 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchNets: Patch-Based Generalizable Deep Implicit 3D Shape Representations
Aug 04, 2020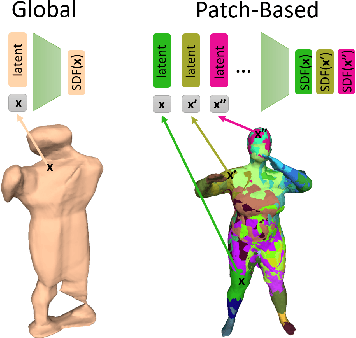
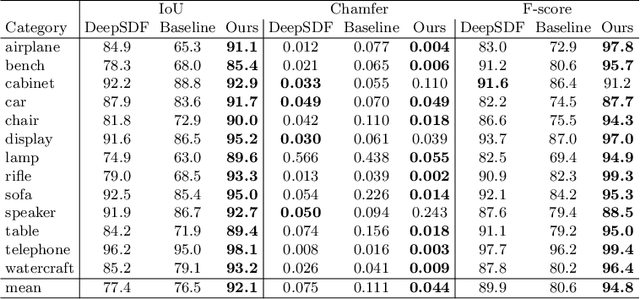

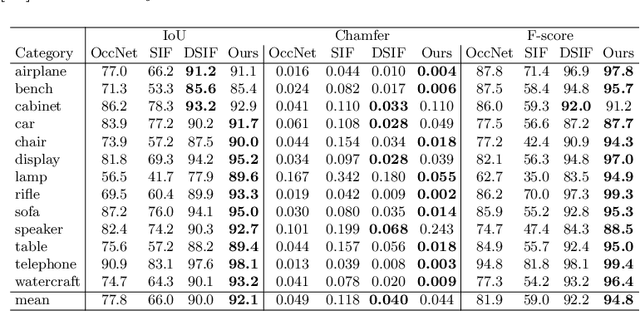
Implicit surface representations, such as signed-distance functions, combined with deep learning have led to impressive models which can represent detailed shapes of objects with arbitrary topology. Since a continuous function is learned, the reconstructions can also be extracted at any arbitrary resolution. However, large datasets such as ShapeNet are required to train such models. In this paper, we present a new mid-level patch-based surface representation. At the level of patches, objects across different categories share similarities, which leads to more generalizable models. We then introduce a novel method to learn this patch-based representation in a canonical space, such that it is as object-agnostic as possible. We show that our representation trained on one category of objects from ShapeNet can also well represent detailed shapes from any other category. In addition, it can be trained using much fewer shapes, compared to existing approaches. We show several applications of our new representation, including shape interpolation and partial point cloud completion. Due to explicit control over positions, orientations and scales of patches, our representation is also more controllable compared to object-level representations, which enables us to deform encoded shapes non-rigidly.
State of the Art on Neural Rendering
Apr 08, 2020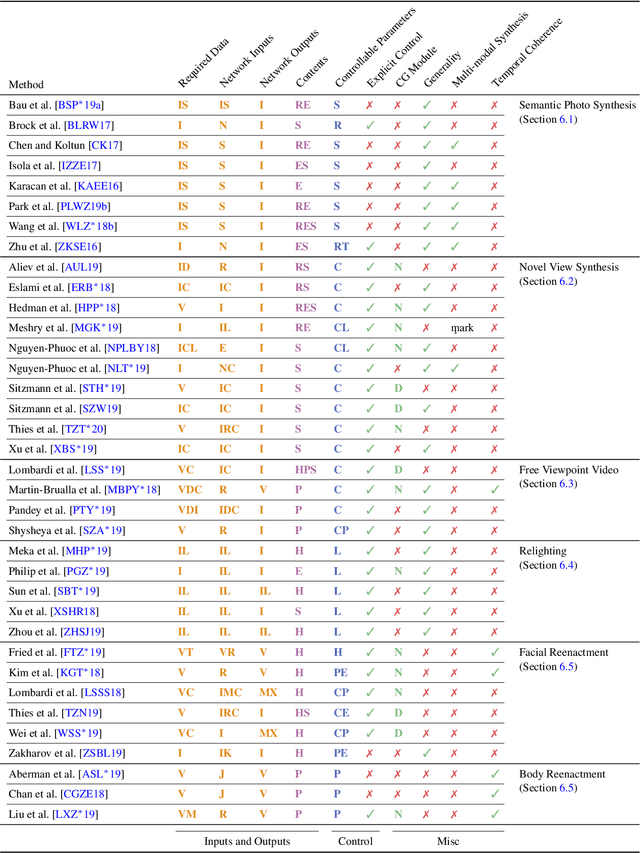



Efficient rendering of photo-realistic virtual worlds is a long standing effort of computer graphics. Modern graphics techniques have succeeded in synthesizing photo-realistic images from hand-crafted scene representations. However, the automatic generation of shape, materials, lighting, and other aspects of scenes remains a challenging problem that, if solved, would make photo-realistic computer graphics more widely accessible. Concurrently, progress in computer vision and machine learning have given rise to a new approach to image synthesis and editing, namely deep generative models. Neural rendering is a new and rapidly emerging field that combines generative machine learning techniques with physical knowledge from computer graphics, e.g., by the integration of differentiable rendering into network training. With a plethora of applications in computer graphics and vision, neural rendering is poised to become a new area in the graphics community, yet no survey of this emerging field exists. This state-of-the-art report summarizes the recent trends and applications of neural rendering. We focus on approaches that combine classic computer graphics techniques with deep generative models to obtain controllable and photo-realistic outputs. Starting with an overview of the underlying computer graphics and machine learning concepts, we discuss critical aspects of neural rendering approaches. This state-of-the-art report is focused on the many important use cases for the described algorithms such as novel view synthesis, semantic photo manipulation, facial and body reenactment, relighting, free-viewpoint video, and the creation of photo-realistic avatars for virtual and augmented reality telepresence. Finally, we conclude with a discussion of the social implications of such technology and investigate open research problems.
StyleRig: Rigging StyleGAN for 3D Control over Portrait Images
Mar 31, 2020
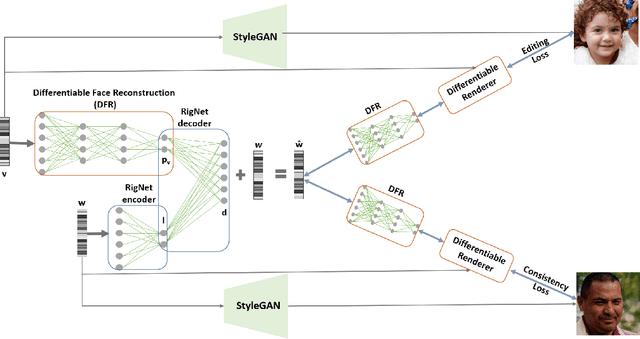
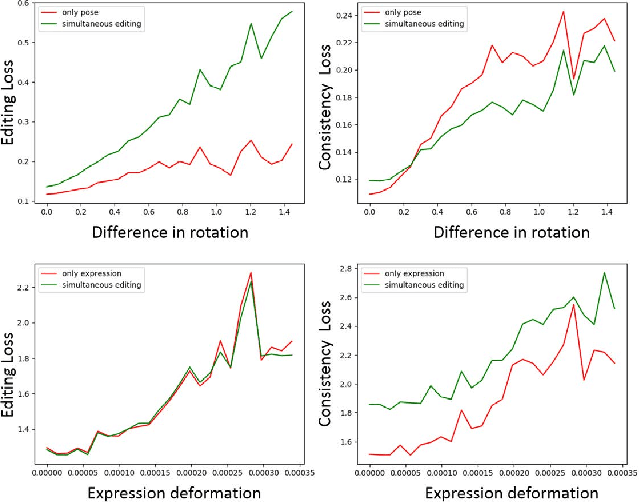

StyleGAN generates photorealistic portrait images of faces with eyes, teeth, hair and context (neck, shoulders, background), but lacks a rig-like control over semantic face parameters that are interpretable in 3D, such as face pose, expressions, and scene illumination. Three-dimensional morphable face models (3DMMs) on the other hand offer control over the semantic parameters, but lack photorealism when rendered and only model the face interior, not other parts of a portrait image (hair, mouth interior, background). We present the first method to provide a face rig-like control over a pretrained and fixed StyleGAN via a 3DMM. A new rigging network, RigNet is trained between the 3DMM's semantic parameters and StyleGAN's input. The network is trained in a self-supervised manner, without the need for manual annotations. At test time, our method generates portrait images with the photorealism of StyleGAN and provides explicit control over the 3D semantic parameters of the face.
Neural Voice Puppetry: Audio-driven Facial Reenactment
Dec 11, 2019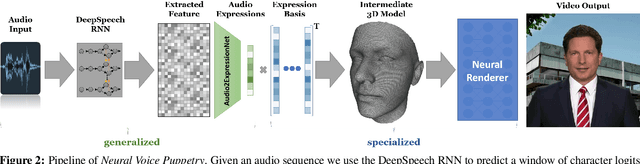
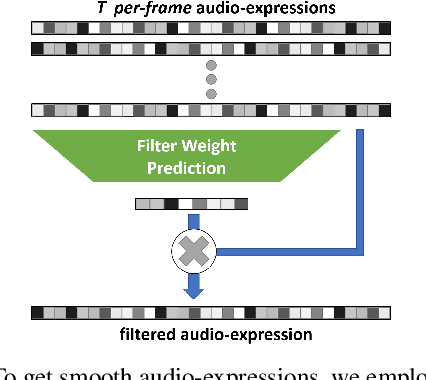

We present Neural Voice Puppetry, a novel approach for audio-driven facial video synthesis. Given an audio sequence of a source person or digital assistant, we generate a photo-realistic output video of a target person that is in sync with the audio of the source input. This audio-driven facial reenactment is driven by a deep neural network that employs a latent 3D face model space. Through the underlying 3D representation, the model inherently learns temporal stability while we leverage neural rendering to generate photo-realistic output frames. Our approach generalizes across different people, allowing us to synthesize videos of a target actor with the voice of any unknown source actor or even synthetic voices that can be generated utilizing standard text-to-speech approaches. Neural Voice Puppetry has a variety of use-cases, including audio-driven video avatars, video dubbing, and text-driven video synthesis of a talking head. We demonstrate the capabilities of our method in a series of audio- and text-based puppetry examples. Our method is not only more general than existing works since we are generic to the input person, but we also show superior visual and lip sync quality compared to photo-realistic audio- and video-driven reenactment techniques.
3D Morphable Face Models -- Past, Present and Future
Sep 03, 2019
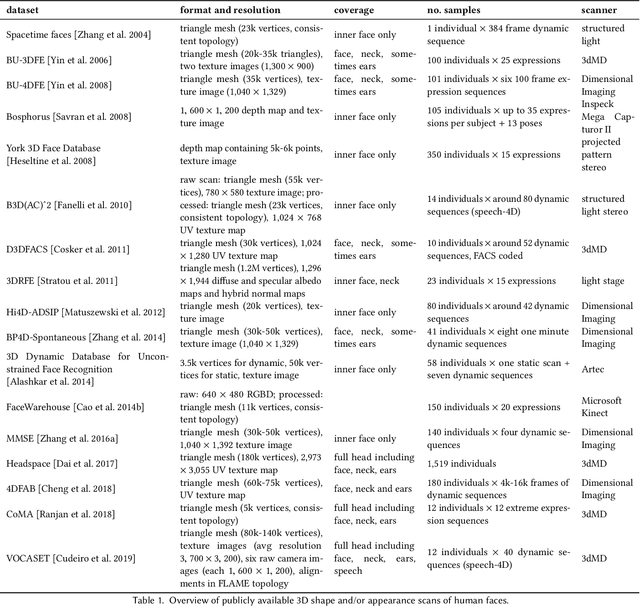
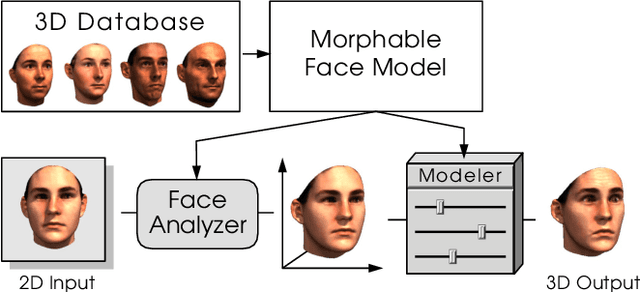
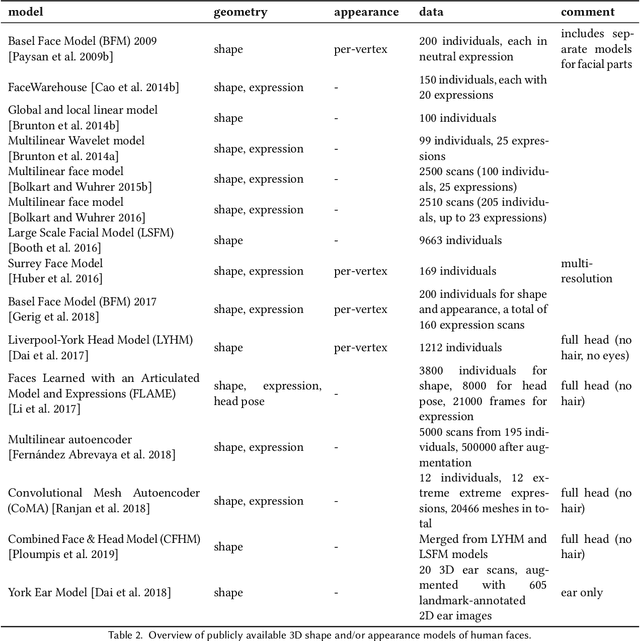
In this paper, we provide a detailed survey of 3D Morphable Face Models over the 20 years since they were first proposed. The challenges in building and applying these models, namely capture, modeling, image formation, and image analysis, are still active research topics, and we review the state-of-the-art in each of these areas. We also look ahead, identifying unsolved challenges, proposing directions for future research and highlighting the broad range of current and future applications.
Text-based Editing of Talking-head Video
Jun 04, 2019
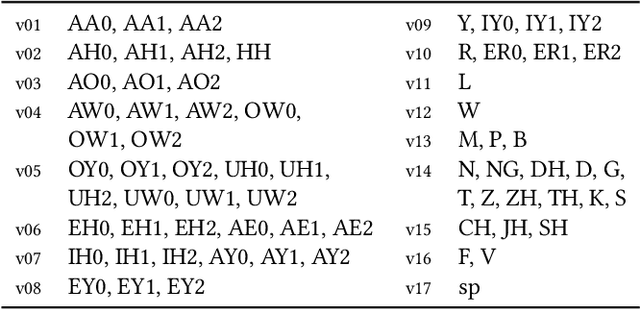
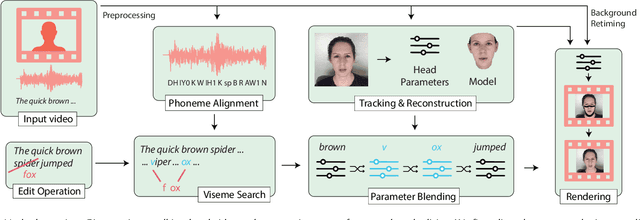
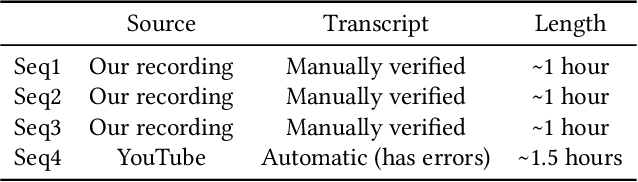
Editing talking-head video to change the speech content or to remove filler words is challenging. We propose a novel method to edit talking-head video based on its transcript to produce a realistic output video in which the dialogue of the speaker has been modified, while maintaining a seamless audio-visual flow (i.e. no jump cuts). Our method automatically annotates an input talking-head video with phonemes, visemes, 3D face pose and geometry, reflectance, expression and scene illumination per frame. To edit a video, the user has to only edit the transcript, and an optimization strategy then chooses segments of the input corpus as base material. The annotated parameters corresponding to the selected segments are seamlessly stitched together and used to produce an intermediate video representation in which the lower half of the face is rendered with a parametric face model. Finally, a recurrent video generation network transforms this representation to a photorealistic video that matches the edited transcript. We demonstrate a large variety of edits, such as the addition, removal, and alteration of words, as well as convincing language translation and full sentence synthesis.
EgoFace: Egocentric Face Performance Capture and Videorealistic Reenactment
May 26, 2019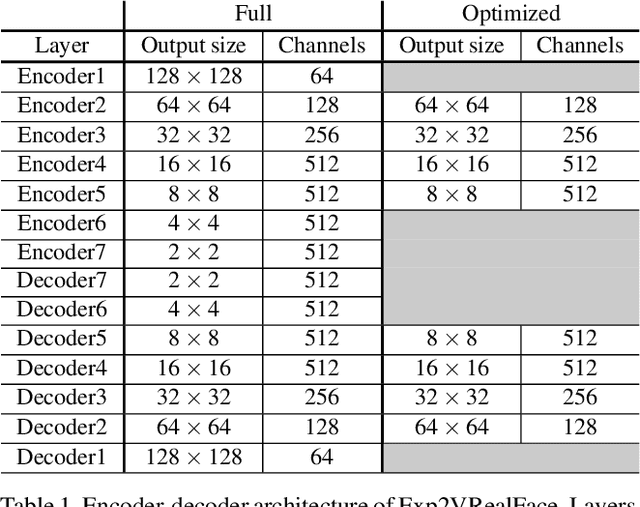
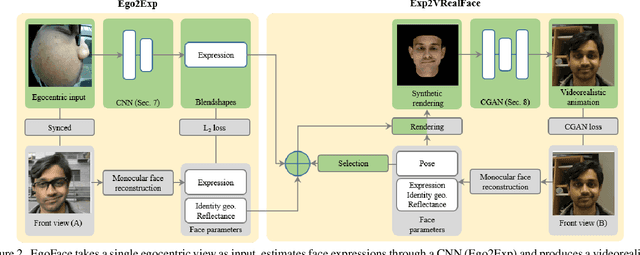
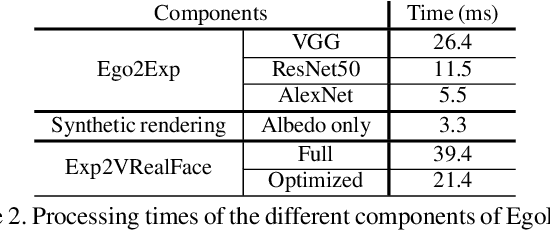

Face performance capture and reenactment techniques use multiple cameras and sensors, positioned at a distance from the face or mounted on heavy wearable devices. This limits their applications in mobile and outdoor environments. We present EgoFace, a radically new lightweight setup for face performance capture and front-view videorealistic reenactment using a single egocentric RGB camera. Our lightweight setup allows operations in uncontrolled environments, and lends itself to telepresence applications such as video-conferencing from dynamic environments. The input image is projected into a low dimensional latent space of the facial expression parameters. Through careful adversarial training of the parameter-space synthetic rendering, a videorealistic animation is produced. Our problem is challenging as the human visual system is sensitive to the smallest face irregularities that could occur in the final results. This sensitivity is even stronger for video results. Our solution is trained in a pre-processing stage, through a supervised manner without manual annotations. EgoFace captures a wide variety of facial expressions, including mouth movements and asymmetrical expressions. It works under varying illuminations, background, movements, handles people from different ethnicities and can operate in real time.
DEMEA: Deep Mesh Autoencoders for Non-Rigidly Deforming Objects
May 24, 2019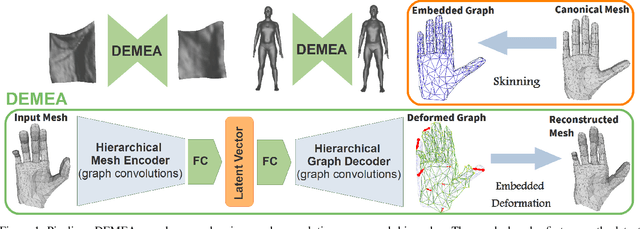
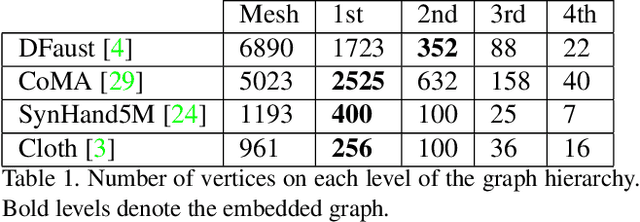
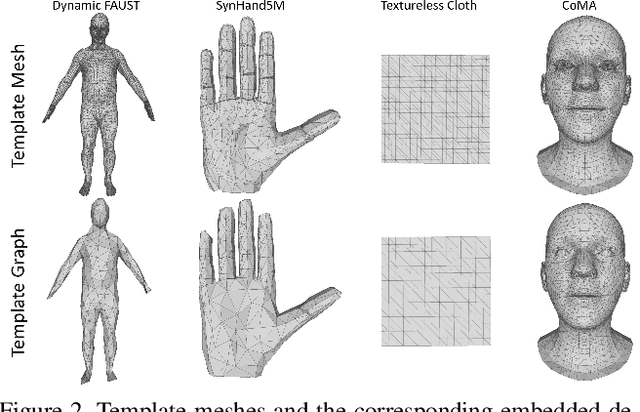

Mesh autoencoders are commonly used for dimensionality reduction, sampling and mesh modeling. We propose a general-purpose DEep MEsh Autoencoder (DEMEA) which adds a novel embedded deformation layer to a graph-convolutional mesh autoencoder. The embedded deformation layer (EDL) is a differentiable deformable geometric proxy which explicitly models point displacements of non-rigid deformations in a lower dimensional space and serves as a local rigidity regularizer. DEMEA decouples the parameterization of the deformation from the final mesh resolution since the deformation is defined over a lower dimensional embedded deformation graph. We perform a large-scale study on four different datasets of deformable objects. Reasoning about the local rigidity of meshes using EDL allows us to achieve higher-quality results for highly deformable objects, compared to directly regressing vertex positions. We demonstrate multiple applications of DEMEA, including non-rigid 3D reconstruction from depth and shading cues, non-rigid surface tracking, as well as the transfer of deformations over different meshes.
FML: Face Model Learning from Videos
Dec 18, 2018
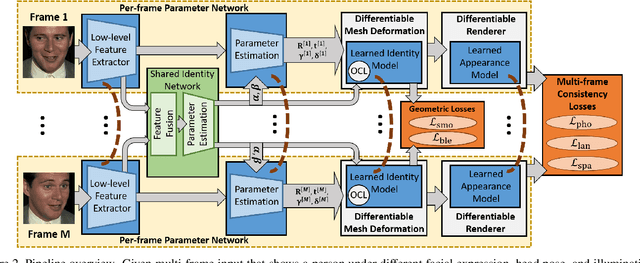
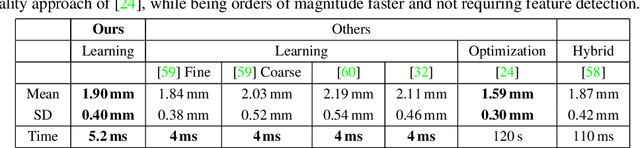
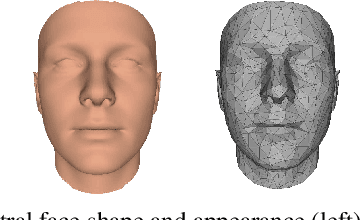
Monocular image-based 3D reconstruction of faces is a long-standing problem in computer vision. Since image data is a 2D projection of a 3D face, the resulting depth ambiguity makes the problem ill-posed. Most existing methods rely on data-driven priors that are built from limited 3D face scans. In contrast, we propose multi-frame video-based self-supervised training of a deep network that (i) learns a face identity model both in shape and appearance while (ii) jointly learning to reconstruct 3D faces. Our face model is learned using only corpora of in-the-wild video clips collected from the Internet. This virtually endless source of training data enables learning of a highly general 3D face model. In order to achieve this, we propose a novel multi-frame consistency loss that ensures consistent shape and appearance across multiple frames of a subject's face, thus minimizing depth ambiguity. At test time we can use an arbitrary number of frames, so that we can perform both monocular as well as multi-frame reconstruction.
A Hybrid Model for Identity Obfuscation by Face Replacement
Jul 24, 2018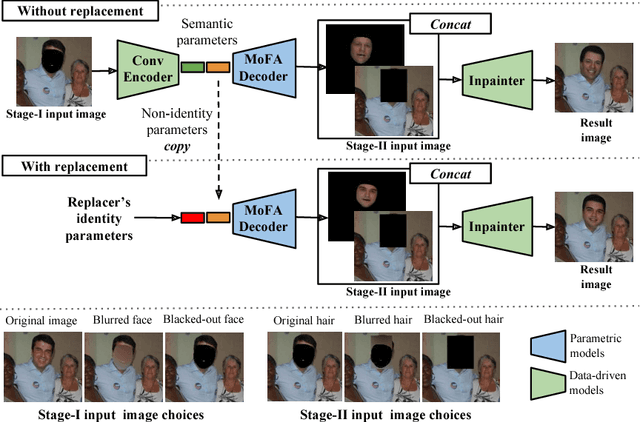
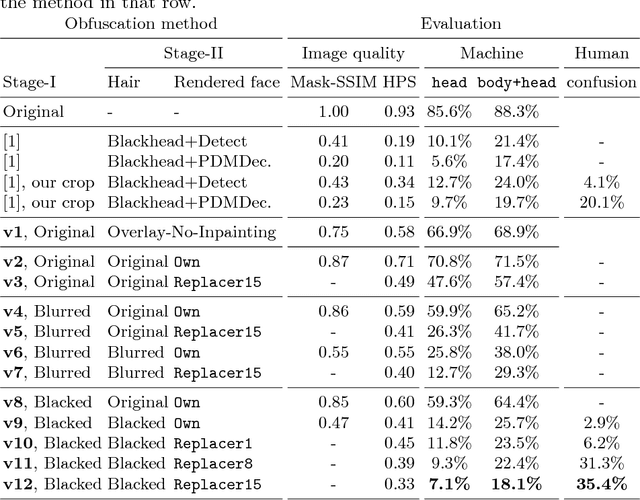
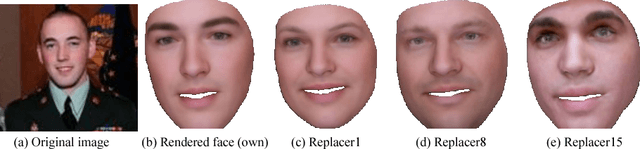
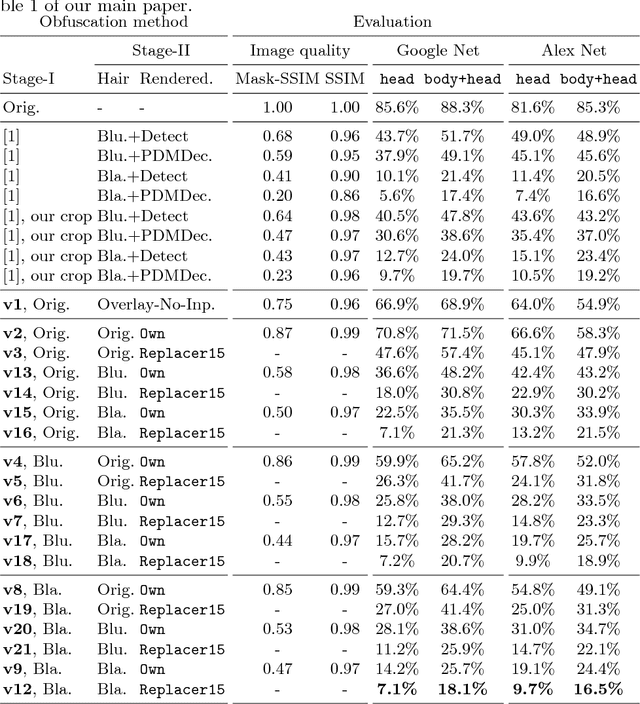
As more and more personal photos are shared and tagged in social media, avoiding privacy risks such as unintended recognition becomes increasingly challenging. We propose a new hybrid approach to obfuscate identities in photos by head replacement. Our approach combines state of the art parametric face synthesis with latest advances in Generative Adversarial Networks (GAN) for data-driven image synthesis. On the one hand, the parametric part of our method gives us control over the facial parameters and allows for explicit manipulation of the identity. On the other hand, the data-driven aspects allow for adding fine details and overall realism as well as seamless blending into the scene context. In our experiments, we show highly realistic output of our system that improves over the previous state of the art in obfuscation rate while preserving a higher similarity to the original image content.