 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Mean-Field Variational Inference via Entropic Regularization: Theory and Computation
Apr 14, 2024



Variational inference (VI) has emerged as a popular method for approximate inference for high-dimensional Bayesian models. In this paper, we propose a novel VI method that extends the naive mean field via entropic regularization, referred to as $\Xi$-variational inference ($\Xi$-VI). $\Xi$-VI has a close connection to the entropic optimal transport problem and benefits from the computationally efficient Sinkhorn algorithm. We show that $\Xi$-variational posteriors effectively recover the true posterior dependency, where the dependence is downweighted by the regularization parameter. We analyze the role of dimensionality of the parameter space on the accuracy of $\Xi$-variational approximation and how it affects computational considerations, providing a rough characterization of the statistical-computational trade-off in $\Xi$-VI. We also investigate the frequentist properties of $\Xi$-VI and establish results on consistency, asymptotic normality, high-dimensional asymptotics, and algorithmic stability. We provide sufficient criteria for achieving polynomial-time approximate inference using the method. Finally, we demonstrate the practical advantage of $\Xi$-VI over mean-field variational inference on simulated and real data.
Frequentist Guarantees of Distributed (Non)-Bayesian Inference
Nov 14, 2023Motivated by the need to analyze large, decentralized datasets, distributed Bayesian inference has become a critical research area across multiple fields, including statistics, electrical engineering, and economics. This paper establishes Frequentist properties, such as posterior consistency, asymptotic normality, and posterior contraction rates, for the distributed (non-)Bayes Inference problem among agents connected via a communication network. Our results show that, under appropriate assumptions on the communication graph, distributed Bayesian inference retains parametric efficiency while enhancing robustness in uncertainty quantification. We also explore the trade-off between statistical efficiency and communication efficiency by examining how the design and size of the communication graph impact the posterior contraction rate. Furthermore, We extend our analysis to time-varying graphs and apply our results to exponential family models, distributed logistic regression, and decentralized detection models.
Monte Carlo inference for semiparametric Bayesian regression
Jun 08, 2023Data transformations are essential for broad applicability of parametric regression models. However, for Bayesian analysis, joint inference of the transformation and model parameters typically involves restrictive parametric transformations or nonparametric representations that are computationally inefficient and cumbersome for implementation and theoretical analysis, which limits their usability in practice. This paper introduces a simple, general, and efficient strategy for joint posterior inference of an unknown transformation and all regression model parameters. The proposed approach directly targets the posterior distribution of the transformation by linking it with the marginal distributions of the independent and dependent variables, and then deploys a Bayesian nonparametric model via the Bayesian bootstrap. Crucially, this approach delivers (1) joint posterior consistency under general conditions, including multiple model misspecifications, and (2) efficient Monte Carlo (not Markov chain Monte Carlo) inference for the transformation and all parameters for important special cases. These tools apply across a variety of data domains, including real-valued, integer-valued, compactly-supported, and positive data. Simulation studies and an empirical application demonstrate the effectiveness and efficiency of this strategy for semiparametric Bayesian analysis with linear models, quantile regression, and Gaussian processes.
M-EMBER: Tackling Long-Horizon Mobile Manipulation via Factorized Domain Transfer
May 23, 2023In this paper, we propose a method to create visuomotor mobile manipulation solutions for long-horizon activities. We propose to leverage the recent advances in simulation to train visual solutions for mobile manipulation. While previous works have shown success applying this procedure to autonomous visual navigation and stationary manipulation, applying it to long-horizon visuomotor mobile manipulation is still an open challenge that demands both perceptual and compositional generalization of multiple skills. In this work, we develop Mobile-EMBER, or M-EMBER, a factorized method that decomposes a long-horizon mobile manipulation activity into a repertoire of primitive visual skills, reinforcement-learns each skill, and composes these skills to a long-horizon mobile manipulation activity. On a mobile manipulation robot, we find that M-EMBER completes a long-horizon mobile manipulation activity, cleaning_kitchen, achieving a 53% success rate. This requires successfully planning and executing five factorized, learned visual skills.
Example-Driven Model-Based Reinforcement Learning for Solving Long-Horizon Visuomotor Tasks
Sep 21, 2021
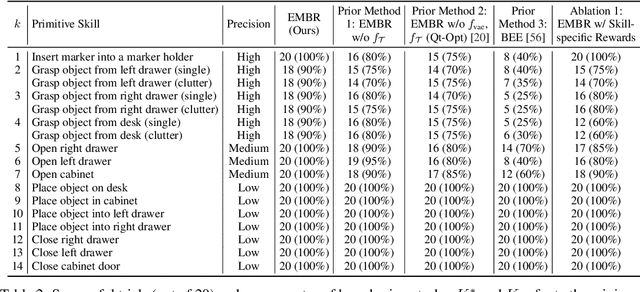
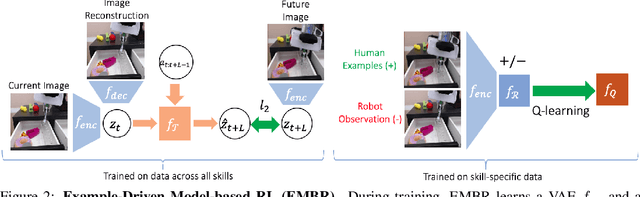

In this paper, we study the problem of learning a repertoire of low-level skills from raw images that can be sequenced to complete long-horizon visuomotor tasks. Reinforcement learning (RL) is a promising approach for acquiring short-horizon skills autonomously. However, the focus of RL algorithms has largely been on the success of those individual skills, more so than learning and grounding a large repertoire of skills that can be sequenced to complete extended multi-stage tasks. The latter demands robustness and persistence, as errors in skills can compound over time, and may require the robot to have a number of primitive skills in its repertoire, rather than just one. To this end, we introduce EMBR, a model-based RL method for learning primitive skills that are suitable for completing long-horizon visuomotor tasks. EMBR learns and plans using a learned model, critic, and success classifier, where the success classifier serves both as a reward function for RL and as a grounding mechanism to continuously detect if the robot should retry a skill when unsuccessful or under perturbations. Further, the learned model is task-agnostic and trained using data from all skills, enabling the robot to efficiently learn a number of distinct primitives. These visuomotor primitive skills and their associated pre- and post-conditions can then be directly combined with off-the-shelf symbolic planners to complete long-horizon tasks. On a Franka Emika robot arm, we find that EMBR enables the robot to complete three long-horizon visuomotor tasks at 85% success rate, such as organizing an office desk, a file cabinet, and drawers, which require sequencing up to 12 skills, involve 14 unique learned primitives, and demand generalization to novel objects.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Semiparametric count data regression for self-reported mental health
Jun 16, 2021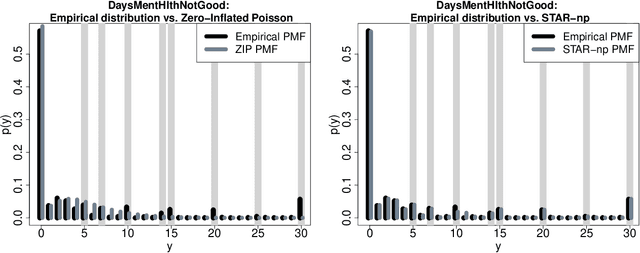

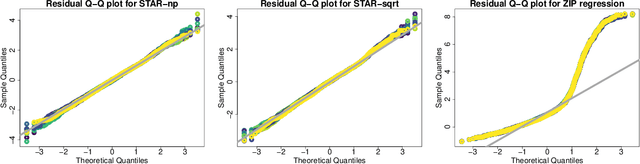
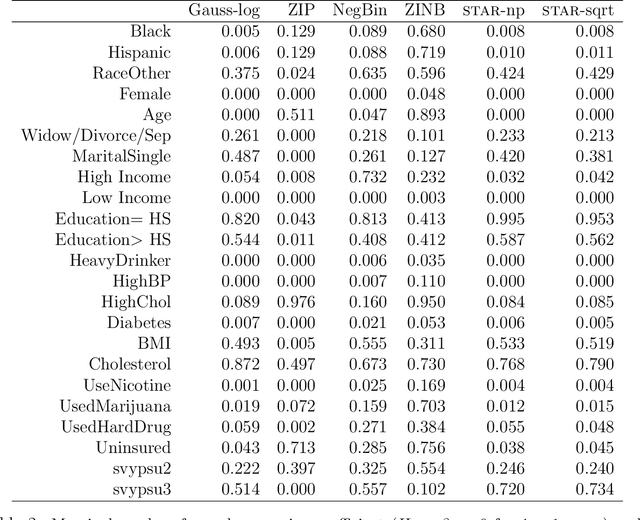
"For how many days during the past 30 days was your mental health not good?" The responses to this question measure self-reported mental health and can be linked to important covariates in the National Health and Nutrition Examination Survey (NHANES). However, these count variables present major distributional challenges: the data are overdispersed, zero-inflated, bounded by 30, and heaped in five- and seven-day increments. To meet these challenges, we design a semiparametric estimation and inference framework for count data regression. The data-generating process is defined by simultaneously transforming and rounding (STAR) a latent Gaussian regression model. The transformation is estimated nonparametrically and the rounding operator ensures the correct support for the discrete and bounded data. Maximum likelihood estimators are computed using an EM algorithm that is compatible with any continuous data model estimable by least squares. STAR regression includes asymptotic hypothesis testing and confidence intervals, variable selection via information criteria, and customized diagnostics. Simulation studies validate the utility of this framework. STAR is deployed to study the factors associated with self-reported mental health and demonstrates substantial improvements in goodness-of-fit compared to existing count data regression models.
Greedy Hierarchical Variational Autoencoders for Large-Scale Video Prediction
Mar 26, 2021
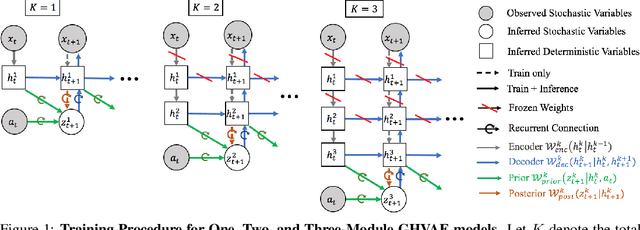

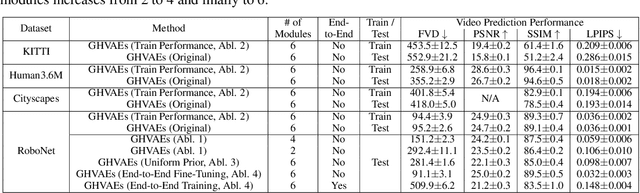
A video prediction model that generalizes to diverse scenes would enable intelligent agents such as robots to perform a variety of tasks via planning with the model. However, while existing video prediction models have produced promising results on small datasets, they suffer from severe underfitting when trained on large and diverse datasets. To address this underfitting challenge, we first observe that the ability to train larger video prediction models is often bottlenecked by the memory constraints of GPUs or TPUs. In parallel, deep hierarchical latent variable models can produce higher quality predictions by capturing the multi-level stochasticity of future observations, but end-to-end optimization of such models is notably difficult. Our key insight is that greedy and modular optimization of hierarchical autoencoders can simultaneously address both the memory constraints and the optimization challenges of large-scale video prediction. We introduce Greedy Hierarchical Variational Autoencoders (GHVAEs), a method that learns high-fidelity video predictions by greedily training each level of a hierarchical autoencoder. In comparison to state-of-the-art models, GHVAEs provide 17-55% gains in prediction performance on four video datasets, a 35-40% higher success rate on real robot tasks, and can improve performance monotonically by simply adding more modules.
SQUIRL: Robust and Efficient Learning from Video Demonstration of Long-Horizon Robotic Manipulation Tasks
Mar 10, 2020
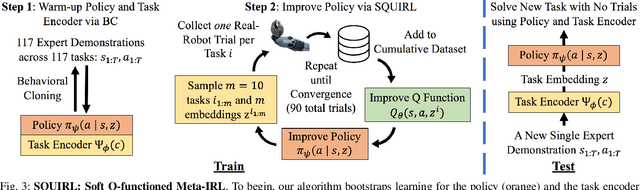


Recent advances in deep reinforcement learning (RL) have demonstrated its potential to learn complex robotic manipulation tasks. However, RL still requires the robot to collect a large amount of real-world experience. To address this problem, recent works have proposed learning from expert demonstrations (LfD), particularly via inverse reinforcement learning (IRL), given its ability to achieve robust performance with only a small number of expert demonstrations. Nevertheless, deploying IRL on real robots is still challenging due to the large number of robot experiences it requires. This paper aims to address this scalability challenge with a robust, sample-efficient, and general meta-IRL algorithm, SQUIRL, that performs a new but related long-horizon task robustly given only a single video demonstration. First, this algorithm bootstraps the learning of a task encoder and a task-conditioned policy using behavioral cloning (BC). It then collects real-robot experiences and bypasses reward learning by directly recovering a Q-function from the combined robot and expert trajectories. Next, this algorithm uses the Q-function to re-evaluate all cumulative experiences collected by the robot to improve the policy quickly. In the end, the policy performs more robustly (90%+ success) than BC on new tasks while requiring no trial-and-errors at test time. Finally, our real-robot and simulated experiments demonstrate our algorithm's generality across different state spaces, action spaces, and vision-based manipulation tasks, e.g., pick-pour-place and pick-carry-drop.
MAT: Multi-Fingered Adaptive Tactile Grasping via Deep Reinforcement Learning
Oct 10, 2019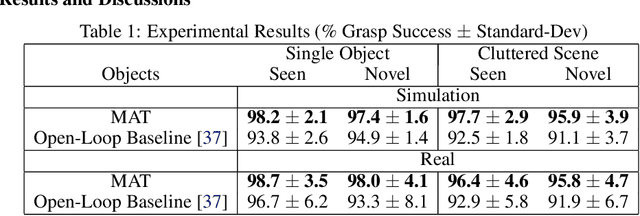

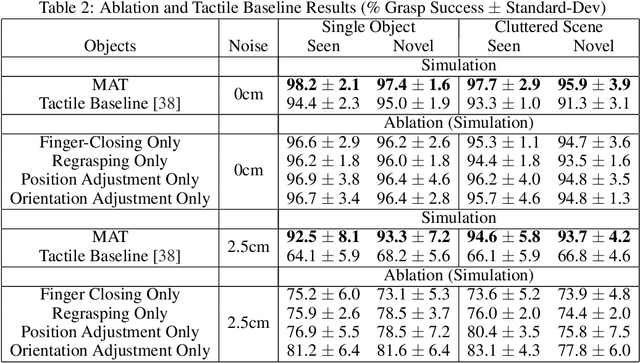

Vision-based grasping systems typically adopt an open-loop execution of a planned grasp. This policy can fail due to many reasons, including ubiquitous calibration error. Recovery from a failed grasp is further complicated by visual occlusion, as the hand is usually occluding the vision sensor as it attempts another open-loop regrasp. This work presents MAT, a tactile closed-loop method capable of realizing grasps provided by a coarse initial positioning of the hand above an object. Our algorithm is a deep reinforcement learning (RL) policy optimized through the clipped surrogate objective within a maximum entropy RL framework to balance exploitation and exploration. The method utilizes tactile and proprioceptive information to act through both fine finger motions and larger regrasp movements to execute stable grasps. A novel curriculum of action motion magnitude makes learning more tractable and helps turn common failure cases into successes. Careful selection of features that exhibit small sim-to-real gaps enables this tactile grasping policy, trained purely in simulation, to transfer well to real world environments without the need for additional learning. Experimentally, this methodology improves over a vision-only grasp success rate substantially on a multi-fingered robot hand. When this methodology is used to realize grasps from coarse initial positions provided by a vision-only planner, the system is made dramatically more robust to calibration errors in the camera-robot transform.