 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Driven Review Systems: Evaluating LLMs in Scalable and Bias-Aware Academic Reviews
Aug 19, 2024



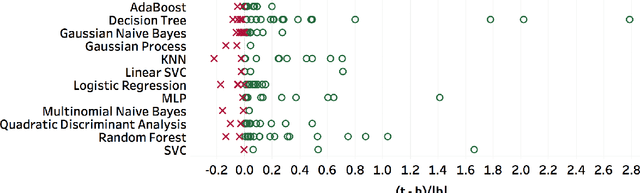
Automatic reviewing helps handle a large volume of papers, provides early feedback and quality control, reduces bias, and allows the analysis of trends. We evaluate the alignment of automatic paper reviews with human reviews using an arena of human preferences by pairwise comparisons. Gathering human preference may be time-consuming; therefore, we also use an LLM to automatically evaluate reviews to increase sample efficiency while reducing bias. In addition to evaluating human and LLM preferences among LLM reviews, we fine-tune an LLM to predict human preferences, predicting which reviews humans will prefer in a head-to-head battle between LLMs. We artificially introduce errors into papers and analyze the LLM's responses to identify limitations, use adaptive review questions, meta prompting, role-playing, integrate visual and textual analysis, use venue-specific reviewing materials, and predict human preferences, improving upon the limitations of the traditional review processes. We make the reviews of publicly available arXiv and open-access Nature journal papers available online, along with a free service which helps authors review and revise their research papers and improve their quality. This work develops proof-of-concept LLM reviewing systems that quickly deliver consistent, high-quality reviews and evaluate their quality. We mitigate the risks of misuse, inflated review scores, overconfident ratings, and skewed score distributions by augmenting the LLM with multiple documents, including the review form, reviewer guide, code of ethics and conduct, area chair guidelines, and previous year statistics, by finding which errors and shortcomings of the paper may be detected by automated reviews, and evaluating pairwise reviewer preferences. This work identifies and addresses the limitations of using LLMs as reviewers and evaluators and enhances the quality of the reviewing process.
Exploring the MIT Mathematics and EECS Curriculum Using Large Language Models
Jun 24, 2023



We curate a comprehensive dataset of 4,550 questions and solutions from problem sets, midterm exams, and final exams across all MIT Mathematics and Electrical Engineering and Computer Science (EECS) courses required for obtaining a degree. We evaluate the ability of large language models to fulfill the graduation requirements for any MIT major in Mathematics and EECS. Our results demonstrate that GPT-3.5 successfully solves a third of the entire MIT curriculum, while GPT-4, with prompt engineering, achieves a perfect solve rate on a test set excluding questions based on images. We fine-tune an open-source large language model on this dataset. We employ GPT-4 to automatically grade model responses, providing a detailed performance breakdown by course, question, and answer type. By embedding questions in a low-dimensional space, we explore the relationships between questions, topics, and classes and discover which questions and classes are required for solving other questions and classes through few-shot learning. Our analysis offers valuable insights into course prerequisites and curriculum design, highlighting language models' potential for learning and improving Mathematics and EECS education.
Human Evaluation of Text-to-Image Models on a Multi-Task Benchmark
Nov 22, 2022



We provide a new multi-task benchmark for evaluating text-to-image models. We perform a human evaluation comparing the most common open-source (Stable Diffusion) and commercial (DALL-E 2) models. Twenty computer science AI graduate students evaluated the two models, on three tasks, at three difficulty levels, across ten prompts each, providing 3,600 ratings. Text-to-image generation has seen rapid progress to the point that many recent models have demonstrated their ability to create realistic high-resolution images for various prompts. However, current text-to-image methods and the broader body of research in vision-language understanding still struggle with intricate text prompts that contain many objects with multiple attributes and relationships. We introduce a new text-to-image benchmark that contains a suite of thirty-two tasks over multiple applications that capture a model's ability to handle different features of a text prompt. For example, asking a model to generate a varying number of the same object to measure its ability to count or providing a text prompt with several objects that each have a different attribute to identify its ability to match objects and attributes correctly. Rather than subjectively evaluating text-to-image results on a set of prompts, our new multi-task benchmark consists of challenge tasks at three difficulty levels (easy, medium, and hard) and human ratings for each generated image.
A Dataset and Benchmark for Automatically Answering and Generating Machine Learning Final Exams
Jun 11, 2022


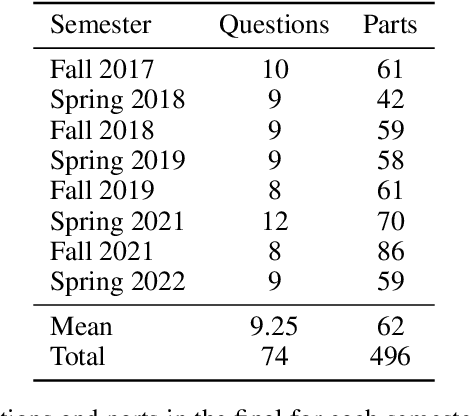
Can a machine learn machine learning? We propose to answer this question using the same criteria we use to answer a similar question: can a human learn machine learning? We automatically answer MIT final exams in Introduction to Machine Learning at a human level. The course is a large undergraduate class with around five hundred students each semester. Recently, program synthesis and few-shot learning solved university-level problem set questions in mathematics and STEM courses at a human level. In this work, we solve questions from final exams that differ from problem sets in several ways: the questions are longer, have multiple parts, are more complicated, and span a broader set of topics. We provide a new dataset and benchmark of questions from eight MIT Introduction to Machine Learning final exams between Fall 2017 and Spring 2022 and provide code for automatically answering these questions and generating new questions. We perform ablation studies comparing zero-shot learning with few-shot learning, chain-of-thought prompting, GPT-3 pre-trained on text and Codex fine-tuned on code on a range of machine learning topics and find that few-shot learning methods perform best. We make our data and code publicly available for the machine learning community.
A Neural Network Solves and Generates Mathematics Problems by Program Synthesis: Calculus, Differential Equations, Linear Algebra, and More
Jan 04, 2022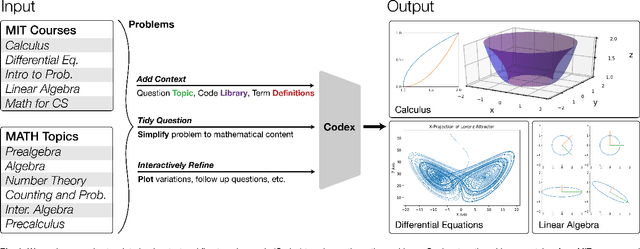
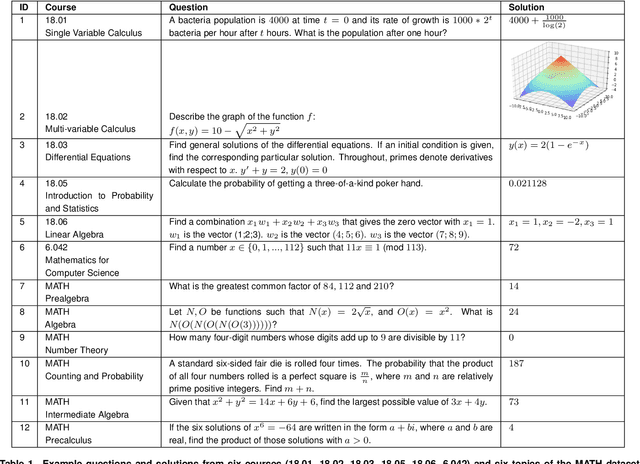
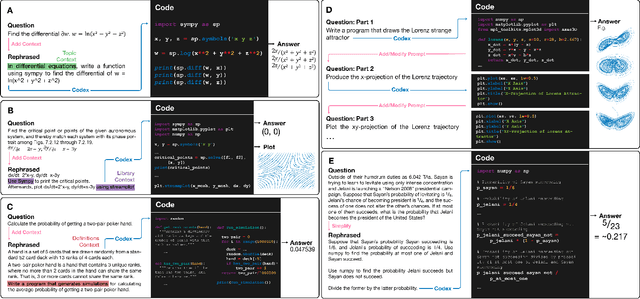
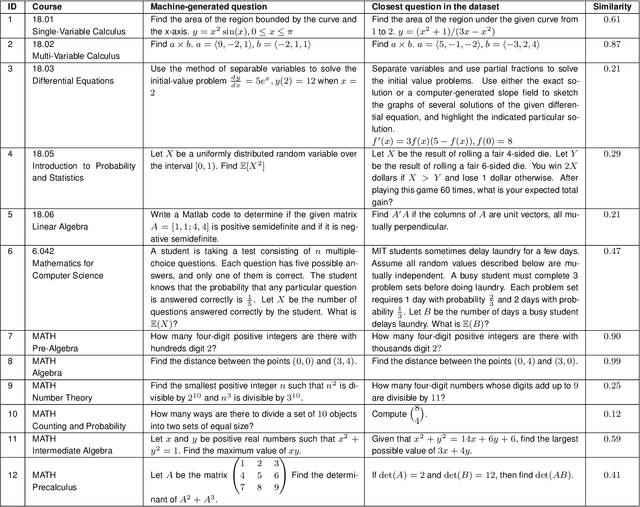
We demonstrate that a neural network pre-trained on text and fine-tuned on code solves Mathematics problems by program synthesis. We turn questions into programming tasks, automatically generate programs, and then execute them, perfectly solving university-level problems from MIT's large Mathematics courses (Single Variable Calculus 18.01, Multivariable Calculus 18.02, Differential Equations 18.03, Introduction to Probability and Statistics 18.05, Linear Algebra 18.06, and Mathematics for Computer Science 6.042), Columbia University's COMS3251 Computational Linear Algebra course, as well as questions from a MATH dataset (on Prealgebra, Algebra, Counting and Probability, Number Theory, and Precalculus), the latest benchmark of advanced mathematics problems specifically designed to assess mathematical reasoning. We explore prompt generation methods that enable Transformers to generate question solving programs for these subjects, including solutions with plots. We generate correct answers for a random sample of questions in each topic. We quantify the gap between the original and transformed questions and perform a survey to evaluate the quality and difficulty of generated questions. This is the first work to automatically solve, grade, and generate university-level Mathematics course questions at scale. This represents a milestone for higher education.
Tracking Blobs in the Turbulent Edge Plasma of Tokamak Fusion Reactors
Nov 16, 2021

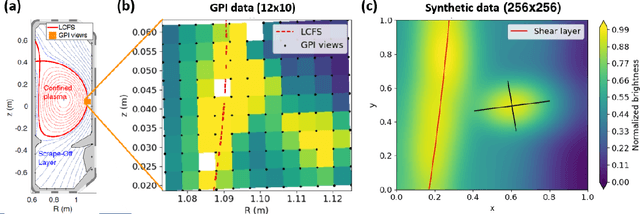
The analysis of turbulent flows is a significant area in fusion plasma physics. Current theoretical models quantify the degree of turbulence based on the evolution of certain plasma density structures, called blobs. In this work we track the shape and the position of these blobs in high frequency video data obtained from Gas Puff Imaging (GPI) diagnostics, by training a mask R-CNN model on synthetic data and testing on both synthetic and real data. As a result, our model effectively tracks blob structures on both synthetic and real experimental GPI data, showing its prospect as a powerful tool to estimate blob statistics linked with edge turbulence of the tokamak plasma.
Solving Probability and Statistics Problems by Program Synthesis
Nov 16, 2021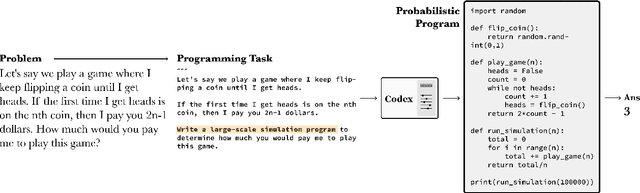


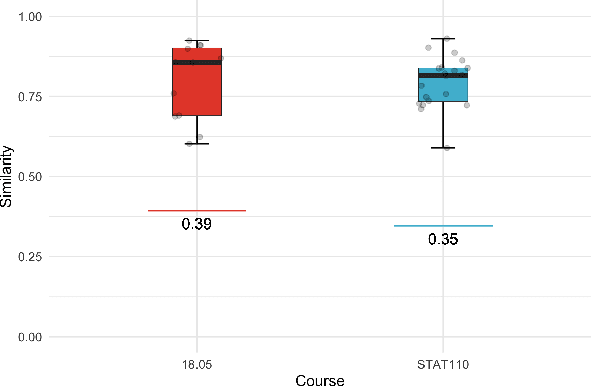
We solve university level probability and statistics questions by program synthesis using OpenAI's Codex, a Transformer trained on text and fine-tuned on code. We transform course problems from MIT's 18.05 Introduction to Probability and Statistics and Harvard's STAT110 Probability into programming tasks. We then execute the generated code to get a solution. Since these course questions are grounded in probability, we often aim to have Codex generate probabilistic programs that simulate a large number of probabilistic dependencies to compute its solution. Our approach requires prompt engineering to transform the question from its original form to an explicit, tractable form that results in a correct program and solution. To estimate the amount of work needed to translate an original question into its tractable form, we measure the similarity between original and transformed questions. Our work is the first to introduce a new dataset of university-level probability and statistics problems and solve these problems in a scalable fashion using the program synthesis capabilities of large language models.
Solving Linear Algebra by Program Synthesis
Nov 16, 2021
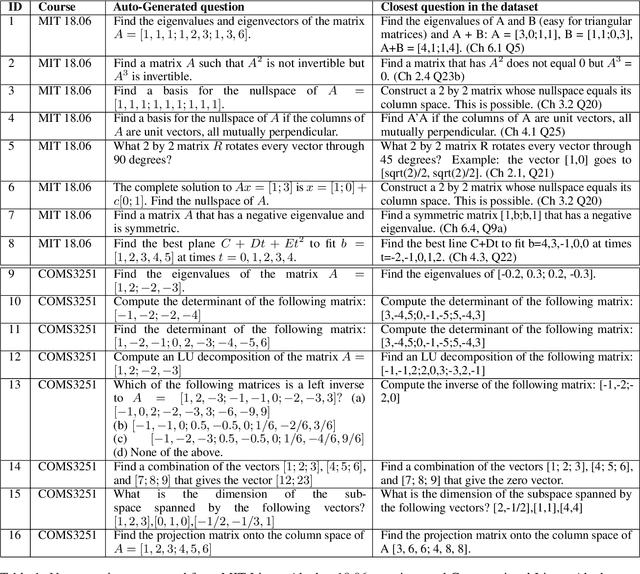
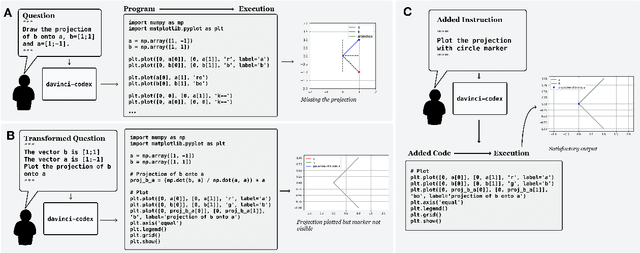
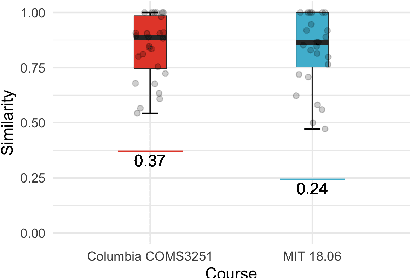
We solve MIT's Linear Algebra 18.06 course and Columbia University's Computational Linear Algebra COMS3251 courses with perfect accuracy by interactive program synthesis. This surprisingly strong result is achieved by turning the course questions into programming tasks and then running the programs to produce the correct answers. We use OpenAI Codex with zero-shot learning, without providing any examples in the prompts, to synthesize code from questions. We quantify the difference between the original question text and the transformed question text that yields a correct answer. Since all COMS3251 questions are not available online the model is not overfitting. We go beyond just generating code for questions with numerical answers by interactively generating code that also results visually pleasing plots as output. Finally, we automatically generate new questions given a few sample questions which may be used as new course content. This work is a significant step forward in solving quantitative math problems and opens the door for solving many university level STEM courses by machine.
AlphaD3M: Machine Learning Pipeline Synthesis
Nov 03, 2021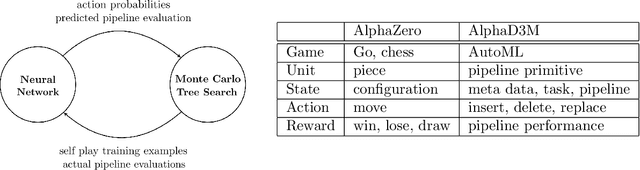
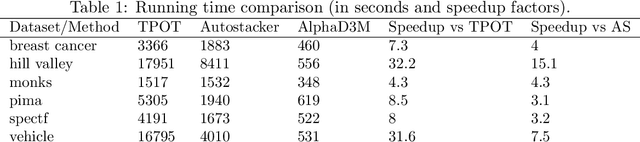
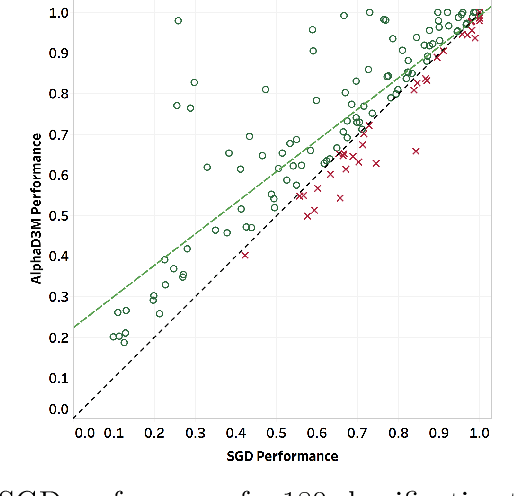
We introduce AlphaD3M, an automatic machine learning (AutoML) system based on meta reinforcement learning using sequence models with self play. AlphaD3M is based on edit operations performed over machine learning pipeline primitives providing explainability. We compare AlphaD3M with state-of-the-art AutoML systems: Autosklearn, Autostacker, and TPOT, on OpenML datasets. AlphaD3M achieves competitive performance while being an order of magnitude faster, reducing computation time from hours to minutes, and is explainable by design.
Predicting Critical Biogeochemistry of the Southern Ocean for Climate Monitoring
Oct 30, 2021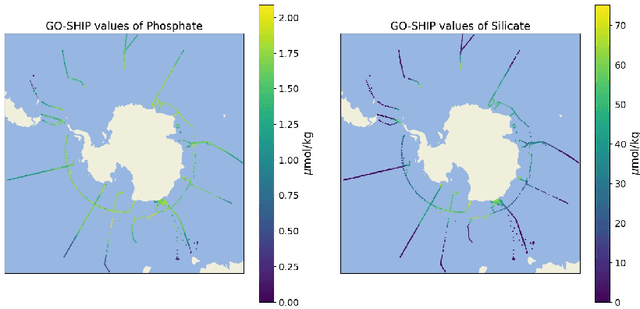
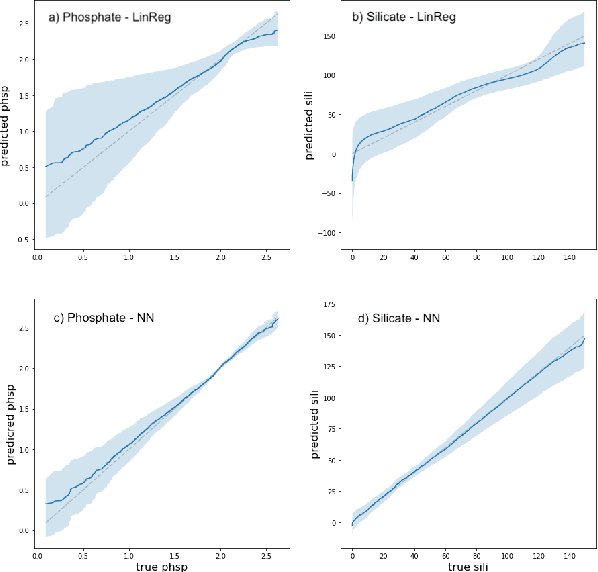
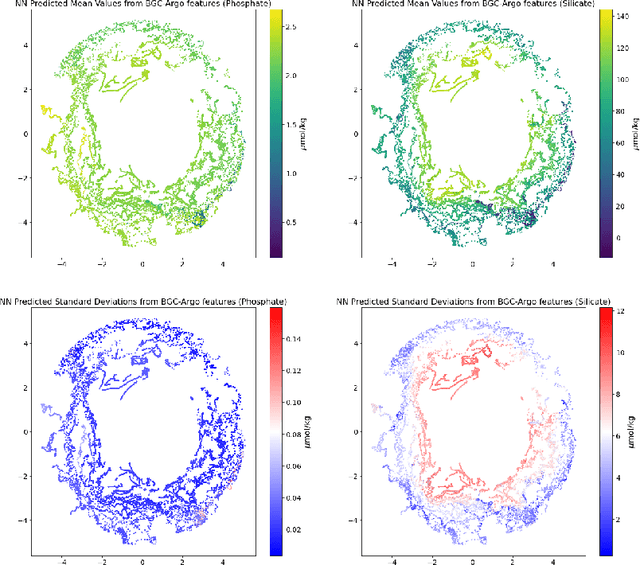
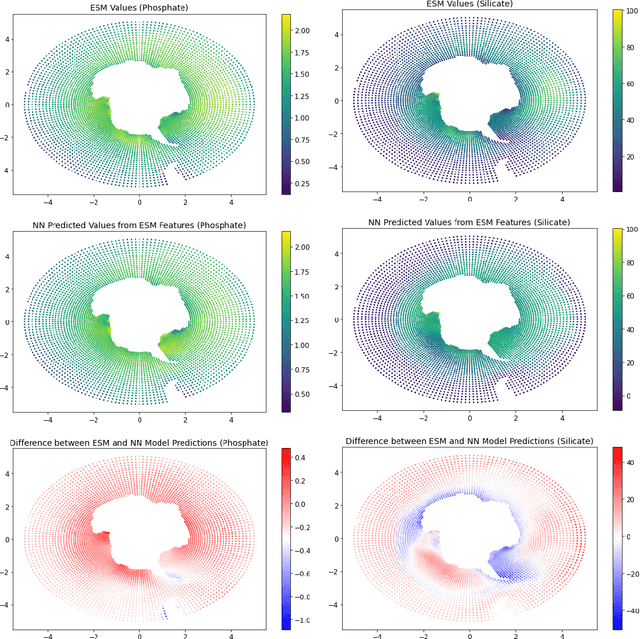
The Biogeochemical-Argo (BGC-Argo) program is building a network of globally distributed, sensor-equipped robotic profiling floats, improving our understanding of the climate system and how it is changing. These floats, however, are limited in the number of variables measured. In this study, we train neural networks to predict silicate and phosphate values in the Southern Ocean from temperature, pressure, salinity, oxygen, nitrate, and location and apply these models to earth system model (ESM) and BGC-Argo data to expand the utility of this ocean observation network. We trained our neural networks on observations from the Global Ocean Ship-Based Hydrographic Investigations Program (GO-SHIP) and use dropout regularization to provide uncertainty bounds around our predicted values. Our neural network significantly improves upon linear regression but shows variable levels of uncertainty across the ranges of predicted variables. We explore the generalization of our estimators to test data outside our training distribution from both ESM and BGC-Argo data. Our use of out-of-distribution test data to examine shifts in biogeochemical parameters and calculate uncertainty bounds around estimates advance the state-of-the-art in oceanographic data and climate monitoring. We make our data and code publicly available.
* 6 pages, 4 figures