 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportance of Synthesizing High-quality Data for Text-to-SQL Parsing
Dec 17, 2022



Recently, there has been increasing interest in synthesizing data to improve downstream text-to-SQL tasks. In this paper, we first examined the existing synthesized datasets and discovered that state-of-the-art text-to-SQL algorithms did not further improve on popular benchmarks when trained with augmented synthetic data. We observed two shortcomings: illogical synthetic SQL queries from independent column sampling and arbitrary table joins. To address these issues, we propose a novel synthesis framework that incorporates key relationships from schema, imposes strong typing, and conducts schema-distance-weighted column sampling. We also adopt an intermediate representation (IR) for the SQL-to-text task to further improve the quality of the generated natural language questions. When existing powerful semantic parsers are pre-finetuned on our high-quality synthesized data, our experiments show that these models have significant accuracy boosts on popular benchmarks, including new state-of-the-art performance on Spider.
Multi-lingual Evaluation of Code Generation Models
Oct 26, 2022



We present MBXP, an execution-based code completion benchmark in 10+ programming languages. This collection of datasets is generated by our conversion framework that translates prompts and test cases from the original MBPP dataset to the corresponding data in a target language. Based on this benchmark, we are able to evaluate code generation models in a multi-lingual fashion, and in particular discover generalization ability of language models on out-of-domain languages, advantages of large multi-lingual models over mono-lingual, benefits of few-shot prompting, and zero-shot translation abilities. In addition, we use our code generation model to perform large-scale bootstrapping to obtain synthetic canonical solutions in several languages. These solutions can be used for other code-related evaluations such as insertion-based, summarization, or code translation tasks where we demonstrate results and release as part of our benchmark.
ContraGen: Effective Contrastive Learning For Causal Language Model
Oct 03, 2022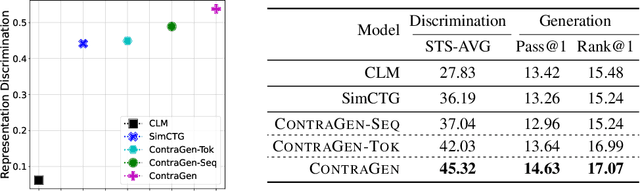
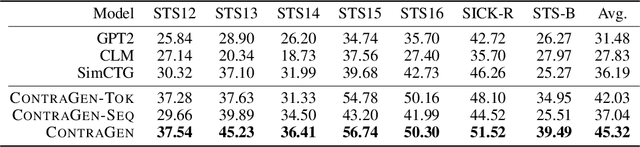
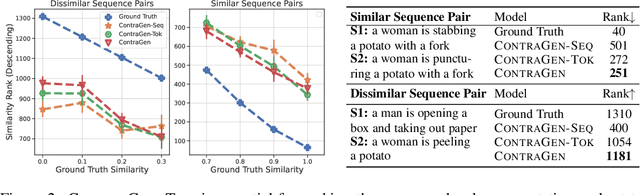
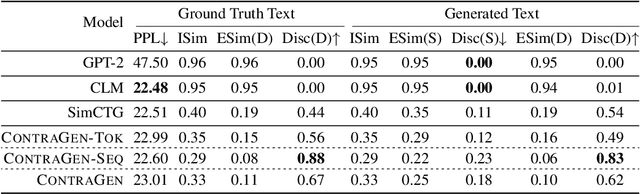
Despite exciting progress in large-scale language generation, the expressiveness of its representations is severely limited by the \textit{anisotropy} issue where the hidden representations are distributed into a narrow cone in the vector space. To address this issue, we present ContraGen, a novel contrastive learning framework to improve the representation with better uniformity and discrimination. We assess ContraGen on a wide range of downstream tasks in natural and programming languages. We show that ContraGen can effectively enhance both uniformity and discrimination of the representations and lead to the desired improvement on various language understanding tasks where discriminative representations are crucial for attaining good performance. Specifically, we attain $44\%$ relative improvement on the Semantic Textual Similarity tasks and $34\%$ on Code-to-Code Search tasks. Furthermore, by improving the expressiveness of the representations, ContraGen also boosts the source code generation capability with $9\%$ relative improvement on execution accuracy on the HumanEval benchmark.
DecAF: Joint Decoding of Answers and Logical Forms for Question Answering over Knowledge Bases
Sep 30, 2022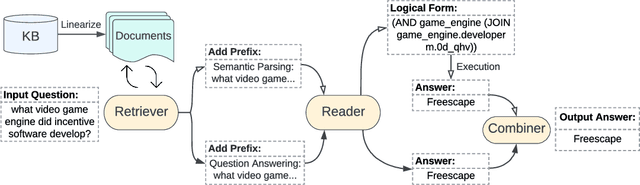
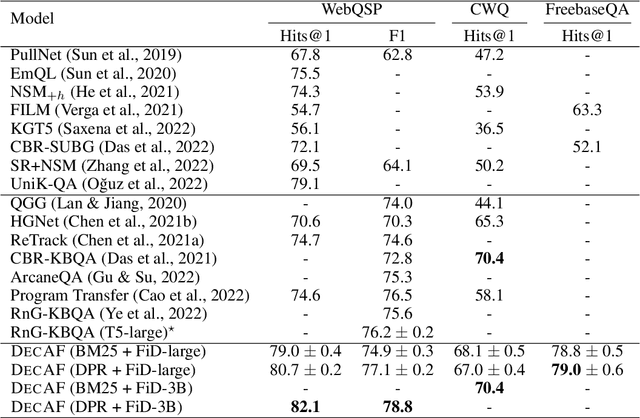
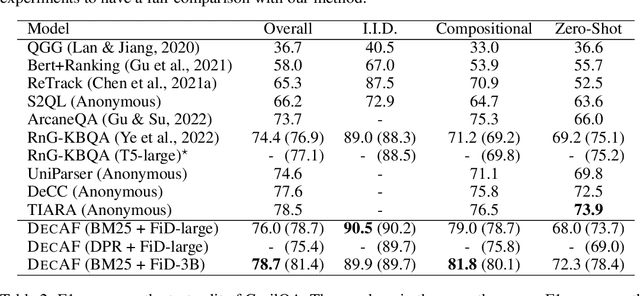
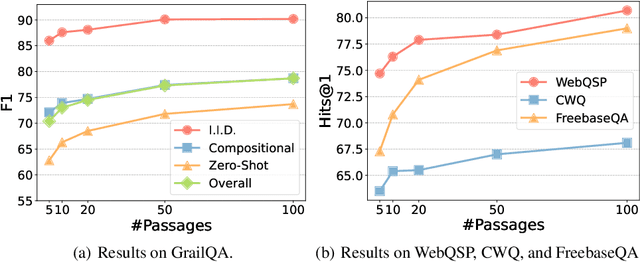
Question answering over knowledge bases (KBs) aims to answer natural language questions with factual information such as entities and relations in KBs. Previous methods either generate logical forms that can be executed over KBs to obtain final answers or predict answers directly. Empirical results show that the former often produces more accurate answers, but it suffers from non-execution issues due to potential syntactic and semantic errors in the generated logical forms. In this work, we propose a novel framework DecAF that jointly generates both logical forms and direct answers, and then combines the merits of them to get the final answers. Moreover, different from most of the previous methods, DecAF is based on simple free-text retrieval without relying on any entity linking tools -- this simplification eases its adaptation to different datasets. DecAF achieves new state-of-the-art accuracy on WebQSP, FreebaseQA, and GrailQA benchmarks, while getting competitive results on the ComplexWebQuestions benchmark.
Improving Text-to-SQL Semantic Parsing with Fine-grained Query Understanding
Sep 28, 2022

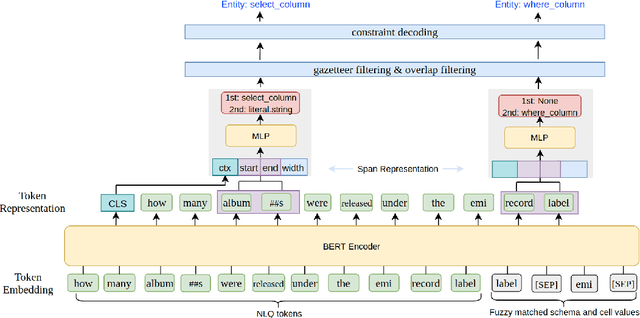
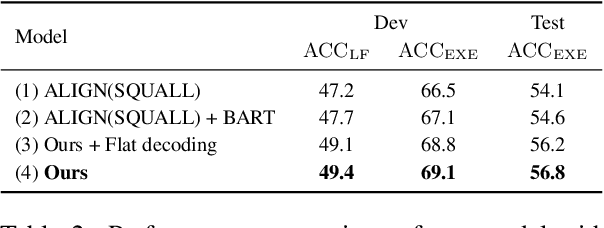
Most recent research on Text-to-SQL semantic parsing relies on either parser itself or simple heuristic based approach to understand natural language query (NLQ). When synthesizing a SQL query, there is no explicit semantic information of NLQ available to the parser which leads to undesirable generalization performance. In addition, without lexical-level fine-grained query understanding, linking between query and database can only rely on fuzzy string match which leads to suboptimal performance in real applications. In view of this, in this paper we present a general-purpose, modular neural semantic parsing framework that is based on token-level fine-grained query understanding. Our framework consists of three modules: named entity recognizer (NER), neural entity linker (NEL) and neural semantic parser (NSP). By jointly modeling query and database, NER model analyzes user intents and identifies entities in the query. NEL model links typed entities to schema and cell values in database. Parser model leverages available semantic information and linking results and synthesizes tree-structured SQL queries based on dynamically generated grammar. Experiments on SQUALL, a newly released semantic parsing dataset, show that we can achieve 56.8% execution accuracy on WikiTableQuestions (WTQ) test set, which outperforms the state-of-the-art model by 2.7%.
REKnow: Enhanced Knowledge for Joint Entity and Relation Extraction
Jun 20, 2022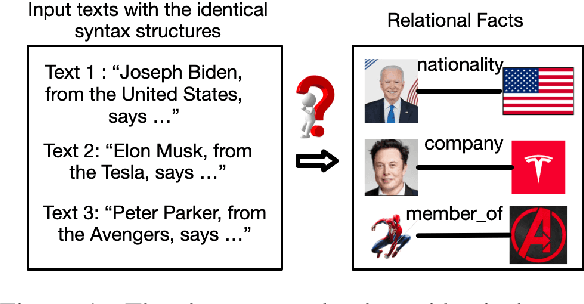
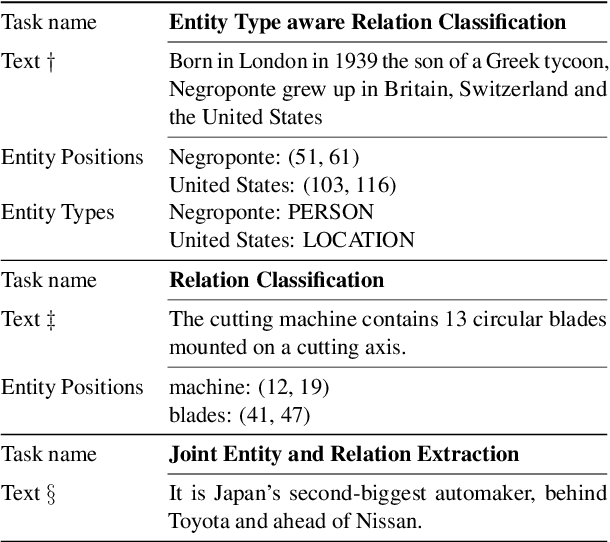
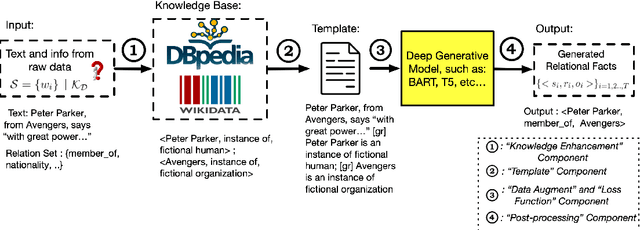
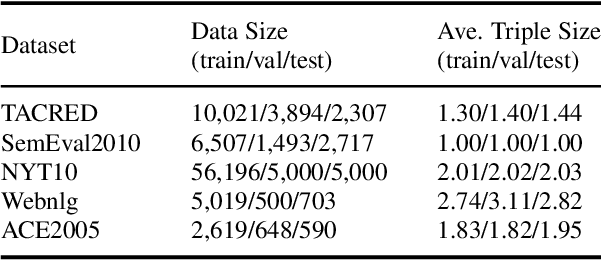
Relation extraction is an important but challenging task that aims to extract all hidden relational facts from the text. With the development of deep language models, relation extraction methods have achieved good performance on various benchmarks. However, we observe two shortcomings of previous methods: first, there is no unified framework that works well under various relation extraction settings; second, effectively utilizing external knowledge as background information is absent. In this work, we propose a knowledge-enhanced generative model to mitigate these two issues. Our generative model is a unified framework to sequentially generate relational triplets under various relation extraction settings and explicitly utilizes relevant knowledge from Knowledge Graph (KG) to resolve ambiguities. Our model achieves superior performance on multiple benchmarks and settings, including WebNLG, NYT10, and TACRED.
Learning Dialogue Representations from Consecutive Utterances
May 26, 2022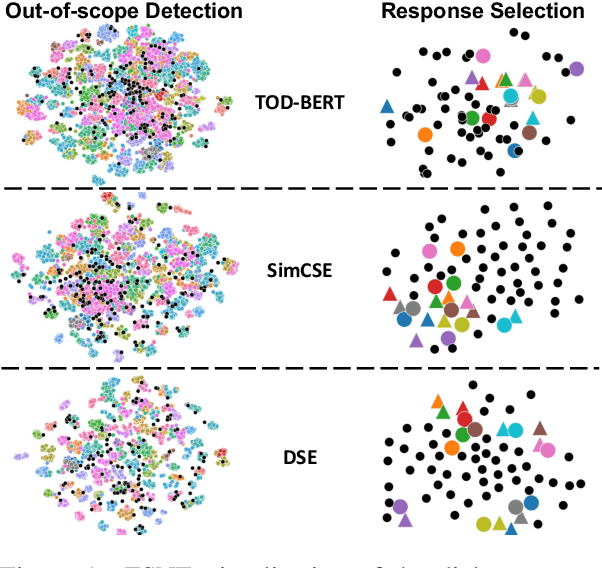

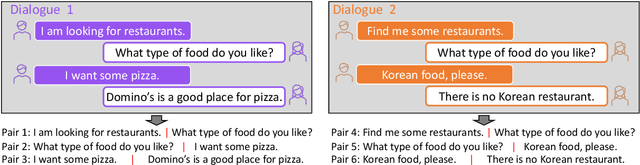
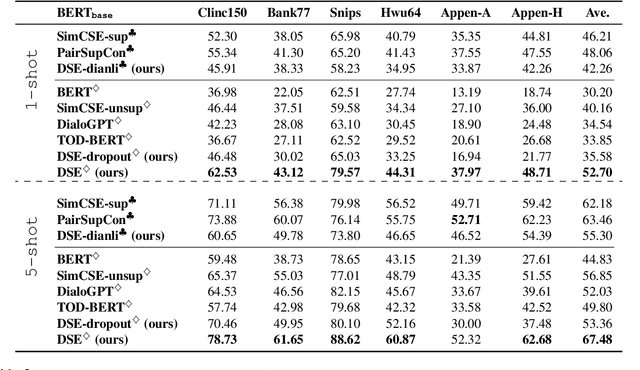
Learning high-quality dialogue representations is essential for solving a variety of dialogue-oriented tasks, especially considering that dialogue systems often suffer from data scarcity. In this paper, we introduce Dialogue Sentence Embedding (DSE), a self-supervised contrastive learning method that learns effective dialogue representations suitable for a wide range of dialogue tasks. DSE learns from dialogues by taking consecutive utterances of the same dialogue as positive pairs for contrastive learning. Despite its simplicity, DSE achieves significantly better representation capability than other dialogue representation and universal sentence representation models. We evaluate DSE on five downstream dialogue tasks that examine dialogue representation at different semantic granularities. Experiments in few-shot and zero-shot settings show that DSE outperforms baselines by a large margin. For example, it achieves 13 average performance improvement over the strongest unsupervised baseline in 1-shot intent classification on 6 datasets. We also provide analyses on the benefits and limitations of our model.
DQ-BART: Efficient Sequence-to-Sequence Model via Joint Distillation and Quantization
Mar 21, 2022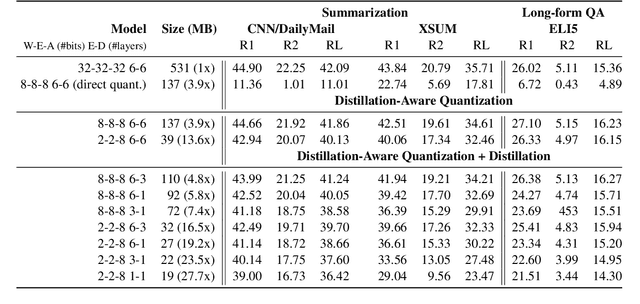
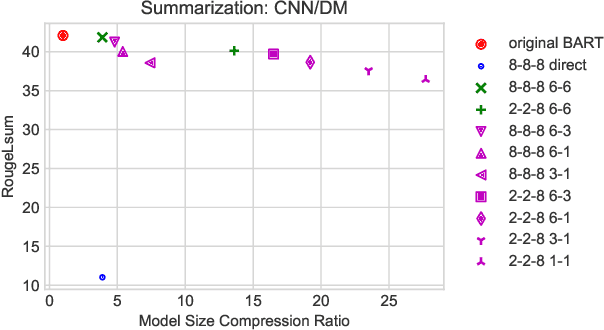
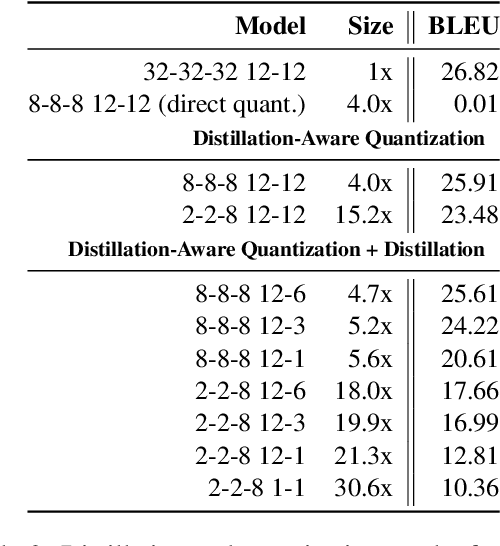
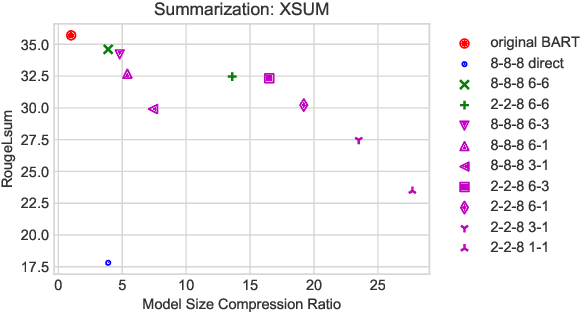
Large-scale pre-trained sequence-to-sequence models like BART and T5 achieve state-of-the-art performance on many generative NLP tasks. However, such models pose a great challenge in resource-constrained scenarios owing to their large memory requirements and high latency. To alleviate this issue, we propose to jointly distill and quantize the model, where knowledge is transferred from the full-precision teacher model to the quantized and distilled low-precision student model. Empirical analyses show that, despite the challenging nature of generative tasks, we were able to achieve a 16.5x model footprint compression ratio with little performance drop relative to the full-precision counterparts on multiple summarization and QA datasets. We further pushed the limit of compression ratio to 27.7x and presented the performance-efficiency trade-off for generative tasks using pre-trained models. To the best of our knowledge, this is the first work aiming to effectively distill and quantize sequence-to-sequence pre-trained models for language generation tasks.
Contrastive Document Representation Learning with Graph Attention Networks
Oct 20, 2021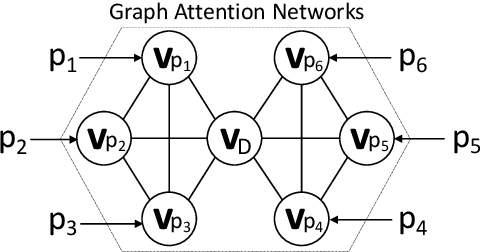
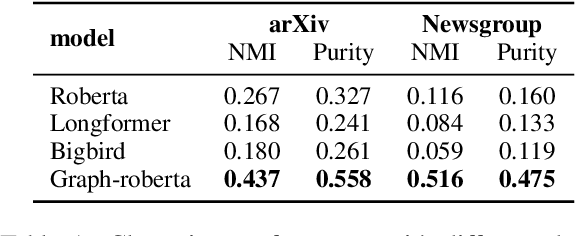
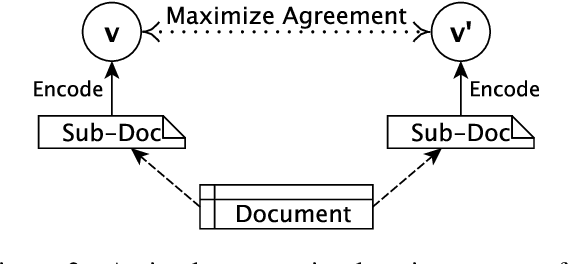
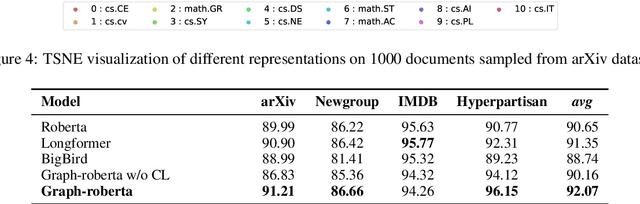
Recent progress in pretrained Transformer-based language models has shown great success in learning contextual representation of text. However, due to the quadratic self-attention complexity, most of the pretrained Transformers models can only handle relatively short text. It is still a challenge when it comes to modeling very long documents. In this work, we propose to use a graph attention network on top of the available pretrained Transformers model to learn document embeddings. This graph attention network allows us to leverage the high-level semantic structure of the document. In addition, based on our graph document model, we design a simple contrastive learning strategy to pretrain our models on a large amount of unlabeled corpus. Empirically, we demonstrate the effectiveness of our approaches in document classification and document retrieval tasks.
Attention-guided Generative Models for Extractive Question Answering
Oct 12, 2021
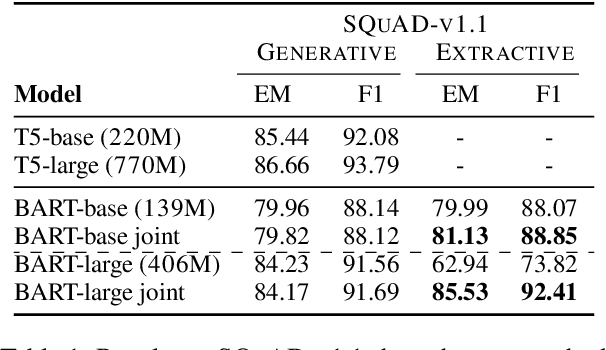
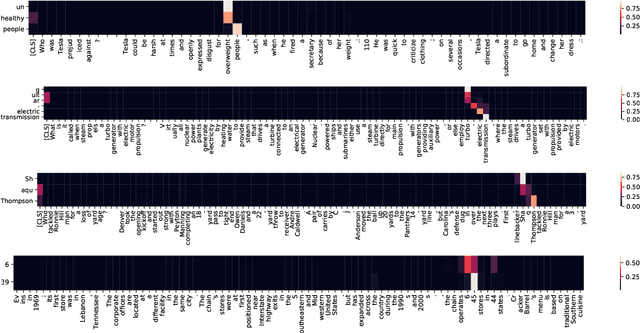
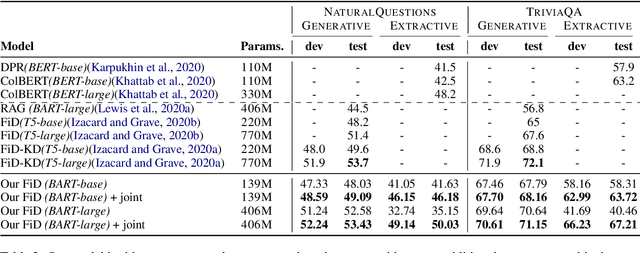
We propose a novel method for applying Transformer models to extractive question answering (QA) tasks. Recently, pretrained generative sequence-to-sequence (seq2seq) models have achieved great success in question answering. Contributing to the success of these models are internal attention mechanisms such as cross-attention. We propose a simple strategy to obtain an extractive answer span from the generative model by leveraging the decoder cross-attention patterns. Viewing cross-attention as an architectural prior, we apply joint training to further improve QA performance. Empirical results show that on open-domain question answering datasets like NaturalQuestions and TriviaQA, our method approaches state-of-the-art performance on both generative and extractive inference, all while using much fewer parameters. Furthermore, this strategy allows us to perform hallucination-free inference while conferring significant improvements to the model's ability to rerank relevant passages.