we treat the algorithm prediction loss at each local client as an objective and maximize the worst-performing client with fairness constraints through optimizing a surrogate maximum function with all objectives involved. A gradient-based procedure is employed to achieve the Pareto optimality of this optimization problem. Theoretical analysis is provided to prove that our method can converge to a Pareto solution that achieves the min-max performance with fairness constraints on all clients. Comprehensive experiments on synthetic and real-world datasets demonstrate the superiority that our approach over baselines and its effectiveness in achieving both fairness and consistency across all local clients.
Explaining Algorithmic Fairness Through Fairness-Aware Causal Path Decomposition
Aug 11, 2021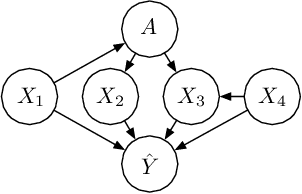

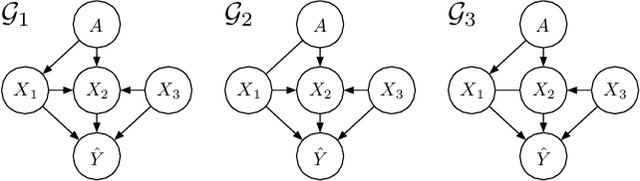
Algorithmic fairness has aroused considerable interests in data mining and machine learning communities recently. So far the existing research has been mostly focusing on the development of quantitative metrics to measure algorithm disparities across different protected groups, and approaches for adjusting the algorithm output to reduce such disparities. In this paper, we propose to study the problem of identification of the source of model disparities. Unlike existing interpretation methods which typically learn feature importance, we consider the causal relationships among feature variables and propose a novel framework to decompose the disparity into the sum of contributions from fairness-aware causal paths, which are paths linking the sensitive attribute and the final predictions, on the graph. We also consider the scenario when the directions on certain edges within those paths cannot be determined. Our framework is also model agnostic and applicable to a variety of quantitative disparity measures. Empirical evaluations on both synthetic and real-world data sets are provided to show that our method can provide precise and comprehensive explanations to the model disparities.
Nearest Neighborhood-Based Deep Clustering for Source Data-absent Unsupervised Domain Adaptation
Aug 03, 2021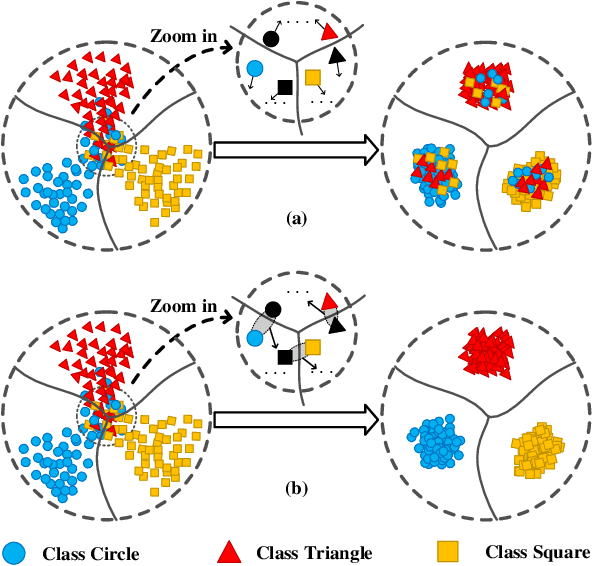
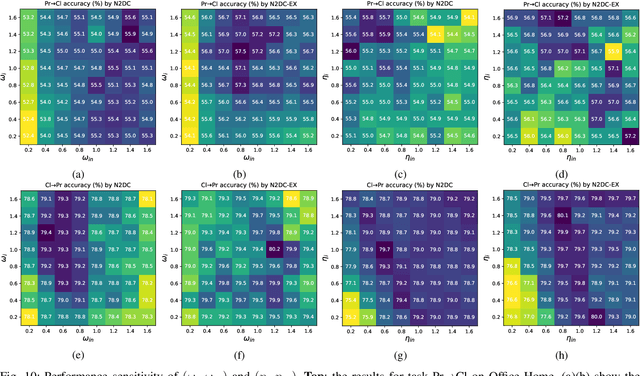
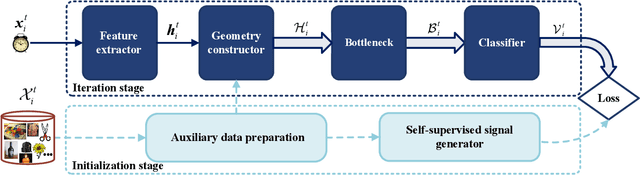
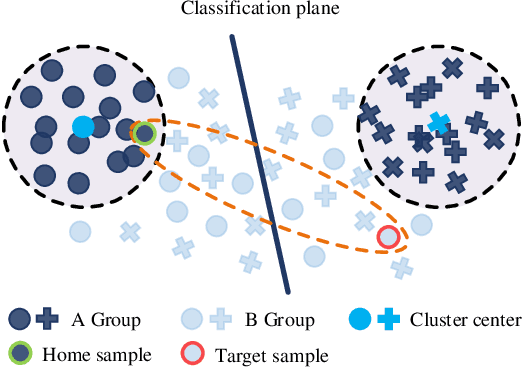
In the classic setting of unsupervised domain adaptation (UDA), the labeled source data are available in the training phase. However, in many real-world scenarios, owing to some reasons such as privacy protection and information security, the source data is inaccessible, and only a model trained on the source domain is available. This paper proposes a novel deep clustering method for this challenging task. Aiming at the dynamical clustering at feature-level, we introduce extra constraints hidden in the geometric structure between data to assist the process. Concretely, we propose a geometry-based constraint, named semantic consistency on the nearest neighborhood (SCNNH), and use it to encourage robust clustering. To reach this goal, we construct the nearest neighborhood for every target data and take it as the fundamental clustering unit by building our objective on the geometry. Also, we develop a more SCNNH-compliant structure with an additional semantic credibility constraint, named semantic hyper-nearest neighborhood (SHNNH). After that, we extend our method to this new geometry. Extensive experiments on three challenging UDA datasets indicate that our method achieves state-of-the-art results. The proposed method has significant improvement on all datasets (as we adopt SHNNH, the average accuracy increases by over 3.0% on the large-scaled dataset). Code is available at https://github.com/tntek/N2DCX.
ReSSL: Relational Self-Supervised Learning with Weak Augmentation
Jul 23, 2021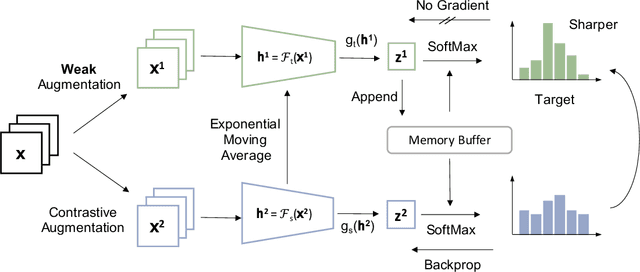
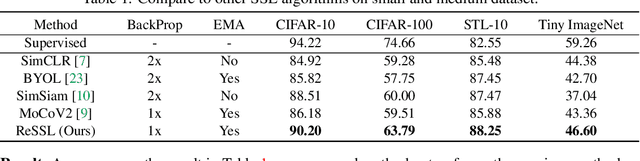
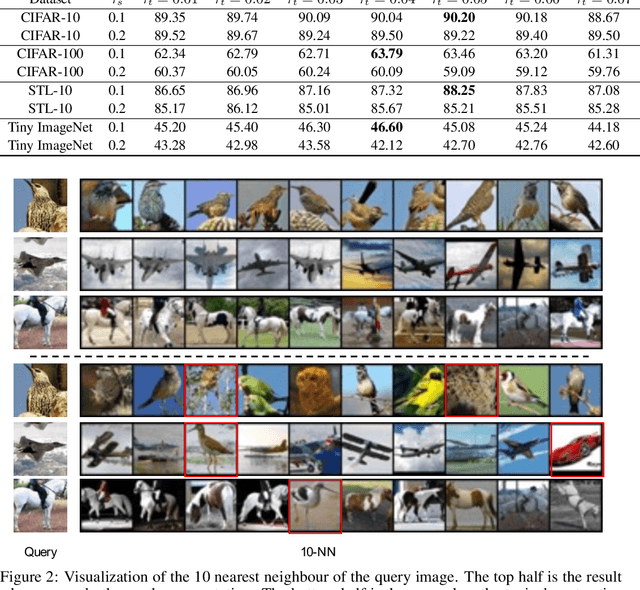
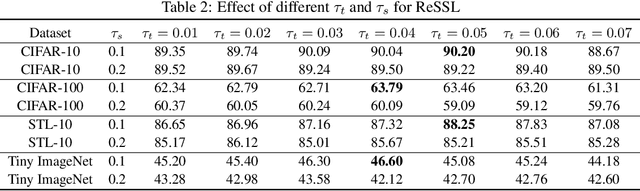
Self-supervised Learning (SSL) including the mainstream contrastive learning has achieved great success in learning visual representations without data annotations. However, most of methods mainly focus on the instance level information (\ie, the different augmented images of the same instance should have the same feature or cluster into the same class), but there is a lack of attention on the relationships between different instances. In this paper, we introduced a novel SSL paradigm, which we term as relational self-supervised learning (ReSSL) framework that learns representations by modeling the relationship between different instances. Specifically, our proposed method employs sharpened distribution of pairwise similarities among different instances as \textit{relation} metric, which is thus utilized to match the feature embeddings of different augmentations. Moreover, to boost the performance, we argue that weak augmentations matter to represent a more reliable relation, and leverage momentum strategy for practical efficiency. Experimental results show that our proposed ReSSL significantly outperforms the previous state-of-the-art algorithms in terms of both performance and training efficiency. Code is available at \url{https://github.com/KyleZheng1997/ReSSL}.
Vision Transformer Architecture Search
Jun 25, 2021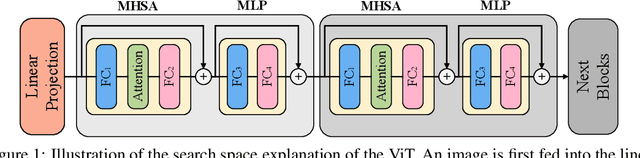

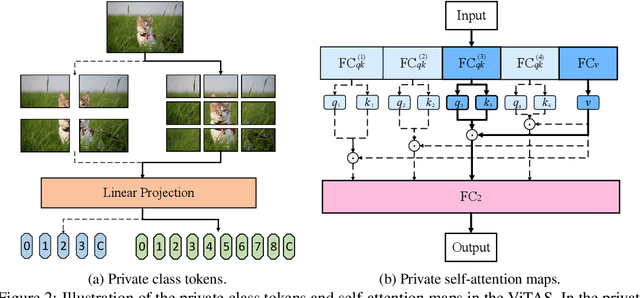

Recently, transformers have shown great superiority in solving computer vision tasks by modeling images as a sequence of manually-split patches with self-attention mechanism. However, current architectures of vision transformers (ViTs) are simply inherited from natural language processing (NLP) tasks and have not been sufficiently investigated and optimized. In this paper, we make a further step by examining the intrinsic structure of transformers for vision tasks and propose an architecture search method, dubbed ViTAS, to search for the optimal architecture with similar hardware budgets. Concretely, we design a new effective yet efficient weight sharing paradigm for ViTs, such that architectures with different token embedding, sequence size, number of heads, width, and depth can be derived from a single super-transformer. Moreover, to cater for the variance of distinct architectures, we introduce \textit{private} class token and self-attention maps in the super-transformer. In addition, to adapt the searching for different budgets, we propose to search the sampling probability of identity operation. Experimental results show that our ViTAS attains excellent results compared to existing pure transformer architectures. For example, with $1.3$G FLOPs budget, our searched architecture achieves $74.7\%$ top-$1$ accuracy on ImageNet and is $2.5\%$ superior than the current baseline ViT architecture. Code is available at \url{https://github.com/xiusu/ViTAS}.
K-shot NAS: Learnable Weight-Sharing for NAS with K-shot Supernets
Jun 11, 2021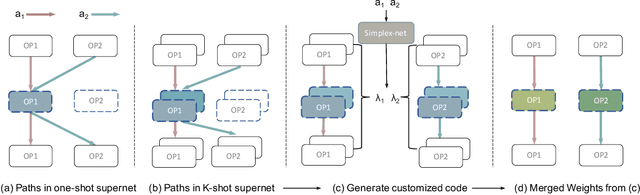
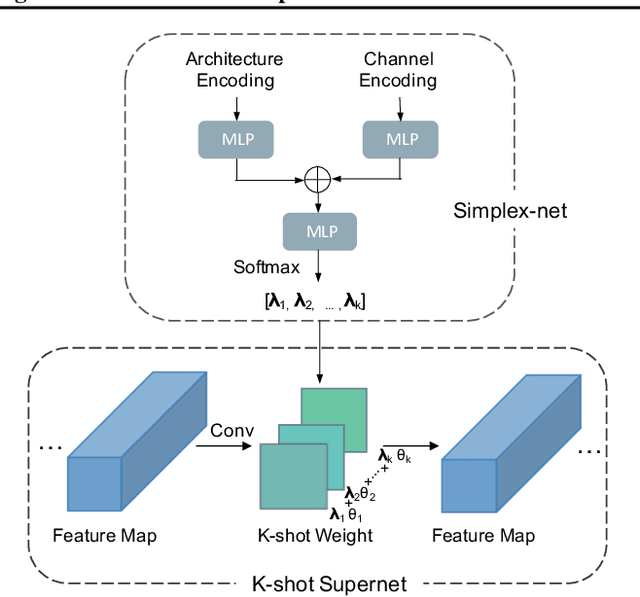
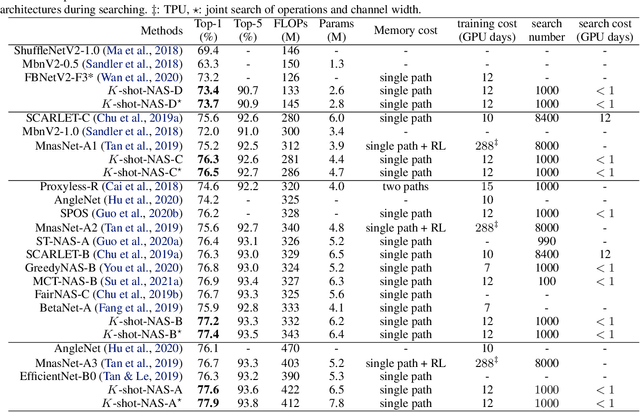

In one-shot weight sharing for NAS, the weights of each operation (at each layer) are supposed to be identical for all architectures (paths) in the supernet. However, this rules out the possibility of adjusting operation weights to cater for different paths, which limits the reliability of the evaluation results. In this paper, instead of counting on a single supernet, we introduce $K$-shot supernets and take their weights for each operation as a dictionary. The operation weight for each path is represented as a convex combination of items in a dictionary with a simplex code. This enables a matrix approximation of the stand-alone weight matrix with a higher rank ($K>1$). A \textit{simplex-net} is introduced to produce architecture-customized code for each path. As a result, all paths can adaptively learn how to share weights in the $K$-shot supernets and acquire corresponding weights for better evaluation. $K$-shot supernets and simplex-net can be iteratively trained, and we further extend the search to the channel dimension. Extensive experiments on benchmark datasets validate that K-shot NAS significantly improves the evaluation accuracy of paths and thus brings in impressive performance improvements.
The Definitions of Interpretability and Learning of Interpretable Models
May 29, 2021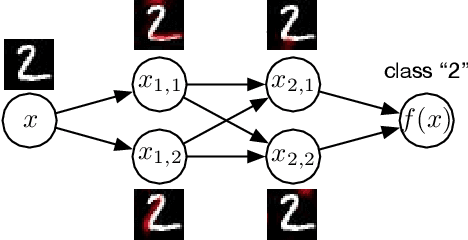

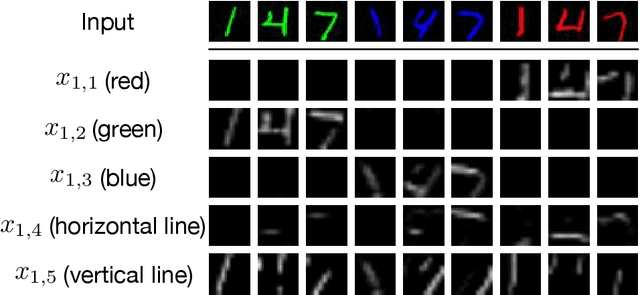
As machine learning algorithms getting adopted in an ever-increasing number of applications, interpretation has emerged as a crucial desideratum. In this paper, we propose a mathematical definition for the human-interpretable model. In particular, we define interpretability between two information process systems. If a prediction model is interpretable by a human recognition system based on the above interpretability definition, the prediction model is defined as a completely human-interpretable model. We further design a practical framework to train a completely human-interpretable model by user interactions. Experiments on image datasets show the advantages of our proposed model in two aspects: 1) The completely human-interpretable model can provide an entire decision-making process that is human-understandable; 2) The completely human-interpretable model is more robust against adversarial attacks.
BCNet: Searching for Network Width with Bilaterally Coupled Network
May 21, 2021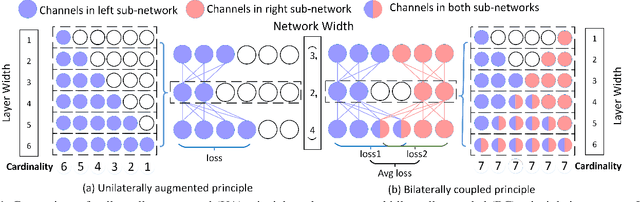
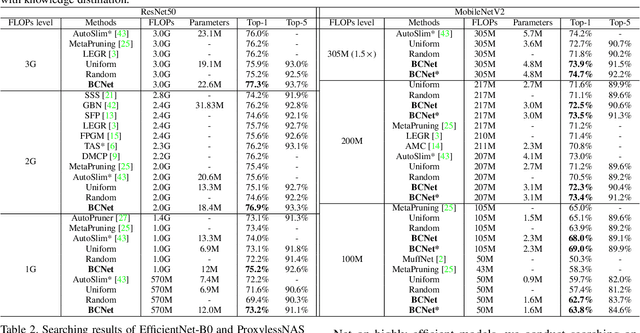
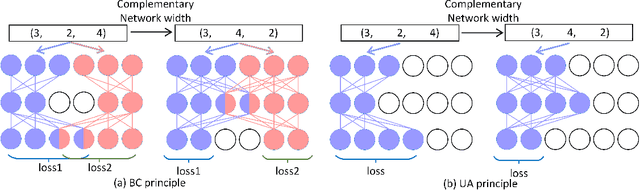
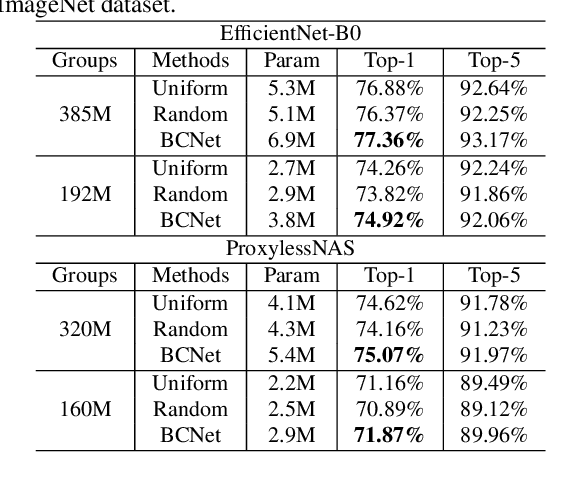
Searching for a more compact network width recently serves as an effective way of channel pruning for the deployment of convolutional neural networks (CNNs) under hardware constraints. To fulfill the searching, a one-shot supernet is usually leveraged to efficiently evaluate the performance \wrt~different network widths. However, current methods mainly follow a \textit{unilaterally augmented} (UA) principle for the evaluation of each width, which induces the training unfairness of channels in supernet. In this paper, we introduce a new supernet called Bilaterally Coupled Network (BCNet) to address this issue. In BCNet, each channel is fairly trained and responsible for the same amount of network widths, thus each network width can be evaluated more accurately. Besides, we leverage a stochastic complementary strategy for training the BCNet, and propose a prior initial population sampling method to boost the performance of the evolutionary search. Extensive experiments on benchmark CIFAR-10 and ImageNet datasets indicate that our method can achieve state-of-the-art or competing performance over other baseline methods. Moreover, our method turns out to further boost the performance of NAS models by refining their network widths. For example, with the same FLOPs budget, our obtained EfficientNet-B0 achieves 77.36\% Top-1 accuracy on ImageNet dataset, surpassing the performance of original setting by 0.48\%.
Learning a Proposal Classifier for Multiple Object Tracking
Mar 26, 2021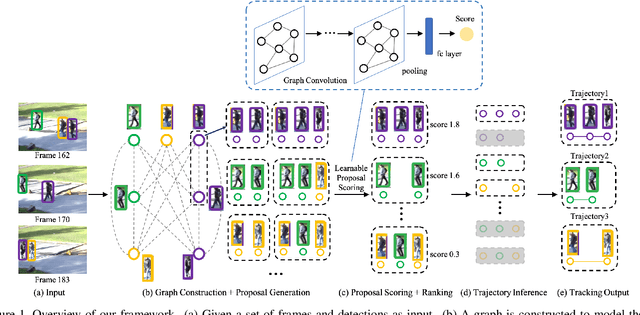
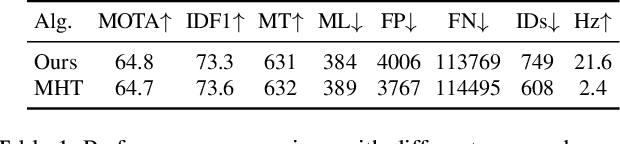
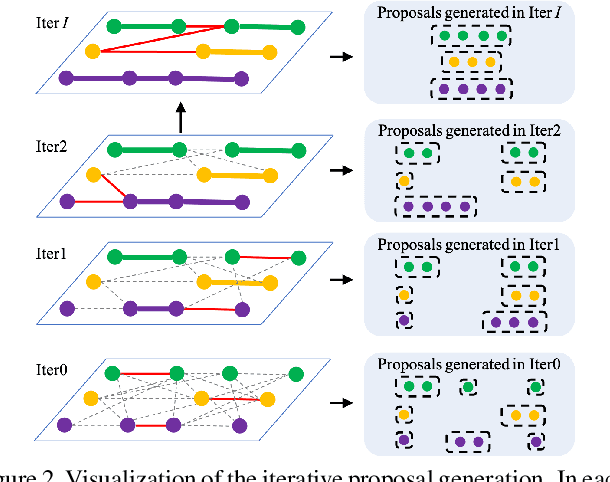
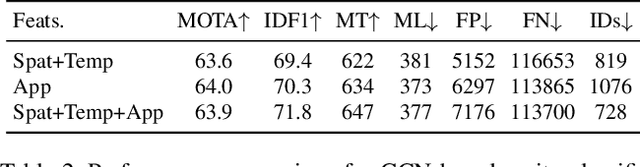
The recent trend in multiple object tracking (MOT) is heading towards leveraging deep learning to boost the tracking performance. However, it is not trivial to solve the data-association problem in an end-to-end fashion. In this paper, we propose a novel proposal-based learnable framework, which models MOT as a proposal generation, proposal scoring and trajectory inference paradigm on an affinity graph. This framework is similar to the two-stage object detector Faster RCNN, and can solve the MOT problem in a data-driven way. For proposal generation, we propose an iterative graph clustering method to reduce the computational cost while maintaining the quality of the generated proposals. For proposal scoring, we deploy a trainable graph-convolutional-network (GCN) to learn the structural patterns of the generated proposals and rank them according to the estimated quality scores. For trajectory inference, a simple deoverlapping strategy is adopted to generate tracking output while complying with the constraints that no detection can be assigned to more than one track. We experimentally demonstrate that the proposed method achieves a clear performance improvement in both MOTA and IDF1 with respect to previous state-of-the-art on two public benchmarks. Our code is available at https://github.com/daip13/LPC_MOT.git.