 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtom-level Protein Representation Learning Improves Protein Structure Prediction
May 21, 2026Recent advances in generative modeling show that pretrained representations can improve generation as conditioning features or alignment targets. Motivated by this, we study protein representations for predicting structures beyond conventional function annotation. We propose TriProRep, a structure-aware pretraining method that jointly models three aligned residue-level views: amino-acid identity, backbone geometry, and local full-atom geometry, discretely encoded via VQ-VAE tokenizers. By pretraining to recover original tokens from generator-corrupted views, TriProRep learns to distinguish plausible but incorrect cross-view augmentations from the original protein. We further introduce RepSP, a benchmark for evaluating protein representations in structure-predictive settings. RepSP tests three uses of representations: homodimer co-folding from apo-chain representations, residue-level prediction of homodimer-derived interaction properties, and representation-aligned monomer structure prediction. Across these tasks, TriProRep improves over sequence-only and prior structure-aware representation models, while maintaining competitive performance on conventional benchmarks.
VideoSPatS: Video SPatiotemporal Splines for Disentangled Occlusion, Appearance and Motion Modeling and Editing
Apr 08, 2025



We present an implicit video representation for occlusions, appearance, and motion disentanglement from monocular videos, which we call Video SPatiotemporal Splines (VideoSPatS). Unlike previous methods that map time and coordinates to deformation and canonical colors, our VideoSPatS maps input coordinates into Spatial and Color Spline deformation fields $D_s$ and $D_c$, which disentangle motion and appearance in videos. With spline-based parametrization, our method naturally generates temporally consistent flow and guarantees long-term temporal consistency, which is crucial for convincing video editing. Using multiple prediction branches, our VideoSPatS model also performs layer separation between the latent video and the selected occluder. By disentangling occlusions, appearance, and motion, our method enables better spatiotemporal modeling and editing of diverse videos, including in-the-wild talking head videos with challenging occlusions, shadows, and specularities while maintaining an appropriate canonical space for editing. We also present general video modeling results on the DAVIS and CoDeF datasets, as well as our own talking head video dataset collected from open-source web videos. Extensive ablations show the combination of $D_s$ and $D_c$ under neural splines can overcome motion and appearance ambiguities, paving the way for more advanced video editing models.
Contextual Gesture: Co-Speech Gesture Video Generation through Context-aware Gesture Representation
Feb 11, 2025Co-speech gesture generation is crucial for creating lifelike avatars and enhancing human-computer interactions by synchronizing gestures with speech. Despite recent advancements, existing methods struggle with accurately identifying the rhythmic or semantic triggers from audio for generating contextualized gesture patterns and achieving pixel-level realism. To address these challenges, we introduce Contextual Gesture, a framework that improves co-speech gesture video generation through three innovative components: (1) a chronological speech-gesture alignment that temporally connects two modalities, (2) a contextualized gesture tokenization that incorporate speech context into motion pattern representation through distillation, and (3) a structure-aware refinement module that employs edge connection to link gesture keypoints to improve video generation. Our extensive experiments demonstrate that Contextual Gesture not only produces realistic and speech-aligned gesture videos but also supports long-sequence generation and video gesture editing applications, shown in Fig.1 Project Page: https://andypinxinliu.github.io/Contextual-Gesture/.
KinMo: Kinematic-aware Human Motion Understanding and Generation
Nov 23, 2024



Controlling human motion based on text presents an important challenge in computer vision. Traditional approaches often rely on holistic action descriptions for motion synthesis, which struggle to capture subtle movements of local body parts. This limitation restricts the ability to isolate and manipulate specific movements. To address this, we propose a novel motion representation that decomposes motion into distinct body joint group movements and interactions from a kinematic perspective. We design an automatic dataset collection pipeline that enhances the existing text-motion benchmark by incorporating fine-grained local joint-group motion and interaction descriptions. To bridge the gap between text and motion domains, we introduce a hierarchical motion semantics approach that progressively fuses joint-level interaction information into the global action-level semantics for modality alignment. With this hierarchy, we introduce a coarse-to-fine motion synthesis procedure for various generation and editing downstream applications. Our quantitative and qualitative experiments demonstrate that the proposed formulation enhances text-motion retrieval by improving joint-spatial understanding, and enables more precise joint-motion generation and control. Project Page: {\small\url{https://andypinxinliu.github.io/KinMo/}}
Discrete Diffusion Schrödinger Bridge Matching for Graph Transformation
Oct 02, 2024



Transporting between arbitrary distributions is a fundamental goal in generative modeling. Recently proposed diffusion bridge models provide a potential solution, but they rely on a joint distribution that is difficult to obtain in practice. Furthermore, formulations based on continuous domains limit their applicability to discrete domains such as graphs. To overcome these limitations, we propose Discrete Diffusion Schr\"odinger Bridge Matching (DDSBM), a novel framework that utilizes continuous-time Markov chains to solve the SB problem in a high-dimensional discrete state space. Our approach extends Iterative Markovian Fitting to discrete domains, and we have proved its convergence to the SB. Furthermore, we adapt our framework for the graph transformation and show that our design choice of underlying dynamics characterized by independent modifications of nodes and edges can be interpreted as the entropy-regularized version of optimal transport with a cost function described by the graph edit distance. To demonstrate the effectiveness of our framework, we have applied DDSBM to molecular optimization in the field of chemistry. Experimental results demonstrate that DDSBM effectively optimizes molecules' property-of-interest with minimal graph transformation, successfully retaining other features.
GaussianHeads: End-to-End Learning of Drivable Gaussian Head Avatars from Coarse-to-fine Representations
Sep 18, 2024Real-time rendering of human head avatars is a cornerstone of many computer graphics applications, such as augmented reality, video games, and films, to name a few. Recent approaches address this challenge with computationally efficient geometry primitives in a carefully calibrated multi-view setup. Albeit producing photorealistic head renderings, it often fails to represent complex motion changes such as the mouth interior and strongly varying head poses. We propose a new method to generate highly dynamic and deformable human head avatars from multi-view imagery in real-time. At the core of our method is a hierarchical representation of head models that allows to capture the complex dynamics of facial expressions and head movements. First, with rich facial features extracted from raw input frames, we learn to deform the coarse facial geometry of the template mesh. We then initialize 3D Gaussians on the deformed surface and refine their positions in a fine step. We train this coarse-to-fine facial avatar model along with the head pose as a learnable parameter in an end-to-end framework. This enables not only controllable facial animation via video inputs, but also high-fidelity novel view synthesis of challenging facial expressions, such as tongue deformations and fine-grained teeth structure under large motion changes. Moreover, it encourages the learned head avatar to generalize towards new facial expressions and head poses at inference time. We demonstrate the performance of our method with comparisons against the related methods on different datasets, spanning challenging facial expression sequences across multiple identities. We also show the potential application of our approach by demonstrating a cross-identity facial performance transfer application.
Content and Style Aware Audio-Driven Facial Animation
Aug 14, 2024



Audio-driven 3D facial animation has several virtual humans applications for content creation and editing. While several existing methods provide solutions for speech-driven animation, precise control over content (what) and style (how) of the final performance is still challenging. We propose a novel approach that takes as input an audio, and the corresponding text to extract temporally-aligned content and disentangled style representations, in order to provide controls over 3D facial animation. Our method is trained in two stages, that evolves from audio prominent styles (how it sounds) to visual prominent styles (how it looks). We leverage a high-resource audio dataset in stage I to learn styles that control speech generation in a self-supervised learning framework, and then fine-tune this model with low-resource audio/3D mesh pairs in stage II to control 3D vertex generation. We employ a non-autoregressive seq2seq formulation to model sentence-level dependencies, and better mouth articulations. Our method provides flexibility that the style of a reference audio and the content of a source audio can be combined to enable audio style transfer. Similarly, the content can be modified, e.g. muting or swapping words, that enables style-preserving content editing.
PAV: Personalized Head Avatar from Unstructured Video Collection
Jul 22, 2024



We propose PAV, Personalized Head Avatar for the synthesis of human faces under arbitrary viewpoints and facial expressions. PAV introduces a method that learns a dynamic deformable neural radiance field (NeRF), in particular from a collection of monocular talking face videos of the same character under various appearance and shape changes. Unlike existing head NeRF methods that are limited to modeling such input videos on a per-appearance basis, our method allows for learning multi-appearance NeRFs, introducing appearance embedding for each input video via learnable latent neural features attached to the underlying geometry. Furthermore, the proposed appearance-conditioned density formulation facilitates the shape variation of the character, such as facial hair and soft tissues, in the radiance field prediction. To the best of our knowledge, our approach is the first dynamic deformable NeRF framework to model appearance and shape variations in a single unified network for multi-appearances of the same subject. We demonstrate experimentally that PAV outperforms the baseline method in terms of visual rendering quality in our quantitative and qualitative studies on various subjects.
HQ3DAvatar: High Quality Controllable 3D Head Avatar
Mar 25, 2023Multi-view volumetric rendering techniques have recently shown great potential in modeling and synthesizing high-quality head avatars. A common approach to capture full head dynamic performances is to track the underlying geometry using a mesh-based template or 3D cube-based graphics primitives. While these model-based approaches achieve promising results, they often fail to learn complex geometric details such as the mouth interior, hair, and topological changes over time. This paper presents a novel approach to building highly photorealistic digital head avatars. Our method learns a canonical space via an implicit function parameterized by a neural network. It leverages multiresolution hash encoding in the learned feature space, allowing for high-quality, faster training and high-resolution rendering. At test time, our method is driven by a monocular RGB video. Here, an image encoder extracts face-specific features that also condition the learnable canonical space. This encourages deformation-dependent texture variations during training. We also propose a novel optical flow based loss that ensures correspondences in the learned canonical space, thus encouraging artifact-free and temporally consistent renderings. We show results on challenging facial expressions and show free-viewpoint renderings at interactive real-time rates for medium image resolutions. Our method outperforms all existing approaches, both visually and numerically. We will release our multiple-identity dataset to encourage further research. Our Project page is available at: https://vcai.mpi-inf.mpg.de/projects/HQ3DAvatar/
VideoForensicsHQ: Detecting High-quality Manipulated Face Videos
May 20, 2020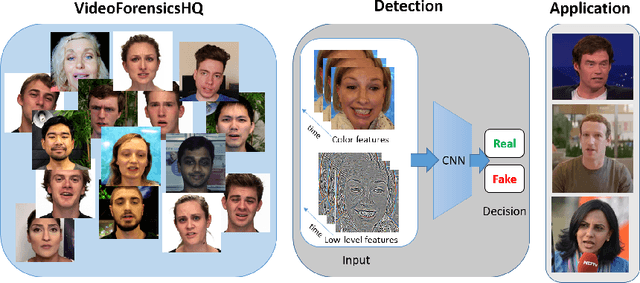

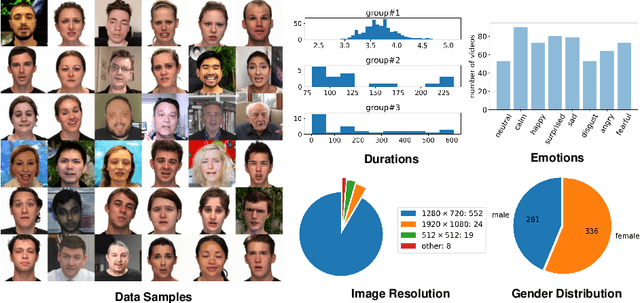
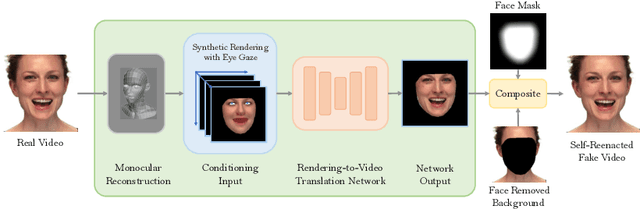
New approaches to synthesize and manipulate face videos at very high quality have paved the way for new applications in computer animation, virtual and augmented reality, or face video analysis. However, there are concerns that they may be used in a malicious way, e.g. to manipulate videos of public figures, politicians or reporters, to spread false information. The research community therefore developed techniques for automated detection of modified imagery, and assembled benchmark datasets showing manipulatons by state-of-the-art techniques. In this paper, we contribute to this initiative in two ways: First, we present a new audio-visual benchmark dataset. It shows some of the highest quality visual manipulations available today. Human observers find them significantly harder to identify as forged than videos from other benchmarks. Furthermore we propose new family of deep-learning-based fake detectors, demonstrating that existing detectors are not well-suited for detecting fakes of a quality as high as presented in our dataset. Our detectors examine spatial and temporal features. This allows them to outperform existing approaches both in terms of high detection accuracy and generalization to unseen fake generation methods and unseen identities.