 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWAN-GPT: An Efficient and Scalable Approach for Long-Context Language Modeling
Apr 11, 2025We present a decoder-only Transformer architecture that robustly generalizes to sequence lengths substantially longer than those seen during training. Our model, SWAN-GPT, interleaves layers without positional encodings (NoPE) and sliding-window attention layers equipped with rotary positional encodings (SWA-RoPE). Experiments demonstrate strong performance on sequence lengths significantly longer than the training length without the need for additional long-context training. This robust length extrapolation is achieved through our novel architecture, enhanced by a straightforward dynamic scaling of attention scores during inference. In addition, SWAN-GPT is more computationally efficient than standard GPT architectures, resulting in cheaper training and higher throughput. Further, we demonstrate that existing pre-trained decoder-only models can be efficiently converted to the SWAN architecture with minimal continued training, enabling longer contexts. Overall, our work presents an effective approach for scaling language models to longer contexts in a robust and efficient manner.
Stochastic Weight Averaging in Parallel: Large-Batch Training that Generalizes Well
Jan 07, 2020

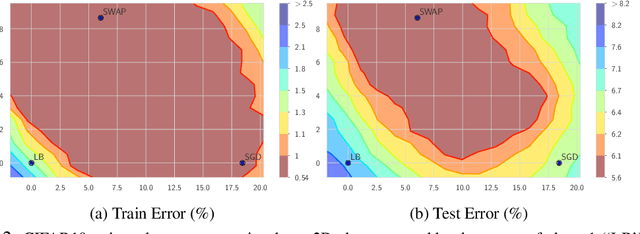

We propose Stochastic Weight Averaging in Parallel (SWAP), an algorithm to accelerate DNN training. Our algorithm uses large mini-batches to compute an approximate solution quickly and then refines it by averaging the weights of multiple models computed independently and in parallel. The resulting models generalize equally well as those trained with small mini-batches but are produced in a substantially shorter time. We demonstrate the reduction in training time and the good generalization performance of the resulting models on the computer vision datasets CIFAR10, CIFAR100, and ImageNet.
Democratizing Production-Scale Distributed Deep Learning
Nov 03, 2018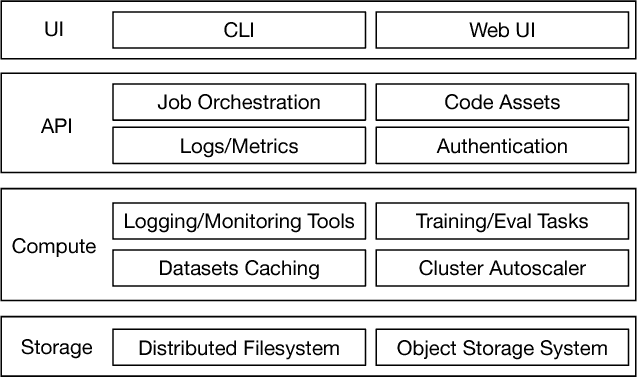
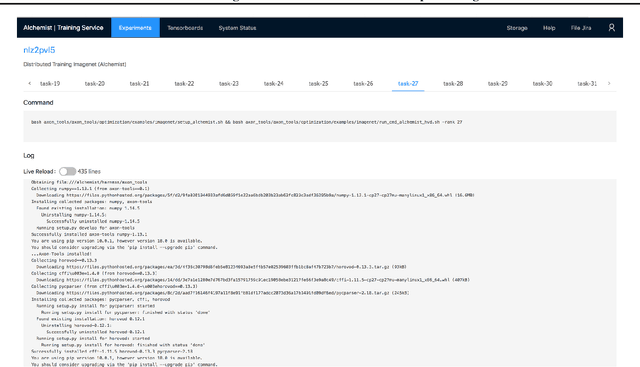
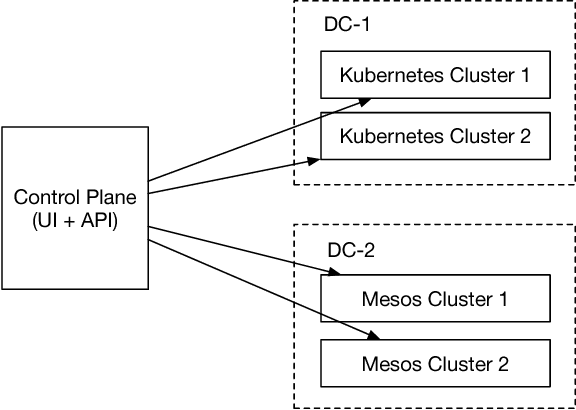

The interest and demand for training deep neural networks have been experiencing rapid growth, spanning a wide range of applications in both academia and industry. However, training them distributed and at scale remains difficult due to the complex ecosystem of tools and hardware involved. One consequence is that the responsibility of orchestrating these complex components is often left to one-off scripts and glue code customized for specific problems. To address these restrictions, we introduce \emph{Alchemist} - an internal service built at Apple from the ground up for \emph{easy}, \emph{fast}, and \emph{scalable} distributed training. We discuss its design, implementation, and examples of running different flavors of distributed training. We also present case studies of its internal adoption in the development of autonomous systems, where training times have been reduced by 10x to keep up with the ever-growing data collection.