 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusing the Blind Spot: Uterine MRI Synthesis with Diffusion Models
Aug 11, 2025


Despite significant progress in generative modelling, existing diffusion models often struggle to produce anatomically precise female pelvic images, limiting their application in gynaecological imaging, where data scarcity and patient privacy concerns are critical. To overcome these barriers, we introduce a novel diffusion-based framework for uterine MRI synthesis, integrating both unconditional and conditioned Denoising Diffusion Probabilistic Models (DDPMs) and Latent Diffusion Models (LDMs) in 2D and 3D. Our approach generates anatomically coherent, high fidelity synthetic images that closely mimic real scans and provide valuable resources for training robust diagnostic models. We evaluate generative quality using advanced perceptual and distributional metrics, benchmarking against standard reconstruction methods, and demonstrate substantial gains in diagnostic accuracy on a key classification task. A blinded expert evaluation further validates the clinical realism of our synthetic images. We release our models with privacy safeguards and a comprehensive synthetic uterine MRI dataset to support reproducible research and advance equitable AI in gynaecology.
Topology Optimization in Medical Image Segmentation with Fast Euler Characteristic
Jul 31, 2025Deep learning-based medical image segmentation techniques have shown promising results when evaluated based on conventional metrics such as the Dice score or Intersection-over-Union. However, these fully automatic methods often fail to meet clinically acceptable accuracy, especially when topological constraints should be observed, e.g., continuous boundaries or closed surfaces. In medical image segmentation, the correctness of a segmentation in terms of the required topological genus sometimes is even more important than the pixel-wise accuracy. Existing topology-aware approaches commonly estimate and constrain the topological structure via the concept of persistent homology (PH). However, these methods are difficult to implement for high dimensional data due to their polynomial computational complexity. To overcome this problem, we propose a novel and fast approach for topology-aware segmentation based on the Euler Characteristic ($\chi$). First, we propose a fast formulation for $\chi$ computation in both 2D and 3D. The scalar $\chi$ error between the prediction and ground-truth serves as the topological evaluation metric. Then we estimate the spatial topology correctness of any segmentation network via a so-called topological violation map, i.e., a detailed map that highlights regions with $\chi$ errors. Finally, the segmentation results from the arbitrary network are refined based on the topological violation maps by a topology-aware correction network. Our experiments are conducted on both 2D and 3D datasets and show that our method can significantly improve topological correctness while preserving pixel-wise segmentation accuracy.
Generate to Ground: Multimodal Text Conditioning Boosts Phrase Grounding in Medical Vision-Language Models
Jul 16, 2025Phrase grounding, i.e., mapping natural language phrases to specific image regions, holds significant potential for disease localization in medical imaging through clinical reports. While current state-of-the-art methods rely on discriminative, self-supervised contrastive models, we demonstrate that generative text-to-image diffusion models, leveraging cross-attention maps, can achieve superior zero-shot phrase grounding performance. Contrary to prior assumptions, we show that fine-tuning diffusion models with a frozen, domain-specific language model, such as CXR-BERT, substantially outperforms domain-agnostic counterparts. This setup achieves remarkable improvements, with mIoU scores doubling those of current discriminative methods. These findings highlight the underexplored potential of generative models for phrase grounding tasks. To further enhance performance, we introduce Bimodal Bias Merging (BBM), a novel post-processing technique that aligns text and image biases to identify regions of high certainty. BBM refines cross-attention maps, achieving even greater localization accuracy. Our results establish generative approaches as a more effective paradigm for phrase grounding in the medical imaging domain, paving the way for more robust and interpretable applications in clinical practice. The source code and model weights are available at https://github.com/Felix-012/generate_to_ground.
CRG Score: A Distribution-Aware Clinical Metric for Radiology Report Generation
May 22, 2025Evaluating long-context radiology report generation is challenging. NLG metrics fail to capture clinical correctness, while LLM-based metrics often lack generalizability. Clinical accuracy metrics are more relevant but are sensitive to class imbalance, frequently favoring trivial predictions. We propose the CRG Score, a distribution-aware and adaptable metric that evaluates only clinically relevant abnormalities explicitly described in reference reports. CRG supports both binary and structured labels (e.g., type, location) and can be paired with any LLM for feature extraction. By balancing penalties based on label distribution, it enables fairer, more robust evaluation and serves as a clinically aligned reward function.
NOVA: A Benchmark for Anomaly Localization and Clinical Reasoning in Brain MRI
May 20, 2025



In many real-world applications, deployed models encounter inputs that differ from the data seen during training. Out-of-distribution detection identifies whether an input stems from an unseen distribution, while open-world recognition flags such inputs to ensure the system remains robust as ever-emerging, previously $unknown$ categories appear and must be addressed without retraining. Foundation and vision-language models are pre-trained on large and diverse datasets with the expectation of broad generalization across domains, including medical imaging. However, benchmarking these models on test sets with only a few common outlier types silently collapses the evaluation back to a closed-set problem, masking failures on rare or truly novel conditions encountered in clinical use. We therefore present $NOVA$, a challenging, real-life $evaluation-only$ benchmark of $\sim$900 brain MRI scans that span 281 rare pathologies and heterogeneous acquisition protocols. Each case includes rich clinical narratives and double-blinded expert bounding-box annotations. Together, these enable joint assessment of anomaly localisation, visual captioning, and diagnostic reasoning. Because NOVA is never used for training, it serves as an $extreme$ stress-test of out-of-distribution generalisation: models must bridge a distribution gap both in sample appearance and in semantic space. Baseline results with leading vision-language models (GPT-4o, Gemini 2.0 Flash, and Qwen2.5-VL-72B) reveal substantial performance drops across all tasks, establishing NOVA as a rigorous testbed for advancing models that can detect, localize, and reason about truly unknown anomalies.
Leveraging Multi-Modal Information to Enhance Dataset Distillation
May 15, 2025Dataset distillation aims to create a compact and highly representative synthetic dataset that preserves the knowledge of a larger real dataset. While existing methods primarily focus on optimizing visual representations, incorporating additional modalities and refining object-level information can significantly improve the quality of distilled datasets. In this work, we introduce two key enhancements to dataset distillation: caption-guided supervision and object-centric masking. To integrate textual information, we propose two strategies for leveraging caption features: the feature concatenation, where caption embeddings are fused with visual features at the classification stage, and caption matching, which introduces a caption-based alignment loss during training to ensure semantic coherence between real and synthetic data. Additionally, we apply segmentation masks to isolate target objects and remove background distractions, introducing two loss functions designed for object-centric learning: masked feature alignment loss and masked gradient matching loss. Comprehensive evaluations demonstrate that integrating caption-based guidance and object-centric masking enhances dataset distillation, leading to synthetic datasets that achieve superior performance on downstream tasks.
Dataset Distillation with Probabilistic Latent Features
May 10, 2025As deep learning models grow in complexity and the volume of training data increases, reducing storage and computational costs becomes increasingly important. Dataset distillation addresses this challenge by synthesizing a compact set of synthetic data that can effectively replace the original dataset in downstream classification tasks. While existing methods typically rely on mapping data from pixel space to the latent space of a generative model, we propose a novel stochastic approach that models the joint distribution of latent features. This allows our method to better capture spatial structures and produce diverse synthetic samples, which benefits model training. Specifically, we introduce a low-rank multivariate normal distribution parameterized by a lightweight network. This design maintains low computational complexity and is compatible with various matching networks used in dataset distillation. After distillation, synthetic images are generated by feeding the learned latent features into a pretrained generator. These synthetic images are then used to train classification models, and performance is evaluated on real test set. We validate our method on several benchmarks, including ImageNet subsets, CIFAR-10, and the MedMNIST histopathological dataset. Our approach achieves state-of-the-art cross architecture performance across a range of backbone architectures, demonstrating its generality and effectiveness.
Video Dataset Condensation with Diffusion Models
May 10, 2025In recent years, the rapid expansion of dataset sizes and the increasing complexity of deep learning models have significantly escalated the demand for computational resources, both for data storage and model training. Dataset distillation has emerged as a promising solution to address this challenge by generating a compact synthetic dataset that retains the essential information from a large real dataset. However, existing methods often suffer from limited performance and poor data quality, particularly in the video domain. In this paper, we focus on video dataset distillation by employing a video diffusion model to generate high-quality synthetic videos. To enhance representativeness, we introduce Video Spatio-Temporal U-Net (VST-UNet), a model designed to select a diverse and informative subset of videos that effectively captures the characteristics of the original dataset. To further optimize computational efficiency, we explore a training-free clustering algorithm, Temporal-Aware Cluster-based Distillation (TAC-DT), to select representative videos without requiring additional training overhead. We validate the effectiveness of our approach through extensive experiments on four benchmark datasets, demonstrating performance improvements of up to \(10.61\%\) over the state-of-the-art. Our method consistently outperforms existing approaches across all datasets, establishing a new benchmark for video dataset distillation.
SpinMeRound: Consistent Multi-View Identity Generation Using Diffusion Models
Apr 14, 2025Despite recent progress in diffusion models, generating realistic head portraits from novel viewpoints remains a significant challenge. Most current approaches are constrained to limited angular ranges, predominantly focusing on frontal or near-frontal views. Moreover, although the recent emerging large-scale diffusion models have been proven robust in handling 3D scenes, they underperform on facial data, given their complex structure and the uncanny valley pitfalls. In this paper, we propose SpinMeRound, a diffusion-based approach designed to generate consistent and accurate head portraits from novel viewpoints. By leveraging a number of input views alongside an identity embedding, our method effectively synthesizes diverse viewpoints of a subject whilst robustly maintaining its unique identity features. Through experimentation, we showcase our model's generation capabilities in 360 head synthesis, while beating current state-of-the-art multiview diffusion models.
EchoFlow: A Foundation Model for Cardiac Ultrasound Image and Video Generation
Mar 28, 2025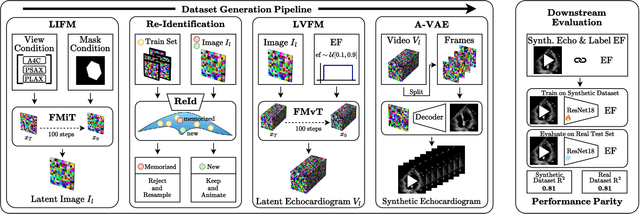
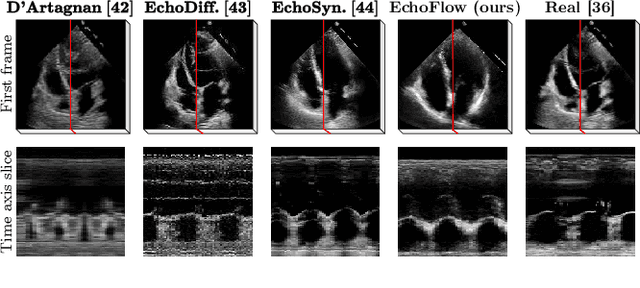
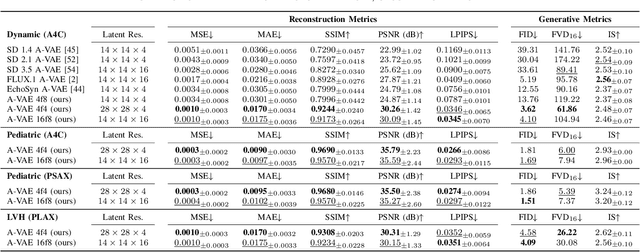
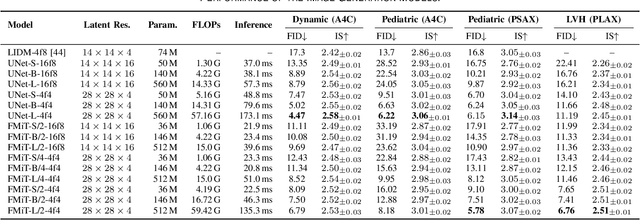
Advances in deep learning have significantly enhanced medical image analysis, yet the availability of large-scale medical datasets remains constrained by patient privacy concerns. We present EchoFlow, a novel framework designed to generate high-quality, privacy-preserving synthetic echocardiogram images and videos. EchoFlow comprises four key components: an adversarial variational autoencoder for defining an efficient latent representation of cardiac ultrasound images, a latent image flow matching model for generating accurate latent echocardiogram images, a latent re-identification model to ensure privacy by filtering images anatomically, and a latent video flow matching model for animating latent images into realistic echocardiogram videos conditioned on ejection fraction. We rigorously evaluate our synthetic datasets on the clinically relevant task of ejection fraction regression and demonstrate, for the first time, that downstream models trained exclusively on EchoFlow-generated synthetic datasets achieve performance parity with models trained on real datasets. We release our models and synthetic datasets, enabling broader, privacy-compliant research in medical ultrasound imaging at https://huggingface.co/spaces/HReynaud/EchoFlow.