 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of The MediaEval 2022 Predicting Video Memorability Task
Dec 13, 2022This paper describes the 5th edition of the Predicting Video Memorability Task as part of MediaEval2022. This year we have reorganised and simplified the task in order to lubricate a greater depth of inquiry. Similar to last year, two datasets are provided in order to facilitate generalisation, however, this year we have replaced the TRECVid2019 Video-to-Text dataset with the VideoMem dataset in order to remedy underlying data quality issues, and to prioritise short-term memorability prediction by elevating the Memento10k dataset as the primary dataset. Additionally, a fully fledged electroencephalography (EEG)-based prediction sub-task is introduced. In this paper, we outline the core facets of the task and its constituent sub-tasks; describing the datasets, evaluation metrics, and requirements for participant submissions.
Experiences from the MediaEval Predicting Media Memorability Task
Dec 07, 2022


The Predicting Media Memorability task in the MediaEval evaluation campaign has been running annually since 2018 and several different tasks and data sets have been used in this time. This has allowed us to compare the performance of many memorability prediction techniques on the same data and in a reproducible way and to refine and improve on those techniques. The resources created to compute media memorability are now being used by researchers well beyond the actual evaluation campaign. In this paper we present a summary of the task, including the collective lessons we have learned for the research community.
Deepfake Caricatures: Amplifying attention to artifacts increases deepfake detection by humans and machines
Jun 02, 2022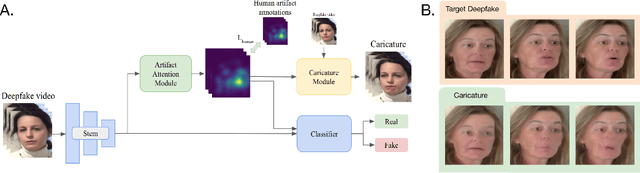
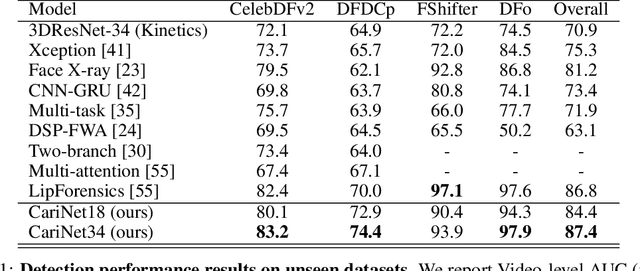

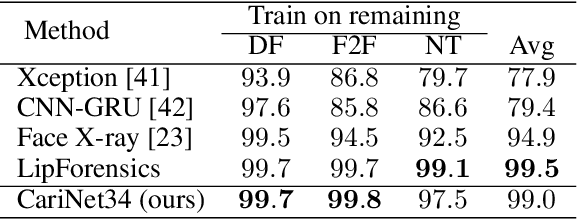
Deepfakes pose a serious threat to our digital society by fueling the spread of misinformation. It is essential to develop techniques that both detect them, and effectively alert the human user to their presence. Here, we introduce a novel deepfake detection framework that meets both of these needs. Our approach learns to generate attention maps of video artifacts, semi-supervised on human annotations. These maps make two contributions. First, they improve the accuracy and generalizability of a deepfake classifier, demonstrated across several deepfake detection datasets. Second, they allow us to generate an intuitive signal for the human user, in the form of "Deepfake Caricatures": transformations of the original deepfake video where attended artifacts are exacerbated to improve human recognition. Our approach, based on a mixture of human and artificial supervision, aims to further the development of countermeasures against fake visual content, and grants humans the ability to make their own judgment when presented with dubious visual media.
Overview of The MediaEval 2021 Predicting Media Memorability Task
Dec 11, 2021This paper describes the MediaEval 2021 Predicting Media Memorability}task, which is in its 4th edition this year, as the prediction of short-term and long-term video memorability remains a challenging task. In 2021, two datasets of videos are used: first, a subset of the TRECVid 2019 Video-to-Text dataset; second, the Memento10K dataset in order to provide opportunities to explore cross-dataset generalisation. In addition, an Electroencephalography (EEG)-based prediction pilot subtask is introduced. In this paper, we outline the main aspects of the task and describe the datasets, evaluation metrics, and requirements for participants' submissions.
VA-RED$^2$: Video Adaptive Redundancy Reduction
Feb 15, 2021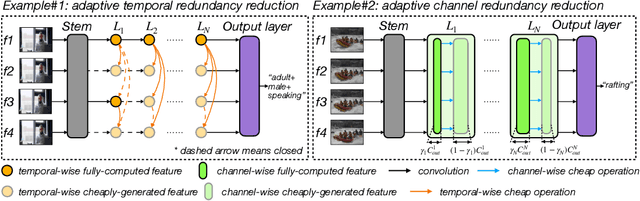
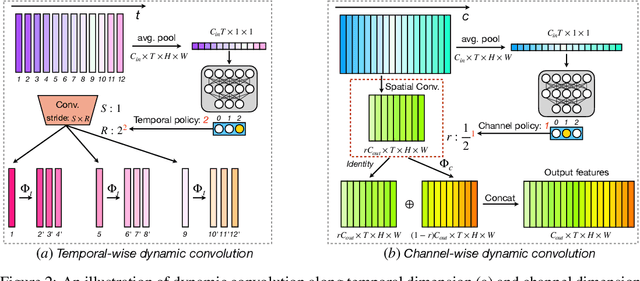
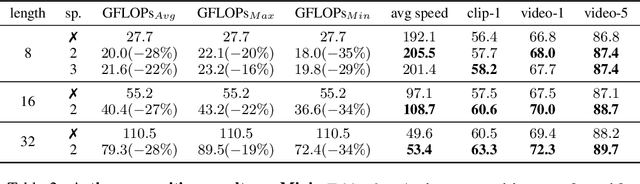
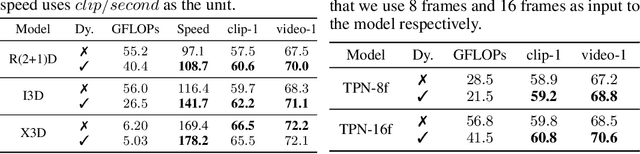
Performing inference on deep learning models for videos remains a challenge due to the large amount of computational resources required to achieve robust recognition. An inherent property of real-world videos is the high correlation of information across frames which can translate into redundancy in either temporal or spatial feature maps of the models, or both. The type of redundant features depends on the dynamics and type of events in the video: static videos have more temporal redundancy while videos focusing on objects tend to have more channel redundancy. Here we present a redundancy reduction framework, termed VA-RED$^2$, which is input-dependent. Specifically, our VA-RED$^2$ framework uses an input-dependent policy to decide how many features need to be computed for temporal and channel dimensions. To keep the capacity of the original model, after fully computing the necessary features, we reconstruct the remaining redundant features from those using cheap linear operations. We learn the adaptive policy jointly with the network weights in a differentiable way with a shared-weight mechanism, making it highly efficient. Extensive experiments on multiple video datasets and different visual tasks show that our framework achieves $20\% - 40\%$ reduction in computation (FLOPs) when compared to state-of-the-art methods without any performance loss. Project page: http://people.csail.mit.edu/bpan/va-red/.
Multimodal Memorability: Modeling Effects of Semantics and Decay on Video Memorability
Sep 05, 2020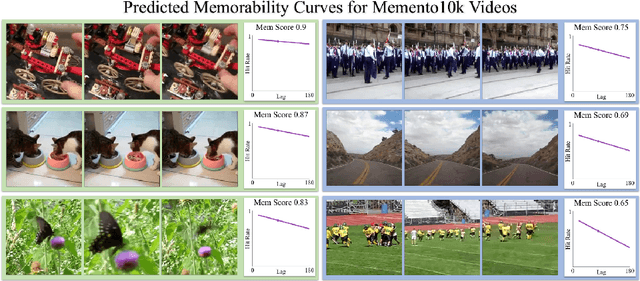
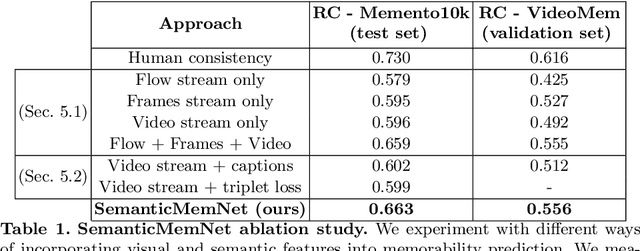


A key capability of an intelligent system is deciding when events from past experience must be remembered and when they can be forgotten. Towards this goal, we develop a predictive model of human visual event memory and how those memories decay over time. We introduce Memento10k, a new, dynamic video memorability dataset containing human annotations at different viewing delays. Based on our findings we propose a new mathematical formulation of memorability decay, resulting in a model that is able to produce the first quantitative estimation of how a video decays in memory over time. In contrast with previous work, our model can predict the probability that a video will be remembered at an arbitrary delay. Importantly, our approach combines visual and semantic information (in the form of textual captions) to fully represent the meaning of events. Our experiments on two video memorability benchmarks, including Memento10k, show that our model significantly improves upon the best prior approach (by 12% on average).
We Have So Much In Common: Modeling Semantic Relational Set Abstractions in Videos
Aug 12, 2020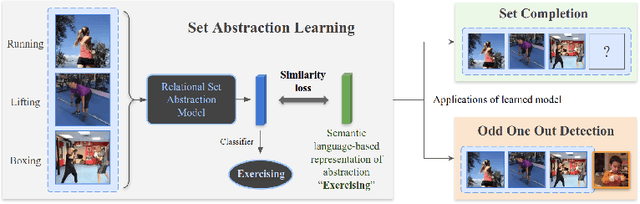
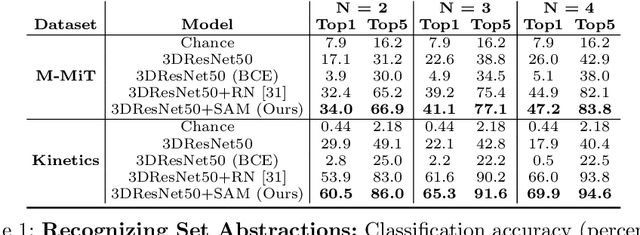

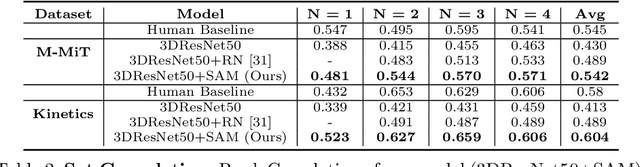
Identifying common patterns among events is a key ability in human and machine perception, as it underlies intelligent decision making. We propose an approach for learning semantic relational set abstractions on videos, inspired by human learning. We combine visual features with natural language supervision to generate high-level representations of similarities across a set of videos. This allows our model to perform cognitive tasks such as set abstraction (which general concept is in common among a set of videos?), set completion (which new video goes well with the set?), and odd one out detection (which video does not belong to the set?). Experiments on two video benchmarks, Kinetics and Multi-Moments in Time, show that robust and versatile representations emerge when learning to recognize commonalities among sets. We compare our model to several baseline algorithms and show that significant improvements result from explicitly learning relational abstractions with semantic supervision.
Predicting Visual Importance Across Graphic Design Types
Aug 07, 2020
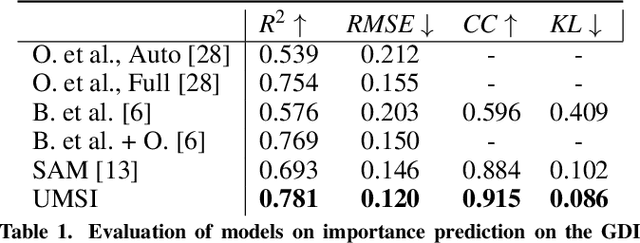
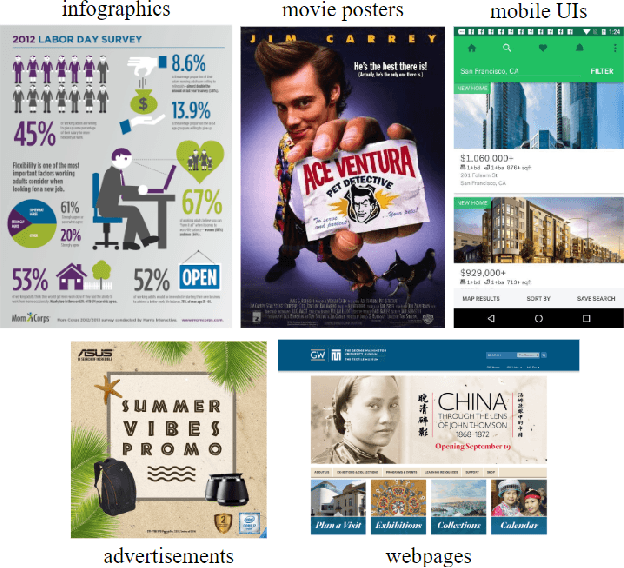
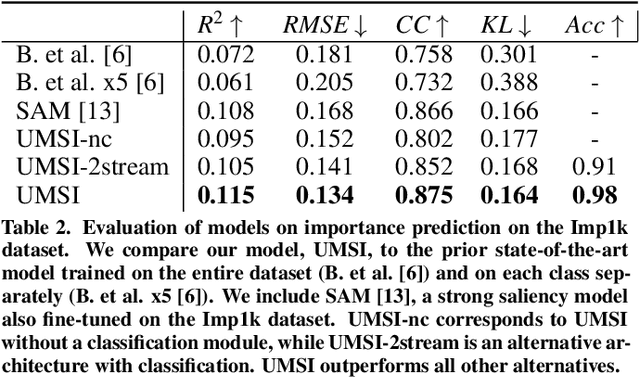
This paper introduces a Unified Model of Saliency and Importance (UMSI), which learns to predict visual importance in input graphic designs, and saliency in natural images, along with a new dataset and applications. Previous methods for predicting saliency or visual importance are trained individually on specialized datasets, making them limited in application and leading to poor generalization on novel image classes, while requiring a user to know which model to apply to which input. UMSI is a deep learning-based model simultaneously trained on images from different design classes, including posters, infographics, mobile UIs, as well as natural images, and includes an automatic classification module to classify the input. This allows the model to work more effectively without requiring a user to label the input. We also introduce Imp1k, a new dataset of designs annotated with importance information. We demonstrate two new design interfaces that use importance prediction, including a tool for adjusting the relative importance of design elements, and a tool for reflowing designs to new aspect ratios while preserving visual importance. The model, code, and importance dataset are available at https://predimportance.mit.edu .