 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory-wise Control Variates for Variance Reduction in Policy Gradient Methods
Paper and Code
Aug 08, 2019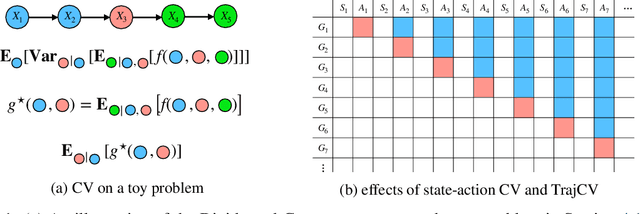
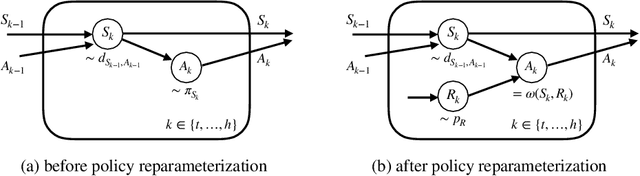
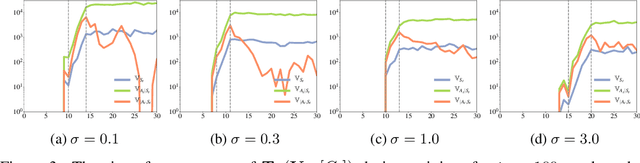
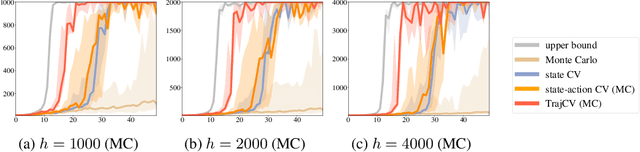
Policy gradient methods have demonstrated success in reinforcement learning tasks that have high-dimensional continuous state and action spaces. However, policy gradient methods are also notoriously sample inefficient. This can be attributed, at least in part, to the high variance in estimating the gradient of the task objective with Monte Carlo methods. Previous research has endeavored to contend with this problem by studying control variates (CVs) that can reduce the variance of estimates without introducing bias, including the early use of baselines, state dependent CVs, and the more recent state-action dependent CVs. In this work, we analyze the properties and drawbacks of previous CV techniques and, surprisingly, we find that these works have overlooked an important fact that Monte Carlo gradient estimates are generated by trajectories of states and actions. We show that ignoring the correlation across the trajectories can result in suboptimal variance reduction, and we propose a simple fix: a class of "trajectory-wise" CVs, that can further drive down the variance. We show that constructing trajectory-wise CVs can be done recursively and requires only learning state-action value functions like the previous CVs for policy gradient. We further prove that the proposed trajectory-wise CVs are optimal for variance reduction under reasonable assumptions.