 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Hierarchical Planner from Humans in Multiple Generations
Oct 17, 2023A typical way in which a machine acquires knowledge from humans is by programming. Compared to learning from demonstrations or experiences, programmatic learning allows the machine to acquire a novel skill as soon as the program is written, and, by building a library of programs, a machine can quickly learn how to perform complex tasks. However, as programs often take their execution contexts for granted, they are brittle when the contexts change, making it difficult to adapt complex programs to new contexts. We present natural programming, a library learning system that combines programmatic learning with a hierarchical planner. Natural programming maintains a library of decompositions, consisting of a goal, a linguistic description of how this goal decompose into sub-goals, and a concrete instance of its decomposition into sub-goals. A user teaches the system via curriculum building, by identifying a challenging yet not impossible goal along with linguistic hints on how this goal may be decomposed into sub-goals. The system solves for the goal via hierarchical planning, using the linguistic hints to guide its probability distribution in proposing the right plans. The system learns from this interaction by adding newly found decompositions in the successful search into its library. Simulated studies and a human experiment (n=360) on a controlled environment demonstrate that natural programming can robustly compose programs learned from different users and contexts, adapting faster and solving more complex tasks when compared to programmatic baselines.
Exploring the MIT Mathematics and EECS Curriculum Using Large Language Models
Jun 24, 2023



We curate a comprehensive dataset of 4,550 questions and solutions from problem sets, midterm exams, and final exams across all MIT Mathematics and Electrical Engineering and Computer Science (EECS) courses required for obtaining a degree. We evaluate the ability of large language models to fulfill the graduation requirements for any MIT major in Mathematics and EECS. Our results demonstrate that GPT-3.5 successfully solves a third of the entire MIT curriculum, while GPT-4, with prompt engineering, achieves a perfect solve rate on a test set excluding questions based on images. We fine-tune an open-source large language model on this dataset. We employ GPT-4 to automatically grade model responses, providing a detailed performance breakdown by course, question, and answer type. By embedding questions in a low-dimensional space, we explore the relationships between questions, topics, and classes and discover which questions and classes are required for solving other questions and classes through few-shot learning. Our analysis offers valuable insights into course prerequisites and curriculum design, highlighting language models' potential for learning and improving Mathematics and EECS education.
Demystifying GPT Self-Repair for Code Generation
Jun 22, 2023Large Language Models (LLMs) have shown remarkable aptitude in code generation but still struggle on challenging programming tasks. Self-repair -- in which the model debugs and fixes mistakes in its own code -- has recently become a popular way to boost performance in these settings. However, only very limited studies on how and when self-repair works effectively exist in the literature, and one might wonder to what extent a model is really capable of providing accurate feedback on why the code is wrong when that code was generated by the same model. In this paper, we analyze GPT-3.5 and GPT-4's ability to perform self-repair on APPS, a challenging dataset consisting of diverse coding challenges. To do so, we first establish a new evaluation strategy dubbed pass@t that measures the pass rate of the tasks against the total number of tokens sampled from the model, enabling a fair comparison to purely sampling-based approaches. With this evaluation strategy, we find that the effectiveness of self-repair is only seen in GPT-4. We also observe that self-repair is bottlenecked by the feedback stage; using GPT-4 to give feedback on the programs generated by GPT-3.5 and using expert human programmers to give feedback on the programs generated by GPT-4, we unlock significant performance gains.
SPARLING: Learning Latent Representations with Extremely Sparse Activations
Feb 03, 2023Real-world processes often contain intermediate state that can be modeled as an extremely sparse tensor. We introduce Sparling, a new kind of informational bottleneck that explicitly models this state by enforcing extreme activation sparsity. We additionally demonstrate that this technique can be used to learn the true intermediate representation with no additional supervision (i.e., from only end-to-end labeled examples), and thus improve the interpretability of the resulting models. On our DigitCircle domain, we are able to get an intermediate state prediction accuracy of 98.84%, even as we only train end-to-end.
Top-Down Synthesis for Library Learning
Nov 29, 2022



This paper introduces corpus-guided top-down synthesis as a mechanism for synthesizing library functions that capture common functionality from a corpus of programs in a domain specific language (DSL). The algorithm builds abstractions directly from initial DSL primitives, using syntactic pattern matching of intermediate abstractions to intelligently prune the search space and guide the algorithm towards abstractions that maximally capture shared structures in the corpus. We present an implementation of the approach in a tool called Stitch and evaluate it against the state-of-the-art deductive library learning algorithm from DreamCoder. Our evaluation shows that Stitch is 3-4 orders of magnitude faster and uses 2 orders of magnitude less memory while maintaining comparable or better library quality (as measured by compressivity). We also demonstrate Stitch's scalability on corpora containing hundreds of complex programs that are intractable with prior deductive approaches and show empirically that it is robust to terminating the search procedure early -- further allowing it to scale to challenging datasets by means of early stopping.
Human Evaluation of Text-to-Image Models on a Multi-Task Benchmark
Nov 22, 2022



We provide a new multi-task benchmark for evaluating text-to-image models. We perform a human evaluation comparing the most common open-source (Stable Diffusion) and commercial (DALL-E 2) models. Twenty computer science AI graduate students evaluated the two models, on three tasks, at three difficulty levels, across ten prompts each, providing 3,600 ratings. Text-to-image generation has seen rapid progress to the point that many recent models have demonstrated their ability to create realistic high-resolution images for various prompts. However, current text-to-image methods and the broader body of research in vision-language understanding still struggle with intricate text prompts that contain many objects with multiple attributes and relationships. We introduce a new text-to-image benchmark that contains a suite of thirty-two tasks over multiple applications that capture a model's ability to handle different features of a text prompt. For example, asking a model to generate a varying number of the same object to measure its ability to count or providing a text prompt with several objects that each have a different attribute to identify its ability to match objects and attributes correctly. Rather than subjectively evaluating text-to-image results on a set of prompts, our new multi-task benchmark consists of challenge tasks at three difficulty levels (easy, medium, and hard) and human ratings for each generated image.
LEMMA: Bootstrapping High-Level Mathematical Reasoning with Learned Symbolic Abstractions
Nov 16, 2022Humans tame the complexity of mathematical reasoning by developing hierarchies of abstractions. With proper abstractions, solutions to hard problems can be expressed concisely, thus making them more likely to be found. In this paper, we propose Learning Mathematical Abstractions (LEMMA): an algorithm that implements this idea for reinforcement learning agents in mathematical domains. LEMMA augments Expert Iteration with an abstraction step, where solutions found so far are revisited and rewritten in terms of new higher-level actions, which then become available to solve new problems. We evaluate LEMMA on two mathematical reasoning tasks--equation solving and fraction simplification--in a step-by-step fashion. In these two domains, LEMMA improves the ability of an existing agent, both solving more problems and generalizing more effectively to harder problems than those seen during training.
ObSynth: An Interactive Synthesis System for Generating Object Models from Natural Language Specifications
Oct 20, 2022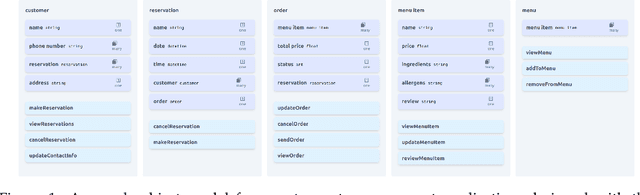

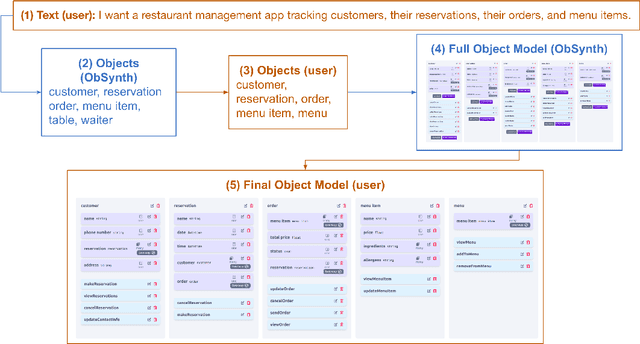
We introduce ObSynth, an interactive system leveraging the domain knowledge embedded in large language models (LLMs) to help users design object models from high level natural language prompts. This is an example of specification reification, the process of taking a high-level, potentially vague specification and reifying it into a more concrete form. We evaluate ObSynth via a user study, leading to three key findings: first, object models designed using ObSynth are more detailed, showing that it often synthesizes fields users might have otherwise omitted. Second, a majority of objects, methods, and fields generated by ObSynth are kept by the user in the final object model, highlighting the quality of generated components. Third, ObSynth altered the workflow of participants: they focus on checking that synthesized components were correct rather than generating them from scratch, though ObSynth did not reduce the time participants took to generate object models.
Neurosymbolic Programming for Science
Oct 10, 2022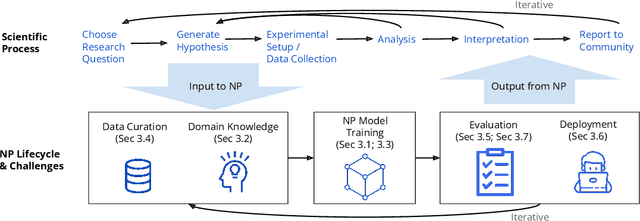
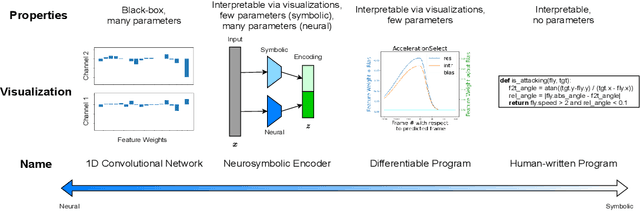
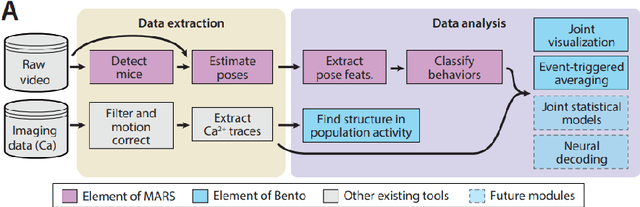
Neurosymbolic Programming (NP) techniques have the potential to accelerate scientific discovery across fields. These models combine neural and symbolic components to learn complex patterns and representations from data, using high-level concepts or known constraints. As a result, NP techniques can interface with symbolic domain knowledge from scientists, such as prior knowledge and experimental context, to produce interpretable outputs. Here, we identify opportunities and challenges between current NP models and scientific workflows, with real-world examples from behavior analysis in science. We define concrete next steps to move the NP for science field forward, to enable its use broadly for workflows across the natural and social sciences.
JoinABLe: Learning Bottom-up Assembly of Parametric CAD Joints
Nov 24, 2021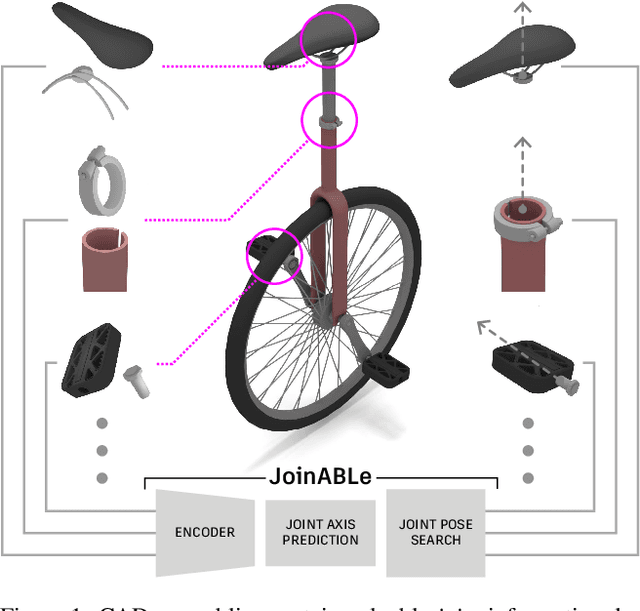
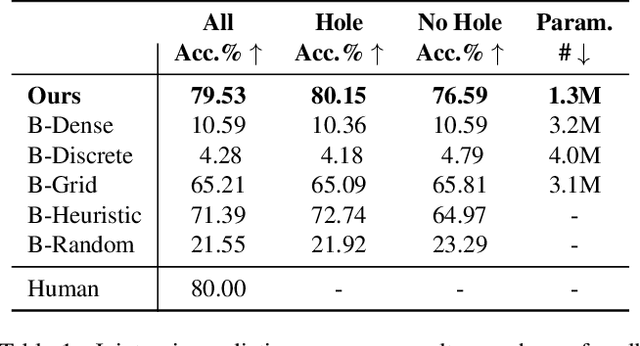
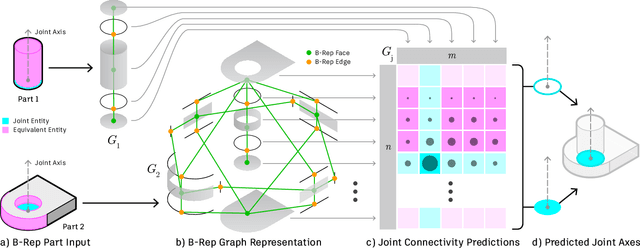
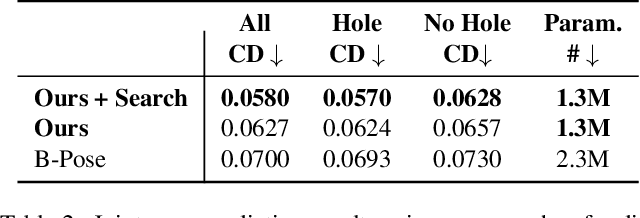
Physical products are often complex assemblies combining a multitude of 3D parts modeled in computer-aided design (CAD) software. CAD designers build up these assemblies by aligning individual parts to one another using constraints called joints. In this paper we introduce JoinABLe, a learning-based method that assembles parts together to form joints. JoinABLe uses the weak supervision available in standard parametric CAD files without the help of object class labels or human guidance. Our results show that by making network predictions over a graph representation of solid models we can outperform multiple baseline methods with an accuracy (79.53%) that approaches human performance (80%). Finally, to support future research we release the Fusion 360 Gallery assembly dataset, containing assemblies with rich information on joints, contact surfaces, holes, and the underlying assembly graph structure.