 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximately Optimal Global Planning for Contact-Rich SE(2) Manipulation on a Graph of Reachable Sets
Jan 15, 2026If we consider human manipulation, it is clear that contact-rich manipulation (CRM)-the ability to use any surface of the manipulator to make contact with objects-can be far more efficient and natural than relying solely on end-effectors (i.e., fingertips). However, state-of-the-art model-based planners for CRM are still focused on feasibility rather than optimality, limiting their ability to fully exploit CRM's advantages. We introduce a new paradigm that computes approximately optimal manipulator plans. This approach has two phases. Offline, we construct a graph of mutual reachable sets, where each set contains all object orientations reachable from a starting object orientation and grasp. Online, we plan over this graph, effectively computing and sequencing local plans for globally optimized motion. On a challenging, representative contact-rich task, our approach outperforms a leading planner, reducing task cost by 61%. It also achieves a 91% success rate across 250 queries and maintains sub-minute query times, ultimately demonstrating that globally optimized contact-rich manipulation is now practical for real-world tasks.
VIRAL: Visual Sim-to-Real at Scale for Humanoid Loco-Manipulation
Nov 19, 2025



A key barrier to the real-world deployment of humanoid robots is the lack of autonomous loco-manipulation skills. We introduce VIRAL, a visual sim-to-real framework that learns humanoid loco-manipulation entirely in simulation and deploys it zero-shot to real hardware. VIRAL follows a teacher-student design: a privileged RL teacher, operating on full state, learns long-horizon loco-manipulation using a delta action space and reference state initialization. A vision-based student policy is then distilled from the teacher via large-scale simulation with tiled rendering, trained with a mixture of online DAgger and behavior cloning. We find that compute scale is critical: scaling simulation to tens of GPUs (up to 64) makes both teacher and student training reliable, while low-compute regimes often fail. To bridge the sim-to-real gap, VIRAL combines large-scale visual domain randomization over lighting, materials, camera parameters, image quality, and sensor delays--with real-to-sim alignment of the dexterous hands and cameras. Deployed on a Unitree G1 humanoid, the resulting RGB-based policy performs continuous loco-manipulation for up to 54 cycles, generalizing to diverse spatial and appearance variations without any real-world fine-tuning, and approaching expert-level teleoperation performance. Extensive ablations dissect the key design choices required to make RGB-based humanoid loco-manipulation work in practice.
Prompt-to-Product: Generative Assembly via Bimanual Manipulation
Aug 28, 2025



Creating assembly products demands significant manual effort and expert knowledge in 1) designing the assembly and 2) constructing the product. This paper introduces Prompt-to-Product, an automated pipeline that generates real-world assembly products from natural language prompts. Specifically, we leverage LEGO bricks as the assembly platform and automate the process of creating brick assembly structures. Given the user design requirements, Prompt-to-Product generates physically buildable brick designs, and then leverages a bimanual robotic system to construct the real assembly products, bringing user imaginations into the real world. We conduct a comprehensive user study, and the results demonstrate that Prompt-to-Product significantly lowers the barrier and reduces manual effort in creating assembly products from imaginative ideas.
NeSyPack: A Neuro-Symbolic Framework for Bimanual Logistics Packing
Jun 06, 2025This paper presents NeSyPack, a neuro-symbolic framework for bimanual logistics packing. NeSyPack combines data-driven models and symbolic reasoning to build an explainable hierarchical system that is generalizable, data-efficient, and reliable. It decomposes a task into subtasks via hierarchical reasoning, and further into atomic skills managed by a symbolic skill graph. The graph selects skill parameters, robot configurations, and task-specific control strategies for execution. This modular design enables robustness, adaptability, and efficient reuse - outperforming end-to-end models that require large-scale retraining. Using NeSyPack, our team won the First Prize in the What Bimanuals Can Do (WBCD) competition at the 2025 IEEE International Conference on Robotics and Automation.
Control Invariant Sets for Neural Network Dynamical Systems and Recursive Feasibility in Model Predictive Control
May 15, 2025



Neural networks are powerful tools for data-driven modeling of complex dynamical systems, enhancing predictive capability for control applications. However, their inherent nonlinearity and black-box nature challenge control designs that prioritize rigorous safety and recursive feasibility guarantees. This paper presents algorithmic methods for synthesizing control invariant sets specifically tailored to neural network based dynamical models. These algorithms employ set recursion, ensuring termination after a finite number of iterations and generating subsets in which closed-loop dynamics are forward invariant, thus guaranteeing perpetual operational safety. Additionally, we propose model predictive control designs that integrate these control invariant sets into mixed-integer optimization, with guaranteed adherence to safety constraints and recursive feasibility at the computational level. We also present a comprehensive theoretical analysis examining the properties and guarantees of the proposed methods. Numerical simulations in an autonomous driving scenario demonstrate the methods' effectiveness in synthesizing control-invariant sets offline and implementing model predictive control online, ensuring safety and recursive feasibility.
Deployable and Generalizable Motion Prediction: Taxonomy, Open Challenges and Future Directions
May 14, 2025



Motion prediction, the anticipation of future agent states or scene evolution, is rooted in human cognition, bridging perception and decision-making. It enables intelligent systems, such as robots and self-driving cars, to act safely in dynamic, human-involved environments, and informs broader time-series reasoning challenges. With advances in methods, representations, and datasets, the field has seen rapid progress, reflected in quickly evolving benchmark results. Yet, when state-of-the-art methods are deployed in the real world, they often struggle to generalize to open-world conditions and fall short of deployment standards. This reveals a gap between research benchmarks, which are often idealized or ill-posed, and real-world complexity. To address this gap, this survey revisits the generalization and deployability of motion prediction models, with an emphasis on the applications of robotics, autonomous driving, and human motion. We first offer a comprehensive taxonomy of motion prediction methods, covering representations, modeling strategies, application domains, and evaluation protocols. We then study two key challenges: (1) how to push motion prediction models to be deployable to realistic deployment standards, where motion prediction does not act in a vacuum, but functions as one module of closed-loop autonomy stacks - it takes input from the localization and perception, and informs downstream planning and control. 2) how to generalize motion prediction models from limited seen scenarios/datasets to the open-world settings. Throughout the paper, we highlight critical open challenges to guide future work, aiming to recalibrate the community's efforts, fostering progress that is not only measurable but also meaningful for real-world applications.
Generating Physically Stable and Buildable LEGO Designs from Text
May 08, 2025


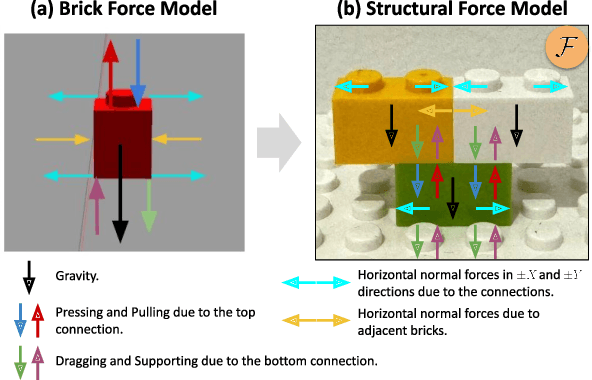
We introduce LegoGPT, the first approach for generating physically stable LEGO brick models from text prompts. To achieve this, we construct a large-scale, physically stable dataset of LEGO designs, along with their associated captions, and train an autoregressive large language model to predict the next brick to add via next-token prediction. To improve the stability of the resulting designs, we employ an efficient validity check and physics-aware rollback during autoregressive inference, which prunes infeasible token predictions using physics laws and assembly constraints. Our experiments show that LegoGPT produces stable, diverse, and aesthetically pleasing LEGO designs that align closely with the input text prompts. We also develop a text-based LEGO texturing method to generate colored and textured designs. We show that our designs can be assembled manually by humans and automatically by robotic arms. We also release our new dataset, StableText2Lego, containing over 47,000 LEGO structures of over 28,000 unique 3D objects accompanied by detailed captions, along with our code and models at the project website: https://avalovelace1.github.io/LegoGPT/.
Demonstrating ViSafe: Vision-enabled Safety for High-speed Detect and Avoid
May 08, 2025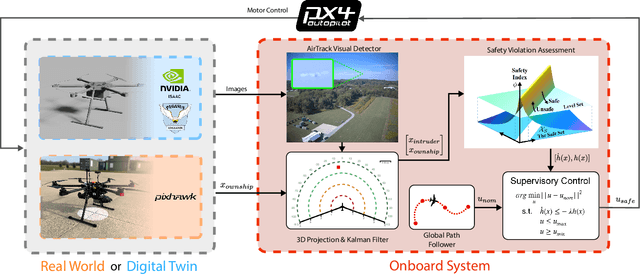
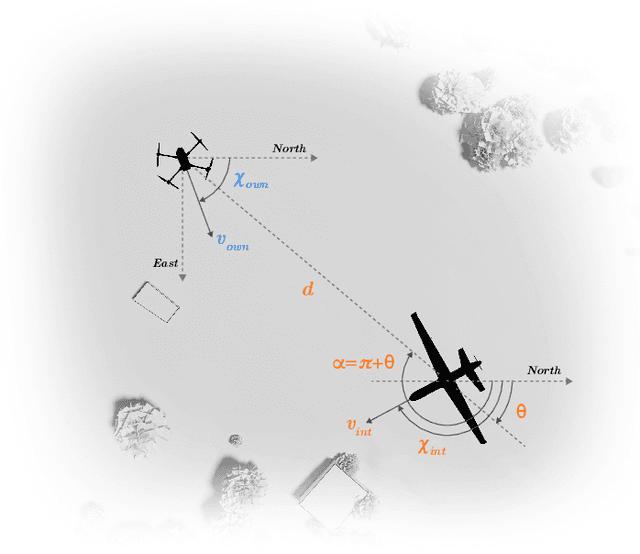

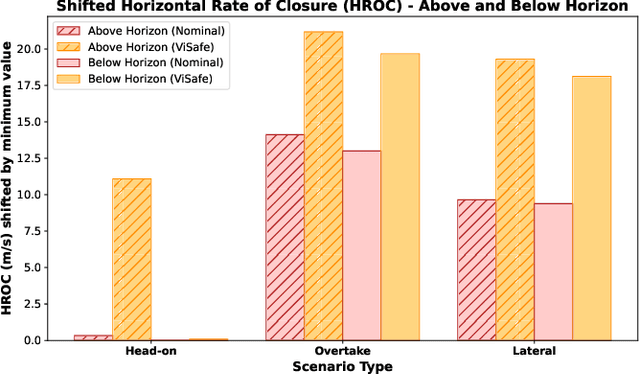
Assured safe-separation is essential for achieving seamless high-density operation of airborne vehicles in a shared airspace. To equip resource-constrained aerial systems with this safety-critical capability, we present ViSafe, a high-speed vision-only airborne collision avoidance system. ViSafe offers a full-stack solution to the Detect and Avoid (DAA) problem by tightly integrating a learning-based edge-AI framework with a custom multi-camera hardware prototype designed under SWaP-C constraints. By leveraging perceptual input-focused control barrier functions (CBF) to design, encode, and enforce safety thresholds, ViSafe can provide provably safe runtime guarantees for self-separation in high-speed aerial operations. We evaluate ViSafe's performance through an extensive test campaign involving both simulated digital twins and real-world flight scenarios. By independently varying agent types, closure rates, interaction geometries, and environmental conditions (e.g., weather and lighting), we demonstrate that ViSafe consistently ensures self-separation across diverse scenarios. In first-of-its-kind real-world high-speed collision avoidance tests with closure rates reaching 144 km/h, ViSafe sets a new benchmark for vision-only autonomous collision avoidance, establishing a new standard for safety in high-speed aerial navigation.
Hierarchical Temporal Logic Task and Motion Planning for Multi-Robot Systems
Apr 29, 2025Task and motion planning (TAMP) for multi-robot systems, which integrates discrete task planning with continuous motion planning, remains a challenging problem in robotics. Existing TAMP approaches often struggle to scale effectively for multi-robot systems with complex specifications, leading to infeasible solutions and prolonged computation times. This work addresses the TAMP problem in multi-robot settings where tasks are specified using expressive hierarchical temporal logic and task assignments are not pre-determined. Our approach leverages the efficiency of hierarchical temporal logic specifications for task-level planning and the optimization-based graph of convex sets method for motion-level planning, integrating them within a product graph framework. At the task level, we convert hierarchical temporal logic specifications into a single graph, embedding task allocation within its edges. At the motion level, we represent the feasible motions of multiple robots through convex sets in the configuration space, guided by a sampling-based motion planner. This formulation allows us to define the TAMP problem as a shortest path search within the product graph, where efficient convex optimization techniques can be applied. We prove that our approach is both sound and complete under mild assumptions. Additionally, we extend our framework to cooperative pick-and-place tasks involving object handovers between robots. We evaluate our method across various high-dimensional multi-robot scenarios, including simulated and real-world environments with quadrupeds, robotic arms, and automated conveyor systems. Our results show that our approach outperforms existing methods in execution time and solution optimality while effectively scaling with task complexity.
APEX-MR: Multi-Robot Asynchronous Planning and Execution for Cooperative Assembly
Mar 20, 2025Compared to a single-robot workstation, a multi-robot system offers several advantages: 1) it expands the system's workspace, 2) improves task efficiency, and more importantly, 3) enables robots to achieve significantly more complex and dexterous tasks, such as cooperative assembly. However, coordinating the tasks and motions of multiple robots is challenging due to issues, e.g. system uncertainty, task efficiency, algorithm scalability, and safety concerns. To address these challenges, this paper studies multi-robot coordination and proposes APEX-MR, an asynchronous planning and execution framework designed to safely and efficiently coordinate multiple robots to achieve cooperative assembly, e.g. LEGO assembly. In particular, APEX-MR provides a systematic approach to post-process multi-robot tasks and motion plans to enable robust asynchronous execution under uncertainty. Experimental results demonstrate that APEX-MR can significantly speed up the execution time of many long-horizon LEGO assembly tasks by 48% compared to sequential planning and 36% compared to synchronous planning on average. To further demonstrate the performance, we deploy APEX-MR to a dual-arm system to perform physical LEGO assembly. To our knowledge, this is the first robotic system capable of performing customized LEGO assembly using commercial LEGO bricks. The experiment results demonstrate that the dual-arm system, with APEX-MR, can safely coordinate robot motions, efficiently collaborate, and construct complex LEGO structures. Our project website is available at https://intelligent-control-lab.github.io/APEX-MR/