 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional 3D Human-Object Neural Animation
Apr 27, 2023



Human-object interactions (HOIs) are crucial for human-centric scene understanding applications such as human-centric visual generation, AR/VR, and robotics. Since existing methods mainly explore capturing HOIs, rendering HOI remains less investigated. In this paper, we address this challenge in HOI animation from a compositional perspective, i.e., animating novel HOIs including novel interaction, novel human and/or novel object driven by a novel pose sequence. Specifically, we adopt neural human-object deformation to model and render HOI dynamics based on implicit neural representations. To enable the interaction pose transferring among different persons and objects, we then devise a new compositional conditional neural radiance field (or CC-NeRF), which decomposes the interdependence between human and object using latent codes to enable compositionally animation control of novel HOIs. Experiments show that the proposed method can generalize well to various novel HOI animation settings. Our project page is https://zhihou7.github.io/CHONA/
Pseudo Contrastive Learning for Graph-based Semi-supervised Learning
Feb 19, 2023



Pseudo Labeling is a technique used to improve the performance of semi-supervised Graph Neural Networks (GNNs) by generating additional pseudo-labels based on confident predictions. However, the quality of generated pseudo-labels has long been a concern due to the sensitivity of the classification objective to given labels. To avoid the untrustworthy classification supervision indicating ``a node belongs to a specific class,'' we favor the fault-tolerant contrasting supervision demonstrating ``two nodes do not belong to the same class.'' Thus, the problem of generating high-quality pseudo-labels is then transformed into a relaxed version, i.e., finding reliable contrasting pairs. To achieve this, we propose a general framework for GNNs, termed Pseudo Contrastive Learning (PCL). It separates two nodes whose positive and negative pseudo-labels target the same class. To incorporate topological knowledge into learning, we devise a topologically weighted contrastive loss that spends more effort separating negative pairs with smaller topological distances. Additionally, to alleviate the heavy reliance on data augmentation, we augment nodes only by applying dropout to the encoded representations. Theoretically, we prove that PCL with the lightweight augmentation works like a representation regularizer to effectively learn separation between negative pairs. Experimentally, we employ PCL on various models, which consistently outperform their counterparts using other popular general techniques on five real-world graphs.
PointWavelet: Learning in Spectral Domain for 3D Point Cloud Analysis
Feb 10, 2023With recent success of deep learning in 2D visual recognition, deep learning-based 3D point cloud analysis has received increasing attention from the community, especially due to the rapid development of autonomous driving technologies. However, most existing methods directly learn point features in the spatial domain, leaving the local structures in the spectral domain poorly investigated. In this paper, we introduce a new method, PointWavelet, to explore local graphs in the spectral domain via a learnable graph wavelet transform. Specifically, we first introduce the graph wavelet transform to form multi-scale spectral graph convolution to learn effective local structural representations. To avoid the time-consuming spectral decomposition, we then devise a learnable graph wavelet transform, which significantly accelerates the overall training process. Extensive experiments on four popular point cloud datasets, ModelNet40, ScanObjectNN, ShapeNet-Part, and S3DIS, demonstrate the effectiveness of the proposed method on point cloud classification and segmentation.
Toward Efficient Language Model Pretraining and Downstream Adaptation via Self-Evolution: A Case Study on SuperGLUE
Dec 04, 2022



This technical report briefly describes our JDExplore d-team's Vega v2 submission on the SuperGLUE leaderboard. SuperGLUE is more challenging than the widely used general language understanding evaluation (GLUE) benchmark, containing eight difficult language understanding tasks, including question answering, natural language inference, word sense disambiguation, coreference resolution, and reasoning. [Method] Instead of arbitrarily increasing the size of a pretrained language model (PLM), our aim is to 1) fully extract knowledge from the input pretraining data given a certain parameter budget, e.g., 6B, and 2) effectively transfer this knowledge to downstream tasks. To achieve goal 1), we propose self-evolution learning for PLMs to wisely predict the informative tokens that should be masked, and supervise the masked language modeling (MLM) process with rectified smooth labels. For goal 2), we leverage the prompt transfer technique to improve the low-resource tasks by transferring the knowledge from the foundation model and related downstream tasks to the target task. [Results] According to our submission record (Oct. 2022), with our optimized pretraining and fine-tuning strategies, our 6B Vega method achieved new state-of-the-art performance on 4/8 tasks, sitting atop the SuperGLUE leaderboard on Oct. 8, 2022, with an average score of 91.3.
Knowledge-Aware Federated Active Learning with Non-IID Data
Nov 24, 2022



Federated learning enables multiple decentralized clients to learn collaboratively without sharing the local training data. However, the expensive annotation cost to acquire data labels on local clients remains an obstacle in utilizing local data. In this paper, we propose a federated active learning paradigm to efficiently learn a global model with limited annotation budget while protecting data privacy in a decentralized learning way. The main challenge faced by federated active learning is the mismatch between the active sampling goal of the global model on the server and that of the asynchronous local clients. This becomes even more significant when data is distributed non-IID across local clients. To address the aforementioned challenge, we propose Knowledge-Aware Federated Active Learning (KAFAL), which consists of Knowledge-Specialized Active Sampling (KSAS) and Knowledge-Compensatory Federated Update (KCFU). KSAS is a novel active sampling method tailored for the federated active learning problem. It deals with the mismatch challenge by sampling actively based on the discrepancies between local and global models. KSAS intensifies specialized knowledge in local clients, ensuring the sampled data to be informative for both the local clients and the global model. KCFU, in the meantime, deals with the client heterogeneity caused by limited data and non-IID data distributions. It compensates for each client's ability in weak classes by the assistance of the global model. Extensive experiments and analyses are conducted to show the superiority of KSAS over the state-of-the-art active learning methods and the efficiency of KCFU under the federated active learning framework.
Responsible Active Learning via Human-in-the-loop Peer Study
Nov 24, 2022



Active learning has been proposed to reduce data annotation efforts by only manually labelling representative data samples for training. Meanwhile, recent active learning applications have benefited a lot from cloud computing services with not only sufficient computational resources but also crowdsourcing frameworks that include many humans in the active learning loop. However, previous active learning methods that always require passing large-scale unlabelled data to cloud may potentially raise significant data privacy issues. To mitigate such a risk, we propose a responsible active learning method, namely Peer Study Learning (PSL), to simultaneously preserve data privacy and improve model stability. Specifically, we first introduce a human-in-the-loop teacher-student architecture to isolate unlabelled data from the task learner (teacher) on the cloud-side by maintaining an active learner (student) on the client-side. During training, the task learner instructs the light-weight active learner which then provides feedback on the active sampling criterion. To further enhance the active learner via large-scale unlabelled data, we introduce multiple peer students into the active learner which is trained by a novel learning paradigm, including the In-Class Peer Study on labelled data and the Out-of-Class Peer Study on unlabelled data. Lastly, we devise a discrepancy-based active sampling criterion, Peer Study Feedback, that exploits the variability of peer students to select the most informative data to improve model stability. Extensive experiments demonstrate the superiority of the proposed PSL over a wide range of active learning methods in both standard and sensitive protection settings.
Domain-Specific Risk Minimization
Aug 23, 2022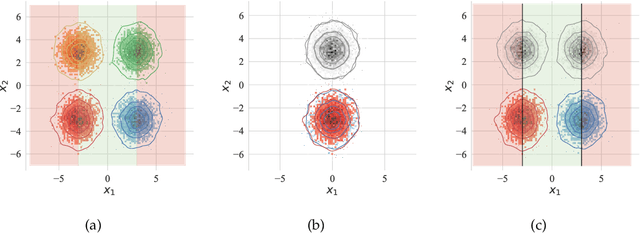
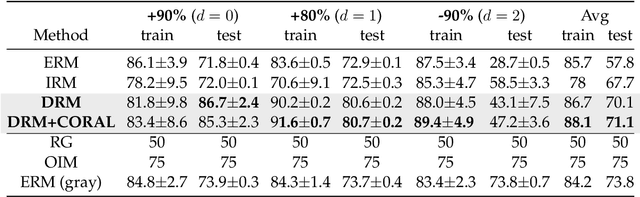
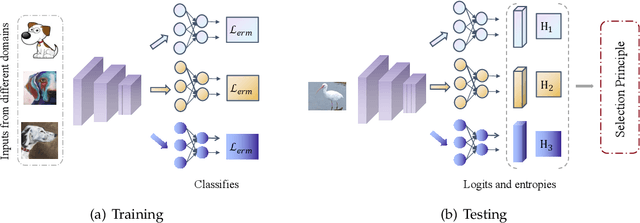
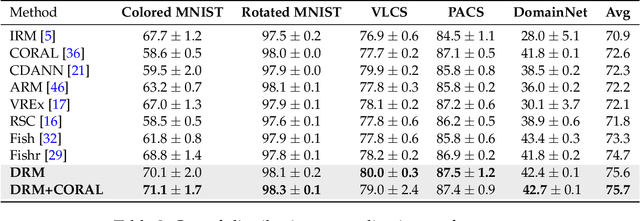
Learning a domain-invariant representation has become one of the most popular approaches for domain adaptation/generalization. In this paper, we show that the invariant representation may not be sufficient to guarantee a good generalization, where the labeling function shift should be taken into consideration. Inspired by this, we first derive a new generalization upper bound on the empirical risk that explicitly considers the labeling function shift. We then propose Domain-specific Risk Minimization (DRM), which can model the distribution shifts of different domains separately and select the most appropriate one for the target domain. Extensive experiments on four popular domain generalization datasets, CMNIST, PACS, VLCS, and DomainNet, demonstrate the effectiveness of the proposed DRM for domain generalization with the following advantages: 1) it significantly outperforms competitive baselines; 2) it enables either comparable or superior accuracies on all training domains comparing to vanilla empirical risk minimization (ERM); 3) it remains very simple and efficient during training, and 4) it is complementary to invariant learning approaches.
Improving Fine-Grained Visual Recognition in Low Data Regimes via Self-Boosting Attention Mechanism
Aug 01, 2022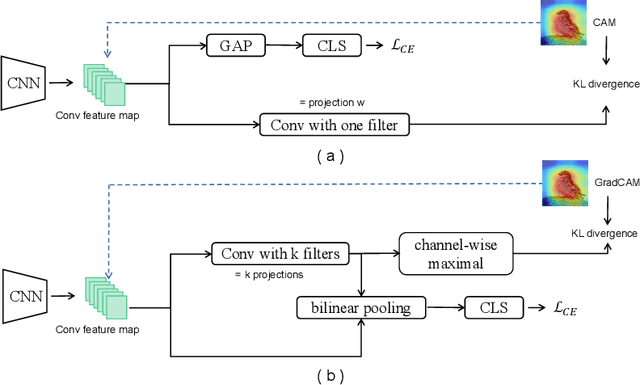
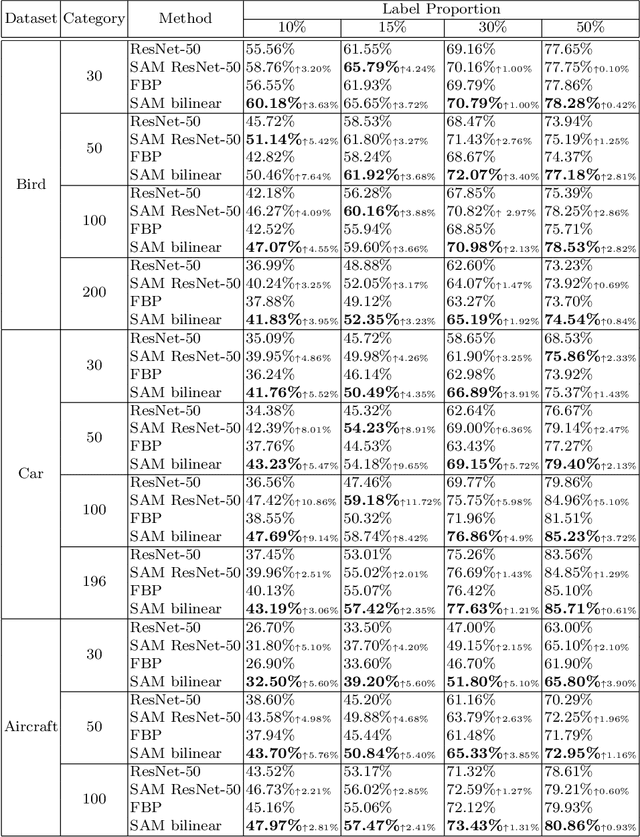
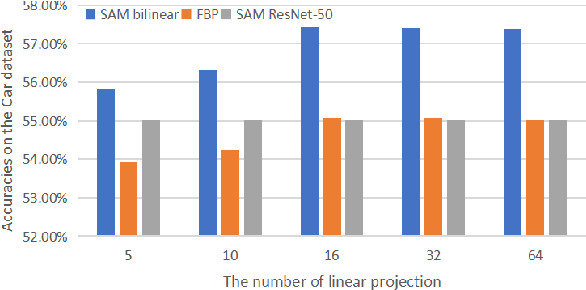
The challenge of fine-grained visual recognition often lies in discovering the key discriminative regions. While such regions can be automatically identified from a large-scale labeled dataset, a similar method might become less effective when only a few annotations are available. In low data regimes, a network often struggles to choose the correct regions for recognition and tends to overfit spurious correlated patterns from the training data. To tackle this issue, this paper proposes the self-boosting attention mechanism, a novel method for regularizing the network to focus on the key regions shared across samples and classes. Specifically, the proposed method first generates an attention map for each training image, highlighting the discriminative part for identifying the ground-truth object category. Then the generated attention maps are used as pseudo-annotations. The network is enforced to fit them as an auxiliary task. We call this approach the self-boosting attention mechanism (SAM). We also develop a variant by using SAM to create multiple attention maps to pool convolutional maps in a style of bilinear pooling, dubbed SAM-Bilinear. Through extensive experimental studies, we show that both methods can significantly improve fine-grained visual recognition performance on low data regimes and can be incorporated into existing network architectures. The source code is publicly available at: https://github.com/GANPerf/SAM
MeshMAE: Masked Autoencoders for 3D Mesh Data Analysis
Jul 20, 2022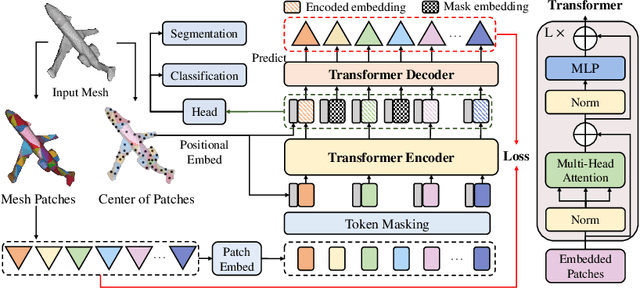
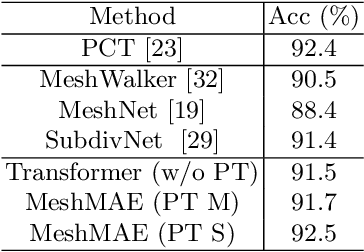
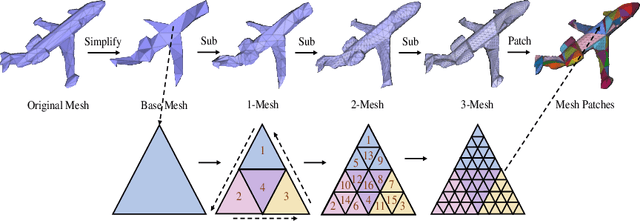
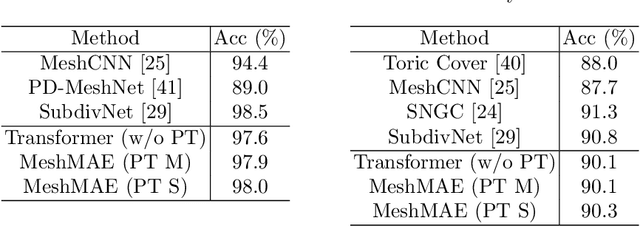
Recently, self-supervised pre-training has advanced Vision Transformers on various tasks w.r.t. different data modalities, e.g., image and 3D point cloud data. In this paper, we explore this learning paradigm for 3D mesh data analysis based on Transformers. Since applying Transformer architectures to new modalities is usually non-trivial, we first adapt Vision Transformer to 3D mesh data processing, i.e., Mesh Transformer. In specific, we divide a mesh into several non-overlapping local patches with each containing the same number of faces and use the 3D position of each patch's center point to form positional embeddings. Inspired by MAE, we explore how pre-training on 3D mesh data with the Transformer-based structure benefits downstream 3D mesh analysis tasks. We first randomly mask some patches of the mesh and feed the corrupted mesh into Mesh Transformers. Then, through reconstructing the information of masked patches, the network is capable of learning discriminative representations for mesh data. Therefore, we name our method MeshMAE, which can yield state-of-the-art or comparable performance on mesh analysis tasks, i.e., classification and segmentation. In addition, we also conduct comprehensive ablation studies to show the effectiveness of key designs in our method.
Deep Dictionary Learning with An Intra-class Constraint
Jul 14, 2022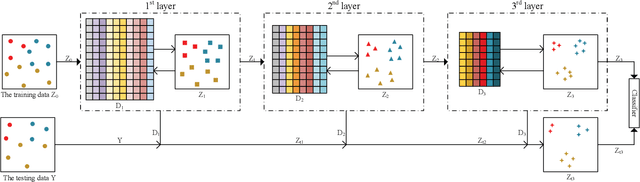
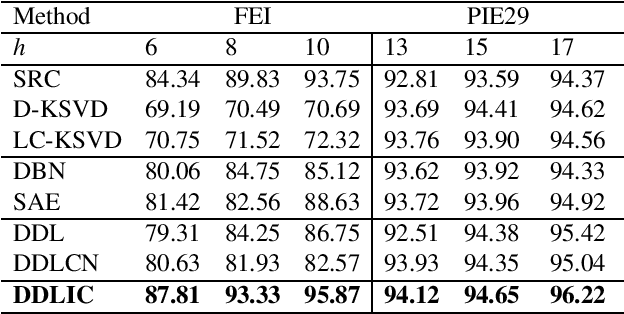
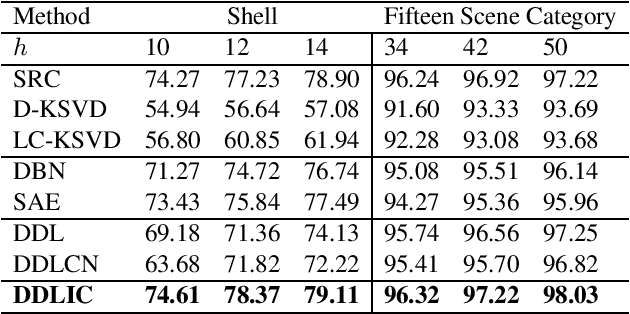
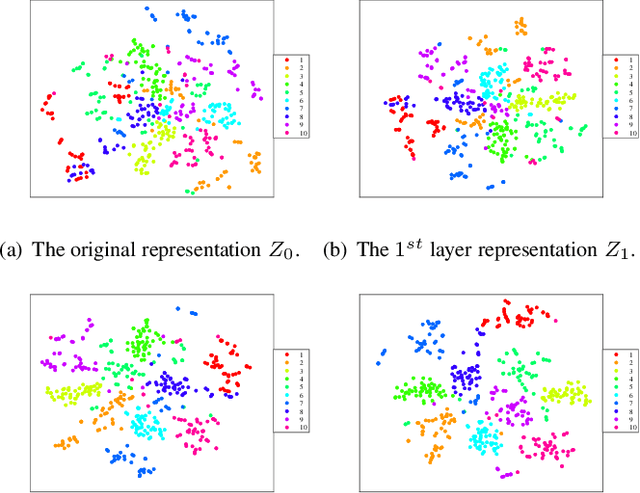
In recent years, deep dictionary learning (DDL)has attracted a great amount of attention due to its effectiveness for representation learning and visual recognition.~However, most existing methods focus on unsupervised deep dictionary learning, failing to further explore the category information.~To make full use of the category information of different samples, we propose a novel deep dictionary learning model with an intra-class constraint (DDLIC) for visual classification. Specifically, we design the intra-class compactness constraint on the intermediate representation at different levels to encourage the intra-class representations to be closer to each other, and eventually the learned representation becomes more discriminative.~Unlike the traditional DDL methods, during the classification stage, our DDLIC performs a layer-wise greedy optimization in a similar way to the training stage. Experimental results on four image datasets show that our method is superior to the state-of-the-art methods.