 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIA-RED$^2$: Interpretability-Aware Redundancy Reduction for Vision Transformers
Jun 23, 2021
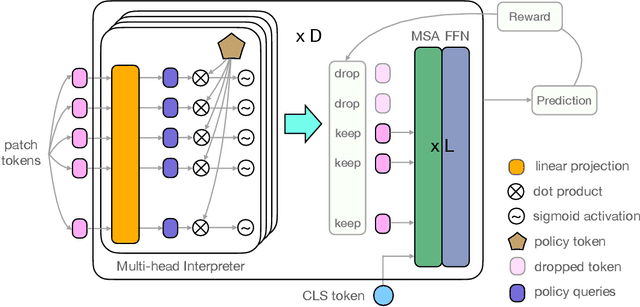
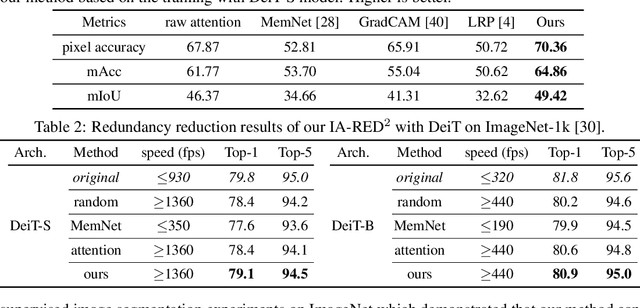
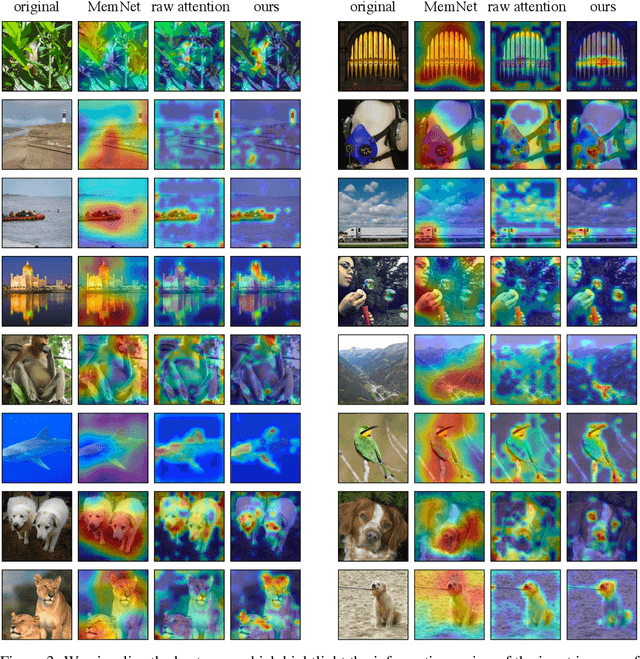
The self-attention-based model, transformer, is recently becoming the leading backbone in the field of computer vision. In spite of the impressive success made by transformers in a variety of vision tasks, it still suffers from heavy computation and intensive memory cost. To address this limitation, this paper presents an Interpretability-Aware REDundancy REDuction framework (IA-RED$^2$). We start by observing a large amount of redundant computation, mainly spent on uncorrelated input patches, and then introduce an interpretable module to dynamically and gracefully drop these redundant patches. This novel framework is then extended to a hierarchical structure, where uncorrelated tokens at different stages are gradually removed, resulting in a considerable shrinkage of computational cost. We include extensive experiments on both image and video tasks, where our method could deliver up to 1.4X speed-up for state-of-the-art models like DeiT and TimeSformer, by only sacrificing less than 0.7% accuracy. More importantly, contrary to other acceleration approaches, our method is inherently interpretable with substantial visual evidence, making vision transformer closer to a more human-understandable architecture while being lighter. We demonstrate that the interpretability that naturally emerged in our framework can outperform the raw attention learned by the original visual transformer, as well as those generated by off-the-shelf interpretation methods, with both qualitative and quantitative results. Project Page: http://people.csail.mit.edu/bpan/ia-red/.
Cross-Modal Discrete Representation Learning
Jun 10, 2021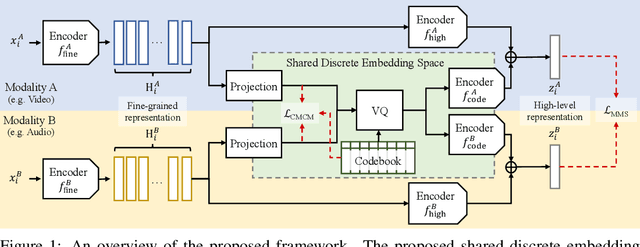
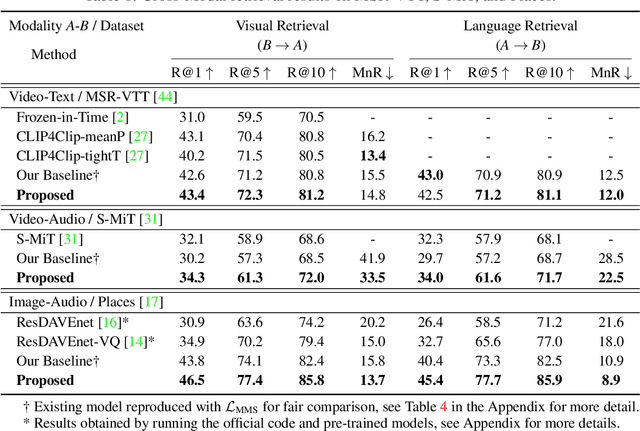
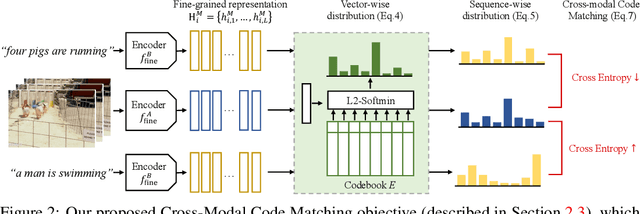
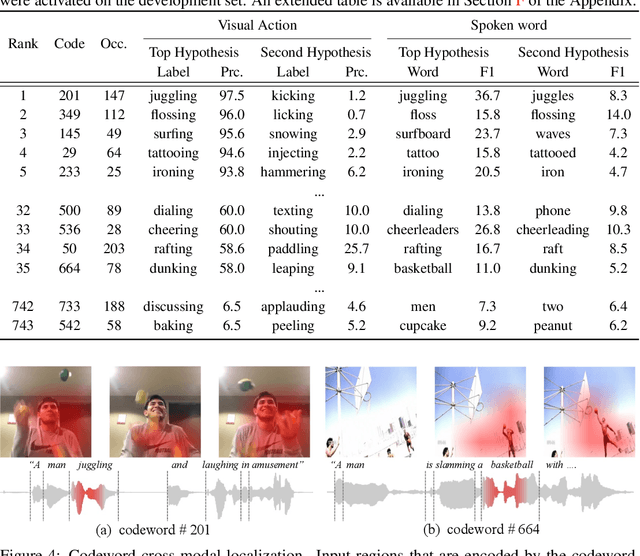
Recent advances in representation learning have demonstrated an ability to represent information from different modalities such as video, text, and audio in a single high-level embedding vector. In this work we present a self-supervised learning framework that is able to learn a representation that captures finer levels of granularity across different modalities such as concepts or events represented by visual objects or spoken words. Our framework relies on a discretized embedding space created via vector quantization that is shared across different modalities. Beyond the shared embedding space, we propose a Cross-Modal Code Matching objective that forces the representations from different views (modalities) to have a similar distribution over the discrete embedding space such that cross-modal objects/actions localization can be performed without direct supervision. In our experiments we show that the proposed discretized multi-modal fine-grained representation (e.g., pixel/word/frame) can complement high-level summary representations (e.g., video/sentence/waveform) for improved performance on cross-modal retrieval tasks. We also observe that the discretized representation uses individual clusters to represent the same semantic concept across modalities.
AdaMML: Adaptive Multi-Modal Learning for Efficient Video Recognition
May 12, 2021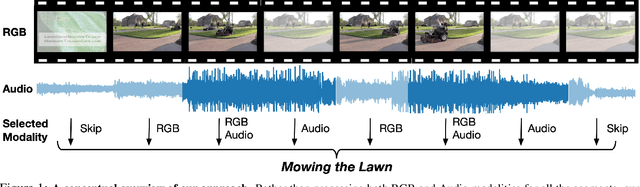
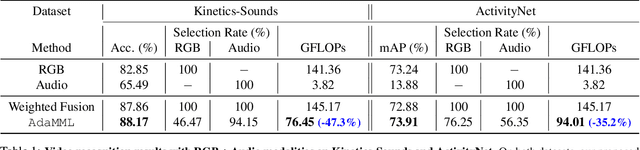
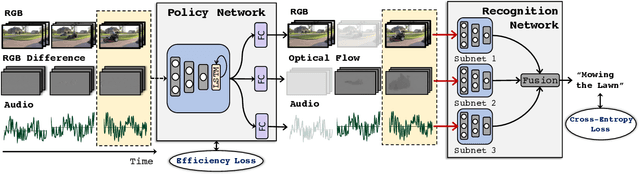
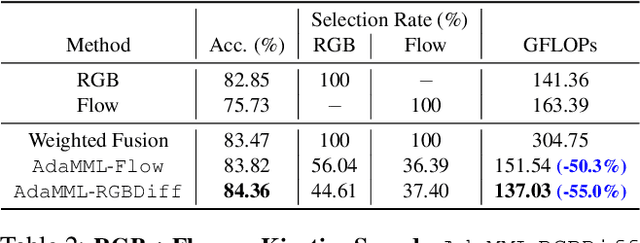
Multi-modal learning, which focuses on utilizing various modalities to improve the performance of a model, is widely used in video recognition. While traditional multi-modal learning offers excellent recognition results, its computational expense limits its impact for many real-world applications. In this paper, we propose an adaptive multi-modal learning framework, called AdaMML, that selects on-the-fly the optimal modalities for each segment conditioned on the input for efficient video recognition. Specifically, given a video segment, a multi-modal policy network is used to decide what modalities should be used for processing by the recognition model, with the goal of improving both accuracy and efficiency. We efficiently train the policy network jointly with the recognition model using standard back-propagation. Extensive experiments on four challenging diverse datasets demonstrate that our proposed adaptive approach yields 35%-55% reduction in computation when compared to the traditional baseline that simply uses all the modalities irrespective of the input, while also achieving consistent improvements in accuracy over the state-of-the-art methods.
Spoken Moments: Learning Joint Audio-Visual Representations from Video Descriptions
May 10, 2021

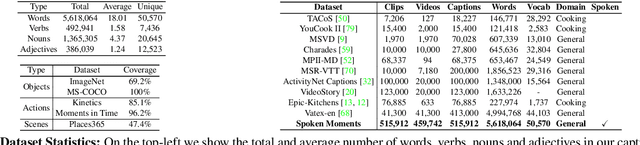
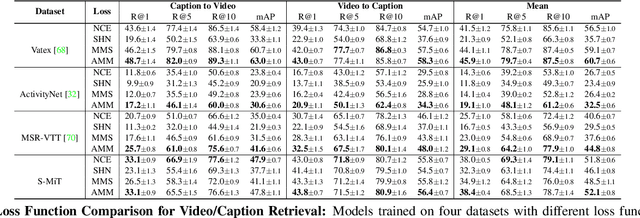
When people observe events, they are able to abstract key information and build concise summaries of what is happening. These summaries include contextual and semantic information describing the important high-level details (what, where, who and how) of the observed event and exclude background information that is deemed unimportant to the observer. With this in mind, the descriptions people generate for videos of different dynamic events can greatly improve our understanding of the key information of interest in each video. These descriptions can be captured in captions that provide expanded attributes for video labeling (e.g. actions/objects/scenes/sentiment/etc.) while allowing us to gain new insight into what people find important or necessary to summarize specific events. Existing caption datasets for video understanding are either small in scale or restricted to a specific domain. To address this, we present the Spoken Moments (S-MiT) dataset of 500k spoken captions each attributed to a unique short video depicting a broad range of different events. We collect our descriptions using audio recordings to ensure that they remain as natural and concise as possible while allowing us to scale the size of a large classification dataset. In order to utilize our proposed dataset, we present a novel Adaptive Mean Margin (AMM) approach to contrastive learning and evaluate our models on video/caption retrieval on multiple datasets. We show that our AMM approach consistently improves our results and that models trained on our Spoken Moments dataset generalize better than those trained on other video-caption datasets.
Memorability: An image-computable measure of information utility
Apr 01, 2021
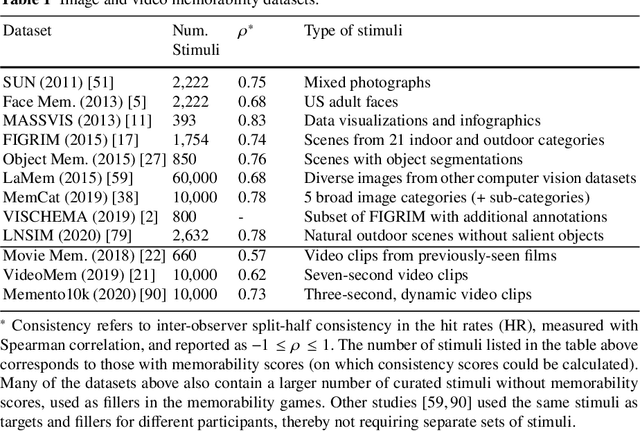

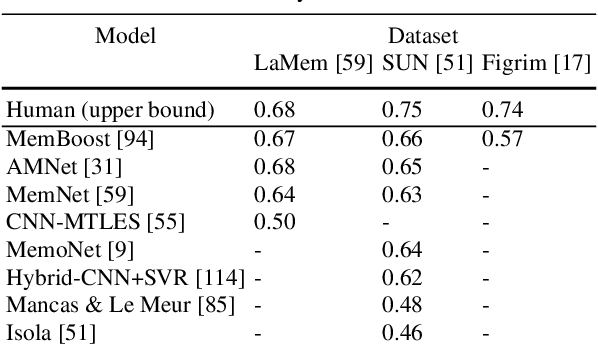
The pixels in an image, and the objects, scenes, and actions that they compose, determine whether an image will be memorable or forgettable. While memorability varies by image, it is largely independent of an individual observer. Observer independence is what makes memorability an image-computable measure of information, and eligible for automatic prediction. In this chapter, we zoom into memorability with a computational lens, detailing the state-of-the-art algorithms that accurately predict image memorability relative to human behavioral data, using image features at different scales from raw pixels to semantic labels. We discuss the design of algorithms and visualizations for face, object, and scene memorability, as well as algorithms that generalize beyond static scenes to actions and videos. We cover the state-of-the-art deep learning approaches that are the current front runners in the memorability prediction space. Beyond prediction, we show how recent A.I. approaches can be used to create and modify visual memorability. Finally, we preview the computational applications that memorability can power, from filtering visual streams to enhancing augmented reality interfaces.
Paint by Word
Mar 24, 2021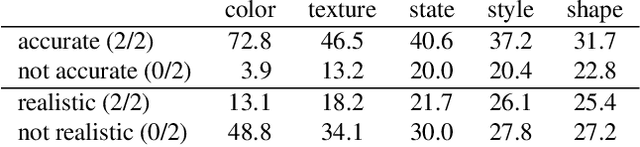
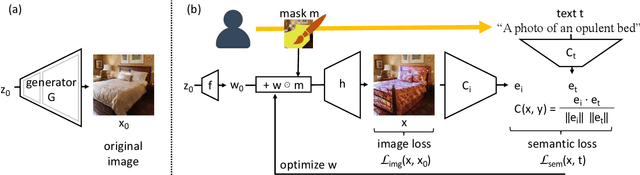

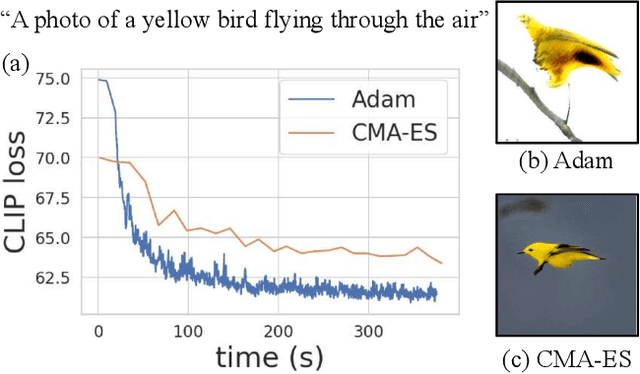
We investigate the problem of zero-shot semantic image painting. Instead of painting modifications into an image using only concrete colors or a finite set of semantic concepts, we ask how to create semantic paint based on open full-text descriptions: our goal is to be able to point to a location in a synthesized image and apply an arbitrary new concept such as "rustic" or "opulent" or "happy dog." To do this, our method combines a state-of-the art generative model of realistic images with a state-of-the-art text-image semantic similarity network. We find that, to make large changes, it is important to use non-gradient methods to explore latent space, and it is important to relax the computations of the GAN to target changes to a specific region. We conduct user studies to compare our methods to several baselines.
All at Once Network Quantization via Collaborative Knowledge Transfer
Mar 02, 2021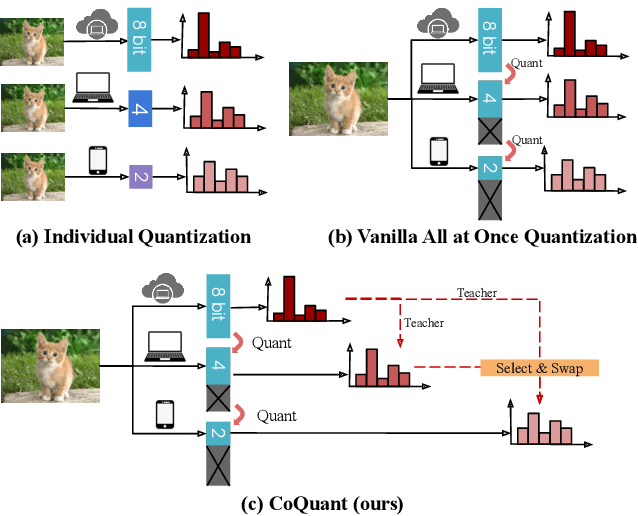
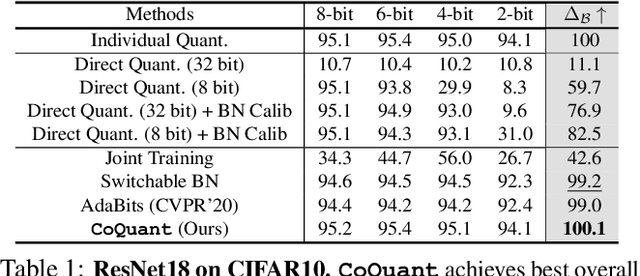
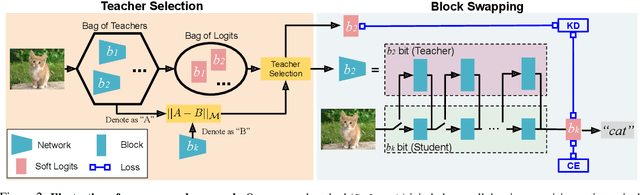
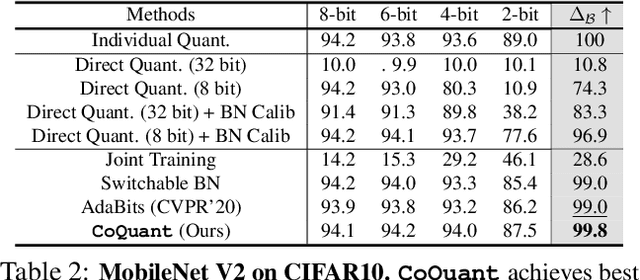
Network quantization has rapidly become one of the most widely used methods to compress and accelerate deep neural networks on edge devices. While existing approaches offer impressive results on common benchmark datasets, they generally repeat the quantization process and retrain the low-precision network from scratch, leading to different networks tailored for different resource constraints. This limits scalable deployment of deep networks in many real-world applications, where in practice dynamic changes in bit-width are often desired. All at Once quantization addresses this problem, by flexibly adjusting the bit-width of a single deep network during inference, without requiring re-training or additional memory to store separate models, for instant adaptation in different scenarios. In this paper, we develop a novel collaborative knowledge transfer approach for efficiently training the all-at-once quantization network. Specifically, we propose an adaptive selection strategy to choose a high-precision \enquote{teacher} for transferring knowledge to the low-precision student while jointly optimizing the model with all bit-widths. Furthermore, to effectively transfer knowledge, we develop a dynamic block swapping method by randomly replacing the blocks in the lower-precision student network with the corresponding blocks in the higher-precision teacher network. Extensive experiments on several challenging and diverse datasets for both image and video classification well demonstrate the efficacy of our proposed approach over state-of-the-art methods.
VA-RED$^2$: Video Adaptive Redundancy Reduction
Feb 15, 2021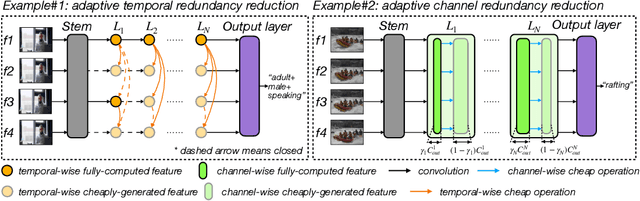
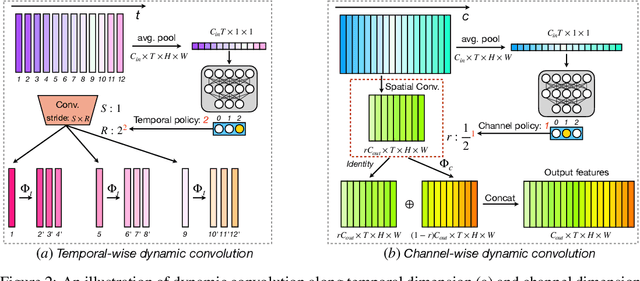
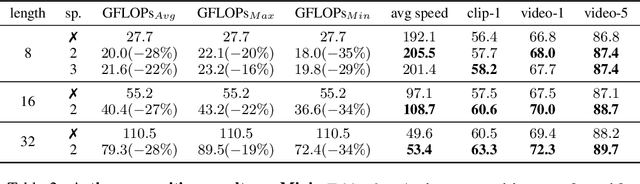
Performing inference on deep learning models for videos remains a challenge due to the large amount of computational resources required to achieve robust recognition. An inherent property of real-world videos is the high correlation of information across frames which can translate into redundancy in either temporal or spatial feature maps of the models, or both. The type of redundant features depends on the dynamics and type of events in the video: static videos have more temporal redundancy while videos focusing on objects tend to have more channel redundancy. Here we present a redundancy reduction framework, termed VA-RED$^2$, which is input-dependent. Specifically, our VA-RED$^2$ framework uses an input-dependent policy to decide how many features need to be computed for temporal and channel dimensions. To keep the capacity of the original model, after fully computing the necessary features, we reconstruct the remaining redundant features from those using cheap linear operations. We learn the adaptive policy jointly with the network weights in a differentiable way with a shared-weight mechanism, making it highly efficient. Extensive experiments on multiple video datasets and different visual tasks show that our framework achieves $20\% - 40\%$ reduction in computation (FLOPs) when compared to state-of-the-art methods without any performance loss. Project page: http://people.csail.mit.edu/bpan/va-red/.
AdaFuse: Adaptive Temporal Fusion Network for Efficient Action Recognition
Feb 10, 2021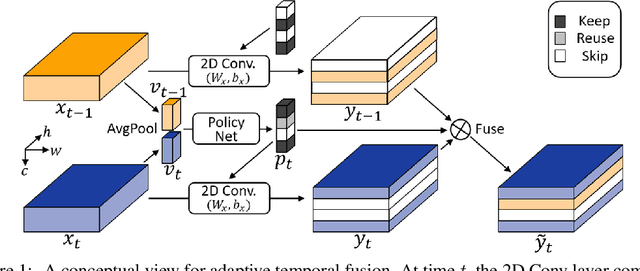

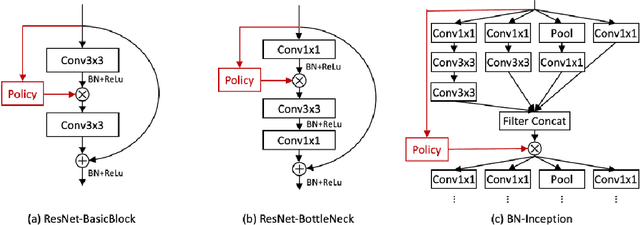
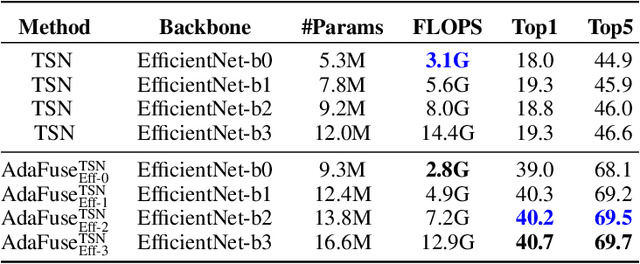
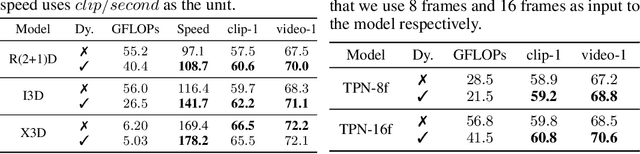
Temporal modelling is the key for efficient video action recognition. While understanding temporal information can improve recognition accuracy for dynamic actions, removing temporal redundancy and reusing past features can significantly save computation leading to efficient action recognition. In this paper, we introduce an adaptive temporal fusion network, called AdaFuse, that dynamically fuses channels from current and past feature maps for strong temporal modelling. Specifically, the necessary information from the historical convolution feature maps is fused with current pruned feature maps with the goal of improving both recognition accuracy and efficiency. In addition, we use a skipping operation to further reduce the computation cost of action recognition. Extensive experiments on Something V1 & V2, Jester and Mini-Kinetics show that our approach can achieve about 40% computation savings with comparable accuracy to state-of-the-art methods. The project page can be found at https://mengyuest.github.io/AdaFuse/
Deep Analysis of CNN-based Spatio-temporal Representations for Action Recognition
Oct 23, 2020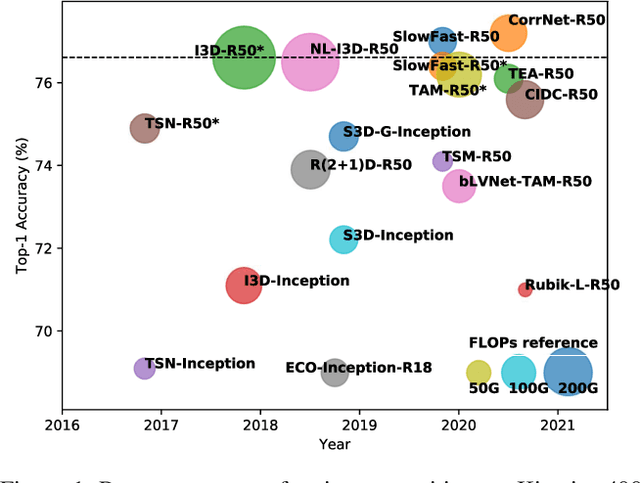
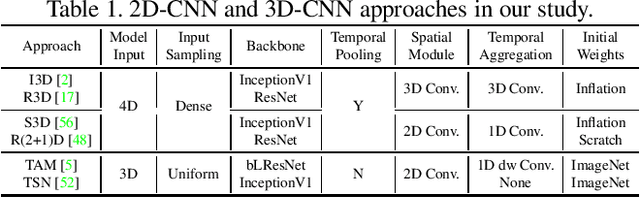
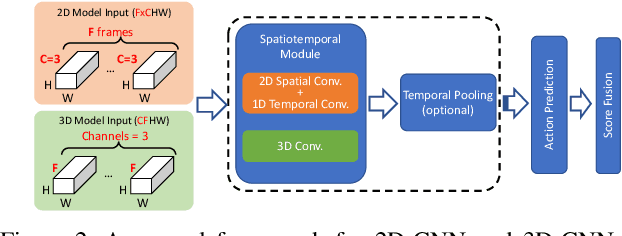
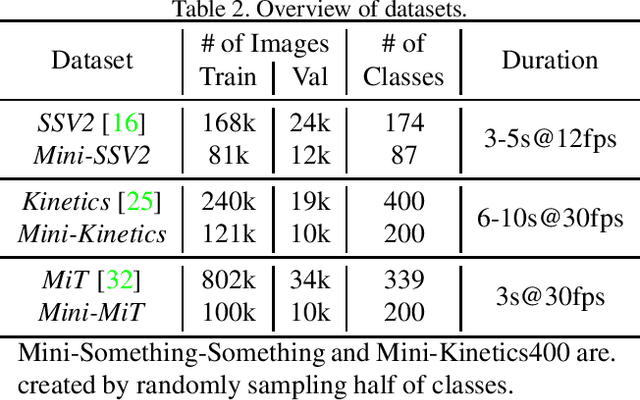
In recent years, a number of approaches based on 2D CNNs and 3D CNNs have emerged for video action recognition, achieving state-of-the-art results on several large-scale benchmark datasets. In this paper, we carry out an in-depth comparative analysis to better understand the differences between these approaches and the progress made by them. To this end, we develop a unified framework for both 2D-CNN and 3D-CNN action models, which enables us to remove bells and whistles and provides a common ground for a fair comparison. We then conduct an effort towards a large-scale analysis involving over 300 action recognition models. Our comprehensive analysis reveals that a) a significant leap is made in efficiency for action recognition, but not in accuracy; b) 2D-CNN and 3D-CNN models behave similarly in terms of spatio-temporal representation abilities and transferability. Our analysis also shows that recent action models seem to be able to learn data-dependent temporality flexibly as needed. Our codes and models are available on https://github.com/IBM/action-recognition-pytorch.