 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Latent Space of GAN Inversion for Real Image Editing
Jul 18, 2023



The exploration of the latent space in StyleGANs and GAN inversion exemplify impressive real-world image editing, yet the trade-off between reconstruction quality and editing quality remains an open problem. In this study, we revisit StyleGANs' hyperspherical prior $\mathcal{Z}$ and combine it with highly capable latent spaces to build combined spaces that faithfully invert real images while maintaining the quality of edited images. More specifically, we propose $\mathcal{F}/\mathcal{Z}^{+}$ space consisting of two subspaces: $\mathcal{F}$ space of an intermediate feature map of StyleGANs enabling faithful reconstruction and $\mathcal{Z}^{+}$ space of an extended StyleGAN prior supporting high editing quality. We project the real images into the proposed space to obtain the inverted codes, by which we then move along $\mathcal{Z}^{+}$, enabling semantic editing without sacrificing image quality. Comprehensive experiments show that $\mathcal{Z}^{+}$ can replace the most commonly-used $\mathcal{W}$, $\mathcal{W}^{+}$, and $\mathcal{S}$ spaces while preserving reconstruction quality, resulting in reduced distortion of edited images.
SINC: Self-Supervised In-Context Learning for Vision-Language Tasks
Jul 15, 2023



Large Pre-trained Transformers exhibit an intriguing capacity for in-context learning. Without gradient updates, these models can rapidly construct new predictors from demonstrations presented in the inputs. Recent works promote this ability in the vision-language domain by incorporating visual information into large language models that can already make in-context predictions. However, these methods could inherit issues in the language domain, such as template sensitivity and hallucination. Also, the scale of these language models raises a significant demand for computations, making learning and operating these models resource-intensive. To this end, we raise a question: ``How can we enable in-context learning for general models without being constrained on large language models?". To answer it, we propose a succinct and general framework, Self-supervised IN-Context learning (SINC), that introduces a meta-model to learn on self-supervised prompts consisting of tailored demonstrations. The learned models can be transferred to downstream tasks for making in-context predictions on-the-fly. Extensive experiments show that SINC outperforms gradient-based methods in various vision-language tasks under few-shot settings. Furthermore, the designs of SINC help us investigate the benefits of in-context learning across different tasks, and the analysis further reveals the essential components for the emergence of in-context learning in the vision-language domain.
Pave the Way to Grasp Anything: Transferring Foundation Models for Universal Pick-Place Robots
Jun 25, 2023



Improving the generalization capabilities of general-purpose robotic agents has long been a significant challenge actively pursued by research communities. Existing approaches often rely on collecting large-scale real-world robotic data, such as the RT-1 dataset. However, these approaches typically suffer from low efficiency, limiting their capability in open-domain scenarios with new objects, and diverse backgrounds. In this paper, we propose a novel paradigm that effectively leverages language-grounded segmentation masks generated by state-of-the-art foundation models, to address a wide range of pick-and-place robot manipulation tasks in everyday scenarios. By integrating precise semantics and geometries conveyed from masks into our multi-view policy model, our approach can perceive accurate object poses and enable sample-efficient learning. Besides, such design facilitates effective generalization for grasping new objects with similar shapes observed during training. Our approach consists of two distinct steps. First, we introduce a series of foundation models to accurately ground natural language demands across multiple tasks. Second, we develop a Multi-modal Multi-view Policy Model that incorporates inputs such as RGB images, semantic masks, and robot proprioception states to jointly predict precise and executable robot actions. Extensive real-world experiments conducted on a Franka Emika robot arm validate the effectiveness of our proposed paradigm. Real-world demos are shown in YouTube (https://www.youtube.com/watch?v=1m9wNzfp_4E ) and Bilibili (https://www.bilibili.com/video/BV178411Z7H2/ ).
Balancing Reconstruction and Editing Quality of GAN Inversion for Real Image Editing with StyleGAN Prior Latent Space
May 31, 2023The exploration of the latent space in StyleGANs and GAN inversion exemplify impressive real-world image editing, yet the trade-off between reconstruction quality and editing quality remains an open problem. In this study, we revisit StyleGANs' hyperspherical prior $\mathcal{Z}$ and $\mathcal{Z}^+$ and integrate them into seminal GAN inversion methods to improve editing quality. Besides faithful reconstruction, our extensions achieve sophisticated editing quality with the aid of the StyleGAN prior. We project the real images into the proposed space to obtain the inverted codes, by which we then move along $\mathcal{Z}^{+}$, enabling semantic editing without sacrificing image quality. Comprehensive experiments show that $\mathcal{Z}^{+}$ can replace the most commonly-used $\mathcal{W}$, $\mathcal{W}^{+}$, and $\mathcal{S}$ spaces while preserving reconstruction quality, resulting in reduced distortion of edited images.
AlphaBlock: Embodied Finetuning for Vision-Language Reasoning in Robot Manipulation
May 30, 2023



We propose a novel framework for learning high-level cognitive capabilities in robot manipulation tasks, such as making a smiley face using building blocks. These tasks often involve complex multi-step reasoning, presenting significant challenges due to the limited paired data connecting human instructions (e.g., making a smiley face) and robot actions (e.g., end-effector movement). Existing approaches relieve this challenge by adopting an open-loop paradigm decomposing high-level instructions into simple sub-task plans, and executing them step-by-step using low-level control models. However, these approaches are short of instant observations in multi-step reasoning, leading to sub-optimal results. To address this issue, we propose to automatically collect a cognitive robot dataset by Large Language Models (LLMs). The resulting dataset AlphaBlock consists of 35 comprehensive high-level tasks of multi-step text plans and paired observation sequences. To enable efficient data acquisition, we employ elaborated multi-round prompt designs that effectively reduce the burden of extensive human involvement. We further propose a closed-loop multi-modal embodied planning model that autoregressively generates plans by taking image observations as input. To facilitate effective learning, we leverage MiniGPT-4 with a frozen visual encoder and LLM, and finetune additional vision adapter and Q-former to enable fine-grained spatial perception for manipulation tasks. We conduct experiments to verify the superiority over existing open and closed-loop methods, and achieve a significant increase in success rate by 21.4% and 14.5% over ChatGPT and GPT-4 based robot tasks. Real-world demos are shown in https://www.youtube.com/watch?v=ayAzID1_qQk .
Whisper-KDQ: A Lightweight Whisper via Guided Knowledge Distillation and Quantization for Efficient ASR
May 18, 2023



Due to the rapid development of computing hardware resources and the dramatic growth of data, pre-trained models in speech recognition, such as Whisper, have significantly improved the performance of speech recognition tasks. However, these models usually have a high computational overhead, making it difficult to execute effectively on resource-constrained devices. To speed up inference and reduce model size while maintaining performance, we propose a novel guided knowledge distillation and quantization for large pre-trained model Whisper. The student model selects distillation and quantization layers based on quantization loss and distillation loss, respectively. We compressed $\text{Whisper}_\text{small}$ to $\text{Whisper}_\text{base}$ and $\text{Whisper}_\text{tiny}$ levels, making $\text{Whisper}_\text{small}$ 5.18x/10.48x smaller, respectively. Moreover, compared to the original $\text{Whisper}_\text{base}$ and $\text{Whisper}_\text{tiny}$, there is also a relative character error rate~(CER) reduction of 11.3% and 14.0% for the new compressed model respectively.
MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation
Dec 19, 2022We propose the first joint audio-video generation framework that brings engaging watching and listening experiences simultaneously, towards high-quality realistic videos. To generate joint audio-video pairs, we propose a novel Multi-Modal Diffusion model (i.e., MM-Diffusion), with two-coupled denoising autoencoders. In contrast to existing single-modal diffusion models, MM-Diffusion consists of a sequential multi-modal U-Net for a joint denoising process by design. Two subnets for audio and video learn to gradually generate aligned audio-video pairs from Gaussian noises. To ensure semantic consistency across modalities, we propose a novel random-shift based attention block bridging over the two subnets, which enables efficient cross-modal alignment, and thus reinforces the audio-video fidelity for each other. Extensive experiments show superior results in unconditional audio-video generation, and zero-shot conditional tasks (e.g., video-to-audio). In particular, we achieve the best FVD and FAD on Landscape and AIST++ dancing datasets. Turing tests of 10k votes further demonstrate dominant preferences for our model. The code and pre-trained models can be downloaded at https://github.com/researchmm/MM-Diffusion.
Build a SRE Challenge System: Lessons from VoxSRC 2022 and CNSRC 2022
Nov 02, 2022



Different speaker recognition challenges have been held to assess the speaker verification system in the wild and probe the performance limit. Voxceleb Speaker Recognition Challenge (VoxSRC), based on the voxceleb, is the most popular. Besides, another challenge called CN-Celeb Speaker Recognition Challenge (CNSRC) is also held this year, which is based on the Chinese celebrity multi-genre dataset CN-Celeb. This year, our team participated in both speaker verification closed tracks in CNSRC 2022 and VoxSRC 2022, and achieved the 1st place and 3rd place respectively. In most system reports, the authors usually only provide a description of their systems but lack an effective analysis of their methods. In this paper, we will outline how to build a strong speaker verification challenge system and give a detailed analysis of each method compared with some other popular technical means.
Long-Form Video-Language Pre-Training with Multimodal Temporal Contrastive Learning
Oct 12, 2022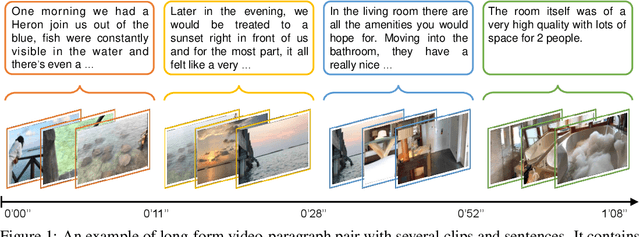
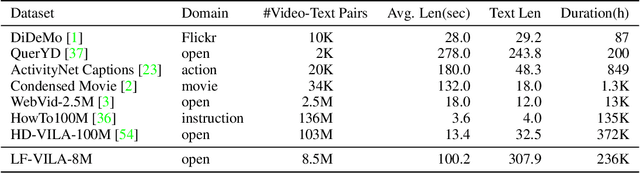
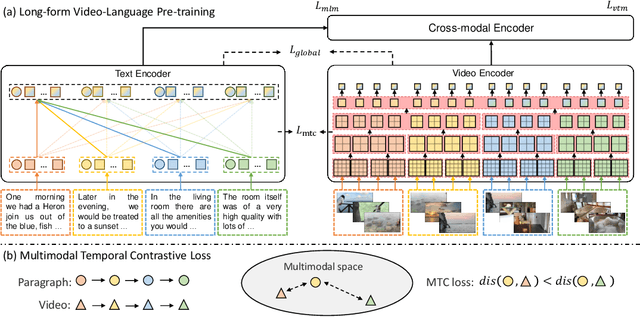
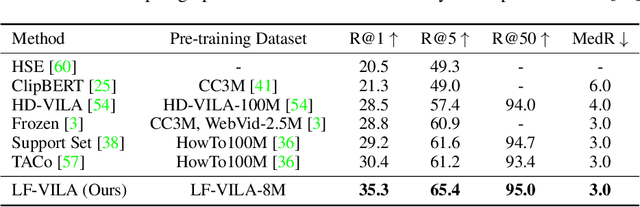
Large-scale video-language pre-training has shown significant improvement in video-language understanding tasks. Previous studies of video-language pretraining mainly focus on short-form videos (i.e., within 30 seconds) and sentences, leaving long-form video-language pre-training rarely explored. Directly learning representation from long-form videos and language may benefit many long-form video-language understanding tasks. However, it is challenging due to the difficulty of modeling long-range relationships and the heavy computational burden caused by more frames. In this paper, we introduce a Long-Form VIdeo-LAnguage pre-training model (LF-VILA) and train it on a large-scale long-form video and paragraph dataset constructed from an existing public dataset. To effectively capture the rich temporal dynamics and to better align video and language in an efficient end-to-end manner, we introduce two novel designs in our LF-VILA model. We first propose a Multimodal Temporal Contrastive (MTC) loss to learn the temporal relation across different modalities by encouraging fine-grained alignment between long-form videos and paragraphs. Second, we propose a Hierarchical Temporal Window Attention (HTWA) mechanism to effectively capture long-range dependency while reducing computational cost in Transformer. We fine-tune the pre-trained LF-VILA model on seven downstream long-form video-language understanding tasks of paragraph-to-video retrieval and long-form video question-answering, and achieve new state-of-the-art performances. Specifically, our model achieves 16.1% relative improvement on ActivityNet paragraph-to-video retrieval task and 2.4% on How2QA task, respectively. We release our code, dataset, and pre-trained models at https://github.com/microsoft/XPretrain.
CLIP-ViP: Adapting Pre-trained Image-Text Model to Video-Language Representation Alignment
Sep 23, 2022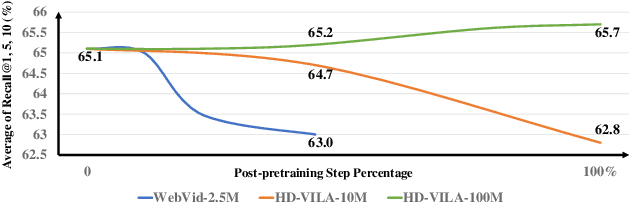
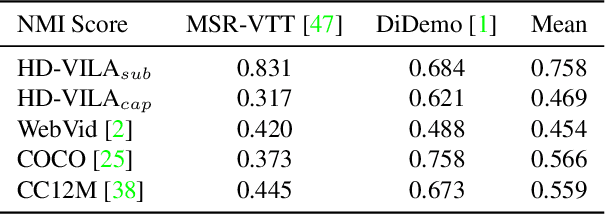
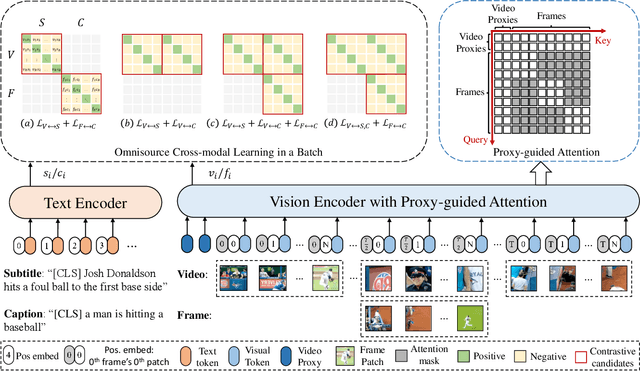
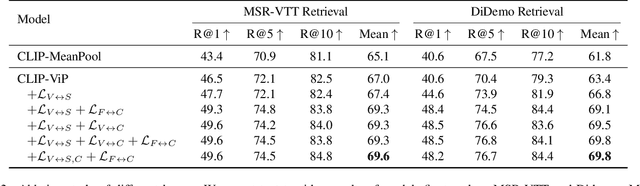
The pre-trained image-text models, like CLIP, have demonstrated the strong power of vision-language representation learned from a large scale of web-collected image-text data. In light of the well-learned visual features, some existing works transfer image representation to video domain and achieve good results. However, how to utilize image-language pre-trained model (e.g., CLIP) for video-language pre-training (post-pretraining) is still under explored. In this paper, we investigate two questions: 1) what are the factors hindering post-pretraining CLIP to further improve the performance on video-language tasks? and 2) how to mitigate the impact of these factors? Through a series of comparative experiments and analyses, we find that the data scale and domain gap between language sources have great impacts. Motivated by these, we propose a Omnisource Cross-modal Learning method equipped with a Video Proxy mechanism on the basis of CLIP, namely CLIP-ViP. Extensive results show that our approach improves the performance of CLIP on video-text retrieval by a large margin. Our model also achieves SOTA results on a variety of datasets, including MSR-VTT, DiDeMo, LSMDC, and ActivityNet. We will release our code and pre-trained CLIP-ViP models at https://github.com/microsoft/XPretrain/tree/main/CLIP-ViP.