 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmented Language Models: a Survey
Feb 15, 2023



This survey reviews works in which language models (LMs) are augmented with reasoning skills and the ability to use tools. The former is defined as decomposing a potentially complex task into simpler subtasks while the latter consists in calling external modules such as a code interpreter. LMs can leverage these augmentations separately or in combination via heuristics, or learn to do so from demonstrations. While adhering to a standard missing tokens prediction objective, such augmented LMs can use various, possibly non-parametric external modules to expand their context processing ability, thus departing from the pure language modeling paradigm. We therefore refer to them as Augmented Language Models (ALMs). The missing token objective allows ALMs to learn to reason, use tools, and even act, while still performing standard natural language tasks and even outperforming most regular LMs on several benchmarks. In this work, after reviewing current advance in ALMs, we conclude that this new research direction has the potential to address common limitations of traditional LMs such as interpretability, consistency, and scalability issues.
OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization
Dec 28, 2022



Recent work has shown that fine-tuning large pre-trained language models on a collection of tasks described via instructions, a.k.a. instruction-tuning, improves their zero and few-shot generalization to unseen tasks. However, there is a limited understanding of the performance trade-offs of different decisions made during the instruction-tuning process. These decisions include the scale and diversity of the instruction-tuning benchmark, different task sampling strategies, fine-tuning with and without demonstrations, training using specialized datasets for reasoning and dialogue, and finally, the fine-tuning objectives themselves. In this paper, we characterize the effect of instruction-tuning decisions on downstream task performance when scaling both model and benchmark sizes. To this end, we create OPT-IML Bench: a large benchmark for Instruction Meta-Learning (IML) of 2000 NLP tasks consolidated into task categories from 8 existing benchmarks, and prepare an evaluation framework to measure three types of model generalizations: to tasks from fully held-out categories, to held-out tasks from seen categories, and to held-out instances from seen tasks. Through the lens of this framework, we first present insights about instruction-tuning decisions as applied to OPT-30B and further exploit these insights to train OPT-IML 30B and 175B, which are instruction-tuned versions of OPT. OPT-IML demonstrates all three generalization abilities at both scales on four different evaluation benchmarks with diverse tasks and input formats -- PromptSource, FLAN, Super-NaturalInstructions, and UnifiedSKG. Not only does it significantly outperform OPT on all benchmarks but is also highly competitive with existing models fine-tuned on each specific benchmark. We release OPT-IML at both scales, together with the OPT-IML Bench evaluation framework.
STRUDEL: Structured Dialogue Summarization for Dialogue Comprehension
Dec 24, 2022



Abstractive dialogue summarization has long been viewed as an important standalone task in natural language processing, but no previous work has explored the possibility of whether abstractive dialogue summarization can also be used as a means to boost an NLP system's performance on other important dialogue comprehension tasks. In this paper, we propose a novel type of dialogue summarization task - STRUctured DiaLoguE Summarization - that can help pre-trained language models to better understand dialogues and improve their performance on important dialogue comprehension tasks. We further collect human annotations of STRUDEL summaries over 400 dialogues and introduce a new STRUDEL dialogue comprehension modeling framework that integrates STRUDEL into a graph-neural-network-based dialogue reasoning module over transformer encoder language models to improve their dialogue comprehension abilities. In our empirical experiments on two important downstream dialogue comprehension tasks - dialogue question answering and dialogue response prediction - we show that our STRUDEL dialogue comprehension model can significantly improve the dialogue comprehension performance of transformer encoder language models.
Improving Faithfulness of Abstractive Summarization by Controlling Confounding Effect of Irrelevant Sentences
Dec 19, 2022



Lack of factual correctness is an issue that still plagues state-of-the-art summarization systems despite their impressive progress on generating seemingly fluent summaries. In this paper, we show that factual inconsistency can be caused by irrelevant parts of the input text, which act as confounders. To that end, we leverage information-theoretic measures of causal effects to quantify the amount of confounding and precisely quantify how they affect the summarization performance. Based on insights derived from our theoretical results, we design a simple multi-task model to control such confounding by leveraging human-annotated relevant sentences when available. Crucially, we give a principled characterization of data distributions where such confounding can be large thereby necessitating the use of human annotated relevant sentences to generate factual summaries. Our approach improves faithfulness scores by 20\% over strong baselines on AnswerSumm \citep{fabbri2021answersumm}, a conversation summarization dataset where lack of faithfulness is a significant issue due to the subjective nature of the task. Our best method achieves the highest faithfulness score while also achieving state-of-the-art results on standard metrics like ROUGE and METEOR. We corroborate these improvements through human evaluation.
ALERT: Adapting Language Models to Reasoning Tasks
Dec 16, 2022



Current large language models can perform reasonably well on complex tasks that require step-by-step reasoning with few-shot learning. Are these models applying reasoning skills they have learnt during pre-training and reason outside of their training context, or are they simply memorizing their training corpus at finer granularity and have learnt to better understand their context? To tease apart these possibilities, we introduce ALERT, a benchmark and suite of analyses for assessing language models' reasoning ability comparing pre-trained and finetuned models on complex tasks that require reasoning skills to solve. ALERT provides a test bed to asses any language model on fine-grained reasoning skills, which spans over 20 datasets and covers 10 different reasoning skills. We leverage ALERT to further investigate the role of finetuning. With extensive empirical analysis we find that language models learn more reasoning skills such as textual entailment, abductive reasoning, and analogical reasoning during finetuning stage compared to pretraining state. We also find that when language models are finetuned they tend to overfit to the prompt template, which hurts the robustness of models causing generalization problems.
MURMUR: Modular Multi-Step Reasoning for Semi-Structured Data-to-Text Generation
Dec 16, 2022



Prompting large language models has enabled significant recent progress in multi-step reasoning over text. However, when applied to text generation from semi-structured data (e.g., graphs or tables), these methods typically suffer from low semantic coverage, hallucination, and logical inconsistency. We propose MURMUR, a neuro-symbolic modular approach to text generation from semi-structured data with multi-step reasoning. MURMUR is a best-first search method that generates reasoning paths using: (1) neural and symbolic modules with specific linguistic and logical skills, (2) a grammar whose production rules define valid compositions of modules, and (3) value functions that assess the quality of each reasoning step. We conduct experiments on two diverse data-to-text generation tasks like WebNLG and LogicNLG. These tasks differ in their data representations (graphs and tables) and span multiple linguistic and logical skills. MURMUR obtains significant improvements over recent few-shot baselines like direct prompting and chain-of-thought prompting, while also achieving comparable performance to fine-tuned GPT-2 on out-of-domain data. Moreover, human evaluation shows that MURMUR generates highly faithful and correct reasoning paths that lead to 26% more logically consistent summaries on LogicNLG, compared to direct prompting.
ROSCOE: A Suite of Metrics for Scoring Step-by-Step Reasoning
Dec 15, 2022



Large language models show improved downstream task performance when prompted to generate step-by-step reasoning to justify their final answers. These reasoning steps greatly improve model interpretability and verification, but objectively studying their correctness (independent of the final answer) is difficult without reliable methods for automatic evaluation. We simply do not know how often the stated reasoning steps actually support the final end task predictions. In this work, we present ROSCOE, a suite of interpretable, unsupervised automatic scores that improve and extend previous text generation evaluation metrics. To evaluate ROSCOE against baseline metrics, we design a typology of reasoning errors and collect synthetic and human evaluation scores on commonly used reasoning datasets. In contrast with existing metrics, ROSCOE can measure semantic consistency, logicality, informativeness, fluency, and factuality - among other traits - by leveraging properties of step-by-step rationales. We empirically verify the strength of our metrics on five human annotated and six programmatically perturbed diagnostics datasets - covering a diverse set of tasks that require reasoning skills and show that ROSCOE can consistently outperform baseline metrics.
Complementary Explanations for Effective In-Context Learning
Nov 25, 2022



Large language models (LLMs) have exhibited remarkable capabilities in learning from explanations in prompts. Yet, there has been limited understanding of what makes explanations effective for in-context learning. This work aims to better understand the mechanisms by which explanations are used for in-context learning. We first study the impact of two different factors on prompting performance when using explanations: the computation trace (the way the solution is decomposed) and the natural language of the prompt. By perturbing explanations on three controlled tasks, we show that both factors contribute to the effectiveness of explanations, indicating that LLMs do faithfully follow the explanations to some extent. We further study how to form maximally effective sets of explanations for solving a given test query. We find that LLMs can benefit from the complementarity of the explanation set as they are able to fuse different reasoning specified by individual exemplars in prompts. Additionally, having relevant exemplars also contributes to more effective prompts. Therefore, we propose a maximal-marginal-relevance-based exemplar selection approach for constructing exemplar sets that are both relevant as well as complementary, which successfully improves the in-context learning performance across three real-world tasks on multiple LLMs.
ED-FAITH: Evaluating Dialogue Summarization on Faithfulness
Nov 15, 2022



Abstractive summarization models typically generate content unfaithful to the input, thus highlighting the significance of evaluating the faithfulness of generated summaries. Most faithfulness metrics are only evaluated on news domain, can they be transferred to other summarization tasks? In this work, we first present a systematic study of faithfulness metrics for dialogue summarization. We evaluate common faithfulness metrics on dialogue datasets and observe that most metrics correlate poorly with human judgements despite performing well on news datasets. Given these findings, to improve existing metrics' performance on dialogue summarization, we first finetune on in-domain dataset, then apply unlikelihood training on negative samples, and show that they can successfully improve metric performance on dialogue data. Inspired by the strong zero-shot performance of the T0 language model, we further propose T0-Score -- a new metric for faithfulness evaluation, which shows consistent improvement against baseline metrics across multiple domains.
Structural Biases for Improving Transformers on Translation into Morphologically Rich Languages
Aug 11, 2022
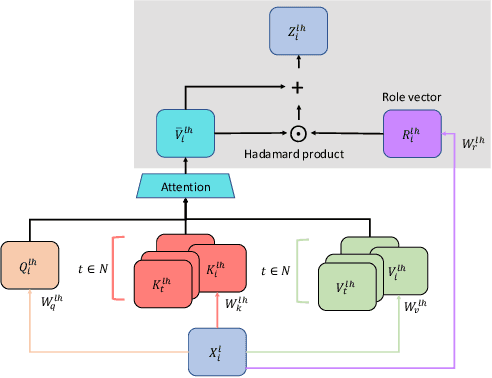

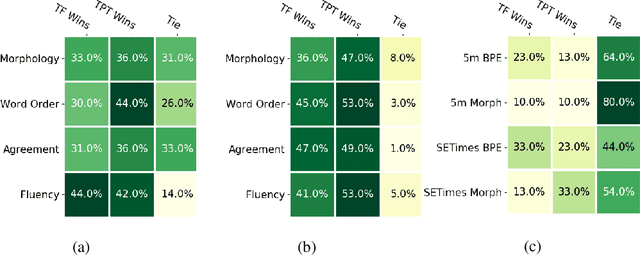
Machine translation has seen rapid progress with the advent of Transformer-based models. These models have no explicit linguistic structure built into them, yet they may still implicitly learn structured relationships by attending to relevant tokens. We hypothesize that this structural learning could be made more robust by explicitly endowing Transformers with a structural bias, and we investigate two methods for building in such a bias. One method, the TP-Transformer, augments the traditional Transformer architecture to include an additional component to represent structure. The second method imbues structure at the data level by segmenting the data with morphological tokenization. We test these methods on translating from English into morphologically rich languages, Turkish and Inuktitut, and consider both automatic metrics and human evaluations. We find that each of these two approaches allows the network to achieve better performance, but this improvement is dependent on the size of the dataset. In sum, structural encoding methods make Transformers more sample-efficient, enabling them to perform better from smaller amounts of data.
* Revised edition to 4th Workshop on Technologies for MT of Low Resource Languages