 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reduction from Reinforcement Learning to No-Regret Online Learning
Jan 01, 2020We present a reduction from reinforcement learning (RL) to no-regret online learning based on the saddle-point formulation of RL, by which "any" online algorithm with sublinear regret can generate policies with provable performance guarantees. This new perspective decouples the RL problem into two parts: regret minimization and function approximation. The first part admits a standard online-learning analysis, and the second part can be quantified independently of the learning algorithm. Therefore, the proposed reduction can be used as a tool to systematically design new RL algorithms. We demonstrate this idea by devising a simple RL algorithm based on mirror descent and the generative-model oracle. For any $\gamma$-discounted tabular RL problem, with probability at least $1-\delta$, it learns an $\epsilon$-optimal policy using at most $\tilde{O}\left(\frac{|\mathcal{S}||\mathcal{A}|\log(\frac{1}{\delta})}{(1-\gamma)^4\epsilon^2}\right)$ samples. Furthermore, this algorithm admits a direct extension to linearly parameterized function approximators for large-scale applications, with computation and sample complexities independent of $|\mathcal{S}|$,$|\mathcal{A}|$, though at the cost of potential approximation bias.
Information Theoretic Model Predictive Q-Learning
Dec 31, 2019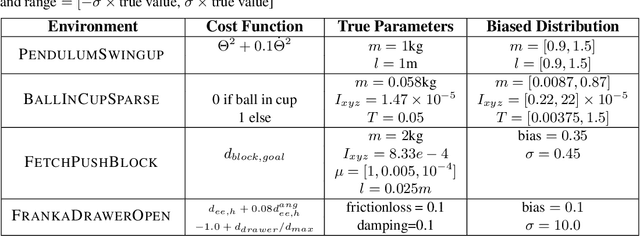
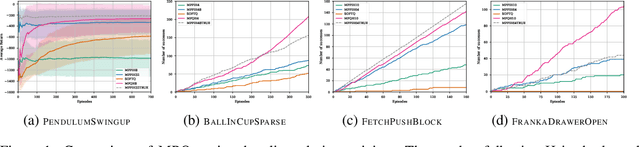
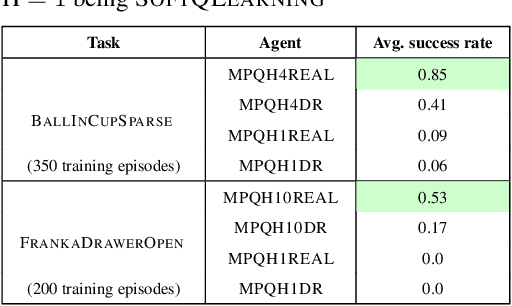
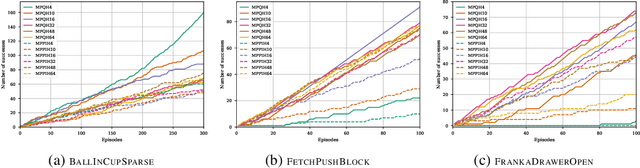
Model-free Reinforcement Learning (RL) algorithms work well in sequential decision-making problems when experience can be collected cheaply and model-based RL is effective when system dynamics can be modeled accurately. However, both of these assumptions can be violated in real world problems such as robotics, where querying the system can be prohibitively expensive and real-world dynamics can be difficult to model accurately. Although sim-to-real approaches such as domain randomization attempt to mitigate the effects of biased simulation,they can still suffer from optimization challenges such as local minima and hand-designed distributions for randomization, making it difficult to learn an accurate global value function or policy that directly transfers to the real world. In contrast to RL, Model Predictive Control (MPC) algorithms use a simulator to optimize a simple policy class online, constructing a closed-loop controller that can effectively contend with real-world dynamics. MPC performance is usually limited by factors such as model bias and the limited horizon of optimization. In this work, we present a novel theoretical connection between information theoretic MPC and entropy regularized RL and develop a Q-learning algorithm that can leverage biased models. We validate the proposed algorithm on sim-to-sim control tasks to demonstrate the improvements over optimal control and reinforcement learning from scratch. Our approach paves the way for deploying reinforcement learning algorithms on real-robots in a systematic manner.
Continuous Online Learning and New Insights to Online Imitation Learning
Dec 03, 2019Online learning is a powerful tool for analyzing iterative algorithms. However, the classic adversarial setup sometimes fails to capture certain regularity in online problems in practice. Motivated by this, we establish a new setup, called Continuous Online Learning (COL), where the gradient of online loss function changes continuously across rounds with respect to the learner's decisions. We show that COL covers and more appropriately describes many interesting applications, from general equilibrium problems (EPs) to optimization in episodic MDPs. Using this new setup, we revisit the difficulty of achieving sublinear dynamic regret. We prove that there is a fundamental equivalence between achieving sublinear dynamic regret in COL and solving certain EPs, and we present a reduction from dynamic regret to both static regret and convergence rate of the associated EP. At the end, we specialize these new insights into online imitation learning and show improved understanding of its learning stability.
Expressiveness and Learning of Hidden Quantum Markov Models
Dec 02, 2019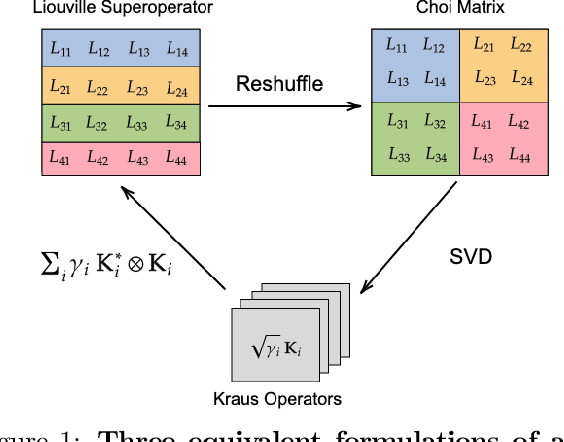
Extending classical probabilistic reasoning using the quantum mechanical view of probability has been of recent interest, particularly in the development of hidden quantum Markov models (HQMMs) to model stochastic processes. However, there has been little progress in characterizing the expressiveness of such models and learning them from data. We tackle these problems by showing that HQMMs are a special subclass of the general class of observable operator models (OOMs) that do not suffer from the \emph{negative probability problem} by design. We also provide a feasible retraction-based learning algorithm for HQMMs using constrained gradient descent on the Stiefel manifold of model parameters. We demonstrate that this approach is faster and scales to larger models than previous learning algorithms.
IRIS: Implicit Reinforcement without Interaction at Scale for Learning Control from Offline Robot Manipulation Data
Nov 13, 2019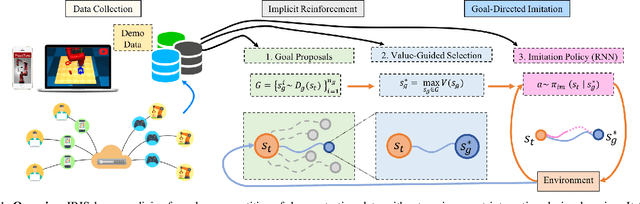
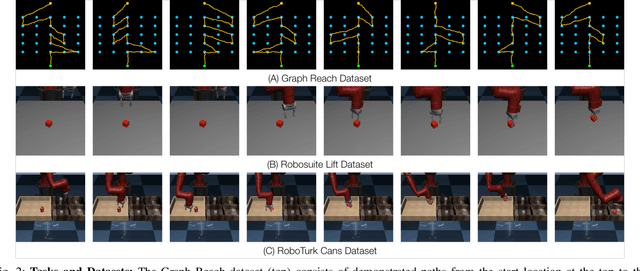
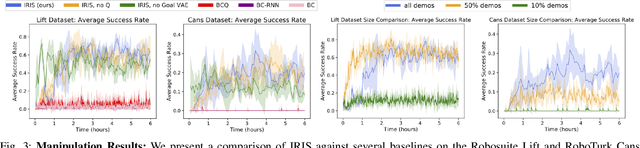
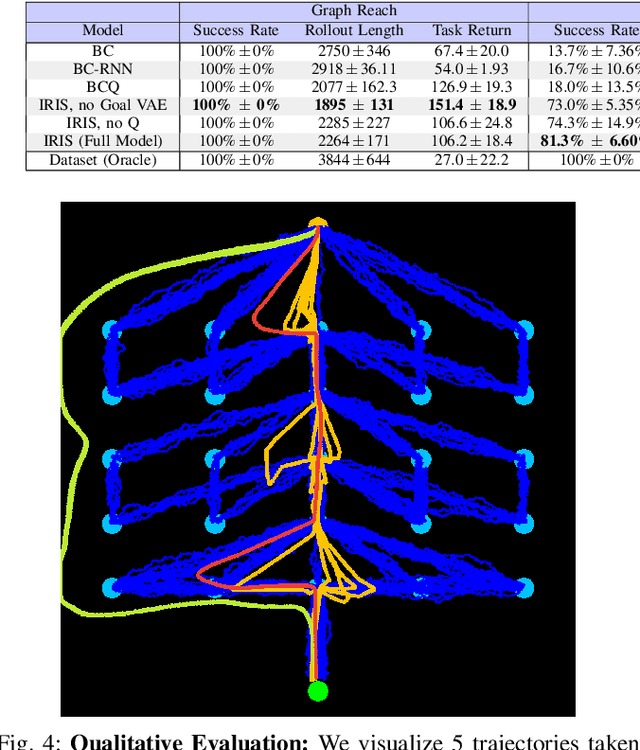
Learning from offline task demonstrations is a problem of great interest in robotics. For simple short-horizon manipulation tasks with modest variation in task instances, offline learning from a small set of demonstrations can produce controllers that successfully solve the task. However, leveraging a fixed batch of data can be problematic for larger datasets and longer-horizon tasks with greater variations. The data can exhibit substantial diversity and consist of suboptimal solution approaches. In this paper, we propose Implicit Reinforcement without Interaction at Scale (IRIS), a novel framework for learning from large-scale demonstration datasets. IRIS factorizes the control problem into a goal-conditioned low-level controller that imitates short demonstration sequences and a high-level goal selection mechanism that sets goals for the low-level and selectively combines parts of suboptimal solutions leading to more successful task completions. We evaluate IRIS across three datasets, including the RoboTurk Cans dataset collected by humans via crowdsourcing, and show that performant policies can be learned from purely offline learning. Additional results and videos at https://stanfordvl.github.io/iris/ .
Riemannian Motion Policy Fusion through Learnable Lyapunov Function Reshaping
Oct 08, 2019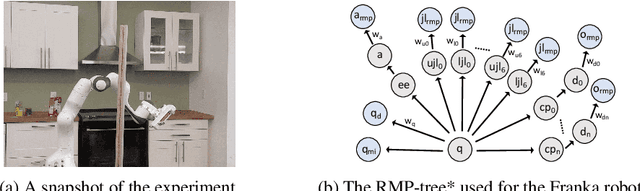
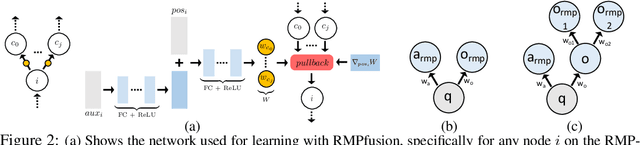
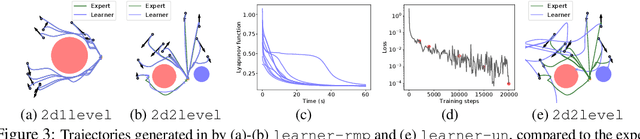
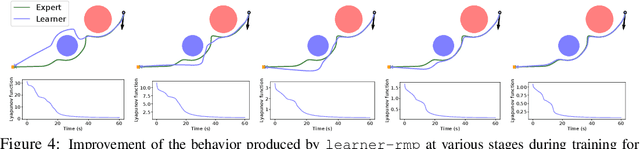
RMPflow is a recently proposed policy-fusion framework based on differential geometry. While RMPflow has demonstrated promising performance, it requires the user to provide sensible subtask policies as Riemannian motion policies (RMPs: a motion policy and an importance matrix function), which can be a difficult design problem in its own right. We propose RMPfusion, a variation of RMPflow, to address this issue. RMPfusion supplements RMPflow with weight functions that can hierarchically reshape the Lyapunov functions of the subtask RMPs according to the current configuration of the robot and environment. This extra flexibility can remedy imperfect subtask RMPs provided by the user, improving the combined policy's performance. These weight functions can be learned by back-propagation. Moreover, we prove that, under mild restrictions on the weight functions, RMPfusion always yields a globally Lyapunov-stable motion policy. This implies that we can treat RMPfusion as a structured policy class in policy optimization that is guaranteed to generate stable policies, even during the immature phase of learning. We demonstrate these properties of RMPfusion in imitation learning experiments both in simulation and on a real-world robot.
Trajectory-wise Control Variates for Variance Reduction in Policy Gradient Methods
Aug 08, 2019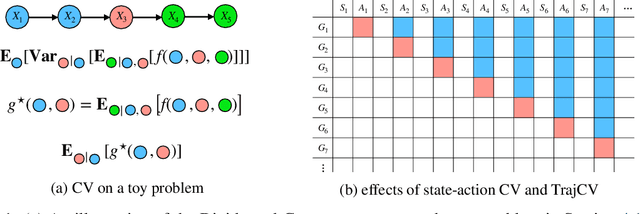
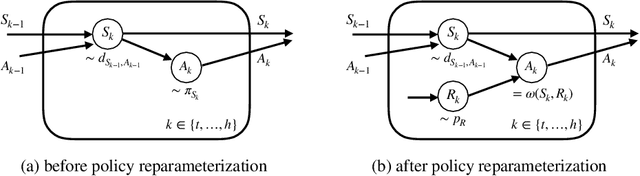
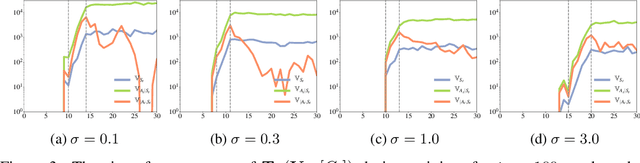
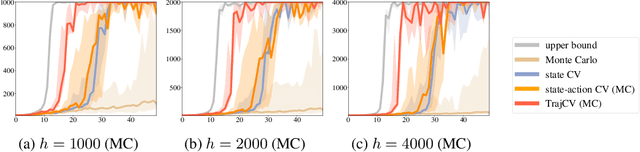
Policy gradient methods have demonstrated success in reinforcement learning tasks that have high-dimensional continuous state and action spaces. However, policy gradient methods are also notoriously sample inefficient. This can be attributed, at least in part, to the high variance in estimating the gradient of the task objective with Monte Carlo methods. Previous research has endeavored to contend with this problem by studying control variates (CVs) that can reduce the variance of estimates without introducing bias, including the early use of baselines, state dependent CVs, and the more recent state-action dependent CVs. In this work, we analyze the properties and drawbacks of previous CV techniques and, surprisingly, we find that these works have overlooked an important fact that Monte Carlo gradient estimates are generated by trajectories of states and actions. We show that ignoring the correlation across the trajectories can result in suboptimal variance reduction, and we propose a simple fix: a class of "trajectory-wise" CVs, that can further drive down the variance. We show that constructing trajectory-wise CVs can be done recursively and requires only learning state-action value functions like the previous CVs for policy gradient. We further prove that the proposed trajectory-wise CVs are optimal for variance reduction under reasonable assumptions.
Online Motion Planning Over Multiple Homotopy Classes with Gaussian Process Inference
Aug 01, 2019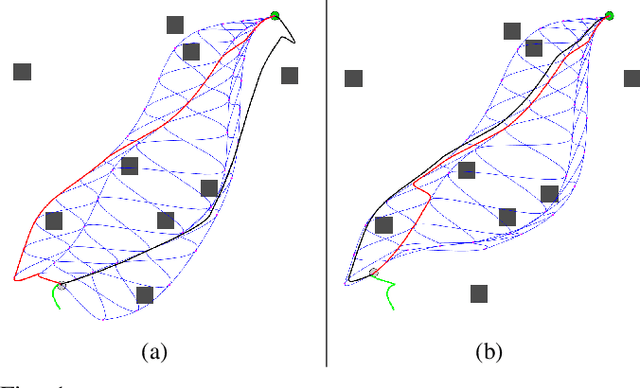
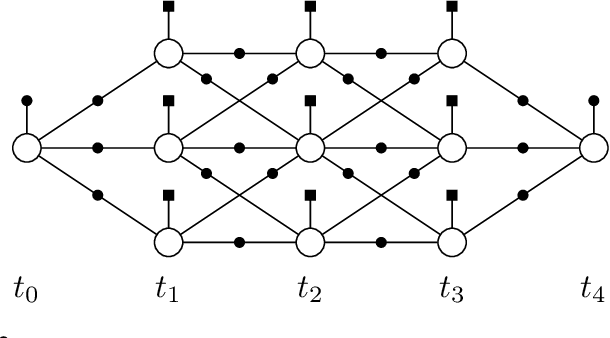
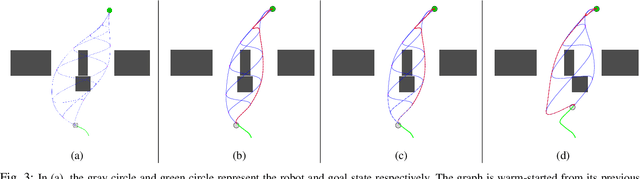
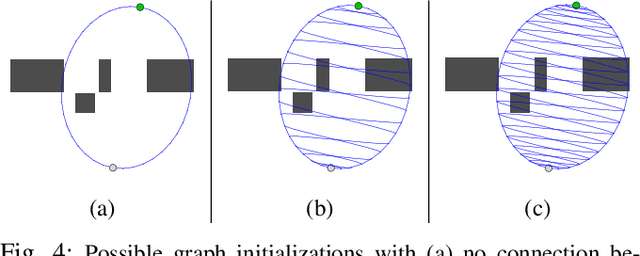
Efficient planning in dynamic and uncertain environments is a fundamental challenge in robotics. In the context of trajectory optimization, the feasibility of paths can change as the environment evolves. Therefore, it can be beneficial to reason about multiple possible paths simultaneously. We build on prior work that considers graph-based trajectories to find solutions in multiple homotopy classes concurrently. Specifically, we extend this previous work to an online setting where the unreachable (in time) part of the graph is pruned and the remaining graph is reoptimized at every time step. As the robot moves within the graph on the path that is most promising, the pruning and reoptimization allows us to retain candidate paths that may become more viable in the future as the environment changes, essentially enabling the robot to dynamically switch between numerous homotopy classes. We compare our approach against prior work without the homotopy switching capability and show improved performance across several metrics in simulation with a 2D robot in multiple dynamic environments under noisy measurements and execution.
Differentiable Gaussian Process Motion Planning
Jul 22, 2019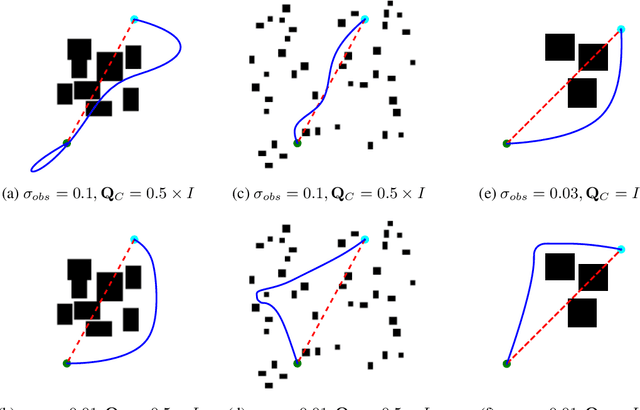
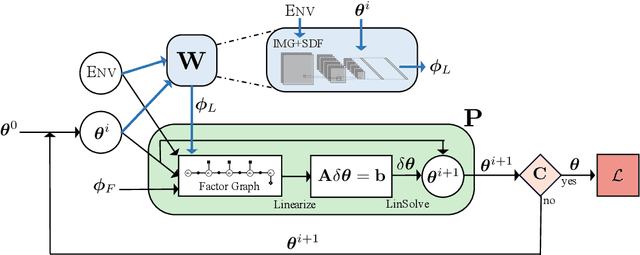
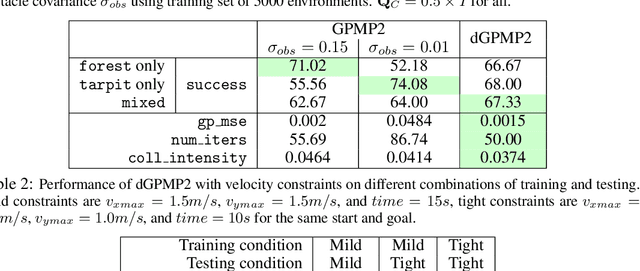
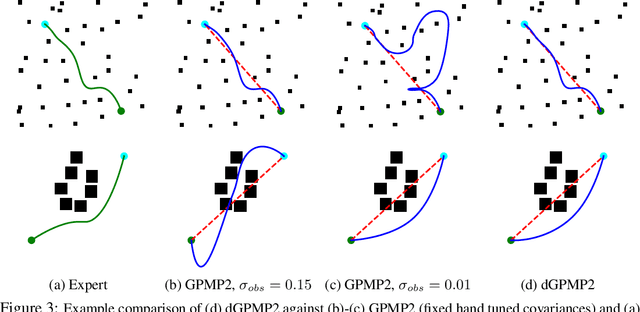
Modern trajectory optimization based approaches to motion planning are fast, easy to implement, and effective on a wide range of robotics tasks. However, trajectory optimization algorithms have parameters that are typically set in advance (and rarely discussed in detail). Setting these parameters properly can have a significant impact on the practical performance of the algorithm, sometimes making the difference between finding a feasible plan or failing at the task entirely. We propose a method for leveraging past experience to learn how to automatically adapt the parameters of Gaussian Process Motion Planning (GPMP) algorithms. Specifically, we propose a differentiable extension to the GPMP2 algorithm, so that it can be trained end-to-end from data. We perform several experiments that validate our algorithm and illustrate the benefits of our proposed learning-based approach to motion planning.
Provably Efficient Imitation Learning from Observation Alone
Jun 11, 2019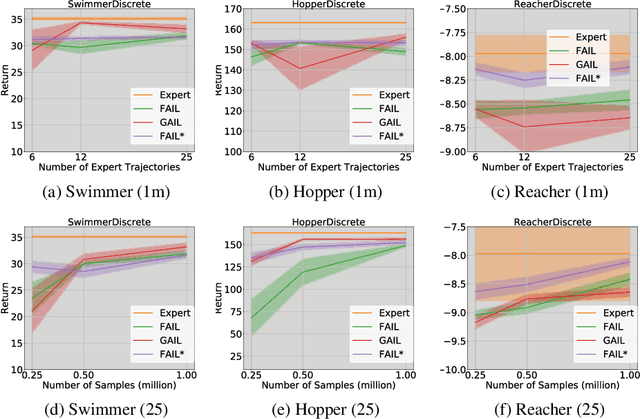
We study Imitation Learning (IL) from Observations alone (ILFO) in large-scale MDPs. While most IL algorithms rely on an expert to directly provide actions to the learner, in this setting the expert only supplies sequences of observations. We design a new model-free algorithm for ILFO, Forward Adversarial Imitation Learning (FAIL), which learns a sequence of time-dependent policies by minimizing an Integral Probability Metric between the observation distributions of the expert policy and the learner. FAIL is the first provably efficient algorithm in ILFO setting, which learns a near-optimal policy with a number of samples that is polynomial in all relevant parameters but independent of the number of unique observations. The resulting theory extends the domain of provably sample efficient learning algorithms beyond existing results, which typically only consider tabular reinforcement learning settings or settings that require access to a near-optimal reset distribution. We also investigate the extension of FAIL in a model-based setting. Finally we demonstrate the efficacy of FAIL on multiple OpenAI Gym control tasks.