 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Llama-Nemotron: Efficient Reasoning Models
May 02, 2025



We introduce the Llama-Nemotron series of models, an open family of heterogeneous reasoning models that deliver exceptional reasoning capabilities, inference efficiency, and an open license for enterprise use. The family comes in three sizes -- Nano (8B), Super (49B), and Ultra (253B) -- and performs competitively with state-of-the-art reasoning models such as DeepSeek-R1 while offering superior inference throughput and memory efficiency. In this report, we discuss the training procedure for these models, which entails using neural architecture search from Llama 3 models for accelerated inference, knowledge distillation, and continued pretraining, followed by a reasoning-focused post-training stage consisting of two main parts: supervised fine-tuning and large scale reinforcement learning. Llama-Nemotron models are the first open-source models to support a dynamic reasoning toggle, allowing users to switch between standard chat and reasoning modes during inference. To further support open research and facilitate model development, we provide the following resources: 1. We release the Llama-Nemotron reasoning models -- LN-Nano, LN-Super, and LN-Ultra -- under the commercially permissive NVIDIA Open Model License Agreement. 2. We release the complete post-training dataset: Llama-Nemotron-Post-Training-Dataset. 3. We also release our training codebases: NeMo, NeMo-Aligner, and Megatron-LM.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
OpenCodeInstruct: A Large-scale Instruction Tuning Dataset for Code LLMs
Apr 05, 2025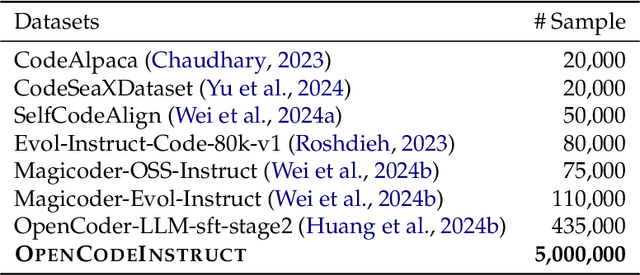
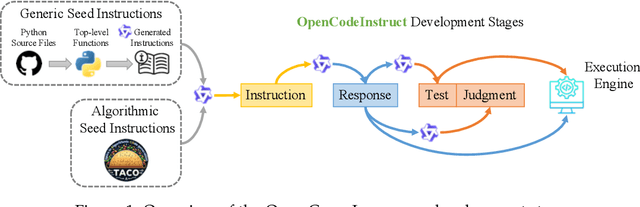
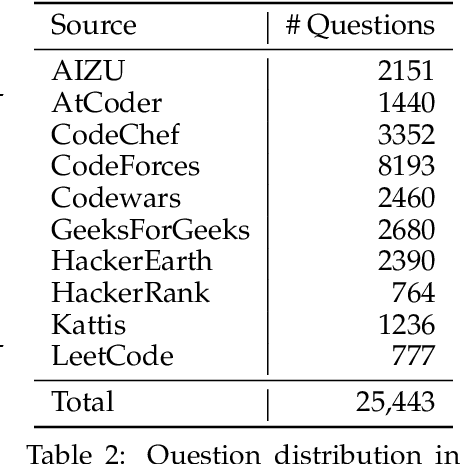
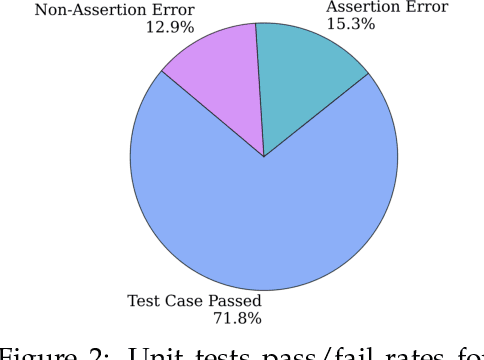
Large Language Models (LLMs) have transformed software development by enabling code generation, automated debugging, and complex reasoning. However, their continued advancement is constrained by the scarcity of high-quality, publicly available supervised fine-tuning (SFT) datasets tailored for coding tasks. To bridge this gap, we introduce OpenCodeInstruct, the largest open-access instruction tuning dataset, comprising 5 million diverse samples. Each sample includes a programming question, solution, test cases, execution feedback, and LLM-generated quality assessments. We fine-tune various base models, including LLaMA and Qwen, across multiple scales (1B+, 3B+, and 7B+) using our dataset. Comprehensive evaluations on popular benchmarks (HumanEval, MBPP, LiveCodeBench, and BigCodeBench) demonstrate substantial performance improvements achieved by SFT with OpenCodeInstruct. We also present a detailed methodology encompassing seed data curation, synthetic instruction and solution generation, and filtering.
OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
Apr 02, 2025Since the advent of reasoning-based large language models, many have found great success from distilling reasoning capabilities into student models. Such techniques have significantly bridged the gap between reasoning and standard LLMs on coding tasks. Despite this, much of the progress on distilling reasoning models remains locked behind proprietary datasets or lacks details on data curation, filtering and subsequent training. To address this, we construct a superior supervised fine-tuning (SFT) dataset that we use to achieve state-of-the-art coding capability results in models of various sizes. Our distilled models use only SFT to achieve 61.8% on LiveCodeBench and 24.6% on CodeContests, surpassing alternatives trained with reinforcement learning. We then perform analysis on the data sources used to construct our dataset, the impact of code execution filtering, and the importance of instruction/solution diversity. We observe that execution filtering negatively affected benchmark accuracy, leading us to prioritize instruction diversity over solution correctness. Finally, we also analyze the token efficiency and reasoning patterns utilized by these models. We will open-source these datasets and distilled models to the community.
Automatic Heteronym Resolution Pipeline Using RAD-TTS Aligners
Feb 28, 2023



Grapheme-to-phoneme (G2P) transduction is part of the standard text-to-speech (TTS) pipeline. However, G2P conversion is difficult for languages that contain heteronyms -- words that have one spelling but can be pronounced in multiple ways. G2P datasets with annotated heteronyms are limited in size and expensive to create, as human labeling remains the primary method for heteronym disambiguation. We propose a RAD-TTS Aligner-based pipeline to automatically disambiguate heteronyms in datasets that contain both audio with text transcripts. The best pronunciation can be chosen by generating all possible candidates for each heteronym and scoring them with an Aligner model. The resulting labels can be used to create training datasets for use in both multi-stage and end-to-end G2P systems.
ACE-VC: Adaptive and Controllable Voice Conversion using Explicitly Disentangled Self-supervised Speech Representations
Feb 16, 2023In this work, we propose a zero-shot voice conversion method using speech representations trained with self-supervised learning. First, we develop a multi-task model to decompose a speech utterance into features such as linguistic content, speaker characteristics, and speaking style. To disentangle content and speaker representations, we propose a training strategy based on Siamese networks that encourages similarity between the content representations of the original and pitch-shifted audio. Next, we develop a synthesis model with pitch and duration predictors that can effectively reconstruct the speech signal from its decomposed representation. Our framework allows controllable and speaker-adaptive synthesis to perform zero-shot any-to-any voice conversion achieving state-of-the-art results on metrics evaluating speaker similarity, intelligibility, and naturalness. Using just 10 seconds of data for a target speaker, our framework can perform voice swapping and achieves a speaker verification EER of 5.5% for seen speakers and 8.4% for unseen speakers.
BASED-XAI: Breaking Ablation Studies Down for Explainable Artificial Intelligence
Jul 12, 2022

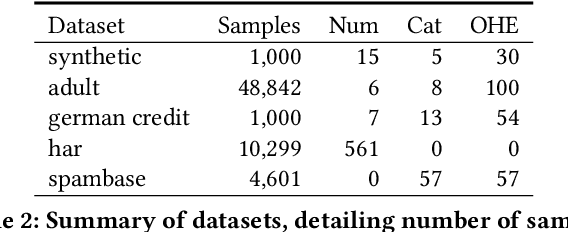
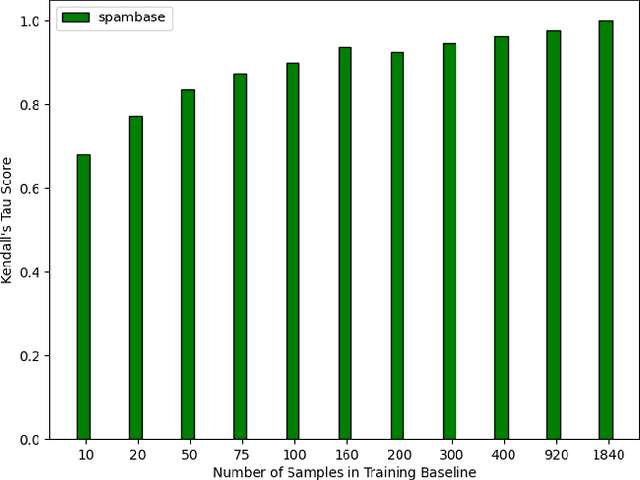
Explainable artificial intelligence (XAI) methods lack ground truth. In its place, method developers have relied on axioms to determine desirable properties for their explanations' behavior. For high stakes uses of machine learning that require explainability, it is not sufficient to rely on axioms as the implementation, or its usage, can fail to live up to the ideal. As a result, there exists active research on validating the performance of XAI methods. The need for validation is especially magnified in domains with a reliance on XAI. A procedure frequently used to assess their utility, and to some extent their fidelity, is an ablation study. By perturbing the input variables in rank order of importance, the goal is to assess the sensitivity of the model's performance. Perturbing important variables should correlate with larger decreases in measures of model capability than perturbing less important features. While the intent is clear, the actual implementation details have not been studied rigorously for tabular data. Using five datasets, three XAI methods, four baselines, and three perturbations, we aim to show 1) how varying perturbations and adding simple guardrails can help to avoid potentially flawed conclusions, 2) how treatment of categorical variables is an important consideration in both post-hoc explainability and ablation studies, and 3) how to identify useful baselines for XAI methods and viable perturbations for ablation studies.
NeMo: a toolkit for building AI applications using Neural Modules
Sep 14, 2019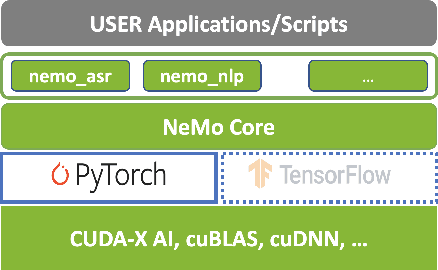

NeMo (Neural Modules) is a Python framework-agnostic toolkit for creating AI applications through re-usability, abstraction, and composition. NeMo is built around neural modules, conceptual blocks of neural networks that take typed inputs and produce typed outputs. Such modules typically represent data layers, encoders, decoders, language models, loss functions, or methods of combining activations. NeMo makes it easy to combine and re-use these building blocks while providing a level of semantic correctness checking via its neural type system. The toolkit comes with extendable collections of pre-built modules for automatic speech recognition and natural language processing. Furthermore, NeMo provides built-in support for distributed training and mixed precision on latest NVIDIA GPUs. NeMo is open-source https://github.com/NVIDIA/NeMo