 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNGPU-LM: GPU-Accelerated N-Gram Language Model for Context-Biasing in Greedy ASR Decoding
May 28, 2025Statistical n-gram language models are widely used for context-biasing tasks in Automatic Speech Recognition (ASR). However, existing implementations lack computational efficiency due to poor parallelization, making context-biasing less appealing for industrial use. This work rethinks data structures for statistical n-gram language models to enable fast and parallel operations for GPU-optimized inference. Our approach, named NGPU-LM, introduces customizable greedy decoding for all major ASR model types - including transducers, attention encoder-decoder models, and CTC - with less than 7% computational overhead. The proposed approach can eliminate more than 50% of the accuracy gap between greedy and beam search for out-of-domain scenarios while avoiding significant slowdown caused by beam search. The implementation of the proposed NGPU-LM is open-sourced.
From Output to Evaluation: Does Raw Instruction-Tuned Code LLMs Output Suffice for Fill-in-the-Middle Code Generation?
May 24, 2025Post-processing is crucial for the automatic evaluation of LLMs in fill-in-the-middle (FIM) code generation due to the frequent presence of extraneous code in raw outputs. This extraneous generation suggests a lack of awareness regarding output boundaries, requiring truncation for effective evaluation. The determination of an optimal truncation strategy, however, often proves intricate, particularly when the scope includes several programming languages. This study investigates the necessity of post-processing instruction-tuned LLM outputs. Our findings reveal that supervised fine-tuning significantly enhances FIM code generation, enabling LLMs to generate code that seamlessly integrates with the surrounding context. Evaluating our fine-tuned \texttt{Qwen2.5-Coder} (base and instruct) models on HumanEval Infilling and SAFIM benchmarks demonstrates improved performances without post-processing, especially when the \emph{middle} consist of complete lines. However, post-processing of the LLM outputs remains necessary when the \emph{middle} is a random span of code.
Word Level Timestamp Generation for Automatic Speech Recognition and Translation
May 21, 2025


We introduce a data-driven approach for enabling word-level timestamp prediction in the Canary model. Accurate timestamp information is crucial for a variety of downstream tasks such as speech content retrieval and timed subtitles. While traditional hybrid systems and end-to-end (E2E) models may employ external modules for timestamp prediction, our approach eliminates the need for separate alignment mechanisms. By leveraging the NeMo Forced Aligner (NFA) as a teacher model, we generate word-level timestamps and train the Canary model to predict timestamps directly. We introduce a new <|timestamp|> token, enabling the Canary model to predict start and end timestamps for each word. Our method demonstrates precision and recall rates between 80% and 90%, with timestamp prediction errors ranging from 20 to 120 ms across four languages, with minimal WER degradation. Additionally, we extend our system to automatic speech translation (AST) tasks, achieving timestamp prediction errors around 200 milliseconds.
Efficient and Direct Duplex Modeling for Speech-to-Speech Language Model
May 21, 2025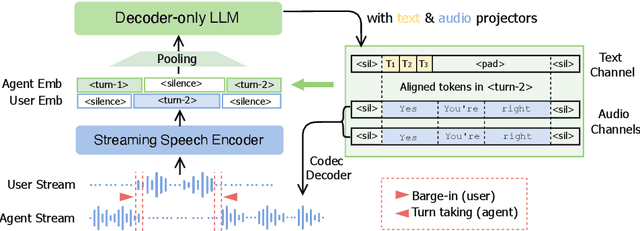
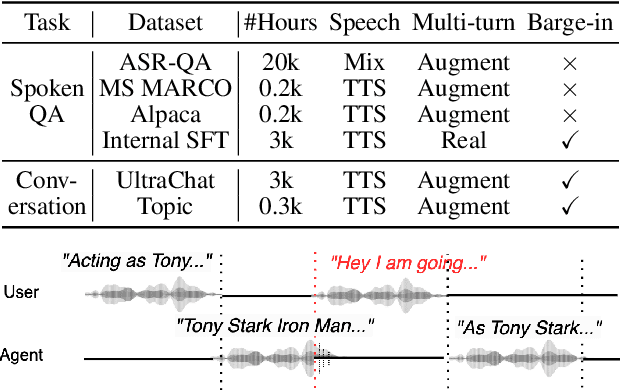
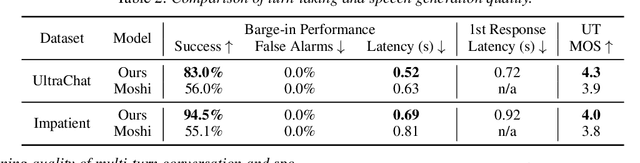
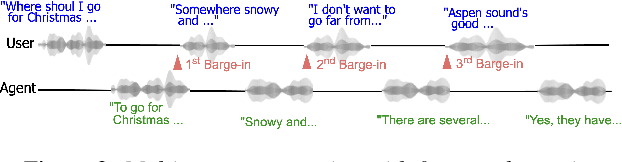
Spoken dialogue is an intuitive form of human-computer interaction, yet current speech language models often remain constrained to turn-based exchanges, lacking real-time adaptability such as user barge-in. We propose a novel duplex speech to speech (S2S) architecture featuring continuous user inputs and codec agent outputs with channel fusion that directly models simultaneous user and agent streams. Using a pretrained streaming encoder for user input enables the first duplex S2S model without requiring speech pretrain. Separate architectures for agent and user modeling facilitate codec fine-tuning for better agent voices and halve the bitrate (0.6 kbps) compared to previous works. Experimental results show that the proposed model outperforms previous duplex models in reasoning, turn-taking, and barge-in abilities. The model requires significantly less speech data, as speech pretrain is skipped, which markedly simplifies the process of building a duplex S2S model from any LLMs. Finally, it is the first openly available duplex S2S model with training and inference code to foster reproducibility.
WIND: Accelerated RNN-T Decoding with Windowed Inference for Non-blank Detection
May 19, 2025We propose Windowed Inference for Non-blank Detection (WIND), a novel strategy that significantly accelerates RNN-T inference without compromising model accuracy. During model inference, instead of processing frames sequentially, WIND processes multiple frames simultaneously within a window in parallel, allowing the model to quickly locate non-blank predictions during decoding, resulting in significant speed-ups. We implement WIND for greedy decoding, batched greedy decoding with label-looping techniques, and also propose a novel beam-search decoding method. Experiments on multiple datasets with different conditions show that our method, when operating in greedy modes, speeds up as much as 2.4X compared to the baseline sequential approach while maintaining identical Word Error Rate (WER) performance. Our beam-search algorithm achieves slightly better accuracy than alternative methods, with significantly improved speed. We will open-source our WIND implementation.
Granary: Speech Recognition and Translation Dataset in 25 European Languages
May 19, 2025Multi-task and multilingual approaches benefit large models, yet speech processing for low-resource languages remains underexplored due to data scarcity. To address this, we present Granary, a large-scale collection of speech datasets for recognition and translation across 25 European languages. This is the first open-source effort at this scale for both transcription and translation. We enhance data quality using a pseudo-labeling pipeline with segmentation, two-pass inference, hallucination filtering, and punctuation restoration. We further generate translation pairs from pseudo-labeled transcriptions using EuroLLM, followed by a data filtration pipeline. Designed for efficiency, our pipeline processes vast amount of data within hours. We assess models trained on processed data by comparing their performance on previously curated datasets for both high- and low-resource languages. Our findings show that these models achieve similar performance using approx. 50% less data. Dataset will be made available at https://hf.co/datasets/nvidia/Granary
Llama-Nemotron: Efficient Reasoning Models
May 02, 2025



We introduce the Llama-Nemotron series of models, an open family of heterogeneous reasoning models that deliver exceptional reasoning capabilities, inference efficiency, and an open license for enterprise use. The family comes in three sizes -- Nano (8B), Super (49B), and Ultra (253B) -- and performs competitively with state-of-the-art reasoning models such as DeepSeek-R1 while offering superior inference throughput and memory efficiency. In this report, we discuss the training procedure for these models, which entails using neural architecture search from Llama 3 models for accelerated inference, knowledge distillation, and continued pretraining, followed by a reasoning-focused post-training stage consisting of two main parts: supervised fine-tuning and large scale reinforcement learning. Llama-Nemotron models are the first open-source models to support a dynamic reasoning toggle, allowing users to switch between standard chat and reasoning modes during inference. To further support open research and facilitate model development, we provide the following resources: 1. We release the Llama-Nemotron reasoning models -- LN-Nano, LN-Super, and LN-Ultra -- under the commercially permissive NVIDIA Open Model License Agreement. 2. We release the complete post-training dataset: Llama-Nemotron-Post-Training-Dataset. 3. We also release our training codebases: NeMo, NeMo-Aligner, and Megatron-LM.
SWAN-GPT: An Efficient and Scalable Approach for Long-Context Language Modeling
Apr 11, 2025We present a decoder-only Transformer architecture that robustly generalizes to sequence lengths substantially longer than those seen during training. Our model, SWAN-GPT, interleaves layers without positional encodings (NoPE) and sliding-window attention layers equipped with rotary positional encodings (SWA-RoPE). Experiments demonstrate strong performance on sequence lengths significantly longer than the training length without the need for additional long-context training. This robust length extrapolation is achieved through our novel architecture, enhanced by a straightforward dynamic scaling of attention scores during inference. In addition, SWAN-GPT is more computationally efficient than standard GPT architectures, resulting in cheaper training and higher throughput. Further, we demonstrate that existing pre-trained decoder-only models can be efficiently converted to the SWAN architecture with minimal continued training, enabling longer contexts. Overall, our work presents an effective approach for scaling language models to longer contexts in a robust and efficient manner.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
OpenCodeInstruct: A Large-scale Instruction Tuning Dataset for Code LLMs
Apr 05, 2025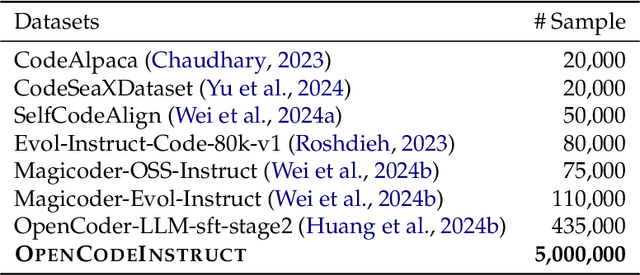
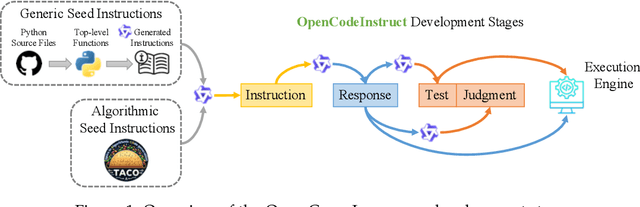
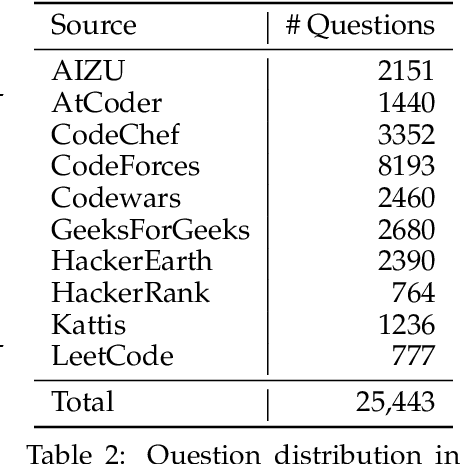
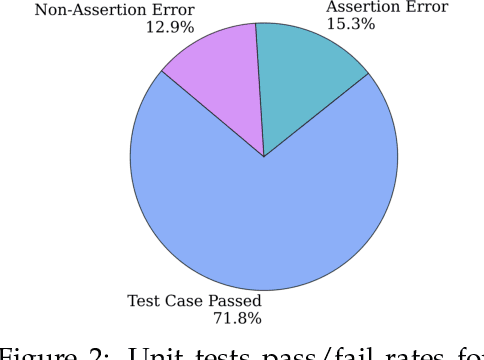
Large Language Models (LLMs) have transformed software development by enabling code generation, automated debugging, and complex reasoning. However, their continued advancement is constrained by the scarcity of high-quality, publicly available supervised fine-tuning (SFT) datasets tailored for coding tasks. To bridge this gap, we introduce OpenCodeInstruct, the largest open-access instruction tuning dataset, comprising 5 million diverse samples. Each sample includes a programming question, solution, test cases, execution feedback, and LLM-generated quality assessments. We fine-tune various base models, including LLaMA and Qwen, across multiple scales (1B+, 3B+, and 7B+) using our dataset. Comprehensive evaluations on popular benchmarks (HumanEval, MBPP, LiveCodeBench, and BigCodeBench) demonstrate substantial performance improvements achieved by SFT with OpenCodeInstruct. We also present a detailed methodology encompassing seed data curation, synthetic instruction and solution generation, and filtering.