 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating Informal Proofs into Formal Proofs Using a Chain of States
Dec 12, 2025



We address the problem of translating informal mathematical proofs expressed in natural language into formal proofs in Lean4 under a constrained computational budget. Our approach is grounded in two key insights. First, informal proofs tend to proceed via a sequence of logical transitions - often implications or equivalences - without explicitly specifying intermediate results or auxiliary lemmas. In contrast, formal systems like Lean require an explicit representation of each proof state and the tactics that connect them. Second, each informal reasoning step can be viewed as an abstract transformation between proof states, but identifying the corresponding formal tactics often requires nontrivial domain knowledge and precise control over proof context. To bridge this gap, we propose a two stage framework. Rather than generating formal tactics directly, we first extract a Chain of States (CoS), a sequence of intermediate formal proof states aligned with the logical structure of the informal argument. We then generate tactics to transition between adjacent states in the CoS, thereby constructing the full formal proof. This intermediate representation significantly reduces the complexity of tactic generation and improves alignment with informal reasoning patterns. We build dedicated datasets and benchmarks for training and evaluation, and introduce an interactive framework to support tactic generation from formal states. Empirical results show that our method substantially outperforms existing baselines, achieving higher proof success rates.
SciAgent: A Unified Multi-Agent System for Generalistic Scientific Reasoning
Nov 17, 2025Recent advances in large language models have enabled AI systems to achieve expert-level performance on domain-specific scientific tasks, yet these systems remain narrow and handcrafted. We introduce SciAgent, a unified multi-agent system designed for generalistic scientific reasoning-the ability to adapt reasoning strategies across disciplines and difficulty levels. SciAgent organizes problem solving as a hierarchical process: a Coordinator Agent interprets each problem's domain and complexity, dynamically orchestrating specialized Worker Systems, each composed of interacting reasoning Sub-agents for symbolic deduction, conceptual modeling, numerical computation, and verification. These agents collaboratively assemble and refine reasoning pipelines tailored to each task. Across mathematics and physics Olympiads (IMO, IMC, IPhO, CPhO), SciAgent consistently attains or surpasses human gold-medalist performance, demonstrating both domain generality and reasoning adaptability. Additionally, SciAgent has been tested on the International Chemistry Olympiad (IChO) and selected problems from the Humanity's Last Exam (HLE) benchmark, further confirming the system's ability to generalize across diverse scientific domains. This work establishes SciAgent as a concrete step toward generalistic scientific intelligence-AI systems capable of coherent, cross-disciplinary reasoning at expert levels.
MorphoBench: A Benchmark with Difficulty Adaptive to Model Reasoning
Oct 16, 2025

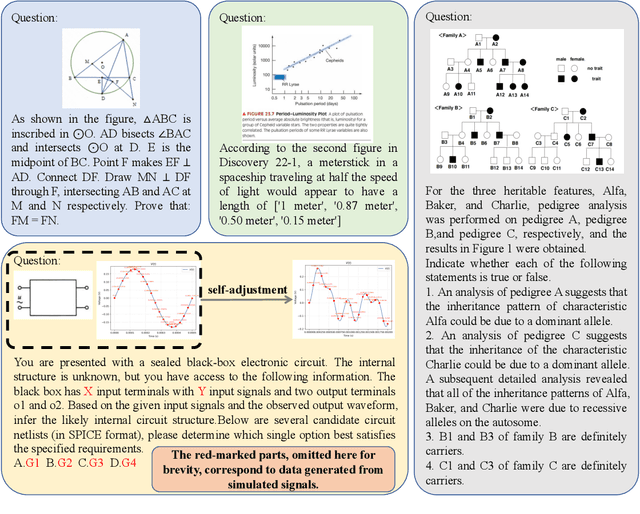
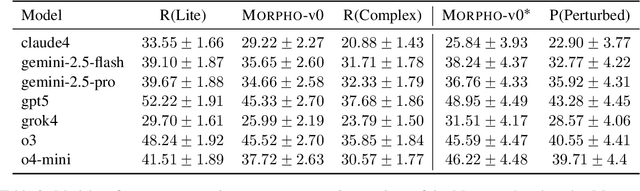
With the advancement of powerful large-scale reasoning models, effectively evaluating the reasoning capabilities of these models has become increasingly important. However, existing benchmarks designed to assess the reasoning abilities of large models tend to be limited in scope and lack the flexibility to adapt their difficulty according to the evolving reasoning capacities of the models. To address this, we propose MorphoBench, a benchmark that incorporates multidisciplinary questions to evaluate the reasoning capabilities of large models and can adjust and update question difficulty based on the reasoning abilities of advanced models. Specifically, we curate the benchmark by selecting and collecting complex reasoning questions from existing benchmarks and sources such as Olympiad-level competitions. Additionally, MorphoBench adaptively modifies the analytical challenge of questions by leveraging key statements generated during the model's reasoning process. Furthermore, it includes questions generated using simulation software, enabling dynamic adjustment of benchmark difficulty with minimal resource consumption. We have gathered over 1,300 test questions and iteratively adjusted the difficulty of MorphoBench based on the reasoning capabilities of models such as o3 and GPT-5. MorphoBench enhances the comprehensiveness and validity of model reasoning evaluation, providing reliable guidance for improving both the reasoning abilities and scientific robustness of large models. The code has been released in https://github.com/OpenDCAI/MorphoBench.
Aria: An Agent For Retrieval and Iterative Auto-Formalization via Dependency Graph
Oct 06, 2025Accurate auto-formalization of theorem statements is essential for advancing automated discovery and verification of research-level mathematics, yet remains a major bottleneck for LLMs due to hallucinations, semantic mismatches, and their inability to synthesize new definitions. To tackle these issues, we present Aria (Agent for Retrieval and Iterative Autoformalization), a system for conjecture-level formalization in Lean that emulates human expert reasoning via a two-phase Graph-of-Thought process: recursively decomposing statements into a dependency graph and then constructing formalizations from grounded concepts. To ensure semantic correctness, we introduce AriaScorer, a checker that retrieves definitions from Mathlib for term-level grounding, enabling rigorous and reliable verification. We evaluate Aria on diverse benchmarks. On ProofNet, it achieves 91.6% compilation success rate and 68.5% final accuracy, surpassing previous methods. On FATE-X, a suite of challenging algebra problems from research literature, it outperforms the best baseline with 44.0% vs. 24.0% final accuracy. On a dataset of homological conjectures, Aria reaches 42.9% final accuracy while all other models score 0%.
Aligning Perception, Reasoning, Modeling and Interaction: A Survey on Physical AI
Oct 06, 2025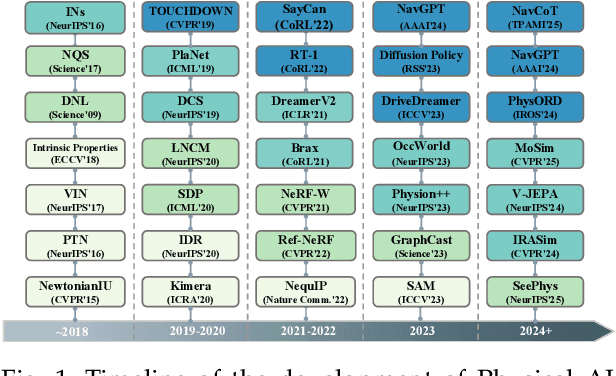
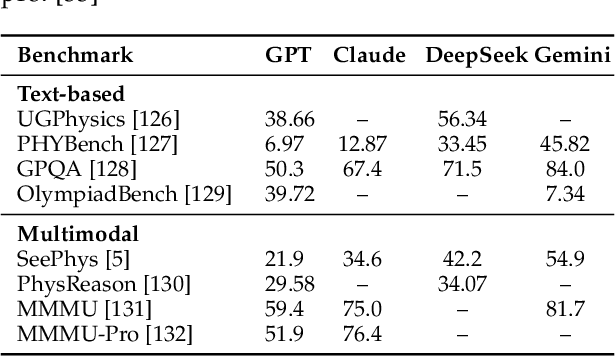
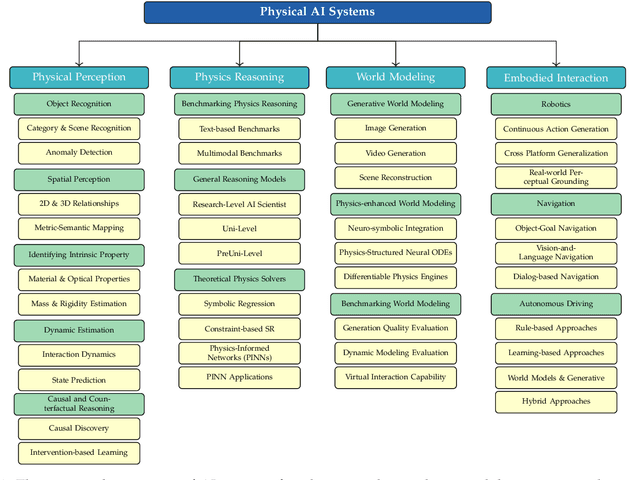
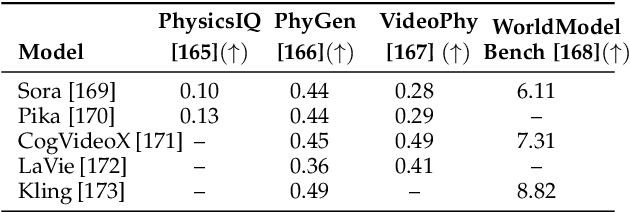
The rapid advancement of embodied intelligence and world models has intensified efforts to integrate physical laws into AI systems, yet physical perception and symbolic physics reasoning have developed along separate trajectories without a unified bridging framework. This work provides a comprehensive overview of physical AI, establishing clear distinctions between theoretical physics reasoning and applied physical understanding while systematically examining how physics-grounded methods enhance AI's real-world comprehension across structured symbolic reasoning, embodied systems, and generative models. Through rigorous analysis of recent advances, we advocate for intelligent systems that ground learning in both physical principles and embodied reasoning processes, transcending pattern recognition toward genuine understanding of physical laws. Our synthesis envisions next-generation world models capable of explaining physical phenomena and predicting future states, advancing safe, generalizable, and interpretable AI systems. We maintain a continuously updated resource at https://github.com/AI4Phys/Awesome-AI-for-Physics.
InverseScope: Scalable Activation Inversion for Interpreting Large Language Models
Jun 09, 2025



Understanding the internal representations of large language models (LLMs) is a central challenge in interpretability research. Existing feature interpretability methods often rely on strong assumptions about the structure of representations that may not hold in practice. In this work, we introduce InverseScope, an assumption-light and scalable framework for interpreting neural activations via input inversion. Given a target activation, we define a distribution over inputs that generate similar activations and analyze this distribution to infer the encoded features. To address the inefficiency of sampling in high-dimensional spaces, we propose a novel conditional generation architecture that significantly improves sample efficiency compared to previous methods. We further introduce a quantitative evaluation protocol that tests interpretability hypotheses using feature consistency rate computed over the sampled inputs. InverseScope scales inversion-based interpretability methods to larger models and practical tasks, enabling systematic and quantitative analysis of internal representations in real-world LLMs.
RainFusion: Adaptive Video Generation Acceleration via Multi-Dimensional Visual Redundancy
May 27, 2025Video generation using diffusion models is highly computationally intensive, with 3D attention in Diffusion Transformer (DiT) models accounting for over 80\% of the total computational resources. In this work, we introduce {\bf RainFusion}, a novel training-free sparse attention method that exploits inherent sparsity nature in visual data to accelerate attention computation while preserving video quality. Specifically, we identify three unique sparse patterns in video generation attention calculations--Spatial Pattern, Temporal Pattern and Textural Pattern. The sparse pattern for each attention head is determined online with negligible overhead (\textasciitilde\,0.2\%) with our proposed {\bf ARM} (Adaptive Recognition Module) during inference. Our proposed {\bf RainFusion} is a plug-and-play method, that can be seamlessly integrated into state-of-the-art 3D-attention video generation models without additional training or calibration. We evaluate our method on leading open-sourced models including HunyuanVideo, OpenSoraPlan-1.2 and CogVideoX-5B, demonstrating its broad applicability and effectiveness. Experimental results show that RainFusion achieves over {\bf 2\(\times\)} speedup in attention computation while maintaining video quality, with only a minimal impact on VBench scores (-0.2\%).
REAL-Prover: Retrieval Augmented Lean Prover for Mathematical Reasoning
May 27, 2025Nowadays, formal theorem provers have made monumental progress on high-school and competition-level mathematics, but few of them generalize to more advanced mathematics. In this paper, we present REAL-Prover, a new open-source stepwise theorem prover for Lean 4 to push this boundary. This prover, based on our fine-tuned large language model (REAL-Prover-v1) and integrated with a retrieval system (Leansearch-PS), notably boosts performance on solving college-level mathematics problems. To train REAL-Prover-v1, we developed HERALD-AF, a data extraction pipeline that converts natural language math problems into formal statements, and a new open-source Lean 4 interactive environment (Jixia-interactive) to facilitate synthesis data collection. In our experiments, our prover using only supervised fine-tune achieves competitive results with a 23.7% success rate (Pass@64) on the ProofNet dataset-comparable to state-of-the-art (SOTA) models. To further evaluate our approach, we introduce FATE-M, a new benchmark focused on algebraic problems, where our prover achieves a SOTA success rate of 56.7% (Pass@64).
MIRB: Mathematical Information Retrieval Benchmark
May 21, 2025Mathematical Information Retrieval (MIR) is the task of retrieving information from mathematical documents and plays a key role in various applications, including theorem search in mathematical libraries, answer retrieval on math forums, and premise selection in automated theorem proving. However, a unified benchmark for evaluating these diverse retrieval tasks has been lacking. In this paper, we introduce MIRB (Mathematical Information Retrieval Benchmark) to assess the MIR capabilities of retrieval models. MIRB includes four tasks: semantic statement retrieval, question-answer retrieval, premise retrieval, and formula retrieval, spanning a total of 12 datasets. We evaluate 13 retrieval models on this benchmark and analyze the challenges inherent to MIR. We hope that MIRB provides a comprehensive framework for evaluating MIR systems and helps advance the development of more effective retrieval models tailored to the mathematical domain.
Unlock Pose Diversity: Accurate and Efficient Implicit Keypoint-based Spatiotemporal Diffusion for Audio-driven Talking Portrait
Mar 17, 2025Audio-driven single-image talking portrait generation plays a crucial role in virtual reality, digital human creation, and filmmaking. Existing approaches are generally categorized into keypoint-based and image-based methods. Keypoint-based methods effectively preserve character identity but struggle to capture fine facial details due to the fixed points limitation of the 3D Morphable Model. Moreover, traditional generative networks face challenges in establishing causality between audio and keypoints on limited datasets, resulting in low pose diversity. In contrast, image-based approaches produce high-quality portraits with diverse details using the diffusion network but incur identity distortion and expensive computational costs. In this work, we propose KDTalker, the first framework to combine unsupervised implicit 3D keypoint with a spatiotemporal diffusion model. Leveraging unsupervised implicit 3D keypoints, KDTalker adapts facial information densities, allowing the diffusion process to model diverse head poses and capture fine facial details flexibly. The custom-designed spatiotemporal attention mechanism ensures accurate lip synchronization, producing temporally consistent, high-quality animations while enhancing computational efficiency. Experimental results demonstrate that KDTalker achieves state-of-the-art performance regarding lip synchronization accuracy, head pose diversity, and execution efficiency.Our codes are available at https://github.com/chaolongy/KDTalker.