 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGODEL: Large-Scale Pre-Training for Goal-Directed Dialog
Jun 22, 2022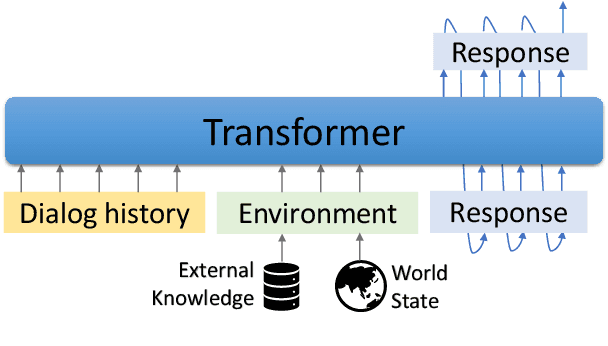
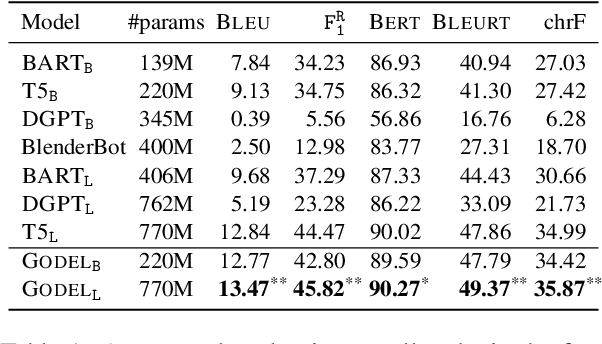

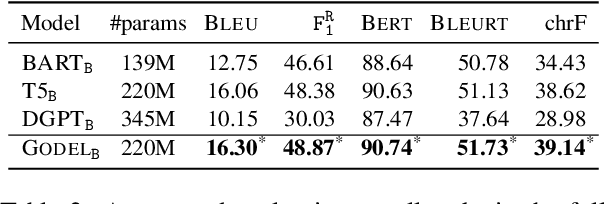
We introduce GODEL (Grounded Open Dialogue Language Model), a large pre-trained language model for dialog. In contrast with earlier models such as DialoGPT, GODEL leverages a new phase of grounded pre-training designed to better support adapting GODEL to a wide range of downstream dialog tasks that require information external to the current conversation (e.g., a database or document) to produce good responses. Experiments against an array of benchmarks that encompass task-oriented dialog, conversational QA, and grounded open-domain dialog show that GODEL outperforms state-of-the-art pre-trained dialog models in few-shot fine-tuning setups, in terms of both human and automatic evaluation. A novel feature of our evaluation methodology is the introduction of a notion of utility that assesses the usefulness of responses (extrinsic evaluation) in addition to their communicative features (intrinsic evaluation). We show that extrinsic evaluation offers improved inter-annotator agreement and correlation with automated metrics. Code and data processing scripts are publicly available.
Towards More Efficient Insertion Transformer with Fractional Positional Encoding
Dec 12, 2021
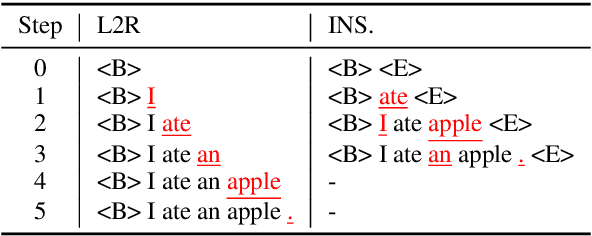
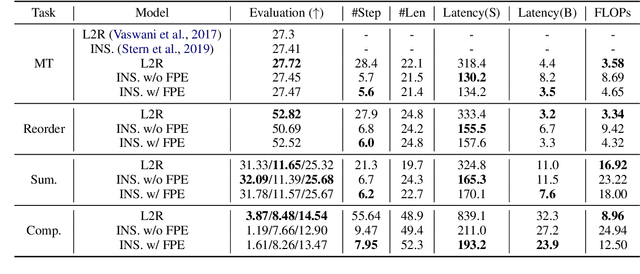
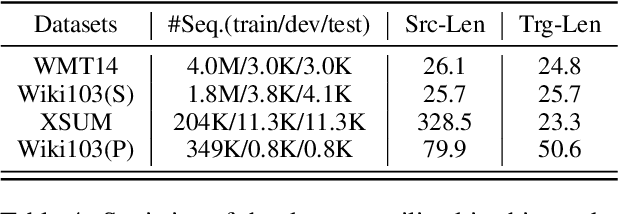
Auto-regressive neural sequence models have been shown to be effective across text generation tasks. However, their left-to-right decoding order prevents generation from being parallelized. Insertion Transformer (Stern et al., 2019) is an attractive alternative that allows outputting multiple tokens in a single generation step. Nevertheless, due to the incompatibility of absolute positional encoding and insertion-based generation schemes, it needs to refresh the encoding of every token in the generated partial hypotheses at each step, which could be costly. We design a novel incremental positional encoding scheme for insertion transformers called Fractional Positional Encoding (FPE), which allows reusing representations calculated in previous steps. Empirical studies on various language generation tasks demonstrate the effectiveness of FPE, which leads to reduction of floating point operations and latency improvements on batched decoding.
Automatic Document Sketching: Generating Drafts from Analogous Texts
Jun 14, 2021
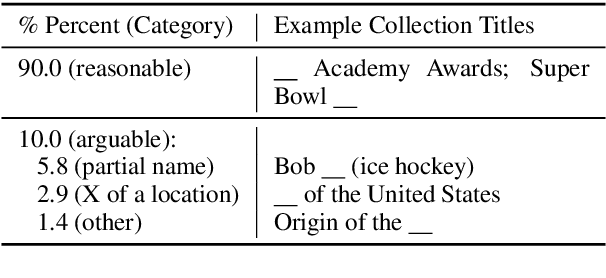
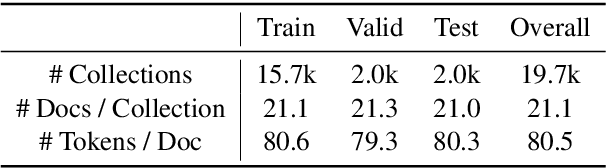
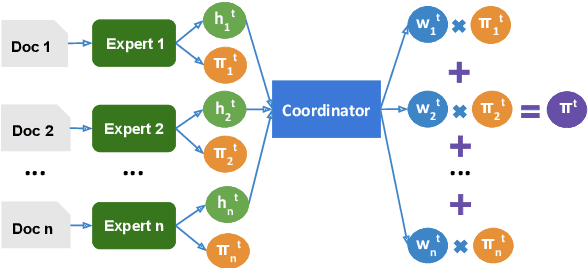
The advent of large pre-trained language models has made it possible to make high-quality predictions on how to add or change a sentence in a document. However, the high branching factor inherent to text generation impedes the ability of even the strongest language models to offer useful editing suggestions at a more global or document level. We introduce a new task, document sketching, which involves generating entire draft documents for the writer to review and revise. These drafts are built from sets of documents that overlap in form - sharing large segments of potentially reusable text - while diverging in content. To support this task, we introduce a Wikipedia-based dataset of analogous documents and investigate the application of weakly supervised methods, including use of a transformer-based mixture of experts, together with reinforcement learning. We report experiments using automated and human evaluation methods and discuss relative merits of these models.
Joint Retrieval and Generation Training for Grounded Text Generation
Jun 03, 2021
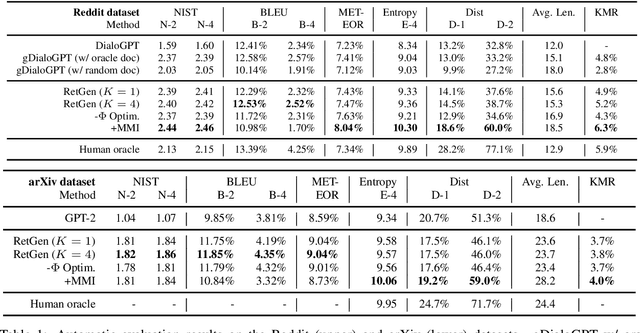
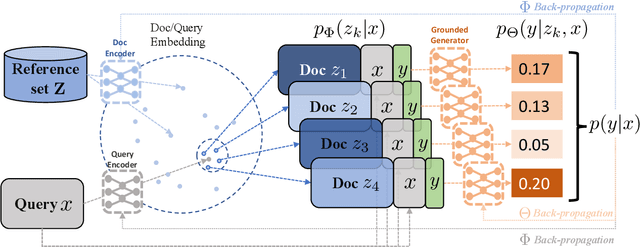

Recent advances in large-scale pre-training such as GPT-3 allow seemingly high quality text to be generated from a given prompt. However, such generation systems often suffer from problems of hallucinated facts, and are not inherently designed to incorporate useful external information. Grounded generation models appear to offer remedies, but their training typically relies on rarely-available parallel data where corresponding information-relevant documents are provided for context. We propose a framework that alleviates this data constraint by jointly training a grounded generator and document retriever on the language model signal. The model learns to reward retrieval of the documents with the highest utility in generation, and attentively combines them using a Mixture-of-Experts (MoE) ensemble to generate follow-on text. We demonstrate that both generator and retriever can take advantage of this joint training and work synergistically to produce more informative and relevant text in both prose and dialogue generation.
A Token-level Reference-free Hallucination Detection Benchmark for Free-form Text Generation
Apr 18, 2021
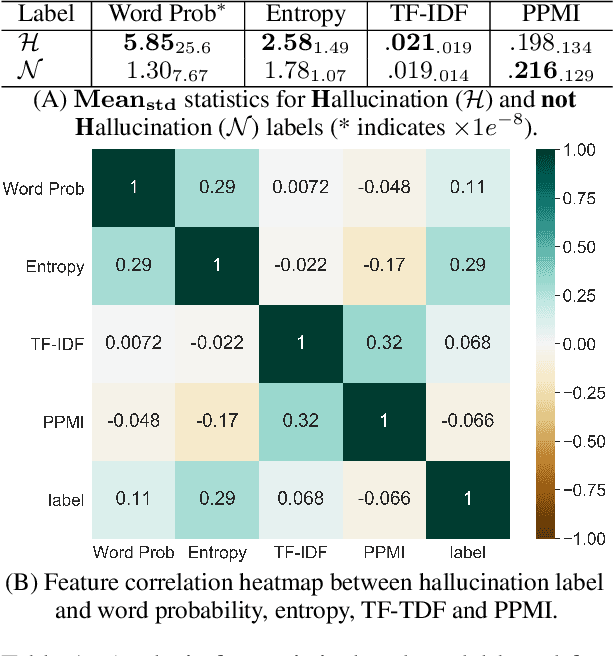
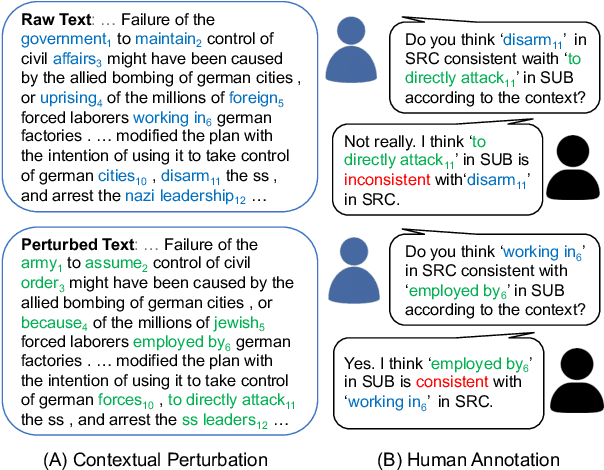
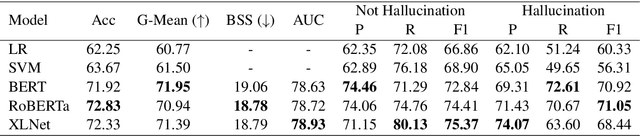
Large pretrained generative models like GPT-3 often suffer from hallucinating non-existent or incorrect content, which undermines their potential merits in real applications. Existing work usually attempts to detect these hallucinations based on a corresponding oracle reference at a sentence or document level. However ground-truth references may not be readily available for many free-form text generation applications, and sentence- or document-level detection may fail to provide the fine-grained signals that would prevent fallacious content in real time. As a first step to addressing these issues, we propose a novel token-level, reference-free hallucination detection task and an associated annotated dataset named HaDes (HAllucination DEtection dataSet). To create this dataset, we first perturb a large number of text segments extracted from English language Wikipedia, and then verify these with crowd-sourced annotations. To mitigate label imbalance during annotation, we utilize an iterative model-in-loop strategy. We conduct comprehensive data analyses and create multiple baseline models.
An Adversarially-Learned Turing Test for Dialog Generation Models
Apr 16, 2021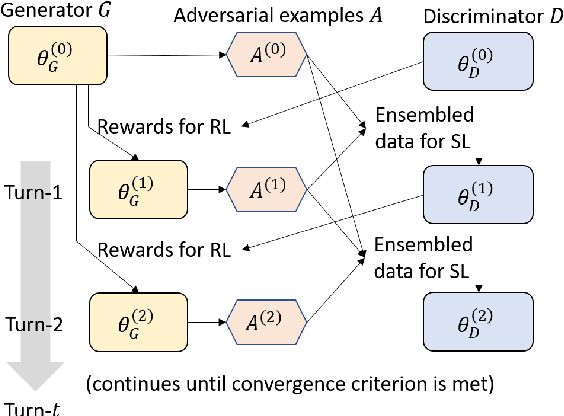

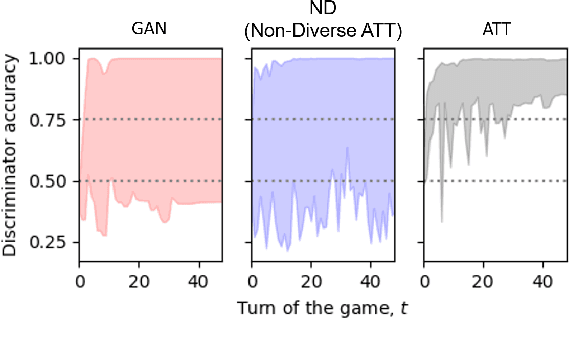
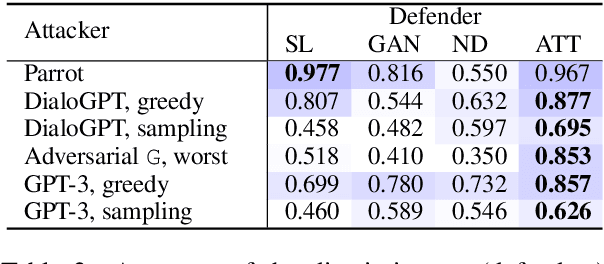
The design of better automated dialogue evaluation metrics offers the potential of accelerate evaluation research on conversational AI. However, existing trainable dialogue evaluation models are generally restricted to classifiers trained in a purely supervised manner, which suffer a significant risk from adversarial attacking (e.g., a nonsensical response that enjoys a high classification score). To alleviate this risk, we propose an adversarial training approach to learn a robust model, ATT (Adversarial Turing Test), that discriminates machine-generated responses from human-written replies. In contrast to previous perturbation-based methods, our discriminator is trained by iteratively generating unrestricted and diverse adversarial examples using reinforcement learning. The key benefit of this unrestricted adversarial training approach is allowing the discriminator to improve robustness in an iterative attack-defense game. Our discriminator shows high accuracy on strong attackers including DialoGPT and GPT-3.
What Makes Good In-Context Examples for GPT-$3$?
Jan 17, 2021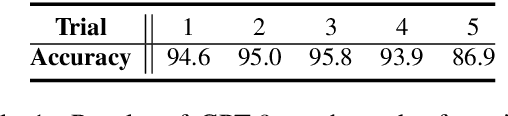
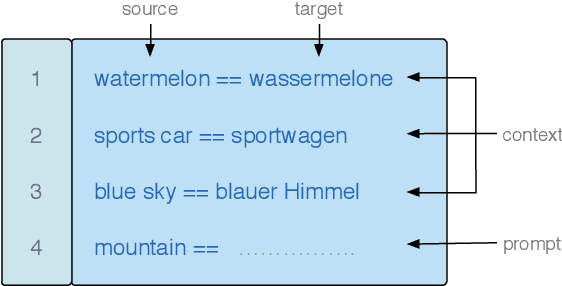
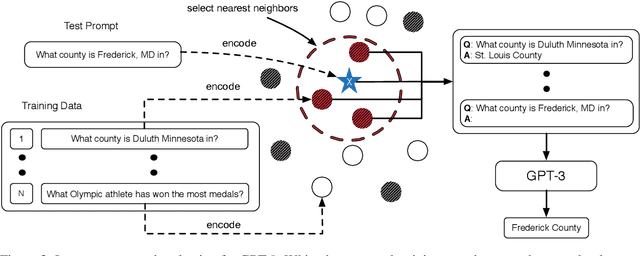
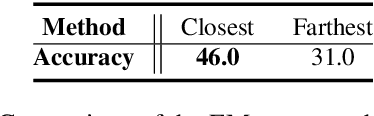
GPT-$3$ has attracted lots of attention due to its superior performance across a wide range of NLP tasks, especially with its powerful and versatile in-context few-shot learning ability. Despite its success, we found that the empirical results of GPT-$3$ depend heavily on the choice of in-context examples. In this work, we investigate whether there are more effective strategies for judiciously selecting in-context examples (relative to random sampling) that better leverage GPT-$3$'s few-shot capabilities. Inspired by the recent success of leveraging a retrieval module to augment large-scale neural network models, we propose to retrieve examples that are semantically-similar to a test sample to formulate its corresponding prompt. Intuitively, the in-context examples selected with such a strategy may serve as more informative inputs to unleash GPT-$3$'s extensive knowledge. We evaluate the proposed approach on several natural language understanding and generation benchmarks, where the retrieval-based prompt selection approach consistently outperforms the random baseline. Moreover, it is observed that the sentence encoders fine-tuned on task-related datasets yield even more helpful retrieval results. Notably, significant gains are observed on tasks such as table-to-text generation (41.9% on the ToTTo dataset) and open-domain question answering (45.5% on the NQ dataset). We hope our investigation could help understand the behaviors of GPT-$3$ and large-scale pre-trained LMs in general and enhance their few-shot capabilities.
Narrative Incoherence Detection
Dec 21, 2020

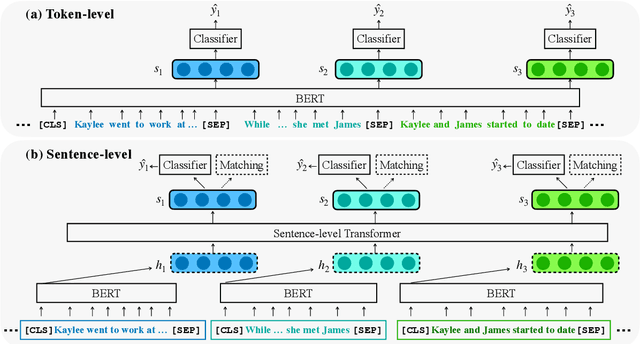
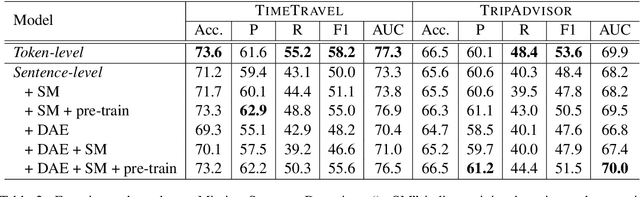
Motivated by the increasing popularity of intelligent editing assistant, we introduce and investigate the task of narrative incoherence detection: Given a (corrupted) long-form narrative, decide whether there exists some semantic discrepancy in the narrative flow. Specifically, we focus on the missing sentence and incoherent sentence detection. Despite its simple setup, this task is challenging as the model needs to understand and analyze a multi-sentence narrative text, and make decisions at the sentence level. As an initial step towards this task, we implement several baselines either directly analyzing the raw text (\textit{token-level}) or analyzing learned sentence representations (\textit{sentence-level}). We observe that while token-level modeling enjoys greater expressive power and hence better performance, sentence-level modeling possesses an advantage in efficiency and flexibility. With pre-training on large-scale data and cycle-consistent sentence embedding, our extended sentence-level model can achieve comparable detection accuracy to the token-level model. As a by-product, such a strategy enables simultaneous incoherence detection and infilling/modification suggestions.
Text Editing by Command
Oct 24, 2020
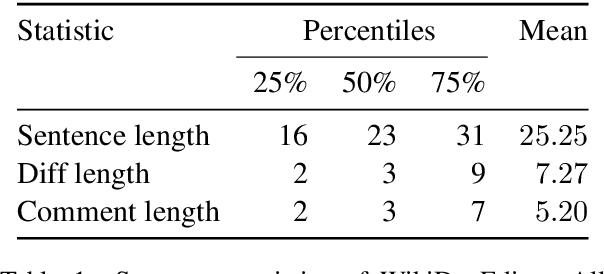
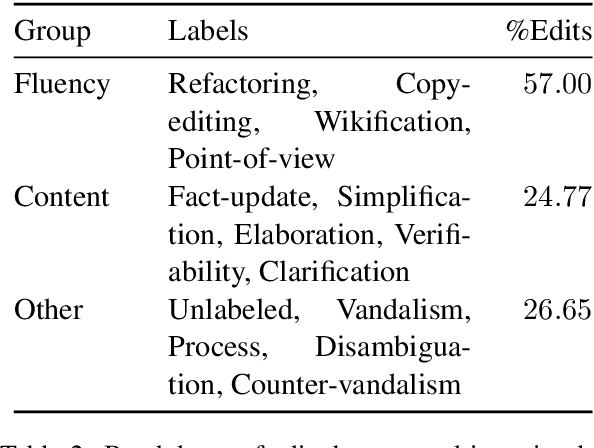
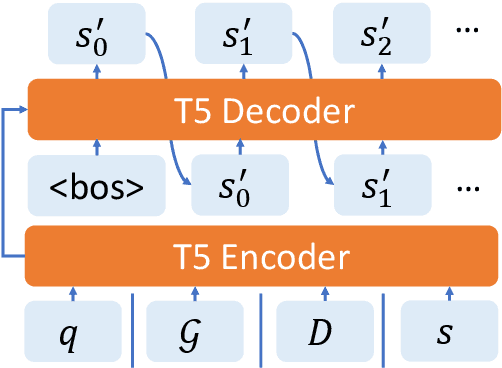
A prevailing paradigm in neural text generation is one-shot generation, where text is produced in a single step. The one-shot setting is inadequate, however, when the constraints the user wishes to impose on the generated text are dynamic, especially when authoring longer documents. We address this limitation with an interactive text generation setting in which the user interacts with the system by issuing commands to edit existing text. To this end, we propose a novel text editing task, and introduce WikiDocEdits, a dataset of single-sentence edits crawled from Wikipedia. We show that our Interactive Editor, a transformer-based model trained on this dataset, outperforms baselines and obtains positive results in both automatic and human evaluations. We present empirical and qualitative analyses of this model's performance.
Substance over Style: Document-Level Targeted Content Transfer
Oct 16, 2020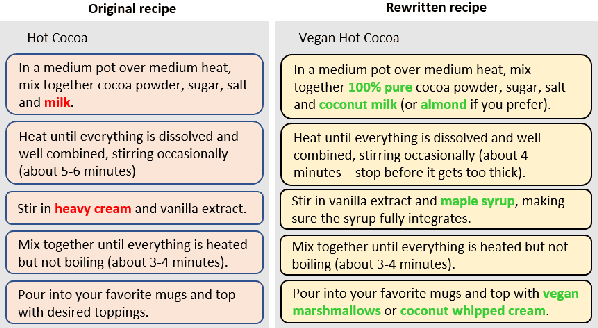
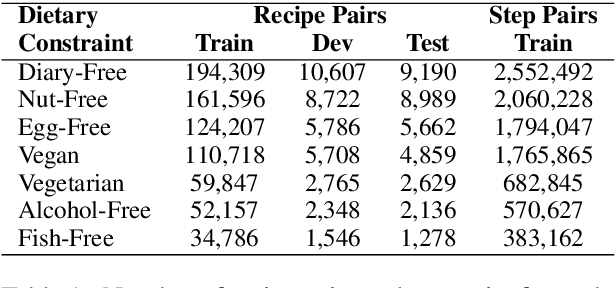
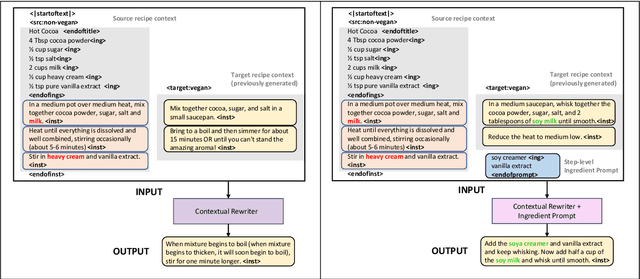

Existing language models excel at writing from scratch, but many real-world scenarios require rewriting an existing document to fit a set of constraints. Although sentence-level rewriting has been fairly well-studied, little work has addressed the challenge of rewriting an entire document coherently. In this work, we introduce the task of document-level targeted content transfer and address it in the recipe domain, with a recipe as the document and a dietary restriction (such as vegan or dairy-free) as the targeted constraint. We propose a novel model for this task based on the generative pre-trained language model (GPT-2) and train on a large number of roughly-aligned recipe pairs (https://github.com/microsoft/document-level-targeted-content-transfer). Both automatic and human evaluations show that our model out-performs existing methods by generating coherent and diverse rewrites that obey the constraint while remaining close to the original document. Finally, we analyze our model's rewrites to assess progress toward the goal of making language generation more attuned to constraints that are substantive rather than stylistic.