 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultistep Belief Space Dynamics Learning For Risk-Aware Control
May 12, 2026As autonomous vehicles move from a simplified research setting to practical use, there exists a large gap between the dynamic behavior of a human driving and an autonomous system. Risk-aware behavior needs to naturally develop in order to scale to the demands of the real world. A major issue for risk-aware planning and control has been predicting how dynamical uncertainty evolves through time and optimizing plans that account for this without being overly conservative. Here, we present a learning framework to predict distributional dynamics that can be optimized in real time for Model Predictive Control (MPC). We explore the importance of structure when learning distributional dynamics for use in MPC. A rigorous ablation study is conducted on a large dataset of real world off-road driving that shows the impact of deviations from our proposed structure. Furthermore, we deploy our learned model and planning stack on a full sized vehicle in challenging off-road conditions. Our planning architecture is able to naturally regulate the speed of the vehicle based on the environment and consistently demonstrates intelligent behavior over miles of diverse terrain.
Meta-Learning Online Dynamics Model Adaptation in Off-Road Autonomous Driving
Apr 23, 2025



High-speed off-road autonomous driving presents unique challenges due to complex, evolving terrain characteristics and the difficulty of accurately modeling terrain-vehicle interactions. While dynamics models used in model-based control can be learned from real-world data, they often struggle to generalize to unseen terrain, making real-time adaptation essential. We propose a novel framework that combines a Kalman filter-based online adaptation scheme with meta-learned parameters to address these challenges. Offline meta-learning optimizes the basis functions along which adaptation occurs, as well as the adaptation parameters, while online adaptation dynamically adjusts the onboard dynamics model in real time for model-based control. We validate our approach through extensive experiments, including real-world testing on a full-scale autonomous off-road vehicle, demonstrating that our method outperforms baseline approaches in prediction accuracy, performance, and safety metrics, particularly in safety-critical scenarios. Our results underscore the effectiveness of meta-learned dynamics model adaptation, advancing the development of reliable autonomous systems capable of navigating diverse and unseen environments. Video is available at: https://youtu.be/cCKHHrDRQEA
MPPI-Generic: A CUDA Library for Stochastic Optimization
Sep 11, 2024



This paper introduces a new C++/CUDA library for GPU-accelerated stochastic optimization called MPPI-Generic. It provides implementations of Model Predictive Path Integral control, Tube-Model Predictive Path Integral Control, and Robust Model Predictive Path Integral Control, and allows for these algorithms to be used across many pre-existing dynamics models and cost functions. Furthermore, researchers can create their own dynamics models or cost functions following our API definitions without needing to change the actual Model Predictive Path Integral Control code. Finally, we compare computational performance to other popular implementations of Model Predictive Path Integral Control over a variety of GPUs to show the real-time capabilities our library can allow for. Library code can be found at: https://acdslab.github.io/mppi-generic-website/ .
Low Frequency Sampling in Model Predictive Path Integral Control
Apr 03, 2024



Sampling-based model-predictive controllers have become a powerful optimization tool for planning and control problems in various challenging environments. In this paper, we show how the default choice of uncorrelated Gaussian distributions can be improved upon with the use of a colored noise distribution. Our choice of distribution allows for the emphasis on low frequency control signals, which can result in smoother and more exploratory samples. We use this frequency-based sampling distribution with Model Predictive Path Integral (MPPI) in both hardware and simulation experiments to show better or equal performance on systems with various speeds of input response.
A Multi-step Dynamics Modeling Framework For Autonomous Driving In Multiple Environments
May 03, 2023Modeling dynamics is often the first step to making a vehicle autonomous. While on-road autonomous vehicles have been extensively studied, off-road vehicles pose many challenging modeling problems. An off-road vehicle encounters highly complex and difficult-to-model terrain/vehicle interactions, as well as having complex vehicle dynamics of its own. These complexities can create challenges for effective high-speed control and planning. In this paper, we introduce a framework for multistep dynamics prediction that explicitly handles the accumulation of modeling error and remains scalable for sampling-based controllers. Our method uses a specially-initialized Long Short-Term Memory (LSTM) over a limited time horizon as the learned component in a hybrid model to predict the dynamics of a 4-person seating all-terrain vehicle (Polaris S4 1000 RZR) in two distinct environments. By only having the LSTM predict over a fixed time horizon, we negate the need for long term stability that is often a challenge when training recurrent neural networks. Our framework is flexible as it only requires odometry information for labels. Through extensive experimentation, we show that our method is able to predict millions of possible trajectories in real-time, with a time horizon of five seconds in challenging off road driving scenarios.
Variational Inference MPC using Tsallis Divergence
Apr 01, 2021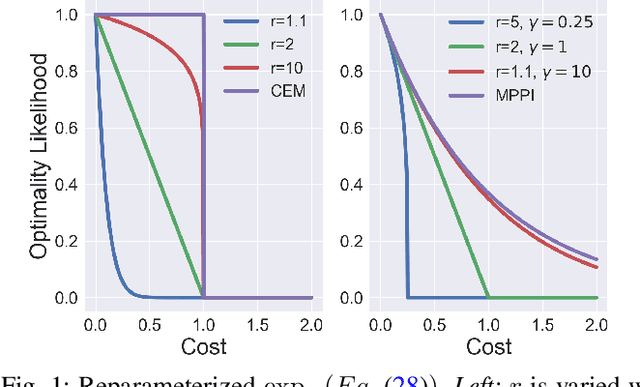
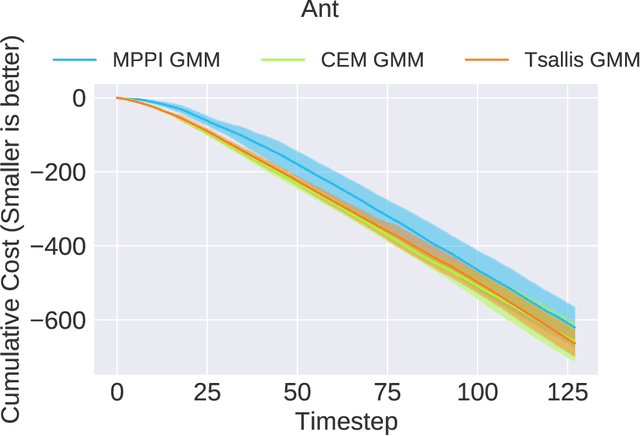
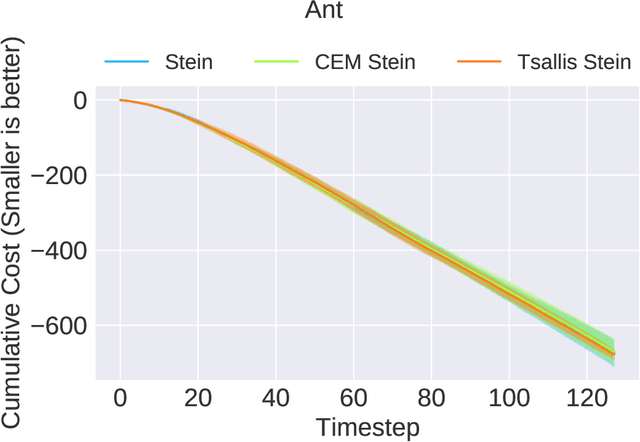
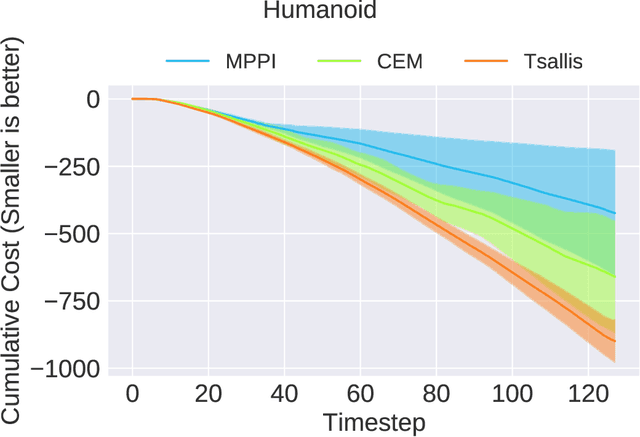
In this paper, we provide a generalized framework for Variational Inference-Stochastic Optimal Control by using thenon-extensive Tsallis divergence. By incorporating the deformed exponential function into the optimality likelihood function, a novel Tsallis Variational Inference-Model Predictive Control algorithm is derived, which includes prior works such as Variational Inference-Model Predictive Control, Model Predictive PathIntegral Control, Cross Entropy Method, and Stein VariationalInference Model Predictive Control as special cases. The proposed algorithm allows for effective control of the cost/reward transform and is characterized by superior performance in terms of mean and variance reduction of the associated cost. The aforementioned features are supported by a theoretical and numerical analysis on the level of risk sensitivity of the proposed algorithm as well as simulation experiments on 5 different robotic systems with 3 different policy parameterizations.
Approximate Inverse Reinforcement Learning from Vision-based Imitation Learning
Apr 17, 2020
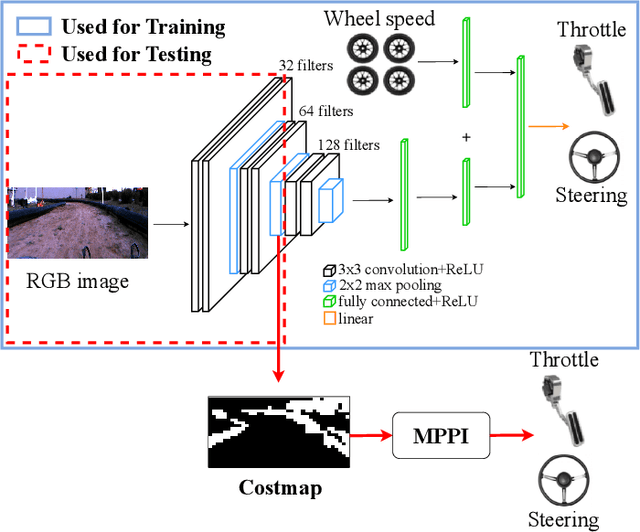


In this work, we present a method for obtaining an implicit objective function for vision-based navigation. The proposed methodology relies on Imitation Learning, Model Predictive Control (MPC), and Deep Learning. We use Imitation Learning as a means to do Inverse Reinforcement Learning in order to create an approximate costmap generator for a visual navigation challenge. The resulting costmap is used in conjunction with a Model Predictive Controller for real-time control and outperforms other state-of-the-art costmap generators combined with MPC in novel environments. The proposed process allows for simple training and robustness to out-of-sample data. We apply our method to the task of vision-based autonomous driving in multiple real and simulated environments using the same weights for the costmap predictor in all environments.
Online Center of Mass Estimation for a Humanoid Wheeled Inverted Pendulum Robot
Oct 07, 2018
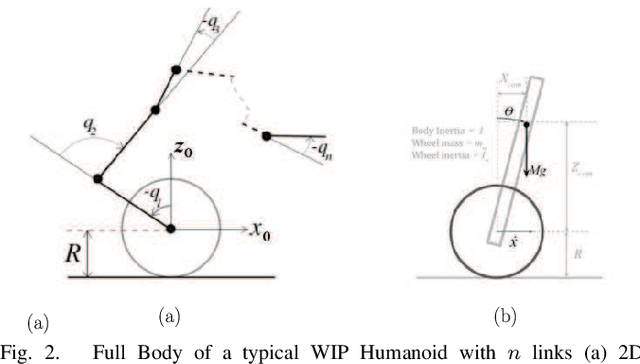
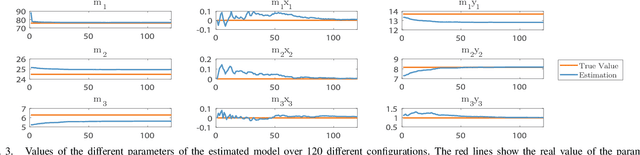
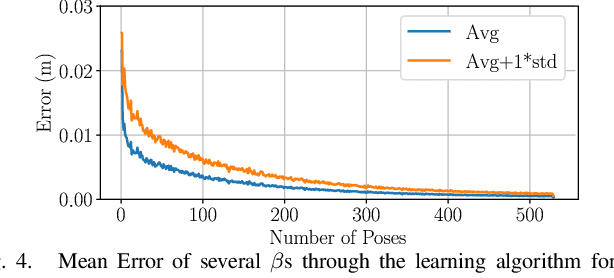
We present a novel application of robust control and online learning for the balancing of a n Degree of Freedom (DoF), Wheeled Inverted Pendulum (WIP) humanoid robot. Our technique condenses the inaccuracies of a mass model into a Center of Mass (CoM) error, balances despite this error, and uses online learning to update the mass model for a better CoM estimate. Using a simulated model of our robot, we meta-learn a set of excitory joint poses that makes our gradient descent algorithm quickly converge to an accurate (CoM) estimate. This simulated pipeline executes in a fully online fashion, using active disturbance rejection to address the mass errors that result from a steadily evolving mass model. Experiments were performed on a 19 DoF WIP, in which we manually acquired the data for the learned set of poses and show that the mass model produced by a gradient descent produces a CoM estimate that improves overall control and efficiency. This work contributes to a greater corpus of whole body control on the Golem Krang humanoid robot.