 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-scale Attention Guided Multi-instance Learning for Crohn's Disease Diagnosis with Pathological Images
Aug 15, 2022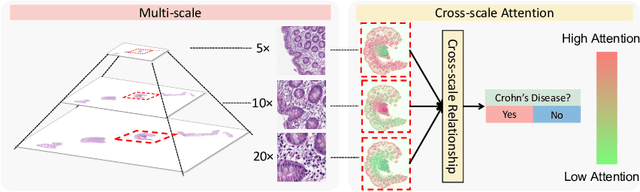
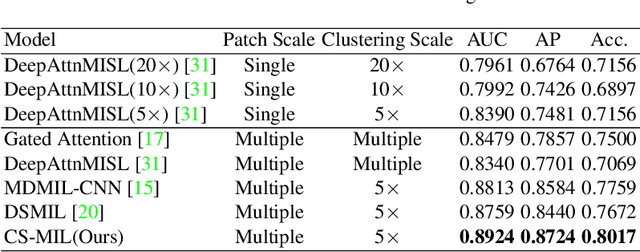
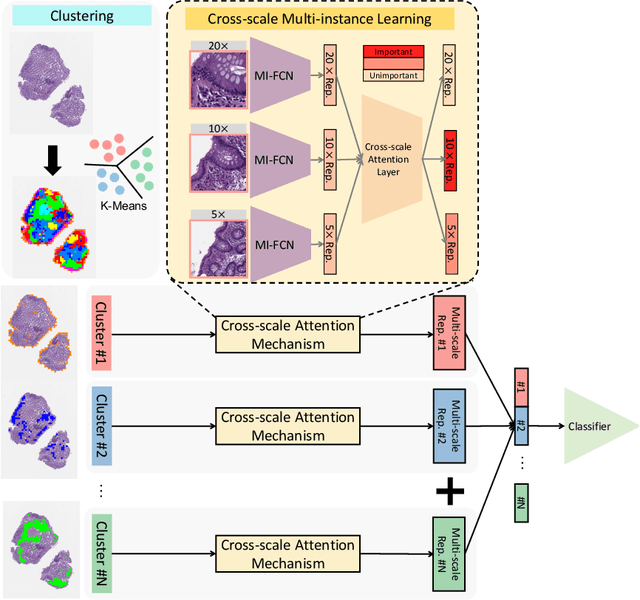
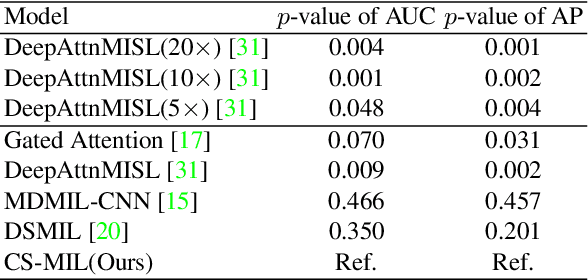
Multi-instance learning (MIL) is widely used in the computer-aided interpretation of pathological Whole Slide Images (WSIs) to solve the lack of pixel-wise or patch-wise annotations. Often, this approach directly applies "natural image driven" MIL algorithms which overlook the multi-scale (i.e. pyramidal) nature of WSIs. Off-the-shelf MIL algorithms are typically deployed on a single-scale of WSIs (e.g., 20x magnification), while human pathologists usually aggregate the global and local patterns in a multi-scale manner (e.g., by zooming in and out between different magnifications). In this study, we propose a novel cross-scale attention mechanism to explicitly aggregate inter-scale interactions into a single MIL network for Crohn's Disease (CD), which is a form of inflammatory bowel disease. The contribution of this paper is two-fold: (1) a cross-scale attention mechanism is proposed to aggregate features from different resolutions with multi-scale interaction; and (2) differential multi-scale attention visualizations are generated to localize explainable lesion patterns. By training ~250,000 H&E-stained Ascending Colon (AC) patches from 20 CD patient and 30 healthy control samples at different scales, our approach achieved a superior Area under the Curve (AUC) score of 0.8924 compared with baseline models. The official implementation is publicly available at https://github.com/hrlblab/CS-MIL.
Body Composition Assessment with Limited Field-of-view Computed Tomography: A Semantic Image Extension Perspective
Jul 13, 2022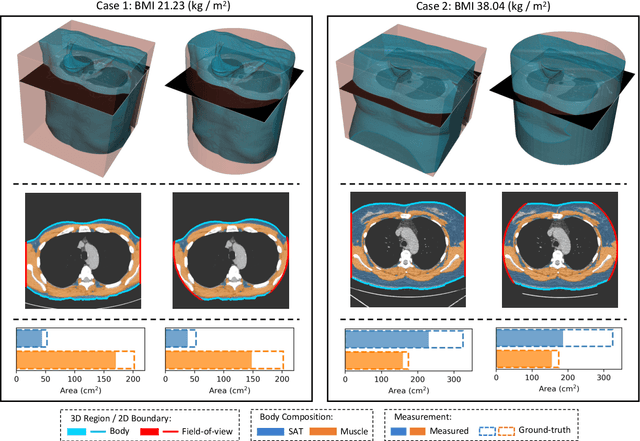
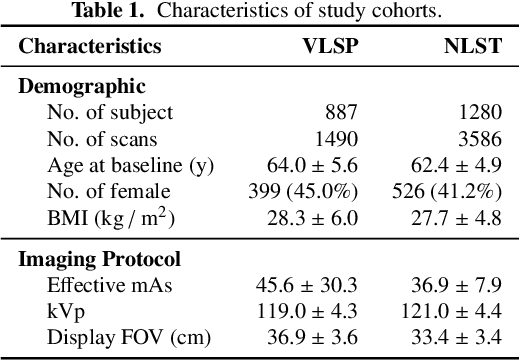
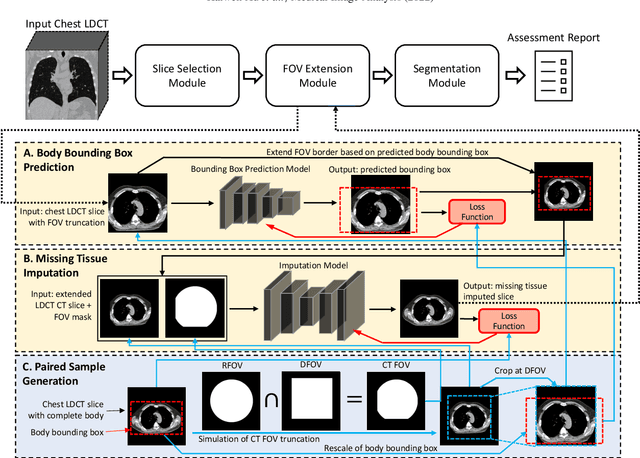
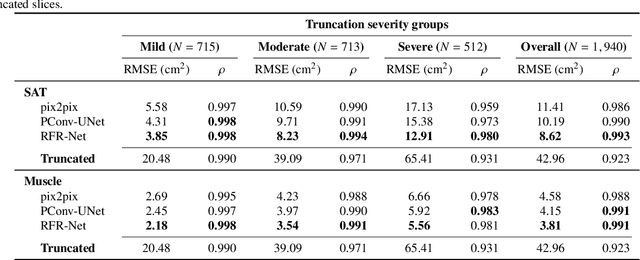
Field-of-view (FOV) tissue truncation beyond the lungs is common in routine lung screening computed tomography (CT). This poses limitations for opportunistic CT- based body composition (BC) assessment as key anatomical structures are missing. Traditionally, extending the FOV of CT is considered as a CT reconstruction problem using limited data. However, this approach relies on the projection domain data which might not be available in application. In this work, we formulate the problem from the semantic image extension perspective which only requires image data as inputs. The proposed two-stage method identifies a new FOV border based on the estimated extent of the complete body and imputes missing tissues in the truncated region. The training samples are simulated using CT slices with complete body in FOV, making the model development self-supervised. We evaluate the validity of the proposed method in automatic BC assessment using lung screening CT with limited FOV. The proposed method effectively restores the missing tissues and reduces BC assessment error introduced by FOV tissue truncation. In the BC assessment for a large-scale lung screening CT dataset, this correction improves both the intra-subject consistency and the correlation with anthropometric approximations. The developed method is available at https://github.com/MASILab/S-EFOV.
Transforming medical imaging with Transformers? A comparative review of key properties, current progresses, and future perspectives
Jun 03, 2022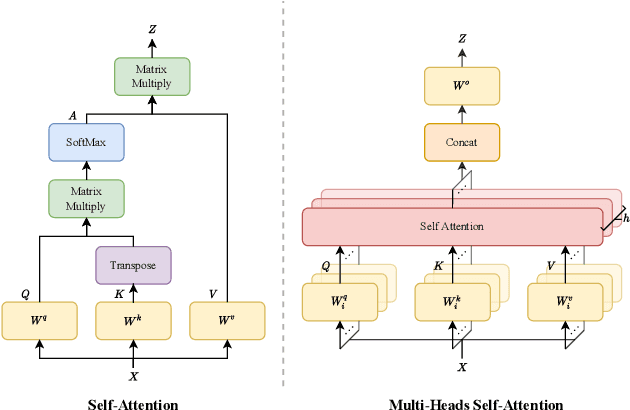
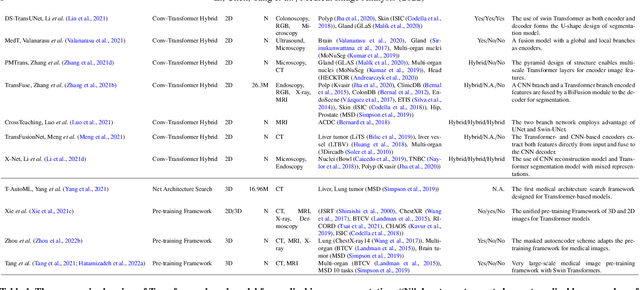
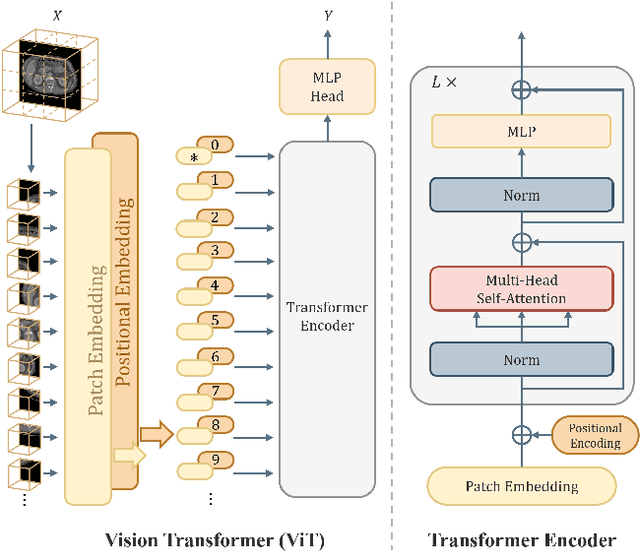
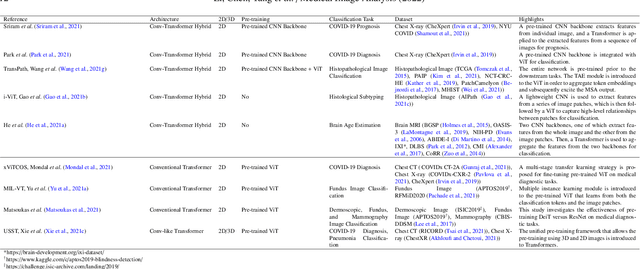
Transformer, the latest technological advance of deep learning, has gained prevalence in natural language processing or computer vision. Since medical imaging bear some resemblance to computer vision, it is natural to inquire about the status quo of Transformers in medical imaging and ask the question: can the Transformer models transform medical imaging? In this paper, we attempt to make a response to the inquiry. After a brief introduction of the fundamentals of Transformers, especially in comparison with convolutional neural networks (CNNs), and highlighting key defining properties that characterize the Transformers, we offer a comprehensive review of the state-of-the-art Transformer-based approaches for medical imaging and exhibit current research progresses made in the areas of medical image segmentation, recognition, detection, registration, reconstruction, enhancement, etc. In particular, what distinguishes our review lies in its organization based on the Transformer's key defining properties, which are mostly derived from comparing the Transformer and CNN, and its type of architecture, which specifies the manner in which the Transformer and CNN are combined, all helping the readers to best understand the rationale behind the reviewed approaches. We conclude with discussions of future perspectives.
Metrics reloaded: Pitfalls and recommendations for image analysis validation
Jun 03, 2022



The field of automatic biomedical image analysis crucially depends on robust and meaningful performance metrics for algorithm validation. Current metric usage, however, is often ill-informed and does not reflect the underlying domain interest. Here, we present a comprehensive framework that guides researchers towards choosing performance metrics in a problem-aware manner. Specifically, we focus on biomedical image analysis problems that can be interpreted as a classification task at image, object or pixel level. The framework first compiles domain interest-, target structure-, data set- and algorithm output-related properties of a given problem into a problem fingerprint, while also mapping it to the appropriate problem category, namely image-level classification, semantic segmentation, instance segmentation, or object detection. It then guides users through the process of selecting and applying a set of appropriate validation metrics while making them aware of potential pitfalls related to individual choices. In this paper, we describe the current status of the Metrics Reloaded recommendation framework, with the goal of obtaining constructive feedback from the image analysis community. The current version has been developed within an international consortium of more than 60 image analysis experts and will be made openly available as a user-friendly toolkit after community-driven optimization.
Pseudo-Label Guided Multi-Contrast Generalization for Non-Contrast Organ-Aware Segmentation
May 12, 2022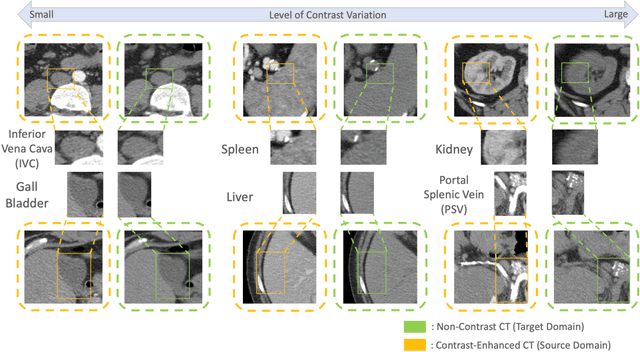
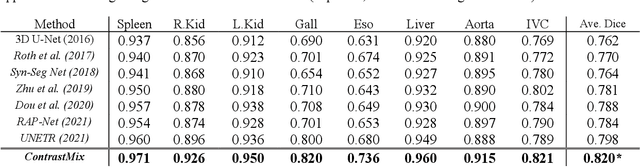
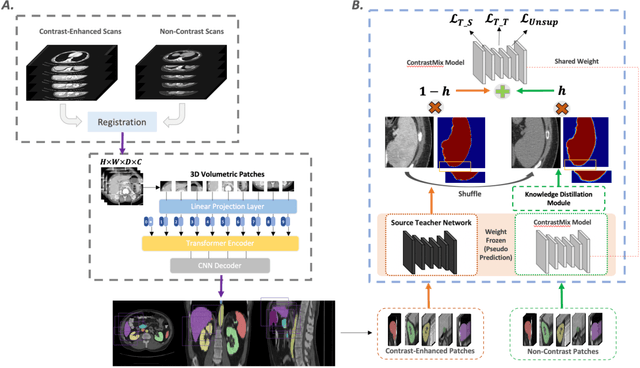
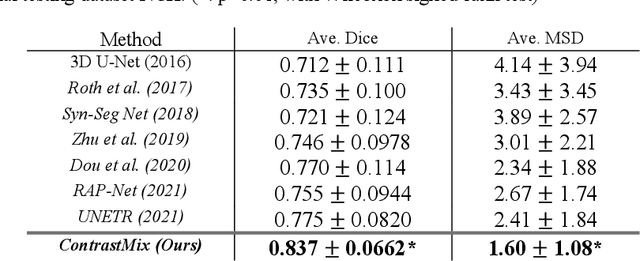
Non-contrast computed tomography (NCCT) is commonly acquired for lung cancer screening, assessment of general abdominal pain or suspected renal stones, trauma evaluation, and many other indications. However, the absence of contrast limits distinguishing organ in-between boundaries. In this paper, we propose a novel unsupervised approach that leverages pairwise contrast-enhanced CT (CECT) context to compute non-contrast segmentation without ground-truth label. Unlike generative adversarial approaches, we compute the pairwise morphological context with CECT to provide teacher guidance instead of generating fake anatomical context. Additionally, we further augment the intensity correlations in 'organ-specific' settings and increase the sensitivity to organ-aware boundary. We validate our approach on multi-organ segmentation with paired non-contrast & contrast-enhanced CT scans using five-fold cross-validation. Full external validations are performed on an independent non-contrast cohort for aorta segmentation. Compared with current abdominal organs segmentation state-of-the-art in fully supervised setting, our proposed pipeline achieves a significantly higher Dice by 3.98% (internal multi-organ annotated), and 8.00% (external aorta annotated) for abdominal organs segmentation. The code and pretrained models are publicly available at https://github.com/MASILab/ContrastMix.
Deep Multi-modal Fusion of Image and Non-image Data in Disease Diagnosis and Prognosis: A Review
Mar 30, 2022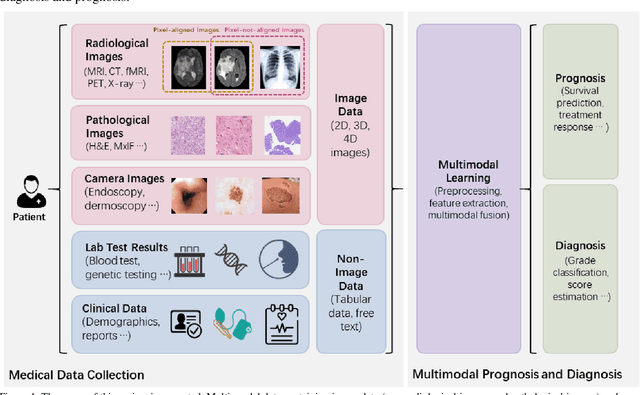
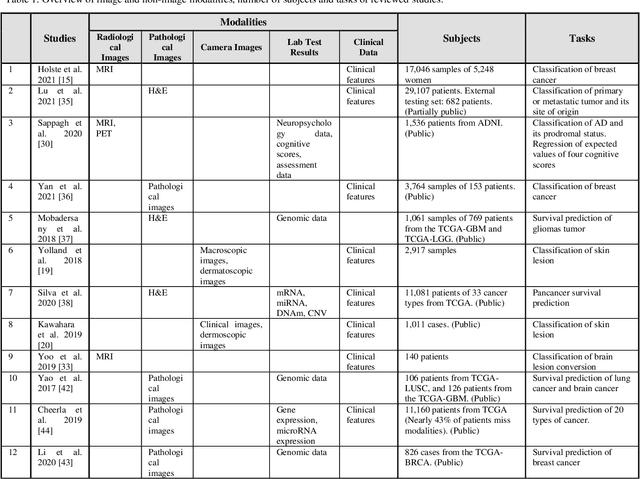
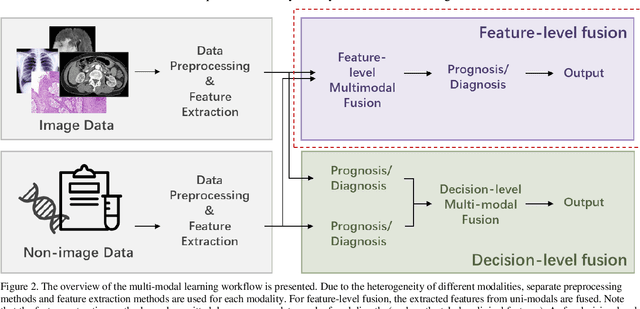

The rapid development of diagnostic technologies in healthcare is leading to higher requirements for physicians to handle and integrate the heterogeneous, yet complementary data that are produced during routine practice. For instance, the personalized diagnosis and treatment planning for a single cancer patient relies on the various images (e.g., radiological, pathological, and camera images) and non-image data (e.g., clinical data and genomic data). However, such decision-making procedures can be subjective, qualitative, and have large inter-subject variabilities. With the recent advances in multi-modal deep learning technologies, an increasingly large number of efforts have been devoted to a key question: how do we extract and aggregate multi-modal information to ultimately provide more objective, quantitative computer-aided clinical decision making? This paper reviews the recent studies on dealing with such a question. Briefly, this review will include the (1) overview of current multi-modal learning workflows, (2) summarization of multi-modal fusion methods, (3) discussion of the performance, (4) applications in disease diagnosis and prognosis, and (5) challenges and future directions.
Survival Prediction of Brain Cancer with Incomplete Radiology, Pathology, Genomics, and Demographic Data
Mar 08, 2022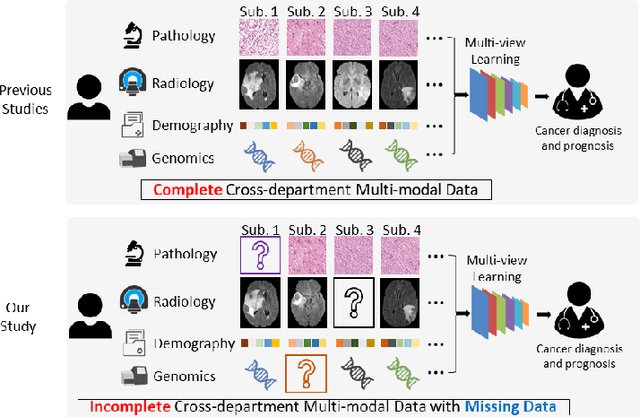

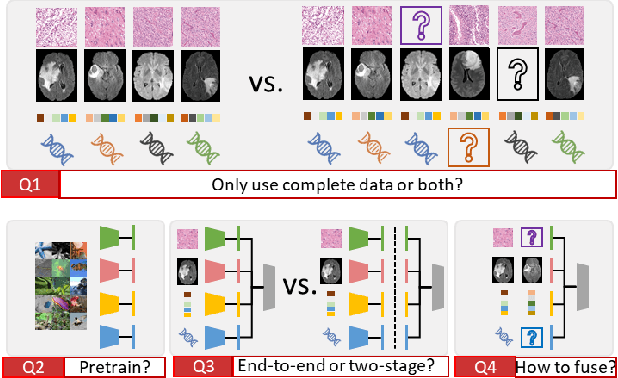
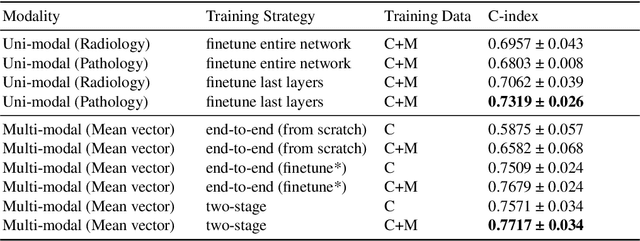
Integrating cross-department multi-modal data (e.g., radiological, pathological, genomic, and clinical data) is ubiquitous in brain cancer diagnosis and survival prediction. To date, such an integration is typically conducted by human physicians (and panels of experts), which can be subjective and semi-quantitative. Recent advances in multi-modal deep learning, however, have opened a door to leverage such a process to a more objective and quantitative manner. Unfortunately, the prior arts of using four modalities on brain cancer survival prediction are limited by a "complete modalities" setting (i.e., with all modalities available). Thus, there are still open questions on how to effectively predict brain cancer survival from the incomplete radiological, pathological, genomic, and demographic data (e.g., one or more modalities might not be collected for a patient). For instance, should we use both complete and incomplete data, and more importantly, how to use those data? To answer the preceding questions, we generalize the multi-modal learning on cross-department multi-modal data to a missing data setting. Our contribution is three-fold: 1) We introduce optimal multi-modal learning with missing data (MMD) pipeline with optimized hardware consumption and computational efficiency; 2) We extend multi-modal learning on radiological, pathological, genomic, and demographic data into missing data scenarios; 3) a large-scale public dataset (with 962 patients) is collected to systematically evaluate glioma tumor survival prediction using four modalities. The proposed method improved the C-index of survival prediction from 0.7624 to 0.8053.
Characterizing Renal Structures with 3D Block Aggregate Transformers
Mar 04, 2022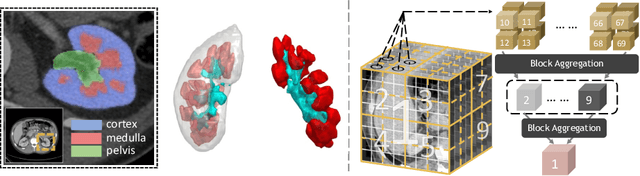
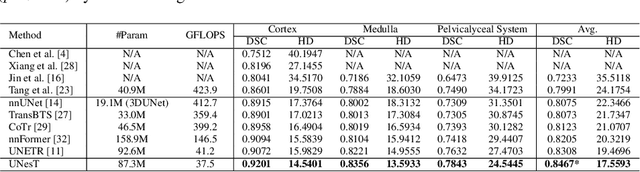
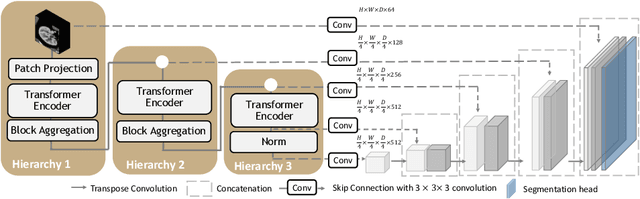

Efficiently quantifying renal structures can provide distinct spatial context and facilitate biomarker discovery for kidney morphology. However, the development and evaluation of the transformer model to segment the renal cortex, medulla, and collecting system remains challenging due to data inefficiency. Inspired by the hierarchical structures in vision transformer, we propose a novel method using a 3D block aggregation transformer for segmenting kidney components on contrast-enhanced CT scans. We construct the first cohort of renal substructures segmentation dataset with 116 subjects under institutional review board (IRB) approval. Our method yields the state-of-the-art performance (Dice of 0.8467) against the baseline approach of 0.8308 with the data-efficient design. The Pearson R achieves 0.9891 between the proposed method and manual standards and indicates the strong correlation and reproducibility for volumetric analysis. We extend the proposed method to the public KiTS dataset, the method leads to improved accuracy compared to transformer-based approaches. We show that the 3D block aggregation transformer can achieve local communication between sequence representations without modifying self-attention, and it can serve as an accurate and efficient quantification tool for characterizing renal structures.
Circle Representation for Medical Object Detection
Oct 22, 2021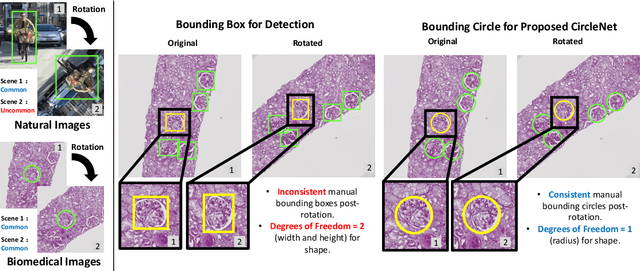
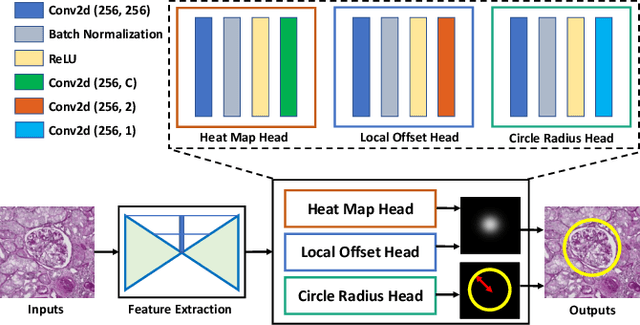
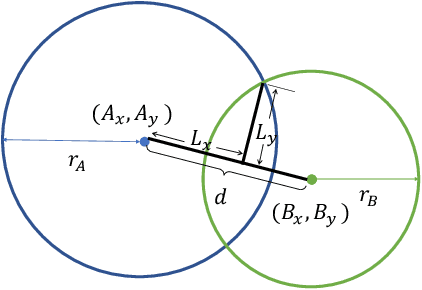
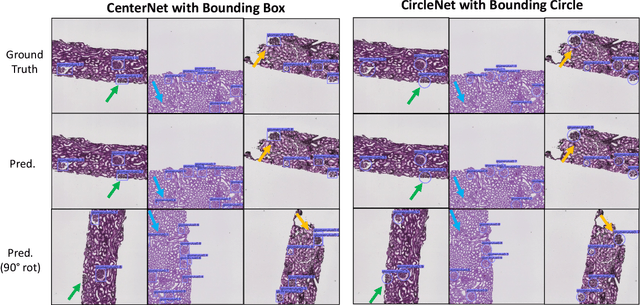
Box representation has been extensively used for object detection in computer vision. Such representation is efficacious but not necessarily optimized for biomedical objects (e.g., glomeruli), which play an essential role in renal pathology. In this paper, we propose a simple circle representation for medical object detection and introduce CircleNet, an anchor-free detection framework. Compared with the conventional bounding box representation, the proposed bounding circle representation innovates in three-fold: (1) it is optimized for ball-shaped biomedical objects; (2) The circle representation reduced the degree of freedom compared with box representation; (3) It is naturally more rotation invariant. When detecting glomeruli and nuclei on pathological images, the proposed circle representation achieved superior detection performance and be more rotation-invariant, compared with the bounding box. The code has been made publicly available: https://github.com/hrlblab/CircleNet
Random Multi-Channel Image Synthesis for Multiplexed Immunofluorescence Imaging
Sep 18, 2021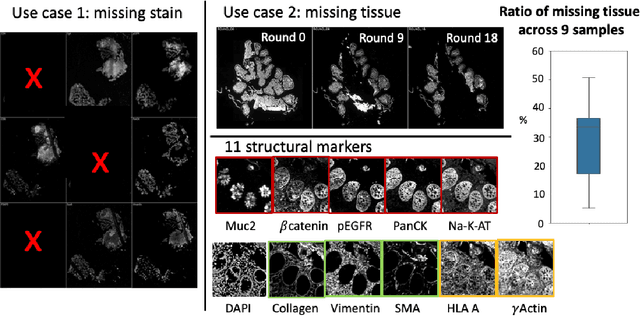
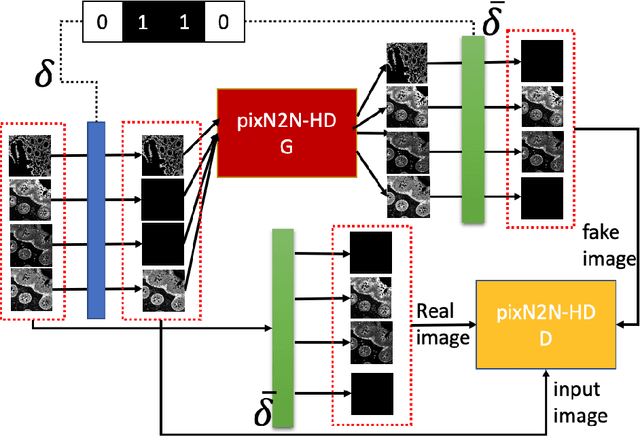
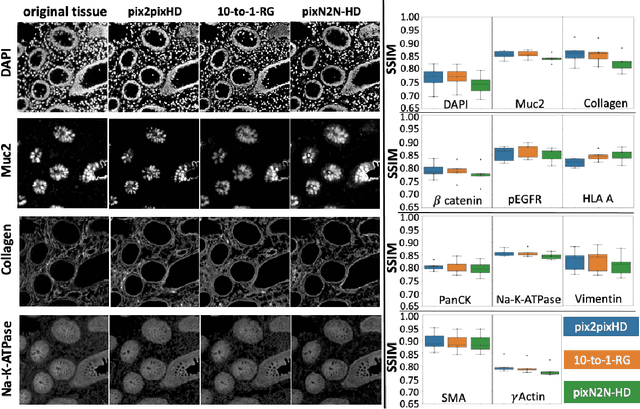
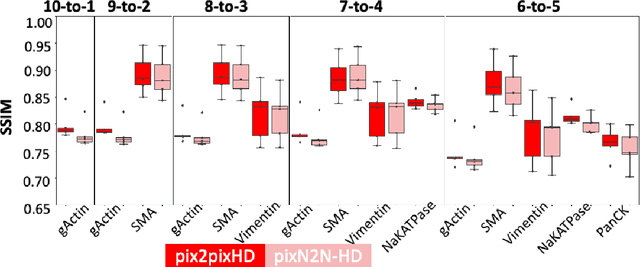
Multiplex immunofluorescence (MxIF) is an emerging imaging technique that produces the high sensitivity and specificity of single-cell mapping. With a tenet of 'seeing is believing', MxIF enables iterative staining and imaging extensive antibodies, which provides comprehensive biomarkers to segment and group different cells on a single tissue section. However, considerable depletion of the scarce tissue is inevitable from extensive rounds of staining and bleaching ('missing tissue'). Moreover, the immunofluorescence (IF) imaging can globally fail for particular rounds ('missing stain''). In this work, we focus on the 'missing stain' issue. It would be appealing to develop digital image synthesis approaches to restore missing stain images without losing more tissue physically. Herein, we aim to develop image synthesis approaches for eleven MxIF structural molecular markers (i.e., epithelial and stromal) on real samples. We propose a novel multi-channel high-resolution image synthesis approach, called pixN2N-HD, to tackle possible missing stain scenarios via a high-resolution generative adversarial network (GAN). Our contribution is three-fold: (1) a single deep network framework is proposed to tackle missing stain in MxIF; (2) the proposed 'N-to-N' strategy reduces theoretical four years of computational time to 20 hours when covering all possible missing stains scenarios, with up to five missing stains (e.g., '(N-1)-to-1', '(N-2)-to-2'); and (3) this work is the first comprehensive experimental study of investigating cross-stain synthesis in MxIF. Our results elucidate a promising direction of advancing MxIF imaging with deep image synthesis.