 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Emerging AI/ML Accelerators: IPU, RDU, and NVIDIA/AMD GPUs
Nov 08, 2023The relentless advancement of artificial intelligence (AI) and machine learning (ML) applications necessitates the development of specialized hardware accelerators capable of handling the increasing complexity and computational demands. Traditional computing architectures, based on the von Neumann model, are being outstripped by the requirements of contemporary AI/ML algorithms, leading to a surge in the creation of accelerators like the Graphcore Intelligence Processing Unit (IPU), Sambanova Reconfigurable Dataflow Unit (RDU), and enhanced GPU platforms. These hardware accelerators are characterized by their innovative data-flow architectures and other design optimizations that promise to deliver superior performance and energy efficiency for AI/ML tasks. This research provides a preliminary evaluation and comparison of these commercial AI/ML accelerators, delving into their hardware and software design features to discern their strengths and unique capabilities. By conducting a series of benchmark evaluations on common DNN operators and other AI/ML workloads, we aim to illuminate the advantages of data-flow architectures over conventional processor designs and offer insights into the performance trade-offs of each platform. The findings from our study will serve as a valuable reference for the design and performance expectations of research prototypes, thereby facilitating the development of next-generation hardware accelerators tailored for the ever-evolving landscape of AI/ML applications. Through this analysis, we aspire to contribute to the broader understanding of current accelerator technologies and to provide guidance for future innovations in the field.
LinGCN: Structural Linearized Graph Convolutional Network for Homomorphically Encrypted Inference
Sep 30, 2023



The growth of Graph Convolution Network (GCN) model sizes has revolutionized numerous applications, surpassing human performance in areas such as personal healthcare and financial systems. The deployment of GCNs in the cloud raises privacy concerns due to potential adversarial attacks on client data. To address security concerns, Privacy-Preserving Machine Learning (PPML) using Homomorphic Encryption (HE) secures sensitive client data. However, it introduces substantial computational overhead in practical applications. To tackle those challenges, we present LinGCN, a framework designed to reduce multiplication depth and optimize the performance of HE based GCN inference. LinGCN is structured around three key elements: (1) A differentiable structural linearization algorithm, complemented by a parameterized discrete indicator function, co-trained with model weights to meet the optimization goal. This strategy promotes fine-grained node-level non-linear location selection, resulting in a model with minimized multiplication depth. (2) A compact node-wise polynomial replacement policy with a second-order trainable activation function, steered towards superior convergence by a two-level distillation approach from an all-ReLU based teacher model. (3) an enhanced HE solution that enables finer-grained operator fusion for node-wise activation functions, further reducing multiplication level consumption in HE-based inference. Our experiments on the NTU-XVIEW skeleton joint dataset reveal that LinGCN excels in latency, accuracy, and scalability for homomorphically encrypted inference, outperforming solutions such as CryptoGCN. Remarkably, LinGCN achieves a 14.2x latency speedup relative to CryptoGCN, while preserving an inference accuracy of 75% and notably reducing multiplication depth.
DeeDiff: Dynamic Uncertainty-Aware Early Exiting for Accelerating Diffusion Model Generation
Sep 29, 2023Diffusion models achieve great success in generating diverse and high-fidelity images. The performance improvements come with low generation speed per image, which hinders the application diffusion models in real-time scenarios. While some certain predictions benefit from the full computation of the model in each sample iteration, not every iteration requires the same amount of computation, potentially leading to computation waste. In this work, we propose DeeDiff, an early exiting framework that adaptively allocates computation resources in each sampling step to improve the generation efficiency of diffusion models. Specifically, we introduce a timestep-aware uncertainty estimation module (UEM) for diffusion models which is attached to each intermediate layer to estimate the prediction uncertainty of each layer. The uncertainty is regarded as the signal to decide if the inference terminates. Moreover, we propose uncertainty-aware layer-wise loss to fill the performance gap between full models and early-exited models. With such loss strategy, our model is able to obtain comparable results as full-layer models. Extensive experiments of class-conditional, unconditional, and text-guided generation on several datasets show that our method achieves state-of-the-art performance and efficiency trade-off compared with existing early exiting methods on diffusion models. More importantly, our method even brings extra benefits to baseline models and obtains better performance on CIFAR-10 and Celeb-A datasets. Full code and model are released for reproduction.
Accel-GCN: High-Performance GPU Accelerator Design for Graph Convolution Networks
Aug 22, 2023



Graph Convolutional Networks (GCNs) are pivotal in extracting latent information from graph data across various domains, yet their acceleration on mainstream GPUs is challenged by workload imbalance and memory access irregularity. To address these challenges, we present Accel-GCN, a GPU accelerator architecture for GCNs. The design of Accel-GCN encompasses: (i) a lightweight degree sorting stage to group nodes with similar degree; (ii) a block-level partition strategy that dynamically adjusts warp workload sizes, enhancing shared memory locality and workload balance, and reducing metadata overhead compared to designs like GNNAdvisor; (iii) a combined warp strategy that improves memory coalescing and computational parallelism in the column dimension of dense matrices. Utilizing these principles, we formulated a kernel for sparse matrix multiplication (SpMM) in GCNs that employs block-level partitioning and combined warp strategy. This approach augments performance and multi-level memory efficiency and optimizes memory bandwidth by exploiting memory coalescing and alignment. Evaluation of Accel-GCN across 18 benchmark graphs reveals that it outperforms cuSPARSE, GNNAdvisor, and graph-BLAST by factors of 1.17 times, 1.86 times, and 2.94 times respectively. The results underscore Accel-GCN as an effective solution for enhancing GCN computational efficiency.
AutoReP: Automatic ReLU Replacement for Fast Private Network Inference
Aug 20, 2023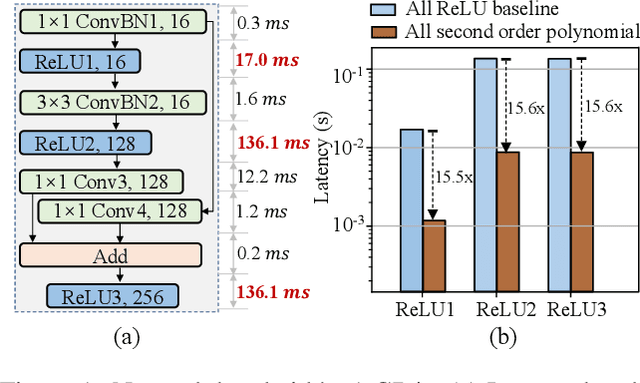

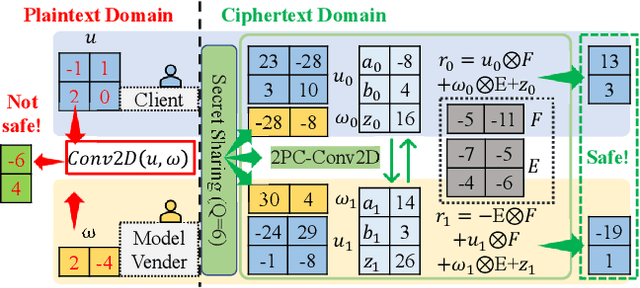
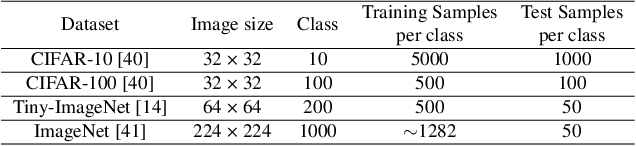
The growth of the Machine-Learning-As-A-Service (MLaaS) market has highlighted clients' data privacy and security issues. Private inference (PI) techniques using cryptographic primitives offer a solution but often have high computation and communication costs, particularly with non-linear operators like ReLU. Many attempts to reduce ReLU operations exist, but they may need heuristic threshold selection or cause substantial accuracy loss. This work introduces AutoReP, a gradient-based approach to lessen non-linear operators and alleviate these issues. It automates the selection of ReLU and polynomial functions to speed up PI applications and introduces distribution-aware polynomial approximation (DaPa) to maintain model expressivity while accurately approximating ReLUs. Our experimental results demonstrate significant accuracy improvements of 6.12% (94.31%, 12.9K ReLU budget, CIFAR-10), 8.39% (74.92%, 12.9K ReLU budget, CIFAR-100), and 9.45% (63.69%, 55K ReLU budget, Tiny-ImageNet) over current state-of-the-art methods, e.g., SNL. Morever, AutoReP is applied to EfficientNet-B2 on ImageNet dataset, and achieved 75.55% accuracy with 176.1 times ReLU budget reduction.
Towards Zero Memory Footprint Spiking Neural Network Training
Aug 16, 2023



Biologically-inspired Spiking Neural Networks (SNNs), processing information using discrete-time events known as spikes rather than continuous values, have garnered significant attention due to their hardware-friendly and energy-efficient characteristics. However, the training of SNNs necessitates a considerably large memory footprint, given the additional storage requirements for spikes or events, leading to a complex structure and dynamic setup. In this paper, to address memory constraint in SNN training, we introduce an innovative framework, characterized by a remarkably low memory footprint. We \textbf{(i)} design a reversible SNN node that retains a high level of accuracy. Our design is able to achieve a $\mathbf{58.65\times}$ reduction in memory usage compared to the current SNN node. We \textbf{(ii)} propose a unique algorithm to streamline the backpropagation process of our reversible SNN node. This significantly trims the backward Floating Point Operations Per Second (FLOPs), thereby accelerating the training process in comparison to current reversible layer backpropagation method. By using our algorithm, the training time is able to be curtailed by $\mathbf{23.8\%}$ relative to existing reversible layer architectures.
Boosting Logical Reasoning in Large Language Models through a New Framework: The Graph of Thought
Aug 16, 2023Recent advancements in large-scale models, such as GPT-4, have showcased remarkable capabilities in addressing standard queries. However, when facing complex problems that require multi-step logical reasoning, their accuracy dramatically decreases. Current research has explored the realm of \textit{prompting engineering} to bolster the inferential capacities of these models. Our paper unveils a pioneering prompting technique, dubbed \textit{Graph of Thoughts (GoT)}. Through testing on a trio of escalating challenges: the 24-point game, resolution of high-degree polynomial equations, and derivation of formulas for recursive sequences, our method outperformed GPT-4, achieving accuracy improvements of $89.7\%$, $86\%$, and $56\%$ for each respective task. Moreover, when juxtaposed with the state-of-the-art (SOTA) prompting method, \textit{Tree of Thought (ToT)}, our approach registered an average accuracy boost of $23\%$, $24\%$, and $15\%$.
Tango: rethinking quantization for graph neural network training on GPUs
Aug 02, 2023



Graph Neural Networks (GNNs) are becoming increasingly popular due to their superior performance in critical graph-related tasks. While quantization is widely used to accelerate GNN computation, quantized training faces unprecedented challenges. Current quantized GNN training systems often have longer training times than their full-precision counterparts for two reasons: (i) addressing the accuracy challenge leads to excessive overhead, and (ii) the optimization potential exposed by quantization is not adequately leveraged. This paper introduces Tango which re-thinks quantization challenges and opportunities for graph neural network training on GPUs with three contributions: Firstly, we introduce efficient rules to maintain accuracy during quantized GNN training. Secondly, we design and implement quantization-aware primitives and inter-primitive optimizations that can speed up GNN training. Finally, we integrate Tango with the popular Deep Graph Library (DGL) system and demonstrate its superior performance over state-of-the-art approaches on various GNN models and datasets.
Creating a Dataset for High-Performance Computing Code Translation: A Bridge Between HPC Fortran and C++
Jul 28, 2023



In this study, we present a novel dataset for training machine learning models translating between OpenMP Fortran and C++ code. To ensure reliability and applicability, the dataset is initially refined using a meticulous code similarity test. The effectiveness of our dataset is assessed using both quantitative (CodeBLEU) and qualitative (human evaluation) methods. We demonstrate how this dataset can significantly improve the translation capabilities of large-scale language models, with improvements of $\mathbf{\times 5.1}$ for models with no prior coding knowledge and $\mathbf{\times 9.9}$ for models with some coding familiarity. Our work highlights the potential of this dataset to advance the field of code translation for high-performance computing. The dataset is available at https://github.com/bin123apple/Fortran-CPP-HPC-code-translation-dataset
Spectral-DP: Differentially Private Deep Learning through Spectral Perturbation and Filtering
Jul 25, 2023



Differential privacy is a widely accepted measure of privacy in the context of deep learning algorithms, and achieving it relies on a noisy training approach known as differentially private stochastic gradient descent (DP-SGD). DP-SGD requires direct noise addition to every gradient in a dense neural network, the privacy is achieved at a significant utility cost. In this work, we present Spectral-DP, a new differentially private learning approach which combines gradient perturbation in the spectral domain with spectral filtering to achieve a desired privacy guarantee with a lower noise scale and thus better utility. We develop differentially private deep learning methods based on Spectral-DP for architectures that contain both convolution and fully connected layers. In particular, for fully connected layers, we combine a block-circulant based spatial restructuring with Spectral-DP to achieve better utility. Through comprehensive experiments, we study and provide guidelines to implement Spectral-DP deep learning on benchmark datasets. In comparison with state-of-the-art DP-SGD based approaches, Spectral-DP is shown to have uniformly better utility performance in both training from scratch and transfer learning settings.