 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Memorability: Modeling Effects of Semantics and Decay on Video Memorability
Sep 05, 2020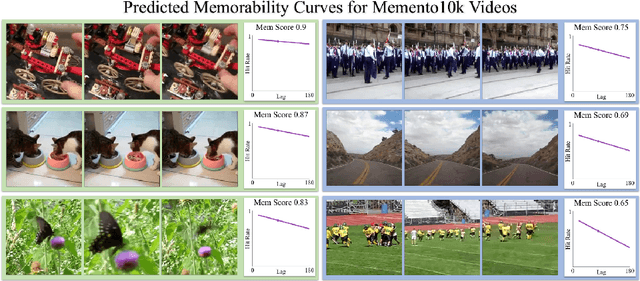
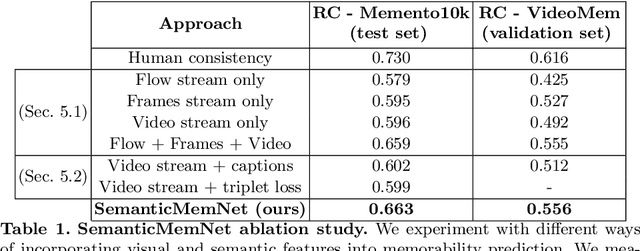


A key capability of an intelligent system is deciding when events from past experience must be remembered and when they can be forgotten. Towards this goal, we develop a predictive model of human visual event memory and how those memories decay over time. We introduce Memento10k, a new, dynamic video memorability dataset containing human annotations at different viewing delays. Based on our findings we propose a new mathematical formulation of memorability decay, resulting in a model that is able to produce the first quantitative estimation of how a video decays in memory over time. In contrast with previous work, our model can predict the probability that a video will be remembered at an arbitrary delay. Importantly, our approach combines visual and semantic information (in the form of textual captions) to fully represent the meaning of events. Our experiments on two video memorability benchmarks, including Memento10k, show that our model significantly improves upon the best prior approach (by 12% on average).
We Have So Much In Common: Modeling Semantic Relational Set Abstractions in Videos
Aug 12, 2020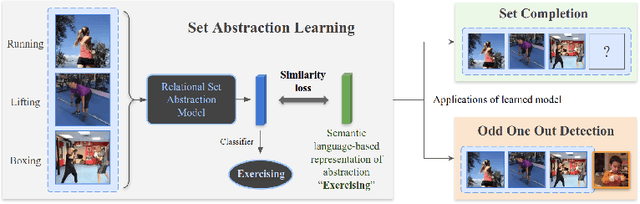
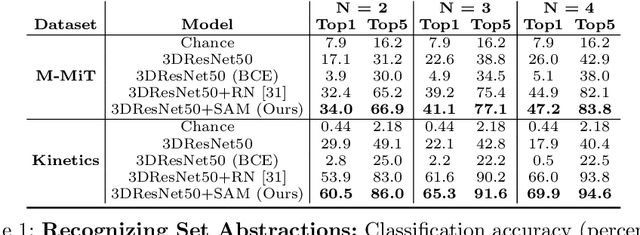

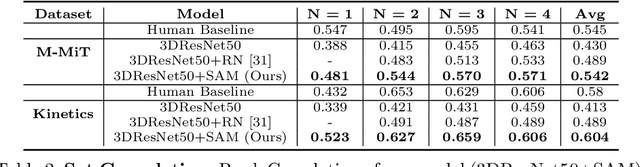
Identifying common patterns among events is a key ability in human and machine perception, as it underlies intelligent decision making. We propose an approach for learning semantic relational set abstractions on videos, inspired by human learning. We combine visual features with natural language supervision to generate high-level representations of similarities across a set of videos. This allows our model to perform cognitive tasks such as set abstraction (which general concept is in common among a set of videos?), set completion (which new video goes well with the set?), and odd one out detection (which video does not belong to the set?). Experiments on two video benchmarks, Kinetics and Multi-Moments in Time, show that robust and versatile representations emerge when learning to recognize commonalities among sets. We compare our model to several baseline algorithms and show that significant improvements result from explicitly learning relational abstractions with semantic supervision.
AR-Net: Adaptive Frame Resolution for Efficient Action Recognition
Jul 31, 2020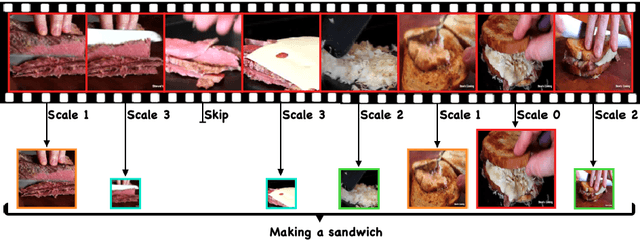
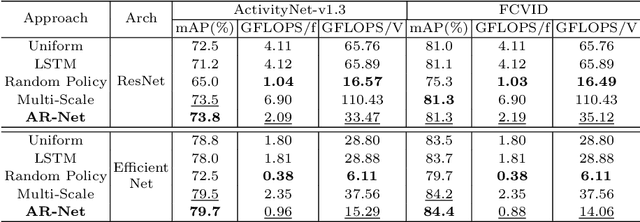

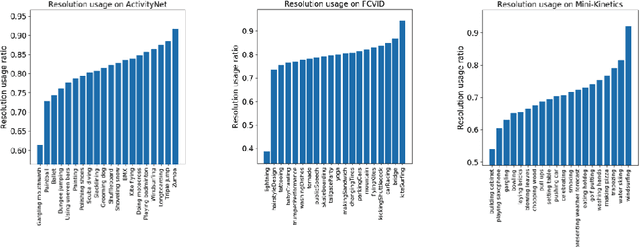
Action recognition is an open and challenging problem in computer vision. While current state-of-the-art models offer excellent recognition results, their computational expense limits their impact for many real-world applications. In this paper, we propose a novel approach, called AR-Net (Adaptive Resolution Network), that selects on-the-fly the optimal resolution for each frame conditioned on the input for efficient action recognition in long untrimmed videos. Specifically, given a video frame, a policy network is used to decide what input resolution should be used for processing by the action recognition model, with the goal of improving both accuracy and efficiency. We efficiently train the policy network jointly with the recognition model using standard back-propagation. Extensive experiments on several challenging action recognition benchmark datasets well demonstrate the efficacy of our proposed approach over state-of-the-art methods. The project page can be found at https://mengyuest.github.io/AR-Net
Multi-Moments in Time: Learning and Interpreting Models for Multi-Action Video Understanding
Nov 04, 2019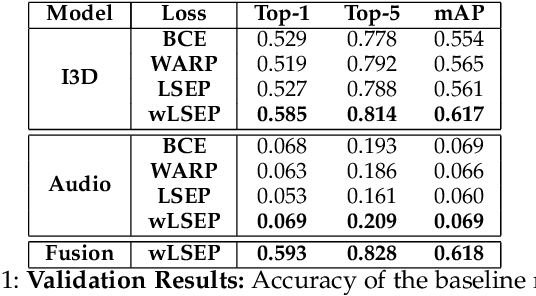


An event happening in the world is often made of different activities and actions that can unfold simultaneously or sequentially within a few seconds. However, most large-scale datasets built to train models for action recognition provide a single label per video clip. Consequently, models can be incorrectly penalized for classifying actions that exist in the videos but are not explicitly labeled and do not learn the full spectrum of information that would be mandatory to more completely comprehend different events and eventually learn causality between them. Towards this goal, we augmented the existing video dataset, Moments in Time (MiT), to include over two million action labels for over one million three second videos. This multi-label dataset introduces novel challenges on how to train and analyze models for multi-action detection. Here, we present baseline results for multi-action recognition using loss functions adapted for long tail multi-label learning and provide improved methods for visualizing and interpreting models trained for multi-label action detection.
Reasoning About Human-Object Interactions Through Dual Attention Networks
Sep 10, 2019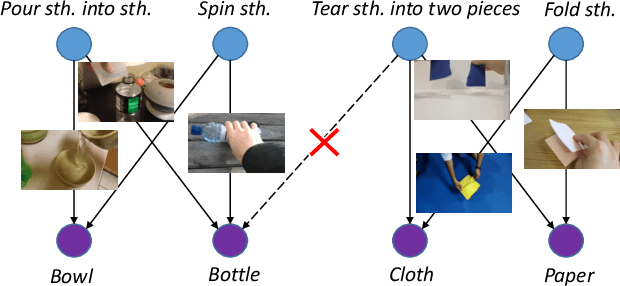

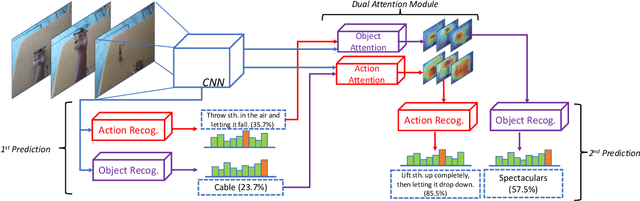
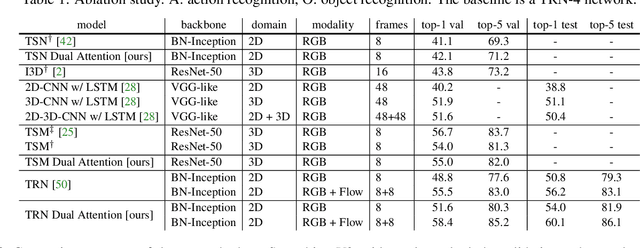
Objects are entities we act upon, where the functionality of an object is determined by how we interact with it. In this work we propose a Dual Attention Network model which reasons about human-object interactions. The dual-attentional framework weights the important features for objects and actions respectively. As a result, the recognition of objects and actions mutually benefit each other. The proposed model shows competitive classification performance on the human-object interaction dataset Something-Something. Besides, it can perform weak spatiotemporal localization and affordance segmentation, despite being trained only with video-level labels. The model not only finds when an action is happening and which object is being manipulated, but also identifies which part of the object is being interacted with. Project page: \url{https://dual-attention-network.github.io/}.
GANalyze: Toward Visual Definitions of Cognitive Image Properties
Jun 24, 2019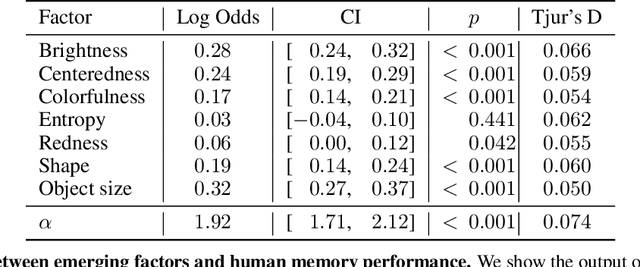

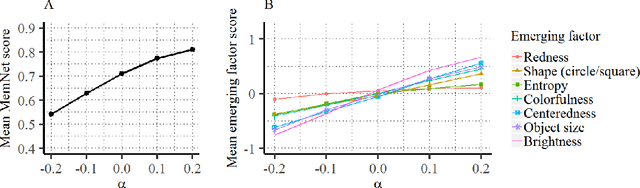
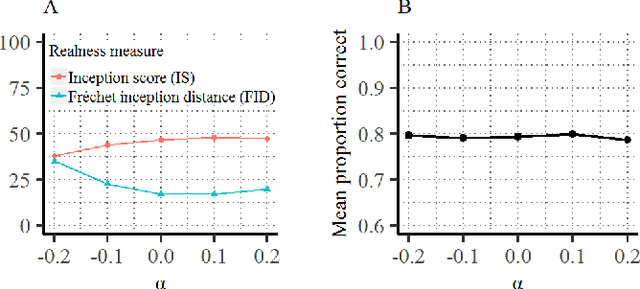
We introduce a framework that uses Generative Adversarial Networks (GANs) to study cognitive properties like memorability, aesthetics, and emotional valence. These attributes are of interest because we do not have a concrete visual definition of what they entail. What does it look like for a dog to be more or less memorable? GANs allow us to generate a manifold of natural-looking images with fine-grained differences in their visual attributes. By navigating this manifold in directions that increase memorability, we can visualize what it looks like for a particular generated image to become more or less memorable. The resulting ``visual definitions" surface image properties (like ``object size") that may underlie memorability. Through behavioral experiments, we verify that our method indeed discovers image manipulations that causally affect human memory performance. We further demonstrate that the same framework can be used to analyze image aesthetics and emotional valence. Visit the GANalyze website at http://ganalyze.csail.mit.edu/.
Cross-view Semantic Segmentation for Sensing Surroundings
Jun 09, 2019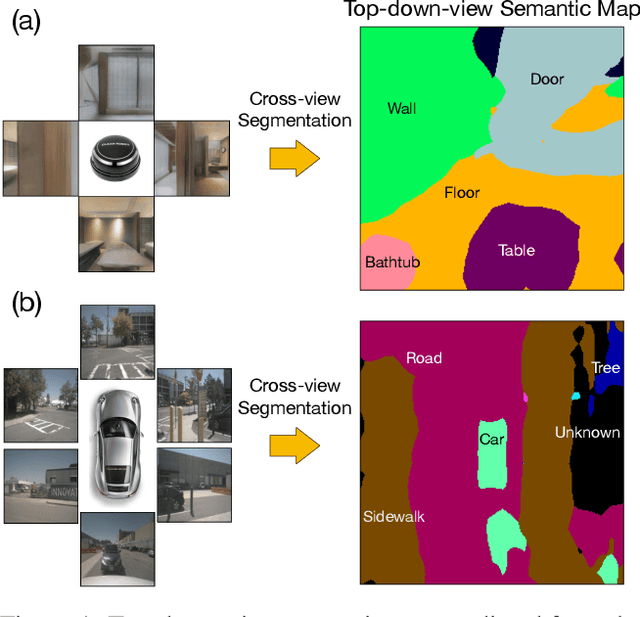
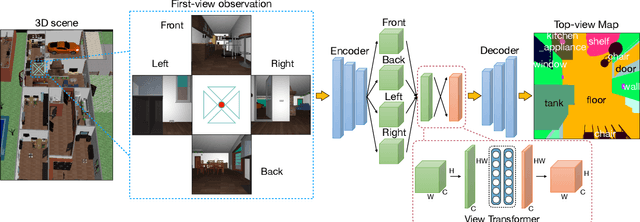
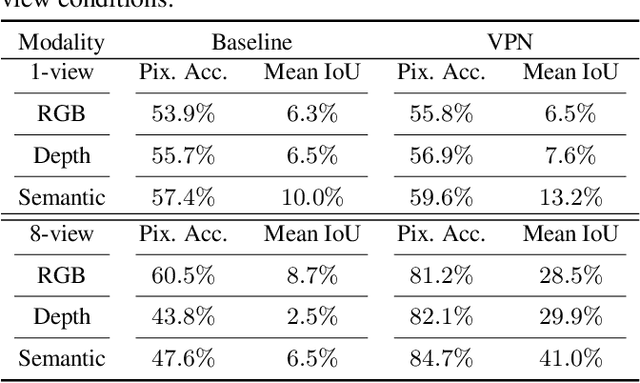
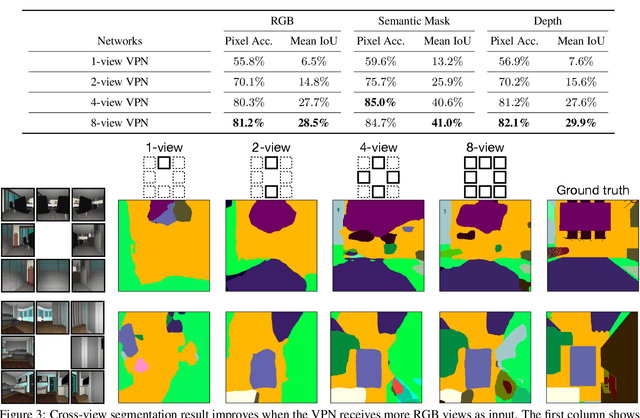
Sensing surroundings is ubiquitous and effortless to humans: It takes a single glance to extract the spatial configuration of objects and the free space from the scene. To help machine vision with spatial understanding capabilities, we introduce the View Parsing Network (VPN) for cross-view semantic segmentation. In this framework, the first-view observations are parsed into a top-down-view semantic map indicating precise object locations. VPN contains a view transformer module, designed to aggregate the first-view observations taken from multiple angles and modalities, in order to draw a bird-view semantic map. We evaluate the VPN framework for cross-view segmentation on two types of environments, indoors and driving-traffic scenes. Experimental results show that our model accurately predicts the top-down-view semantic mask of the visible objects from the first-view observations, as well as infer the location of contextually-relevant objects even if they are invisible.
The Algonauts Project: A Platform for Communication between the Sciences of Biological and Artificial Intelligence
May 14, 2019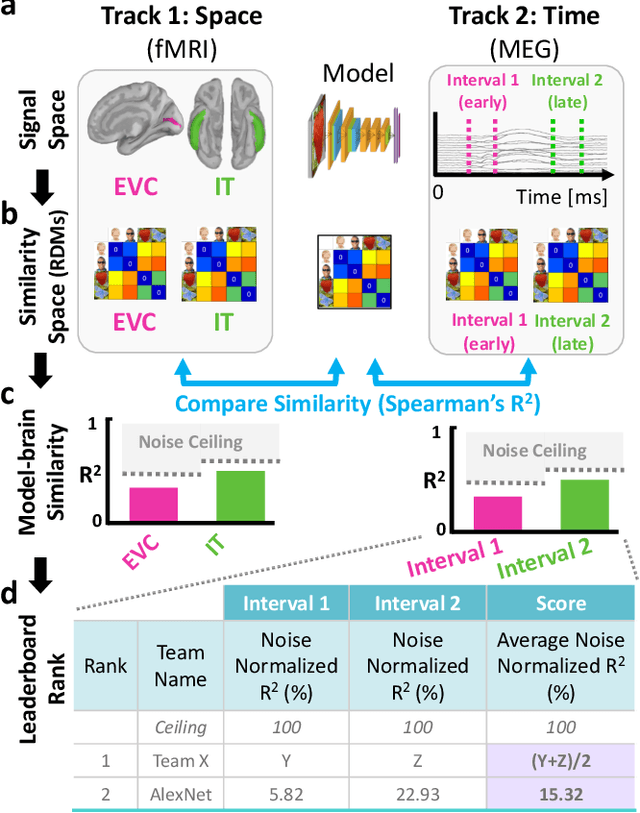

In the last decade, artificial intelligence (AI) models inspired by the brain have made unprecedented progress in performing real-world perceptual tasks like object classification and speech recognition. Recently, researchers of natural intelligence have begun using those AI models to explore how the brain performs such tasks. These developments suggest that future progress will benefit from increased interaction between disciplines. Here we introduce the Algonauts Project as a structured and quantitative communication channel for interdisciplinary interaction between natural and artificial intelligence researchers. The project's core is an open challenge with a quantitative benchmark whose goal is to account for brain data through computational models. This project has the potential to provide better models of natural intelligence and to gather findings that advance AI. The 2019 Algonauts Project focuses on benchmarking computational models predicting human brain activity when people look at pictures of objects. The 2019 edition of the Algonauts Project is available online: http://algonauts.csail.mit.edu/.
Synthetically Trained Icon Proposals for Parsing and Summarizing Infographics
Jul 27, 2018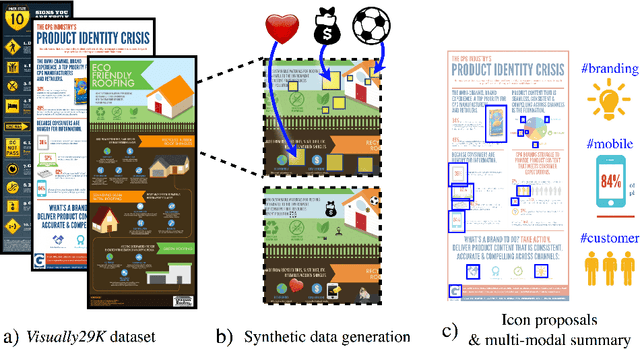
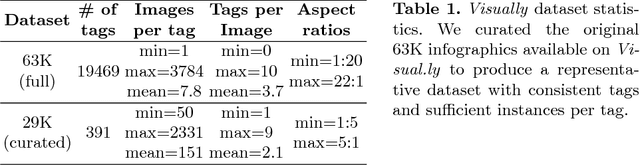

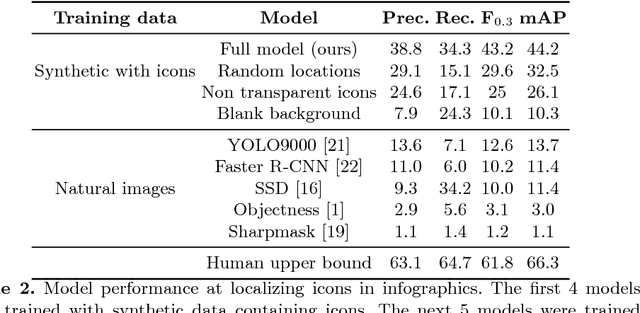
Widely used in news, business, and educational media, infographics are handcrafted to effectively communicate messages about complex and often abstract topics including `ways to conserve the environment' and `understanding the financial crisis'. Composed of stylistically and semantically diverse visual and textual elements, infographics pose new challenges for computer vision. While automatic text extraction works well on infographics, computer vision approaches trained on natural images fail to identify the stand-alone visual elements in infographics, or `icons'. To bridge this representation gap, we propose a synthetic data generation strategy: we augment background patches in infographics from our Visually29K dataset with Internet-scraped icons which we use as training data for an icon proposal mechanism. On a test set of 1K annotated infographics, icons are located with 38% precision and 34% recall (the best model trained with natural images achieves 14% precision and 7% recall). Combining our icon proposals with icon classification and text extraction, we present a multi-modal summarization application. Our application takes an infographic as input and automatically produces text tags and visual hashtags that are textually and visually representative of the infographic's topics respectively.
Temporal Relational Reasoning in Videos
Jul 25, 2018
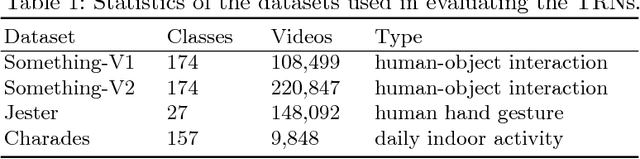
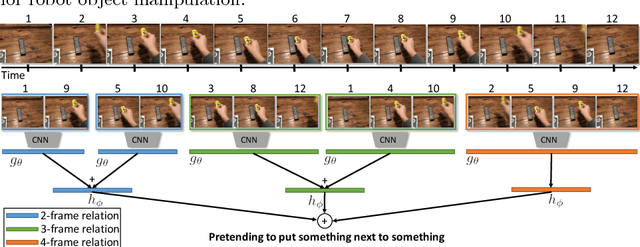

Temporal relational reasoning, the ability to link meaningful transformations of objects or entities over time, is a fundamental property of intelligent species. In this paper, we introduce an effective and interpretable network module, the Temporal Relation Network (TRN), designed to learn and reason about temporal dependencies between video frames at multiple time scales. We evaluate TRN-equipped networks on activity recognition tasks using three recent video datasets - Something-Something, Jester, and Charades - which fundamentally depend on temporal relational reasoning. Our results demonstrate that the proposed TRN gives convolutional neural networks a remarkable capacity to discover temporal relations in videos. Through only sparsely sampled video frames, TRN-equipped networks can accurately predict human-object interactions in the Something-Something dataset and identify various human gestures on the Jester dataset with very competitive performance. TRN-equipped networks also outperform two-stream networks and 3D convolution networks in recognizing daily activities in the Charades dataset. Further analyses show that the models learn intuitive and interpretable visual common sense knowledge in videos.