 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Software Engineering Agents Through the Lens of Traceability: An Empirical Study
Jun 10, 2025



With the advent of large language models (LLMs), software engineering agents (SWE agents) have emerged as a powerful paradigm for automating a range of software tasks -- from code generation and repair to test case synthesis. These agents operate autonomously by interpreting user input and responding to environmental feedback. While various agent architectures have demonstrated strong empirical performance, the internal decision-making worfklows that drive their behavior remain poorly understood. Deeper insight into these workflows hold promise for improving both agent reliability and efficiency. In this work, we present the first systematic study of SWE agent behavior through the lens of execution traces. Our contributions are as follows: (1) we propose the first taxonomy of decision-making pathways across five representative agents; (2) using this taxonomy, we identify three core components essential to agent success -- bug localization, patch generation, and reproduction test generation -- and study each in depth; (3) we study the impact of test generation on successful patch production; and analyze strategies that can lead to successful test generation; (4) we further conduct the first large-scale code clone analysis comparing agent-generated and developer-written patches and provide a qualitative study revealing structural and stylistic differences in patch content. Together, these findings offer novel insights into agent design and open avenues for building agents that are both more effective and more aligned with human development practices.
SeaView: Software Engineering Agent Visual Interface for Enhanced Workflow
Apr 14, 2025



Auto-regressive LLM-based software engineering (SWE) agents, henceforth SWE agents, have made tremendous progress (>60% on SWE-Bench Verified) on real-world coding challenges including GitHub issue resolution. SWE agents use a combination of reasoning, environment interaction and self-reflection to resolve issues thereby generating "trajectories". Analysis of SWE agent trajectories is difficult, not only as they exceed LLM sequence length (sometimes, greater than 128k) but also because it involves a relatively prolonged interaction between an LLM and the environment managed by the agent. In case of an agent error, it can be hard to decipher, locate and understand its scope. Similarly, it can be hard to track improvements or regression over multiple runs or experiments. While a lot of research has gone into making these SWE agents reach state-of-the-art, much less focus has been put into creating tools to help analyze and visualize agent output. We propose a novel tool called SeaView: Software Engineering Agent Visual Interface for Enhanced Workflow, with a vision to assist SWE-agent researchers to visualize and inspect their experiments. SeaView's novel mechanisms help compare experimental runs with varying hyper-parameters or LLMs, and quickly get an understanding of LLM or environment related problems. Based on our user study, experienced researchers spend between 10 and 30 minutes to gather the information provided by SeaView, while researchers with little experience can spend between 30 minutes to 1 hour to diagnose their experiment.
Ansible Lightspeed: A Code Generation Service for IT Automation
Feb 27, 2024



The availability of Large Language Models (LLMs) which can generate code, has made it possible to create tools that improve developer productivity. Integrated development environments or IDEs which developers use to write software are often used as an interface to interact with LLMs. Although many such tools have been released, almost all of them focus on general-purpose programming languages. Domain-specific languages, such as those crucial for IT automation, have not received much attention. Ansible is one such YAML-based IT automation-specific language. Red Hat Ansible Lightspeed with IBM Watson Code Assistant, further referred to as Ansible Lightspeed, is an LLM-based service designed explicitly for natural language to Ansible code generation. In this paper, we describe the design and implementation of the Ansible Lightspeed service and analyze feedback from thousands of real users. We examine diverse performance indicators, classified according to both immediate and extended utilization patterns along with user sentiments. The analysis shows that the user acceptance rate of Ansible Lightspeed suggestions is higher than comparable tools that are more general and not specific to a programming language. This remains true even after we use much more stringent criteria for what is considered an accepted model suggestion, discarding suggestions which were heavily edited after being accepted. The relatively high acceptance rate results in higher-than-expected user retention and generally positive user feedback. This paper provides insights on how a comparatively small, dedicated model performs on a domain-specific language and more importantly, how it is received by users.
Learning Transfers over Several Programming Languages
Oct 25, 2023



Large language models (LLMs) have recently become remarkably good at improving developer productivity for high-resource programming languages. These models use two kinds of data: large amounts of unlabeled code samples for pretraining and relatively smaller amounts of labeled code samples for fine-tuning or in-context learning. Unfortunately, many programming languages are low-resource, lacking labeled samples for most tasks and often even lacking unlabeled samples. Therefore, users of low-resource languages (e.g., legacy or new languages) miss out on the benefits of LLMs. Cross-lingual transfer learning uses data from a source language to improve model performance on a target language. It has been well-studied for natural languages, but has received little attention for programming languages. This paper reports extensive experiments on four tasks using a transformer-based LLM and 11 to 41 programming languages to explore the following questions. First, how well cross-lingual transfer works for a given task across different language pairs. Second, given a task and target language, how to best choose a source language. Third, the characteristics of a language pair that are predictive of transfer performance, and fourth, how that depends on the given task.
Beyond Accuracy: Evaluating Self-Consistency of Code Large Language Models with IdentityChain
Oct 21, 2023



Code Large Language Models (Code LLMs) are being increasingly employed in real-life applications, so evaluating them is critical. While the general accuracy of Code LLMs on individual tasks has been extensively evaluated, their self-consistency across different tasks is overlooked. Intuitively, a trustworthy model should be self-consistent when generating natural language specifications for its own code and generating code for its own specifications. Failure to preserve self-consistency reveals a lack of understanding of the shared semantics underlying natural language and programming language, and therefore undermines the trustworthiness of a model. In this paper, we first formally define the self-consistency of Code LLMs and then design a framework, IdentityChain, which effectively and efficiently evaluates the self-consistency and general accuracy of a model at the same time. We study eleven Code LLMs and show that they fail to preserve self-consistency, which is indeed a distinct aspect from general accuracy. Furthermore, we show that IdentityChain can be used as a model debugging tool to expose weaknesses of Code LLMs by demonstrating three major weaknesses that we identify in current models using IdentityChain. Our code is available at https://github.com/marcusm117/IdentityChain.
Automated Code generation for Information Technology Tasks in YAML through Large Language Models
May 05, 2023



The recent improvement in code generation capabilities due to the use of large language models has mainly benefited general purpose programming languages. Domain specific languages, such as the ones used for IT Automation, have received far less attention, despite involving many active developers and being an essential component of modern cloud platforms. This work focuses on the generation of Ansible-YAML, a widely used markup language for IT Automation. We present Ansible Wisdom, a natural-language to Ansible-YAML code generation tool, aimed at improving IT automation productivity. Ansible Wisdom is a transformer-based model, extended by training with a new dataset containing Ansible-YAML. We also develop two novel performance metrics for YAML and Ansible to capture the specific characteristics of this domain. Results show that Ansible Wisdom can accurately generate Ansible script from natural language prompts with performance comparable or better than existing state of the art code generation models.
Contrastive Learning for Source Code with Structural and Functional Properties
Oct 08, 2021
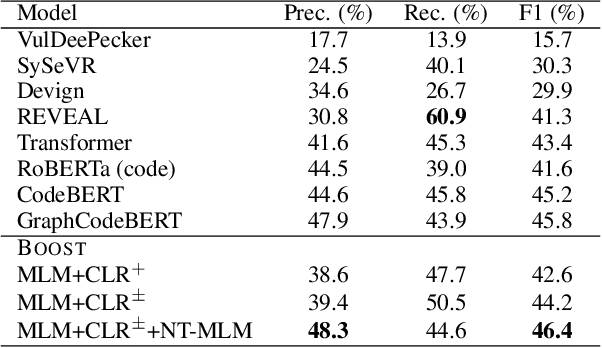
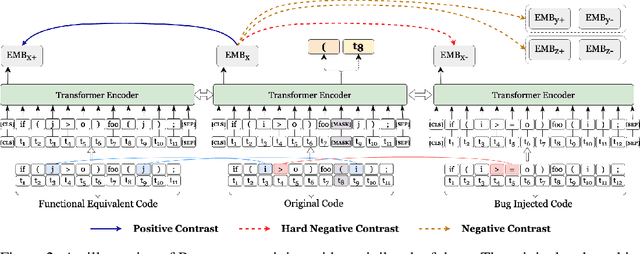

Pre-trained transformer models have recently shown promises for understanding the source code. Most existing works expect to understand code from the textual features and limited structural knowledge of code. However, the program functionalities sometimes cannot be fully revealed by the code sequence, even with structure information. Programs can contain very different tokens and structures while sharing the same functionality, but changing only one or a few code tokens can introduce unexpected or malicious program behaviors while preserving the syntax and most tokens. In this work, we present BOOST, a novel self-supervised model to focus pre-training based on the characteristics of source code. We first employ automated, structure-guided code transformation algorithms that generate (i.) functionally equivalent code that looks drastically different from the original one, and (ii.) textually and syntactically very similar code that is functionally distinct from the original. We train our model in a way that brings the functionally equivalent code closer and distinct code further through a contrastive learning objective. To encode the structure information, we introduce a new node-type masked language model objective that helps the model learn about structural context. We pre-train BOOST with a much smaller dataset than the state-of-the-art models, but our small models can still match or outperform these large models in code understanding and generation tasks.
Project CodeNet: A Large-Scale AI for Code Dataset for Learning a Diversity of Coding Tasks
May 25, 2021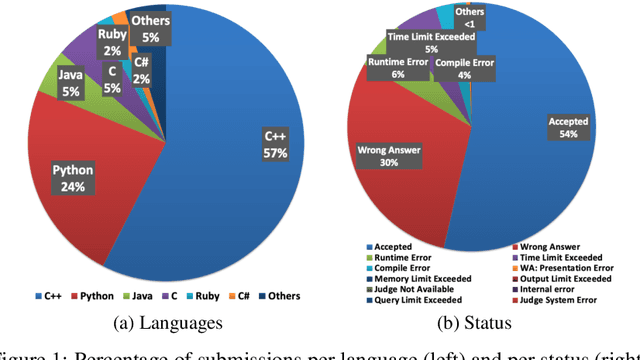
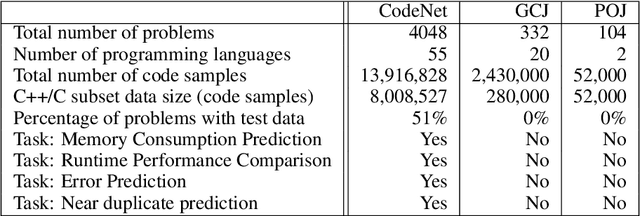
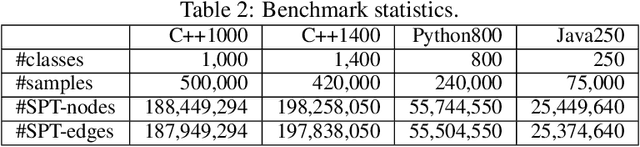
Advancements in deep learning and machine learning algorithms have enabled breakthrough progress in computer vision, speech recognition, natural language processing and beyond. In addition, over the last several decades, software has been built into the fabric of every aspect of our society. Together, these two trends have generated new interest in the fast-emerging research area of AI for Code. As software development becomes ubiquitous across all industries and code infrastructure of enterprise legacy applications ages, it is more critical than ever to increase software development productivity and modernize legacy applications. Over the last decade, datasets like ImageNet, with its large scale and diversity, have played a pivotal role in algorithmic advancements from computer vision to language and speech understanding. In this paper, we present Project CodeNet, a first-of-its-kind, very large scale, diverse, and high-quality dataset to accelerate the algorithmic advancements in AI for Code. It consists of 14M code samples and about 500M lines of code in 55 different programming languages. Project CodeNet is not only unique in its scale, but also in the diversity of coding tasks it can help benchmark: from code similarity and classification for advances in code recommendation algorithms, and code translation between a large variety programming languages, to advances in code performance (both runtime, and memory) improvement techniques. CodeNet also provides sample input and output test sets for over 7M code samples, which can be critical for determining code equivalence in different languages. As a usability feature, we provide several preprocessing tools in Project CodeNet to transform source codes into representations that can be readily used as inputs into machine learning models.
D2A: A Dataset Built for AI-Based Vulnerability Detection Methods Using Differential Analysis
Feb 16, 2021
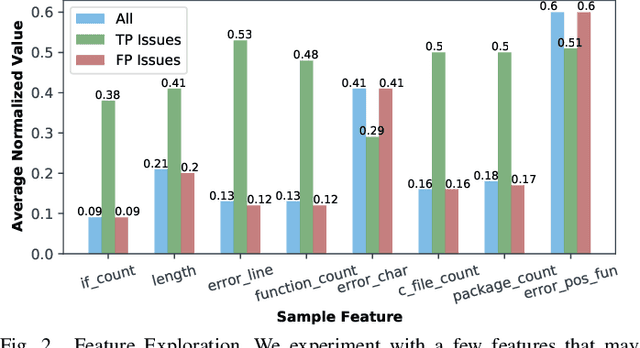


Static analysis tools are widely used for vulnerability detection as they understand programs with complex behavior and millions of lines of code. Despite their popularity, static analysis tools are known to generate an excess of false positives. The recent ability of Machine Learning models to understand programming languages opens new possibilities when applied to static analysis. However, existing datasets to train models for vulnerability identification suffer from multiple limitations such as limited bug context, limited size, and synthetic and unrealistic source code. We propose D2A, a differential analysis based approach to label issues reported by static analysis tools. The D2A dataset is built by analyzing version pairs from multiple open source projects. From each project, we select bug fixing commits and we run static analysis on the versions before and after such commits. If some issues detected in a before-commit version disappear in the corresponding after-commit version, they are very likely to be real bugs that got fixed by the commit. We use D2A to generate a large labeled dataset to train models for vulnerability identification. We show that the dataset can be used to build a classifier to identify possible false alarms among the issues reported by static analysis, hence helping developers prioritize and investigate potential true positives first.
Exploring Software Naturalness through Neural Language Models
Jun 24, 2020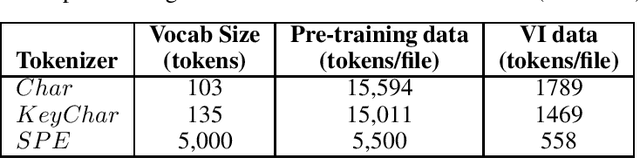
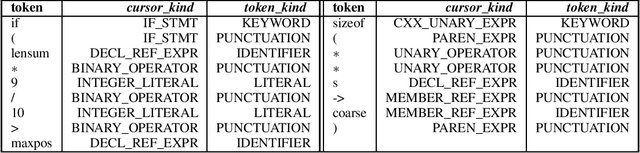
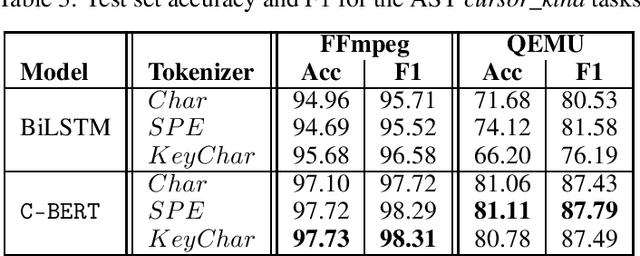
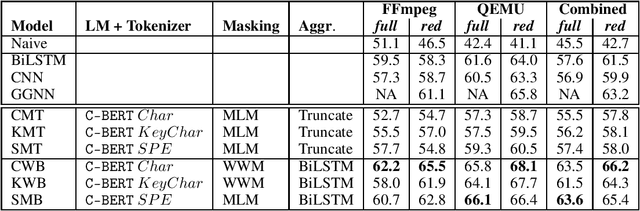
The Software Naturalness hypothesis argues that programming languages can be understood through the same techniques used in natural language processing. We explore this hypothesis through the use of a pre-trained transformer-based language model to perform code analysis tasks. Present approaches to code analysis depend heavily on features derived from the Abstract Syntax Tree (AST) while our transformer-based language models work on raw source code. This work is the first to investigate whether such language models can discover AST features automatically. To achieve this, we introduce a sequence labeling task that directly probes the language models understanding of AST. Our results show that transformer based language models achieve high accuracy in the AST tagging task. Furthermore, we evaluate our model on a software vulnerability identification task. Importantly, we show that our approach obtains vulnerability identification results comparable to graph based approaches that rely heavily on compilers for feature extraction.