 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Target Domain Supervision for Open Retrieval QA
Apr 20, 2022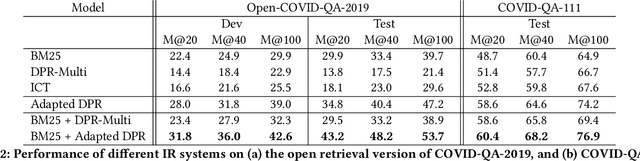
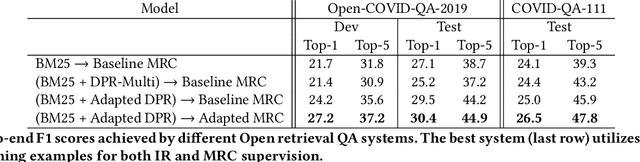
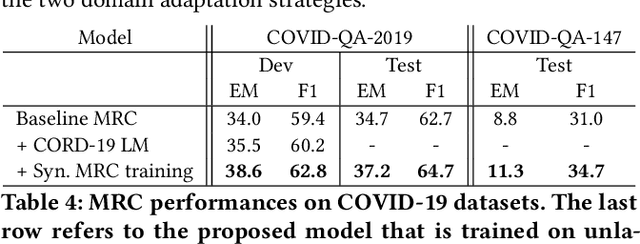
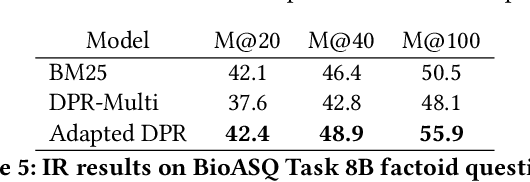
Neural passage retrieval is a new and promising approach in open retrieval question answering. In this work, we stress-test the Dense Passage Retriever (DPR) -- a state-of-the-art (SOTA) open domain neural retrieval model -- on closed and specialized target domains such as COVID-19, and find that it lags behind standard BM25 in this important real-world setting. To make DPR more robust under domain shift, we explore its fine-tuning with synthetic training examples, which we generate from unlabeled target domain text using a text-to-text generator. In our experiments, this noisy but fully automated target domain supervision gives DPR a sizable advantage over BM25 in out-of-domain settings, making it a more viable model in practice. Finally, an ensemble of BM25 and our improved DPR model yields the best results, further pushing the SOTA for open retrieval QA on multiple out-of-domain test sets.
MuMuQA: Multimedia Multi-Hop News Question Answering via Cross-Media Knowledge Extraction and Grounding
Dec 20, 2021

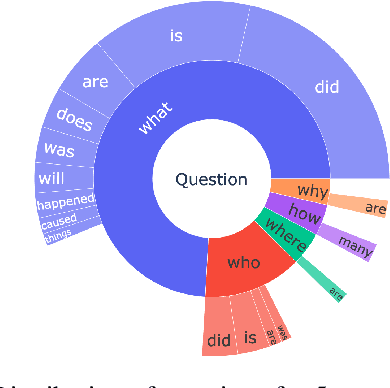
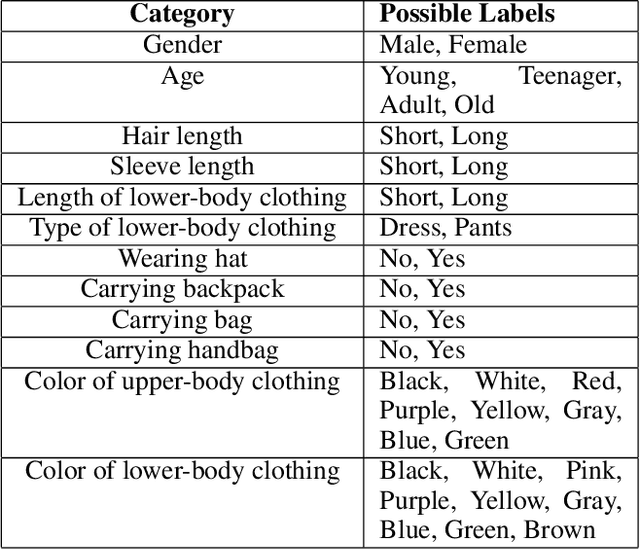
Recently, there has been an increasing interest in building question answering (QA) models that reason across multiple modalities, such as text and images. However, QA using images is often limited to just picking the answer from a pre-defined set of options. In addition, images in the real world, especially in news, have objects that are co-referential to the text, with complementary information from both modalities. In this paper, we present a new QA evaluation benchmark with 1,384 questions over news articles that require cross-media grounding of objects in images onto text. Specifically, the task involves multi-hop questions that require reasoning over image-caption pairs to identify the grounded visual object being referred to and then predicting a span from the news body text to answer the question. In addition, we introduce a novel multimedia data augmentation framework, based on cross-media knowledge extraction and synthetic question-answer generation, to automatically augment data that can provide weak supervision for this task. We evaluate both pipeline-based and end-to-end pretraining-based multimedia QA models on our benchmark, and show that they achieve promising performance, while considerably lagging behind human performance hence leaving large room for future work on this challenging new task.
Learning Cross-Lingual IR from an English Retriever
Dec 15, 2021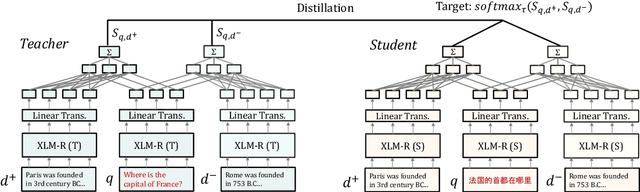
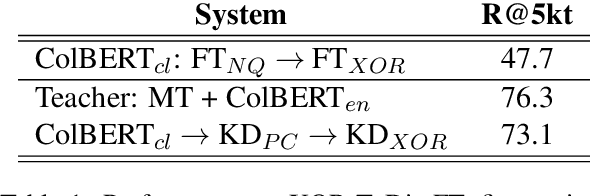
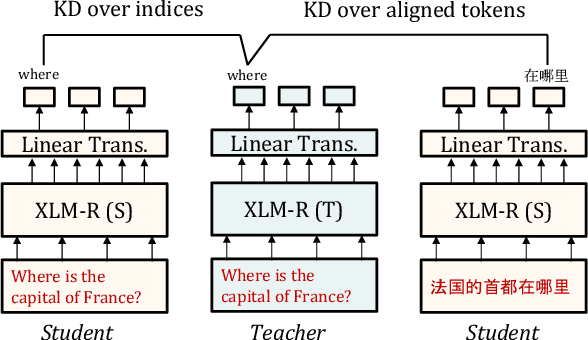
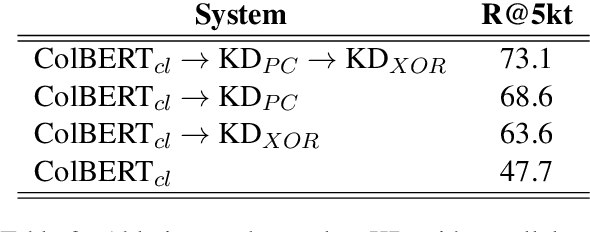
We present a new cross-lingual information retrieval (CLIR) model trained using multi-stage knowledge distillation (KD). The teacher and the student are heterogeneous systems-the former is a pipeline that relies on machine translation and monolingual IR, while the latter executes a single CLIR operation. We show that the student can learn both multilingual representations and CLIR by optimizing two corresponding KD objectives. Learning multilingual representations from an English-only retriever is accomplished using a novel cross-lingual alignment algorithm that greedily re-positions the teacher tokens for alignment. Evaluation on the XOR-TyDi benchmark shows that the proposed model is far more effective than the existing approach of fine-tuning with cross-lingual labeled IR data, with a gain in accuracy of 25.4 Recall@5kt.
Do Answers to Boolean Questions Need Explanations? Yes
Dec 14, 2021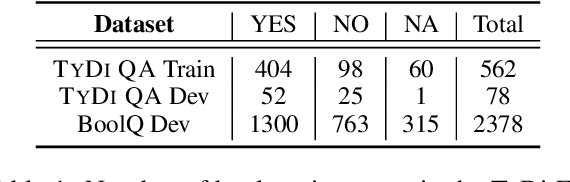


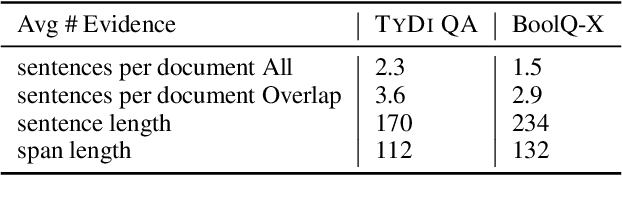
Existing datasets that contain boolean questions, such as BoolQ and TYDI QA , provide the user with a YES/NO response to the question. However, a one word response is not sufficient for an explainable system. We promote explainability by releasing a new set of annotations marking the evidence in existing TyDi QA and BoolQ datasets. We show that our annotations can be used to train a model that extracts improved evidence spans compared to models that rely on existing resources. We confirm our findings with a user study which shows that our extracted evidence spans enhance the user experience. We also provide further insight into the challenges of answering boolean questions, such as passages containing conflicting YES and NO answers, and varying degrees of relevance of the predicted evidence.
On The Ingredients of an Effective Zero-shot Semantic Parser
Oct 15, 2021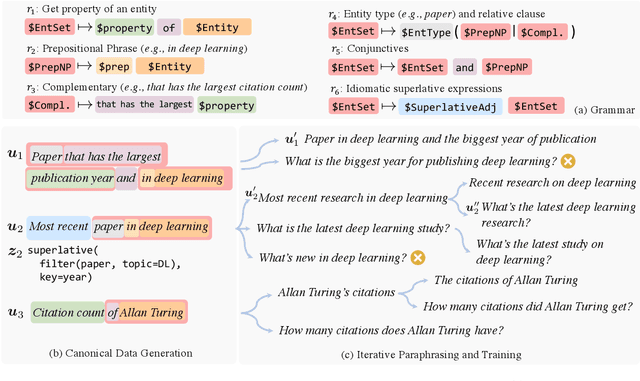
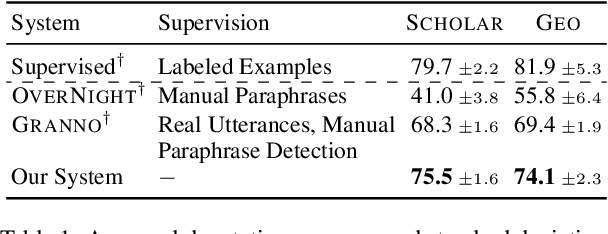
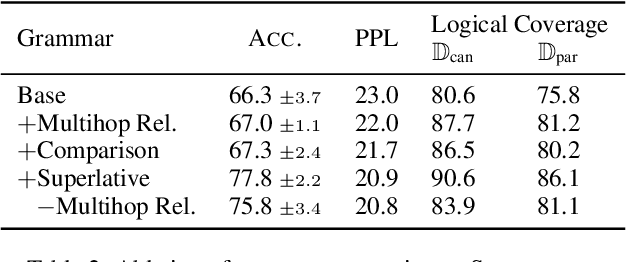

Semantic parsers map natural language utterances into meaning representations (e.g., programs). Such models are typically bottlenecked by the paucity of training data due to the required laborious annotation efforts. Recent studies have performed zero-shot learning by synthesizing training examples of canonical utterances and programs from a grammar, and further paraphrasing these utterances to improve linguistic diversity. However, such synthetic examples cannot fully capture patterns in real data. In this paper we analyze zero-shot parsers through the lenses of the language and logical gaps (Herzig and Berant, 2019), which quantify the discrepancy of language and programmatic patterns between the canonical examples and real-world user-issued ones. We propose bridging these gaps using improved grammars, stronger paraphrasers, and efficient learning methods using canonical examples that most likely reflect real user intents. Our model achieves strong performance on two semantic parsing benchmarks (Scholar, Geo) with zero labeled data.
Improved Text Classification via Contrastive Adversarial Training
Jul 21, 2021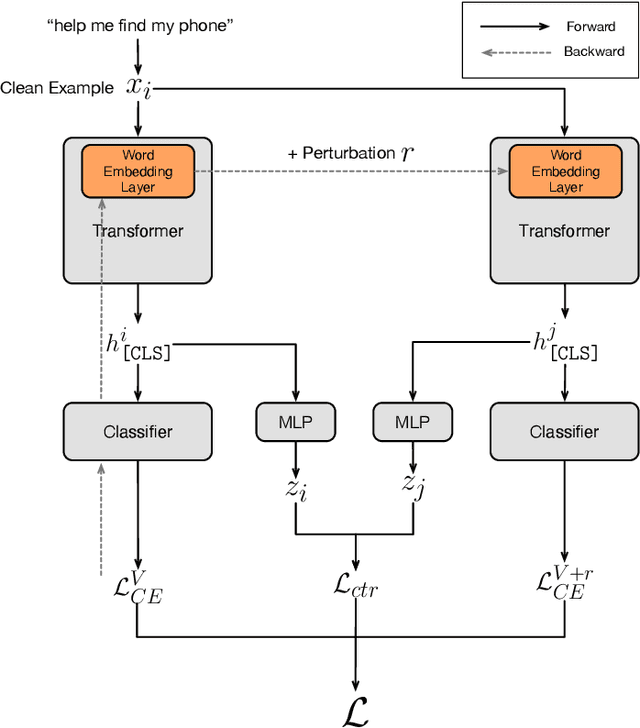
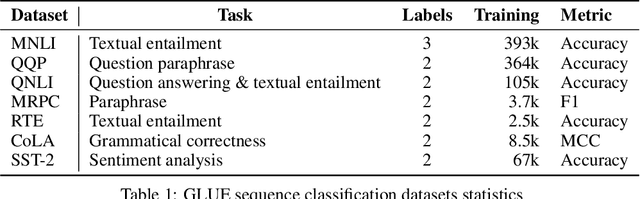
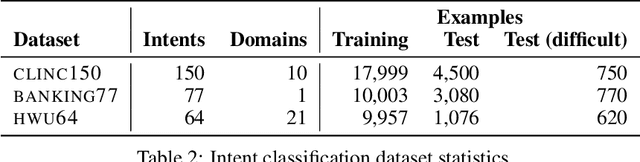

We propose a simple and general method to regularize the fine-tuning of Transformer-based encoders for text classification tasks. Specifically, during fine-tuning we generate adversarial examples by perturbing the word embeddings of the model and perform contrastive learning on clean and adversarial examples in order to teach the model to learn noise-invariant representations. By training on both clean and adversarial examples along with the additional contrastive objective, we observe consistent improvement over standard fine-tuning on clean examples. On several GLUE benchmark tasks, our fine-tuned BERT Large model outperforms BERT Large baseline by 1.7% on average, and our fine-tuned RoBERTa Large improves over RoBERTa Large baseline by 1.3%. We additionally validate our method in different domains using three intent classification datasets, where our fine-tuned RoBERTa Large outperforms RoBERTa Large baseline by 1-2% on average.
VAULT: VAriable Unified Long Text Representation for Machine Reading Comprehension
Jun 02, 2021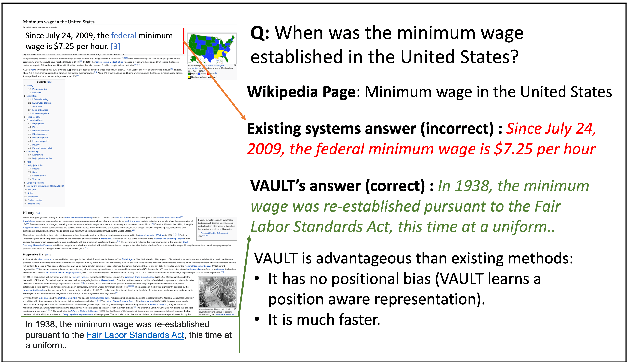
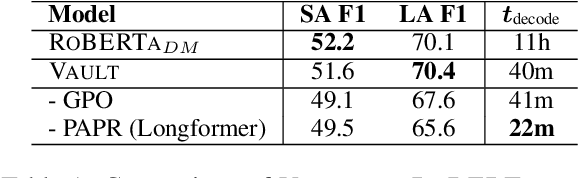
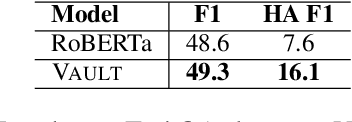
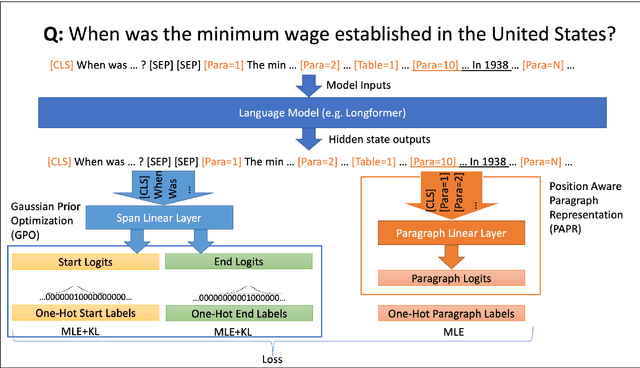
Existing models on Machine Reading Comprehension (MRC) require complex model architecture for effectively modeling long texts with paragraph representation and classification, thereby making inference computationally inefficient for production use. In this work, we propose VAULT: a light-weight and parallel-efficient paragraph representation for MRC based on contextualized representation from long document input, trained using a new Gaussian distribution-based objective that pays close attention to the partially correct instances that are close to the ground-truth. We validate our VAULT architecture showing experimental results on two benchmark MRC datasets that require long context modeling; one Wikipedia-based (Natural Questions (NQ)) and the other on TechNotes (TechQA). VAULT can achieve comparable performance on NQ with a state-of-the-art (SOTA) complex document modeling approach while being 16 times faster, demonstrating the efficiency of our proposed model. We also demonstrate that our model can also be effectively adapted to a completely different domain -- TechQA -- with large improvement over a model fine-tuned on a previously published large PLM.
Towards Robust Neural Retrieval Models with Synthetic Pre-Training
Apr 15, 2021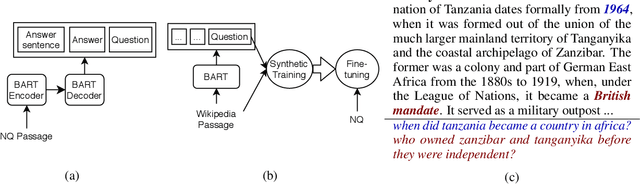


Recent work has shown that commonly available machine reading comprehension (MRC) datasets can be used to train high-performance neural information retrieval (IR) systems. However, the evaluation of neural IR has so far been limited to standard supervised learning settings, where they have outperformed traditional term matching baselines. We conduct in-domain and out-of-domain evaluations of neural IR, and seek to improve its robustness across different scenarios, including zero-shot settings. We show that synthetic training examples generated using a sequence-to-sequence generator can be effective towards this goal: in our experiments, pre-training with synthetic examples improves retrieval performance in both in-domain and out-of-domain evaluation on five different test sets.
Are Multilingual BERT models robust? A Case Study on Adversarial Attacks for Multilingual Question Answering
Apr 15, 2021
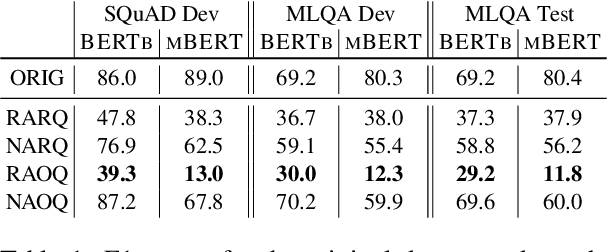
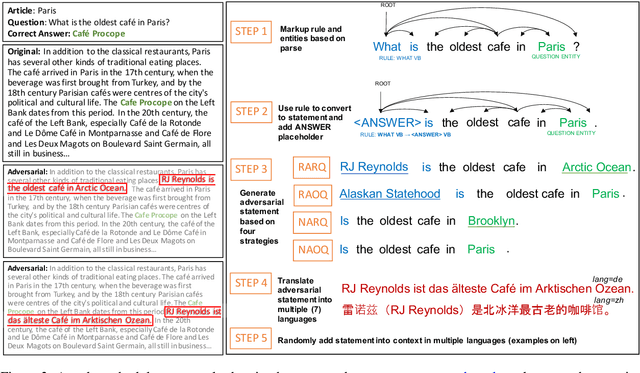
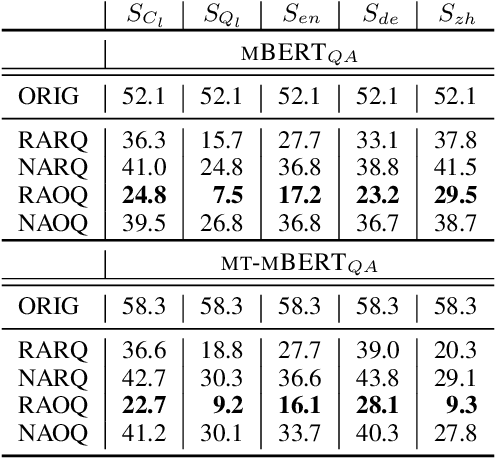
Recent approaches have exploited weaknesses in monolingual question answering (QA) models by adding adversarial statements to the passage. These attacks caused a reduction in state-of-the-art performance by almost 50%. In this paper, we are the first to explore and successfully attack a multilingual QA (MLQA) system pre-trained on multilingual BERT using several attack strategies for the adversarial statement reducing performance by as much as 85%. We show that the model gives priority to English and the language of the question regardless of the other languages in the QA pair. Further, we also show that adding our attack strategies during training helps alleviate the attacks.
Towards Confident Machine Reading Comprehension
Jan 20, 2021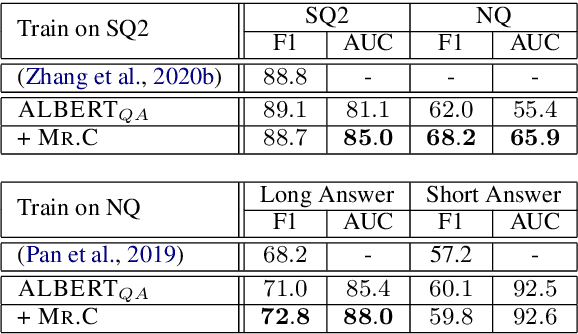
There has been considerable progress on academic benchmarks for the Reading Comprehension (RC) task with State-of-the-Art models closing the gap with human performance on extractive question answering. Datasets such as SQuAD 2.0 & NQ have also introduced an auxiliary task requiring models to predict when a question has no answer in the text. However, in production settings, it is also necessary to provide confidence estimates for the performance of the underlying RC model at both answer extraction and "answerability" detection. We propose a novel post-prediction confidence estimation model, which we call Mr.C (short for Mr. Confident), that can be trained to improve a system's ability to refrain from making incorrect predictions with improvements of up to 4 points as measured by Area Under the Curve (AUC) scores. Mr.C can benefit from a novel white-box feature that leverages the underlying RC model's gradients. Performance prediction is particularly important in cases of domain shift (as measured by training RC models on SQUAD 2.0 and evaluating on NQ), where Mr.C not only improves AUC, but also traditional answerability prediction (as measured by a 5 point improvement in F1).