 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTucker-O-Minus Decomposition for Multi-view Tensor Subspace Clustering
Oct 23, 2022



With powerful ability to exploit latent structure of self-representation information, different tensor decompositions have been employed into low rank multi-view clustering (LRMVC) models for achieving significant performance. However, current approaches suffer from a series of problems related to those tensor decomposition, such as the unbalanced matricization scheme, rotation sensitivity, deficient correlations capture and so forth. All these will lead to LRMVC having insufficient access to global information, which is contrary to the target of multi-view clustering. To alleviate these problems, we propose a new tensor decomposition called Tucker-O-Minus Decomposition (TOMD) for multi-view clustering. Specifically, based on the Tucker format, we additionally employ the O-minus structure, which consists of a circle with an efficient bridge linking two weekly correlated factors. In this way, the core tensor in Tucker format is replaced by the O-minus architecture with a more balanced structure, and the enhanced capacity of capturing the global low rank information will be achieved. The proposed TOMD also provides more compact and powerful representation abilities for the self-representation tensor, simultaneously. The alternating direction method of multipliers is used to solve the proposed model TOMD-MVC. Numerical experiments on six benchmark data sets demonstrate the superiority of our proposed method in terms of F-score, precision, recall, normalized mutual information, adjusted rand index, and accuracy.
Learning Nonlocal Sparse and Low-Rank Models for Image Compressive Sensing
Mar 22, 2022
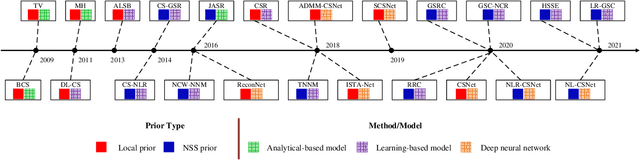

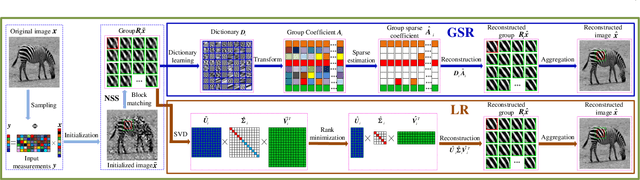
The compressive sensing (CS) scheme exploits much fewer measurements than suggested by the Nyquist-Shannon sampling theorem to accurately reconstruct images, which has attracted considerable attention in the computational imaging community. While classic image CS schemes employed sparsity using analytical transforms or bases, the learning-based approaches have become increasingly popular in recent years. Such methods can effectively model the structures of image patches by optimizing their sparse representations or learning deep neural networks, while preserving the known or modeled sensing process. Beyond exploiting local image properties, advanced CS schemes adopt nonlocal image modeling, by extracting similar or highly correlated patches at different locations of an image to form a group to process jointly. More recent learning-based CS schemes apply nonlocal structured sparsity prior using group sparse representation (GSR) and/or low-rank (LR) modeling, which have demonstrated promising performance in various computational imaging and image processing applications. This article reviews some recent works in image CS tasks with a focus on the advanced GSR and LR based methods. Furthermore, we present a unified framework for incorporating various GSR and LR models and discuss the relationship between GSR and LR models. Finally, we discuss the open problems and future directions in the field.
Semi-tensor Product-based TensorDecomposition for Neural Network Compression
Sep 30, 2021
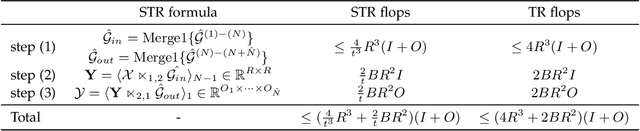
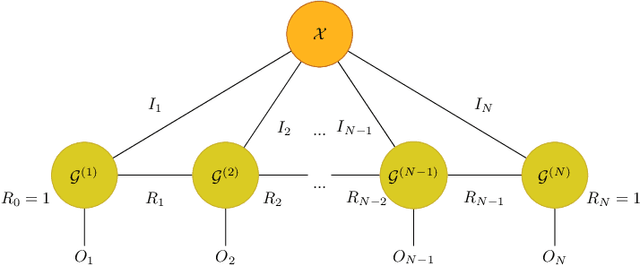

The existing tensor networks adopt conventional matrix product for connection. The classical matrix product requires strict dimensionality consistency between factors, which can result in redundancy in data representation. In this paper, the semi-tensor product is used to generalize classical matrix product-based mode product to semi-tensor mode product. As it permits the connection of two factors with different dimensionality, more flexible and compact tensor decompositions can be obtained with smaller sizes of factors. Tucker decomposition, Tensor Train (TT) and Tensor Ring (TR) are common decomposition for low rank compression of deep neural networks. The semi-tensor product is applied to these tensor decompositions to obtained their generalized versions, i.e., semi-tensor Tucker decomposition (STTu), semi-tensor train(STT) and semi-tensor ring (STR). Experimental results show the STTu, STT and STR achieve higher compression factors than the conventional tensor decompositions with the same accuracy but less training times in ResNet and WideResNetcompression. With 2% accuracy degradation, the TT-RN (rank = 14) and the TR-WRN (rank = 16) only obtain 3 times and99t times compression factors while the STT-RN (rank = 14) and the STR-WRN (rank = 16) achieve 9 times and 179 times compression factors, respectively.
Feature Encoding with AutoEncoders for Weakly-supervised Anomaly Detection
Jun 03, 2021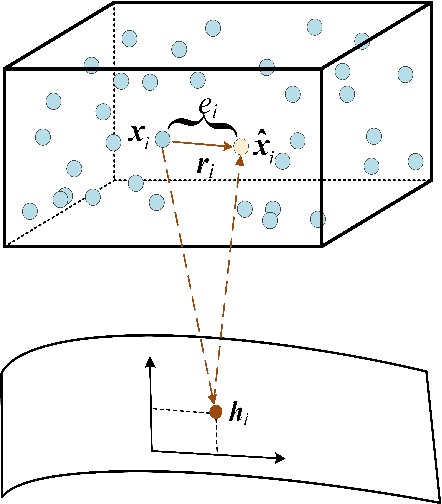
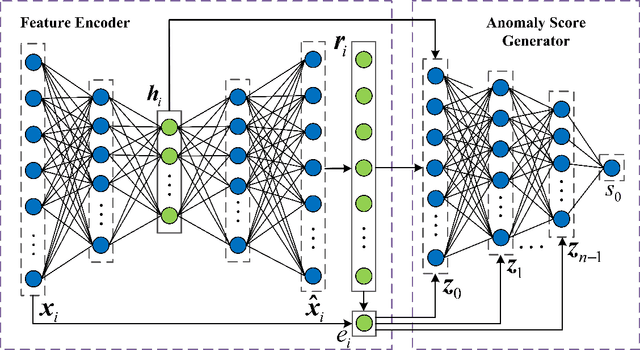
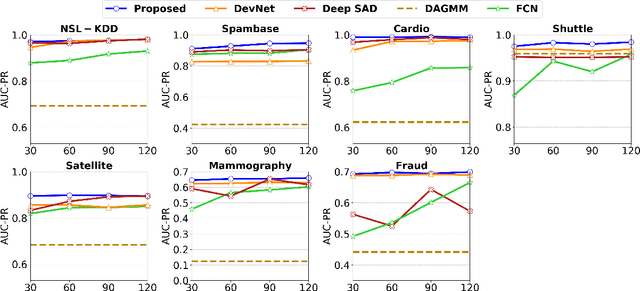
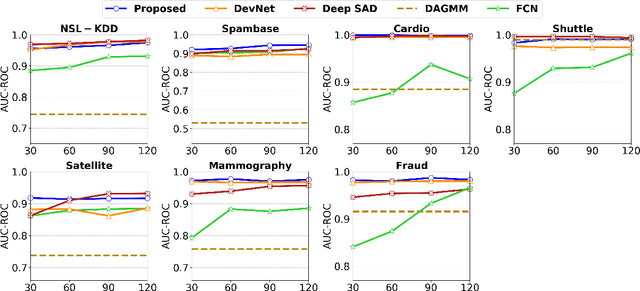
Weakly-supervised anomaly detection aims at learning an anomaly detector from a limited amount of labeled data and abundant unlabeled data. Recent works build deep neural networks for anomaly detection by discriminatively mapping the normal samples and abnormal samples to different regions in the feature space or fitting different distributions. However, due to the limited number of annotated anomaly samples, directly training networks with the discriminative loss may not be sufficient. To overcome this issue, this paper proposes a novel strategy to transform the input data into a more meaningful representation that could be used for anomaly detection. Specifically, we leverage an autoencoder to encode the input data and utilize three factors, hidden representation, reconstruction residual vector, and reconstruction error, as the new representation for the input data. This representation amounts to encode a test sample with its projection on the training data manifold, its direction to its projection and its distance to its projection. In addition to this encoding, we also propose a novel network architecture to seamlessly incorporate those three factors. From our extensive experiments, the benefits of the proposed strategy are clearly demonstrated by its superior performance over the competitive methods.
Performance Evaluation of Adversarial Attacks: Discrepancies and Solutions
Apr 22, 2021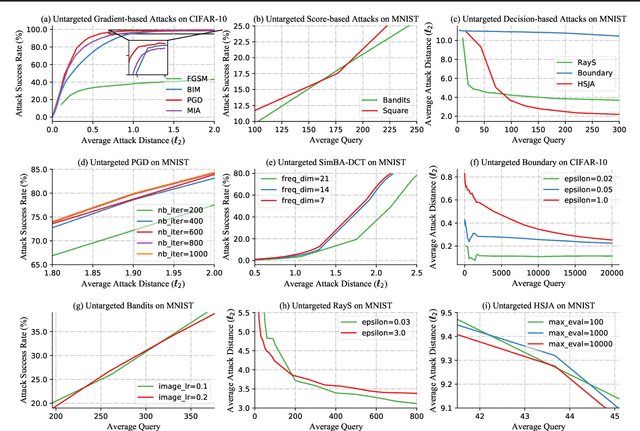

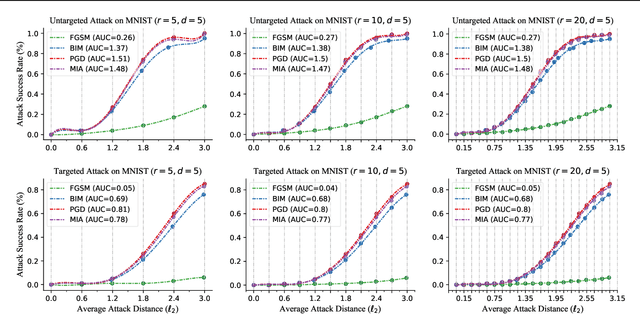
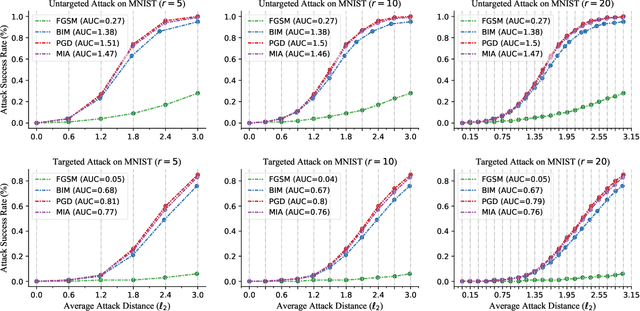
Recently, adversarial attack methods have been developed to challenge the robustness of machine learning models. However, mainstream evaluation criteria experience limitations, even yielding discrepancies among results under different settings. By examining various attack algorithms, including gradient-based and query-based attacks, we notice the lack of a consensus on a uniform standard for unbiased performance evaluation. Accordingly, we propose a Piece-wise Sampling Curving (PSC) toolkit to effectively address the aforementioned discrepancy, by generating a comprehensive comparison among adversaries in a given range. In addition, the PSC toolkit offers options for balancing the computational cost and evaluation effectiveness. Experimental results demonstrate our PSC toolkit presents comprehensive comparisons of attack algorithms, significantly reducing discrepancies in practice.
Real-World Single Image Super-Resolution: A Brief Review
Mar 03, 2021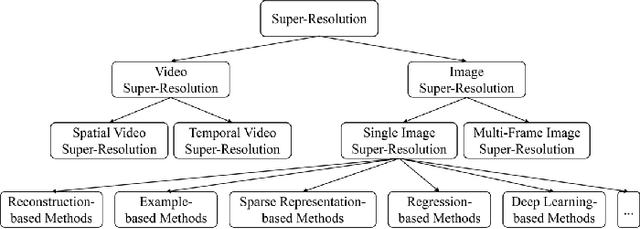

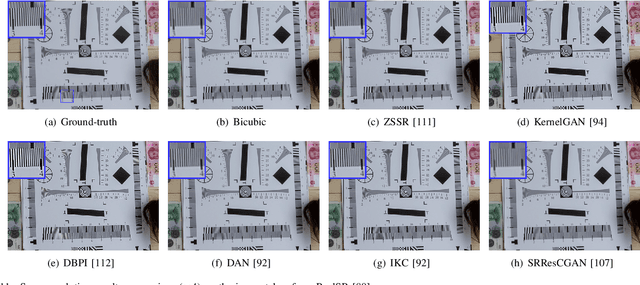
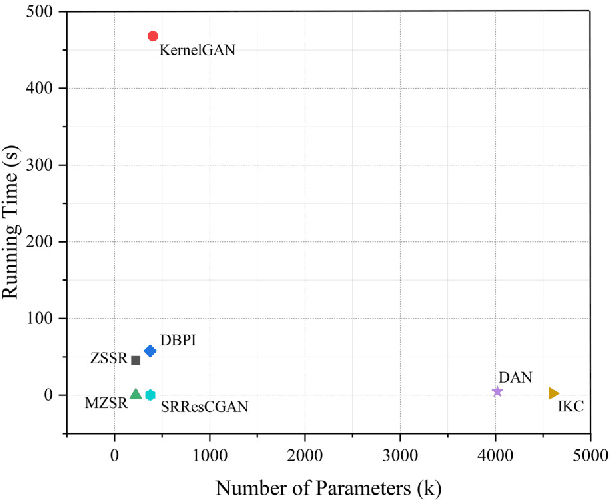
Single image super-resolution (SISR), which aims to reconstruct a high-resolution (HR) image from a low-resolution (LR) observation, has been an active research topic in the area of image processing in recent decades. Particularly, deep learning-based super-resolution (SR) approaches have drawn much attention and have greatly improved the reconstruction performance on synthetic data. Recent studies show that simulation results on synthetic data usually overestimate the capacity to super-resolve real-world images. In this context, more and more researchers devote themselves to develop SR approaches for realistic images. This article aims to make a comprehensive review on real-world single image super-resolution (RSISR). More specifically, this review covers the critical publically available datasets and assessment metrics for RSISR, and four major categories of RSISR methods, namely the degradation modeling-based RSISR, image pairs-based RSISR, domain translation-based RSISR, and self-learning-based RSISR. Comparisons are also made among representative RSISR methods on benchmark datasets, in terms of both reconstruction quality and computational efficiency. Besides, we discuss challenges and promising research topics on RSISR.
Scalable Deep Compressive Sensing
Jan 22, 2021
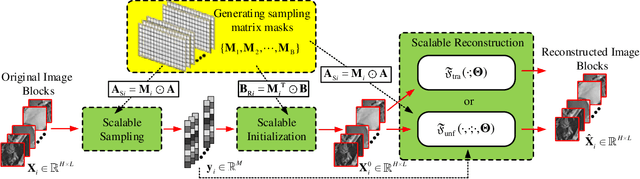
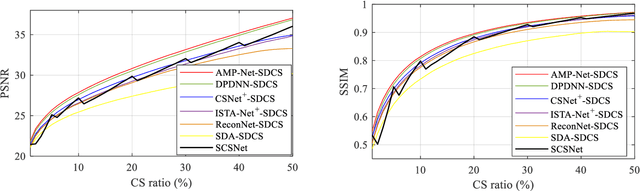
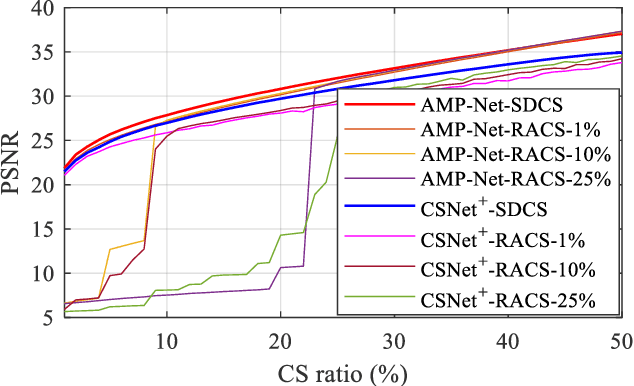
Deep learning has been used to image compressive sensing (CS) for enhanced reconstruction performance. However, most existing deep learning methods train different models for different subsampling ratios, which brings additional hardware burden. In this paper, we develop a general framework named scalable deep compressive sensing (SDCS) for the scalable sampling and reconstruction (SSR) of all existing end-to-end-trained models. In the proposed way, images are measured and initialized linearly. Two sampling masks are introduced to flexibly control the subsampling ratios used in sampling and reconstruction, respectively. To make the reconstruction model adapt to any subsampling ratio, a training strategy dubbed scalable training is developed. In scalable training, the model is trained with the sampling matrix and the initialization matrix at various subsampling ratios by integrating different sampling matrix masks. Experimental results show that models with SDCS can achieve SSR without changing their structure while maintaining good performance, and SDCS outperforms other SSR methods.
Learning Deep Interleaved Networks with Asymmetric Co-Attention for Image Restoration
Oct 29, 2020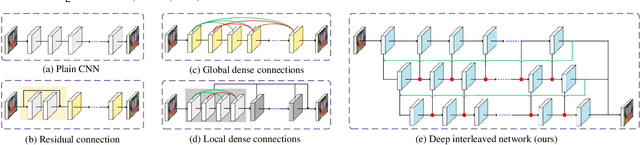
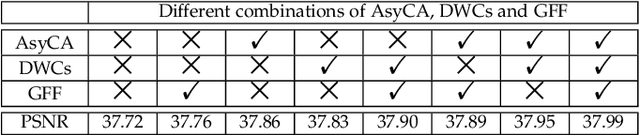
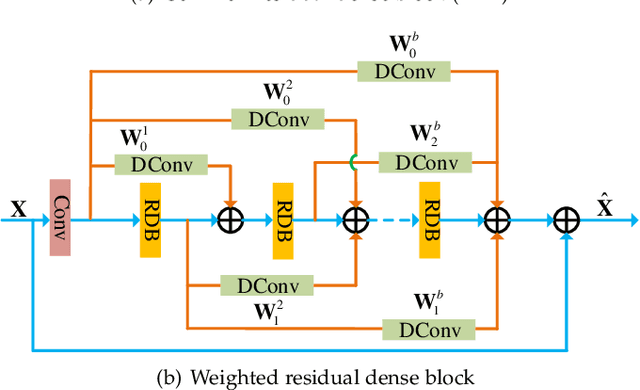
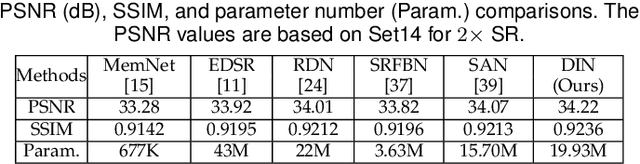
Recently, convolutional neural network (CNN) has demonstrated significant success for image restoration (IR) tasks (e.g., image super-resolution, image deblurring, rain streak removal, and dehazing). However, existing CNN based models are commonly implemented as a single-path stream to enrich feature representations from low-quality (LQ) input space for final predictions, which fail to fully incorporate preceding low-level contexts into later high-level features within networks, thereby producing inferior results. In this paper, we present a deep interleaved network (DIN) that learns how information at different states should be combined for high-quality (HQ) images reconstruction. The proposed DIN follows a multi-path and multi-branch pattern allowing multiple interconnected branches to interleave and fuse at different states. In this way, the shallow information can guide deep representative features prediction to enhance the feature expression ability. Furthermore, we propose asymmetric co-attention (AsyCA) which is attached at each interleaved node to model the feature dependencies. Such AsyCA can not only adaptively emphasize the informative features from different states, but also improves the discriminative ability of networks. Our presented DIN can be trained end-to-end and applied to various IR tasks. Comprehensive evaluations on public benchmarks and real-world datasets demonstrate that the proposed DIN perform favorably against the state-of-the-art methods quantitatively and qualitatively.
Decision-based Universal Adversarial Attack
Sep 17, 2020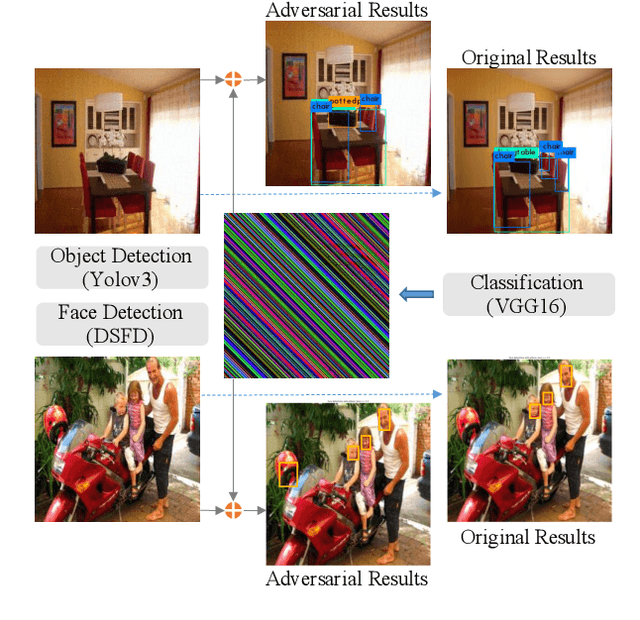

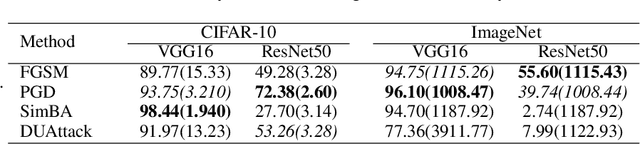

A single perturbation can pose the most natural images to be misclassified by classifiers. In black-box setting, current universal adversarial attack methods utilize substitute models to generate the perturbation, then apply the perturbation to the attacked model. However, this transfer often produces inferior results. In this study, we directly work in the black-box setting to generate the universal adversarial perturbation. Besides, we aim to design an adversary generating a single perturbation having texture like stripes based on orthogonal matrix, as the top convolutional layers are sensitive to stripes. To this end, we propose an efficient Decision-based Universal Attack (DUAttack). With few data, the proposed adversary computes the perturbation based solely on the final inferred labels, but good transferability has been realized not only across models but also span different vision tasks. The effectiveness of DUAttack is validated through comparisons with other state-of-the-art attacks. The efficiency of DUAttack is also demonstrated on real world settings including the Microsoft Azure. In addition, several representative defense methods are struggling with DUAttack, indicating the practicability of the proposed method.
Siamese Network for RGB-D Salient Object Detection and Beyond
Aug 26, 2020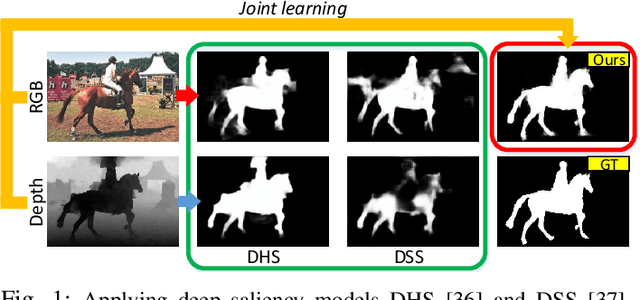

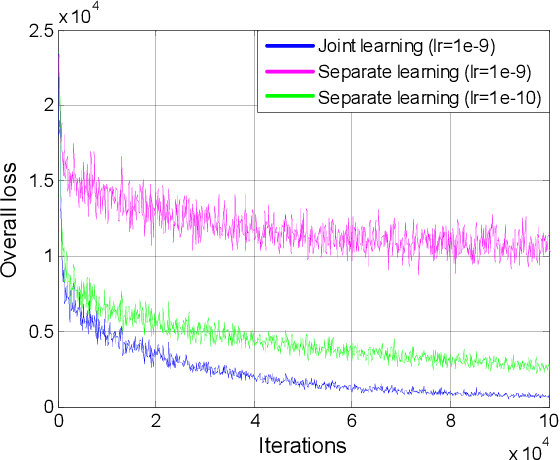

Existing RGB-D salient object detection (SOD) models usually treat RGB and depth as independent information and design separate networks for feature extraction from each. Such schemes can easily be constrained by a limited amount of training data or over-reliance on an elaborately designed training process. Inspired by the observation that RGB and depth modalities actually present certain commonality in distinguishing salient objects, a novel joint learning and densely cooperative fusion (JL-DCF) architecture is designed to learn from both RGB and depth inputs through a shared network backbone, known as the Siamese architecture. In this paper, we propose two effective components: joint learning (JL), and densely cooperative fusion (DCF). The JL module provides robust saliency feature learning by exploiting cross-modal commonality via a Siamese network, while the DCF module is introduced for complementary feature discovery. Comprehensive experiments using five popular metrics show that the designed framework yields a robust RGB-D saliency detector with good generalization. As a result, JL-DCF significantly advances the state-of-the-art models by an average of ~2.0% (F-measure) across seven challenging datasets. In addition, we show that JL-DCF is readily applicable to other related multi-modal detection tasks, including RGB-T (thermal infrared) SOD and video SOD (VSOD), achieving comparable or even better performance against state-of-the-art methods. This further confirms that the proposed framework could offer a potential solution for various applications and provide more insight into the cross-modal complementarity task. The code will be available at https://github.com/kerenfu/JLDCF/