 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Leverage Unlabeled Data in Offline Reinforcement Learning
Feb 03, 2022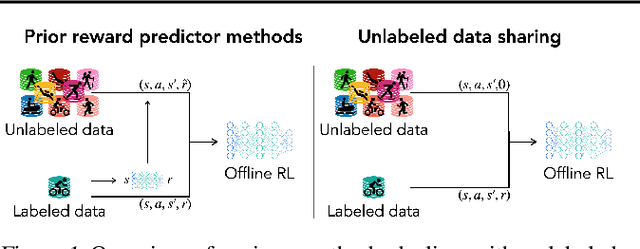


Offline reinforcement learning (RL) can learn control policies from static datasets but, like standard RL methods, it requires reward annotations for every transition. In many cases, labeling large datasets with rewards may be costly, especially if those rewards must be provided by human labelers, while collecting diverse unlabeled data might be comparatively inexpensive. How can we best leverage such unlabeled data in offline RL? One natural solution is to learn a reward function from the labeled data and use it to label the unlabeled data. In this paper, we find that, perhaps surprisingly, a much simpler method that simply applies zero rewards to unlabeled data leads to effective data sharing both in theory and in practice, without learning any reward model at all. While this approach might seem strange (and incorrect) at first, we provide extensive theoretical and empirical analysis that illustrates how it trades off reward bias, sample complexity and distributional shift, often leading to good results. We characterize conditions under which this simple strategy is effective, and further show that extending it with a simple reweighting approach can further alleviate the bias introduced by using incorrect reward labels. Our empirical evaluation confirms these findings in simulated robotic locomotion, navigation, and manipulation settings.
DR3: Value-Based Deep Reinforcement Learning Requires Explicit Regularization
Dec 09, 2021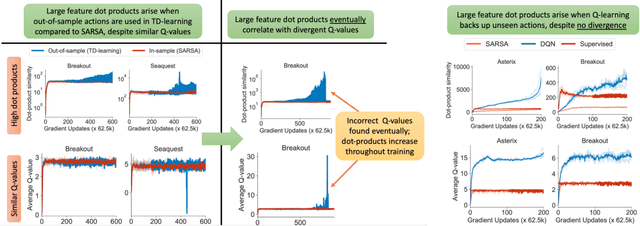
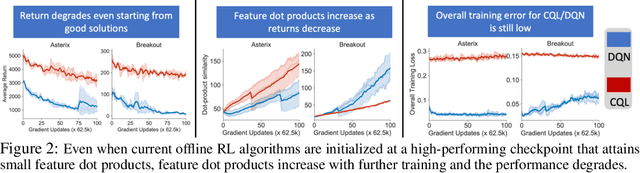

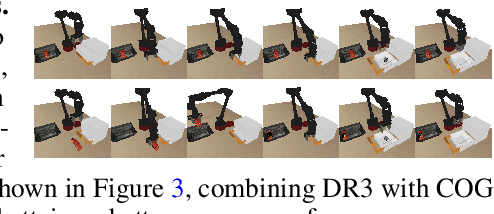
Despite overparameterization, deep networks trained via supervised learning are easy to optimize and exhibit excellent generalization. One hypothesis to explain this is that overparameterized deep networks enjoy the benefits of implicit regularization induced by stochastic gradient descent, which favors parsimonious solutions that generalize well on test inputs. It is reasonable to surmise that deep reinforcement learning (RL) methods could also benefit from this effect. In this paper, we discuss how the implicit regularization effect of SGD seen in supervised learning could in fact be harmful in the offline deep RL setting, leading to poor generalization and degenerate feature representations. Our theoretical analysis shows that when existing models of implicit regularization are applied to temporal difference learning, the resulting derived regularizer favors degenerate solutions with excessive "aliasing", in stark contrast to the supervised learning case. We back up these findings empirically, showing that feature representations learned by a deep network value function trained via bootstrapping can indeed become degenerate, aliasing the representations for state-action pairs that appear on either side of the Bellman backup. To address this issue, we derive the form of this implicit regularizer and, inspired by this derivation, propose a simple and effective explicit regularizer, called DR3, that counteracts the undesirable effects of this implicit regularizer. When combined with existing offline RL methods, DR3 substantially improves performance and stability, alleviating unlearning in Atari 2600 games, D4RL domains and robotic manipulation from images.
Data-Driven Offline Optimization For Architecting Hardware Accelerators
Oct 20, 2021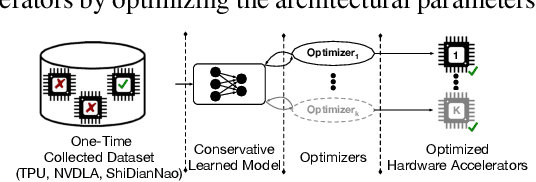
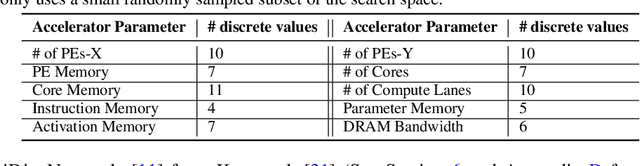
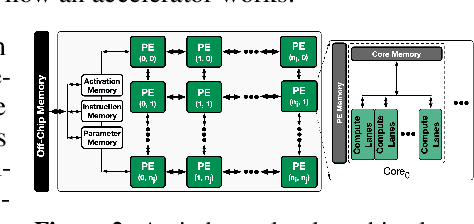
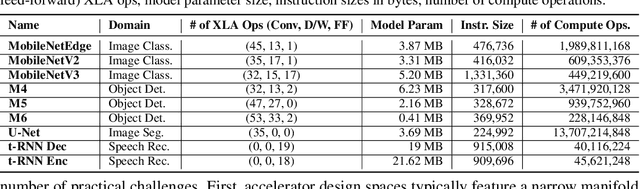
Industry has gradually moved towards application-specific hardware accelerators in order to attain higher efficiency. While such a paradigm shift is already starting to show promising results, designers need to spend considerable manual effort and perform a large number of time-consuming simulations to find accelerators that can accelerate multiple target applications while obeying design constraints. Moreover, such a "simulation-driven" approach must be re-run from scratch every time the set of target applications or design constraints change. An alternative paradigm is to use a "data-driven", offline approach that utilizes logged simulation data, to architect hardware accelerators, without needing any form of simulations. Such an approach not only alleviates the need to run time-consuming simulation, but also enables data reuse and applies even when set of target applications changes. In this paper, we develop such a data-driven offline optimization method for designing hardware accelerators, dubbed PRIME, that enjoys all of these properties. Our approach learns a conservative, robust estimate of the desired cost function, utilizes infeasible points, and optimizes the design against this estimate without any additional simulator queries during optimization. PRIME architects accelerators -- tailored towards both single and multiple applications -- improving performance upon state-of-the-art simulation-driven methods by about 1.54x and 1.20x, while considerably reducing the required total simulation time by 93% and 99%, respectively. In addition, PRIME also architects effective accelerators for unseen applications in a zero-shot setting, outperforming simulation-based methods by 1.26x.
A Workflow for Offline Model-Free Robotic Reinforcement Learning
Sep 23, 2021

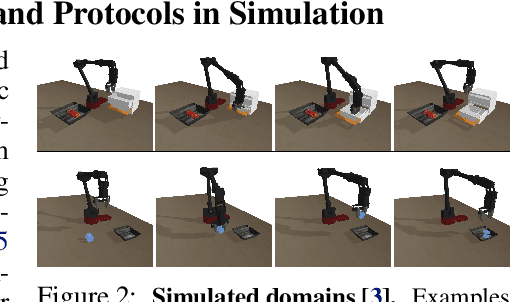
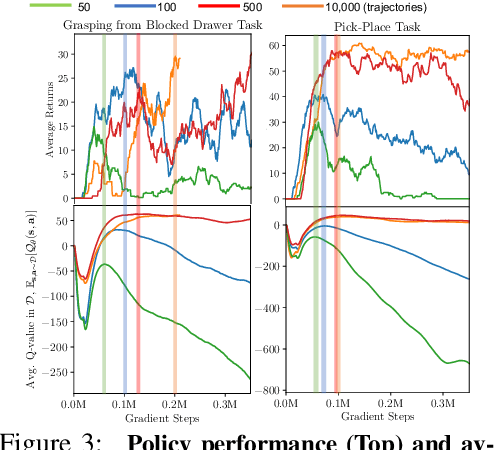
Offline reinforcement learning (RL) enables learning control policies by utilizing only prior experience, without any online interaction. This can allow robots to acquire generalizable skills from large and diverse datasets, without any costly or unsafe online data collection. Despite recent algorithmic advances in offline RL, applying these methods to real-world problems has proven challenging. Although offline RL methods can learn from prior data, there is no clear and well-understood process for making various design choices, from model architecture to algorithm hyperparameters, without actually evaluating the learned policies online. In this paper, our aim is to develop a practical workflow for using offline RL analogous to the relatively well-understood workflows for supervised learning problems. To this end, we devise a set of metrics and conditions that can be tracked over the course of offline training, and can inform the practitioner about how the algorithm and model architecture should be adjusted to improve final performance. Our workflow is derived from a conceptual understanding of the behavior of conservative offline RL algorithms and cross-validation in supervised learning. We demonstrate the efficacy of this workflow in producing effective policies without any online tuning, both in several simulated robotic learning scenarios and for three tasks on two distinct real robots, focusing on learning manipulation skills with raw image observations with sparse binary rewards. Explanatory video and additional results can be found at sites.google.com/view/offline-rl-workflow
Conservative Data Sharing for Multi-Task Offline Reinforcement Learning
Sep 16, 2021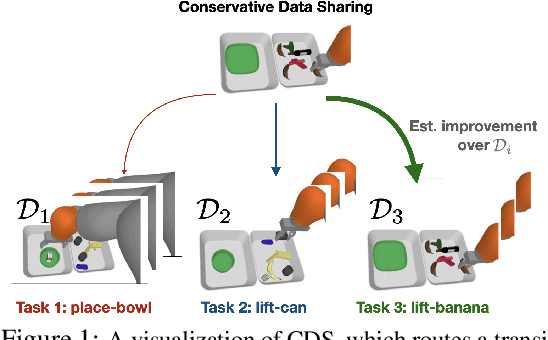
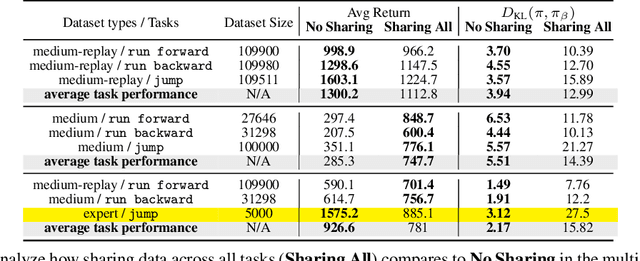
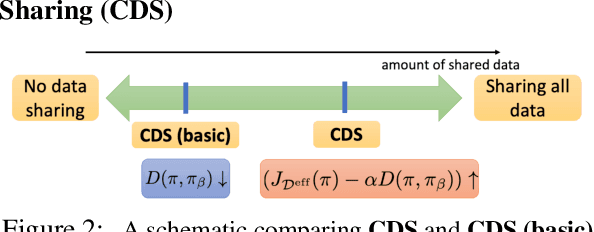

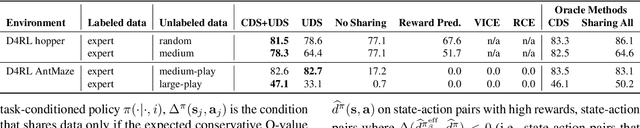
Offline reinforcement learning (RL) algorithms have shown promising results in domains where abundant pre-collected data is available. However, prior methods focus on solving individual problems from scratch with an offline dataset without considering how an offline RL agent can acquire multiple skills. We argue that a natural use case of offline RL is in settings where we can pool large amounts of data collected in various scenarios for solving different tasks, and utilize all of this data to learn behaviors for all the tasks more effectively rather than training each one in isolation. However, sharing data across all tasks in multi-task offline RL performs surprisingly poorly in practice. Thorough empirical analysis, we find that sharing data can actually exacerbate the distributional shift between the learned policy and the dataset, which in turn can lead to divergence of the learned policy and poor performance. To address this challenge, we develop a simple technique for data-sharing in multi-task offline RL that routes data based on the improvement over the task-specific data. We call this approach conservative data sharing (CDS), and it can be applied with multiple single-task offline RL methods. On a range of challenging multi-task locomotion, navigation, and vision-based robotic manipulation problems, CDS achieves the best or comparable performance compared to prior offline multi-task RL methods and previous data sharing approaches.
Conservative Objective Models for Effective Offline Model-Based Optimization
Jul 14, 2021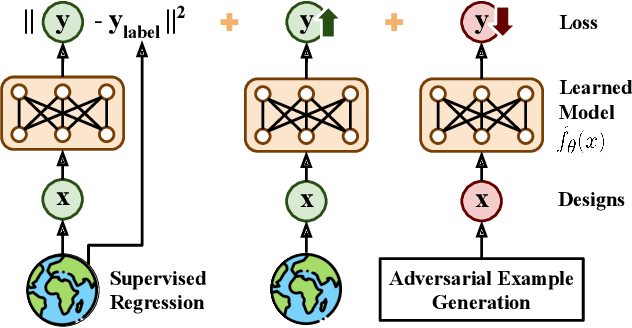
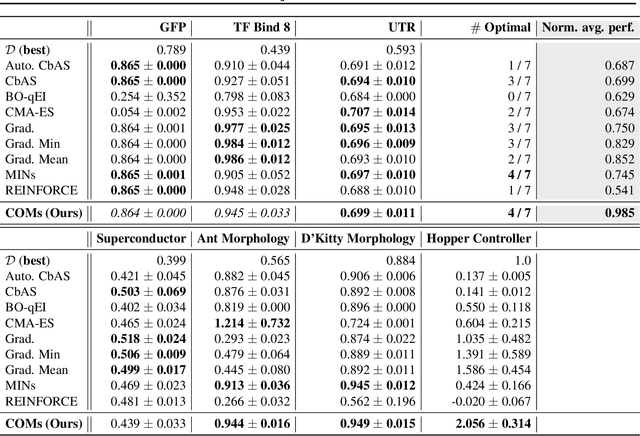
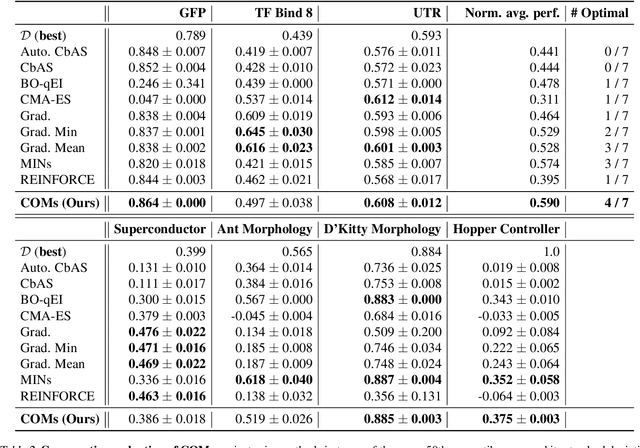
Computational design problems arise in a number of settings, from synthetic biology to computer architectures. In this paper, we aim to solve data-driven model-based optimization (MBO) problems, where the goal is to find a design input that maximizes an unknown objective function provided access to only a static dataset of prior experiments. Such data-driven optimization procedures are the only practical methods in many real-world domains where active data collection is expensive (e.g., when optimizing over proteins) or dangerous (e.g., when optimizing over aircraft designs). Typical methods for MBO that optimize the design against a learned model suffer from distributional shift: it is easy to find a design that "fools" the model into predicting a high value. To overcome this, we propose conservative objective models (COMs), a method that learns a model of the objective function that lower bounds the actual value of the ground-truth objective on out-of-distribution inputs, and uses it for optimization. Structurally, COMs resemble adversarial training methods used to overcome adversarial examples. COMs are simple to implement and outperform a number of existing methods on a wide range of MBO problems, including optimizing protein sequences, robot morphologies, neural network weights, and superconducting materials.
Why Generalization in RL is Difficult: Epistemic POMDPs and Implicit Partial Observability
Jul 13, 2021

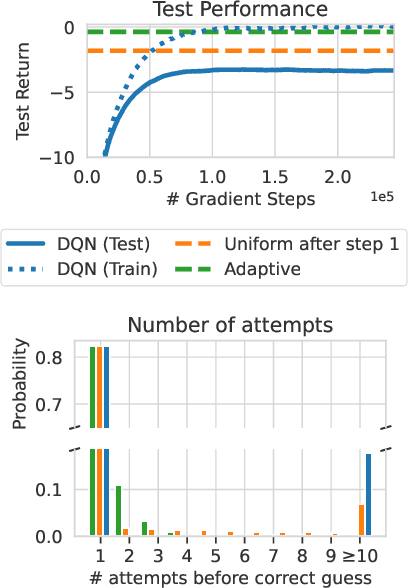
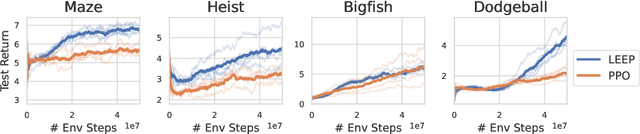
Generalization is a central challenge for the deployment of reinforcement learning (RL) systems in the real world. In this paper, we show that the sequential structure of the RL problem necessitates new approaches to generalization beyond the well-studied techniques used in supervised learning. While supervised learning methods can generalize effectively without explicitly accounting for epistemic uncertainty, we show that, perhaps surprisingly, this is not the case in RL. We show that generalization to unseen test conditions from a limited number of training conditions induces implicit partial observability, effectively turning even fully-observed MDPs into POMDPs. Informed by this observation, we recast the problem of generalization in RL as solving the induced partially observed Markov decision process, which we call the epistemic POMDP. We demonstrate the failure modes of algorithms that do not appropriately handle this partial observability, and suggest a simple ensemble-based technique for approximately solving the partially observed problem. Empirically, we demonstrate that our simple algorithm derived from the epistemic POMDP achieves significant gains in generalization over current methods on the Procgen benchmark suite.
Benchmarks for Deep Off-Policy Evaluation
Mar 30, 2021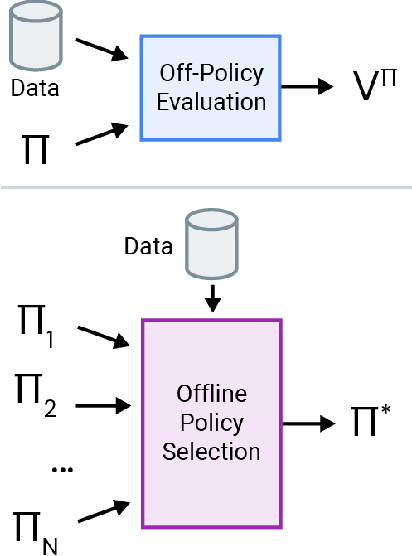
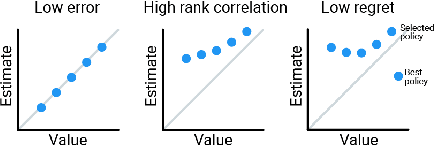
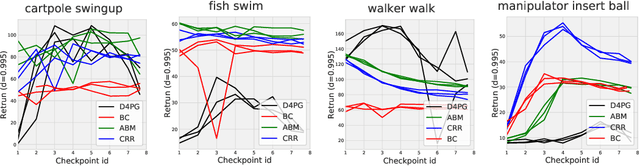
Off-policy evaluation (OPE) holds the promise of being able to leverage large, offline datasets for both evaluating and selecting complex policies for decision making. The ability to learn offline is particularly important in many real-world domains, such as in healthcare, recommender systems, or robotics, where online data collection is an expensive and potentially dangerous process. Being able to accurately evaluate and select high-performing policies without requiring online interaction could yield significant benefits in safety, time, and cost for these applications. While many OPE methods have been proposed in recent years, comparing results between papers is difficult because currently there is a lack of a comprehensive and unified benchmark, and measuring algorithmic progress has been challenging due to the lack of difficult evaluation tasks. In order to address this gap, we present a collection of policies that in conjunction with existing offline datasets can be used for benchmarking off-policy evaluation. Our tasks include a range of challenging high-dimensional continuous control problems, with wide selections of datasets and policies for performing policy selection. The goal of our benchmark is to provide a standardized measure of progress that is motivated from a set of principles designed to challenge and test the limits of existing OPE methods. We perform an evaluation of state-of-the-art algorithms and provide open-source access to our data and code to foster future research in this area.
COMBO: Conservative Offline Model-Based Policy Optimization
Feb 16, 2021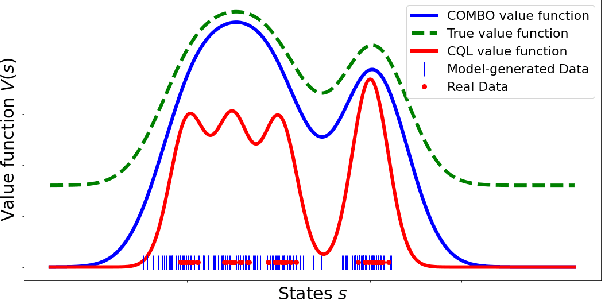
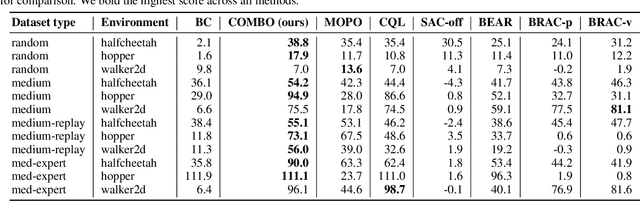
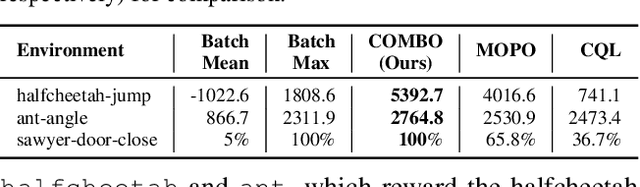

Model-based algorithms, which learn a dynamics model from logged experience and perform some sort of pessimistic planning under the learned model, have emerged as a promising paradigm for offline reinforcement learning (offline RL). However, practical variants of such model-based algorithms rely on explicit uncertainty quantification for incorporating pessimism. Uncertainty estimation with complex models, such as deep neural networks, can be difficult and unreliable. We overcome this limitation by developing a new model-based offline RL algorithm, COMBO, that regularizes the value function on out-of-support state-action tuples generated via rollouts under the learned model. This results in a conservative estimate of the value function for out-of-support state-action tuples, without requiring explicit uncertainty estimation. We theoretically show that our method optimizes a lower bound on the true policy value, that this bound is tighter than that of prior methods, and our approach satisfies a policy improvement guarantee in the offline setting. Through experiments, we find that COMBO consistently performs as well or better as compared to prior offline model-free and model-based methods on widely studied offline RL benchmarks, including image-based tasks.
COG: Connecting New Skills to Past Experience with Offline Reinforcement Learning
Oct 27, 2020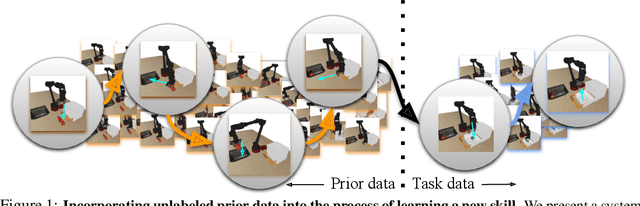
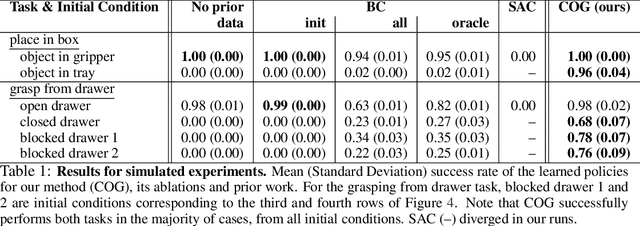
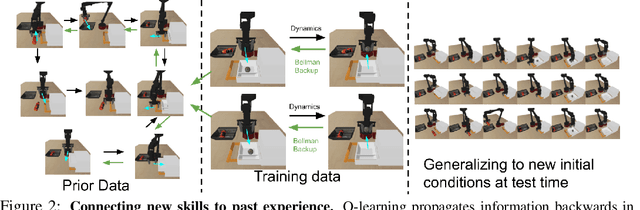

Reinforcement learning has been applied to a wide variety of robotics problems, but most of such applications involve collecting data from scratch for each new task. Since the amount of robot data we can collect for any single task is limited by time and cost considerations, the learned behavior is typically narrow: the policy can only execute the task in a handful of scenarios that it was trained on. What if there was a way to incorporate a large amount of prior data, either from previously solved tasks or from unsupervised or undirected environment interaction, to extend and generalize learned behaviors? While most prior work on extending robotic skills using pre-collected data focuses on building explicit hierarchies or skill decompositions, we show in this paper that we can reuse prior data to extend new skills simply through dynamic programming. We show that even when the prior data does not actually succeed at solving the new task, it can still be utilized for learning a better policy, by providing the agent with a broader understanding of the mechanics of its environment. We demonstrate the effectiveness of our approach by chaining together several behaviors seen in prior datasets for solving a new task, with our hardest experimental setting involving composing four robotic skills in a row: picking, placing, drawer opening, and grasping, where a +1/0 sparse reward is provided only on task completion. We train our policies in an end-to-end fashion, mapping high-dimensional image observations to low-level robot control commands, and present results in both simulated and real world domains. Additional materials and source code can be found on our project website: https://sites.google.com/view/cog-rl