 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMethods, Data, and Conceptual Change: Reflections from Two Quantitative Diachronic Case Studies
May 03, 2026This discussion paper reflects on how quantitative approaches to historical linguistics interact with dataset properties. Drawing on two worked examples, we examine English data using quad-based concept modelling of Early Modern English discourse in EEBO-TCP (c. 1470s-1690s; 765M words) alongside SynFlow analysis of scientific writing in Royal Society Corpus 6.0.4 (1750-1799; drawn from a 78.6M-token open corpus). Through parallel comparison, the paper explores how each approach operationalises concepts, the data assumptions they entail, and the diachronic interpretations they support. We argue that comparative methodological reflection clarifies the limits of purely lexical, frequency-based approaches and highlights how dataset structure shapes the kinds of semantic change that quantitative methods can reliably detect.
Top-Down Synthesis for Library Learning
Nov 29, 2022



This paper introduces corpus-guided top-down synthesis as a mechanism for synthesizing library functions that capture common functionality from a corpus of programs in a domain specific language (DSL). The algorithm builds abstractions directly from initial DSL primitives, using syntactic pattern matching of intermediate abstractions to intelligently prune the search space and guide the algorithm towards abstractions that maximally capture shared structures in the corpus. We present an implementation of the approach in a tool called Stitch and evaluate it against the state-of-the-art deductive library learning algorithm from DreamCoder. Our evaluation shows that Stitch is 3-4 orders of magnitude faster and uses 2 orders of magnitude less memory while maintaining comparable or better library quality (as measured by compressivity). We also demonstrate Stitch's scalability on corpora containing hundreds of complex programs that are intractable with prior deductive approaches and show empirically that it is robust to terminating the search procedure early -- further allowing it to scale to challenging datasets by means of early stopping.
Structured, flexible, and robust: benchmarking and improving large language models towards more human-like behavior in out-of-distribution reasoning tasks
May 11, 2022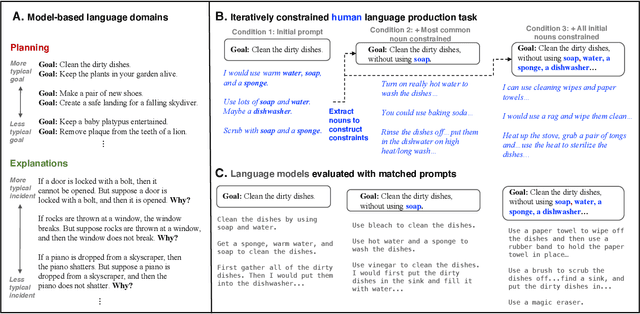

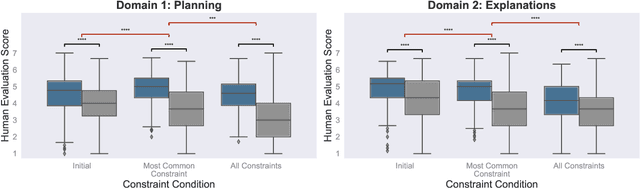
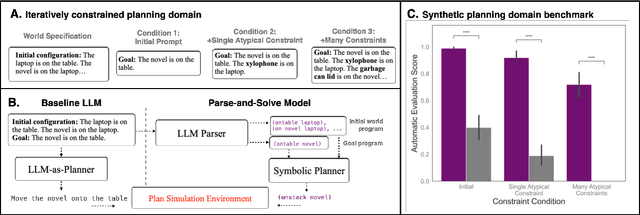
Human language offers a powerful window into our thoughts -- we tell stories, give explanations, and express our beliefs and goals through words. Abundant evidence also suggests that language plays a developmental role in structuring our learning. Here, we ask: how much of human-like thinking can be captured by learning statistical patterns in language alone? We first contribute a new challenge benchmark for comparing humans and distributional large language models (LLMs). Our benchmark contains two problem-solving domains (planning and explanation generation) and is designed to require generalization to new, out-of-distribution problems expressed in language. We find that humans are far more robust than LLMs on this benchmark. Next, we propose a hybrid Parse-and-Solve model, which augments distributional LLMs with a structured symbolic reasoning module. We find that this model shows more robust adaptation to out-of-distribution planning problems, demonstrating the promise of hybrid AI models for more human-like reasoning.
Identifying concept libraries from language about object structure
May 11, 2022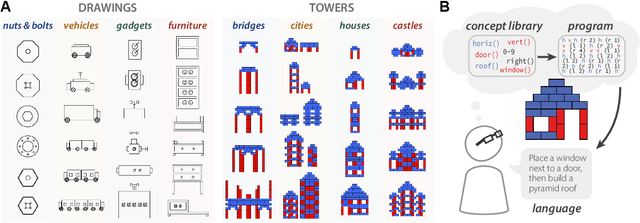
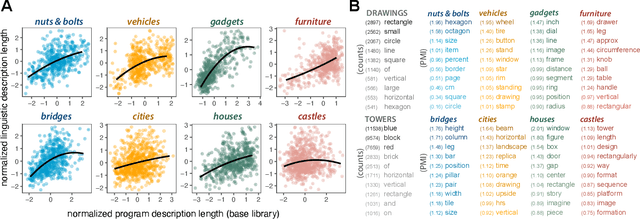
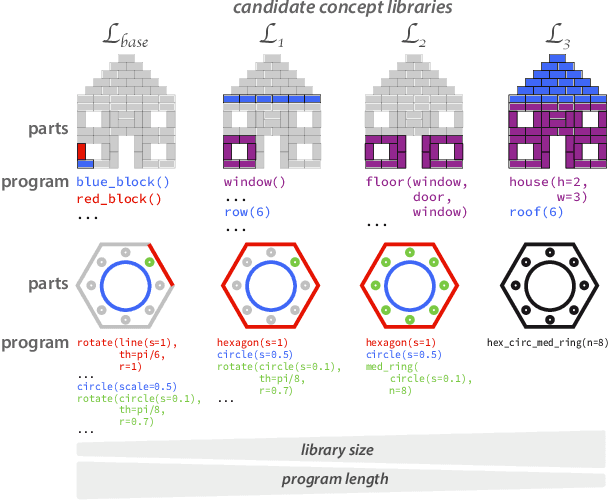
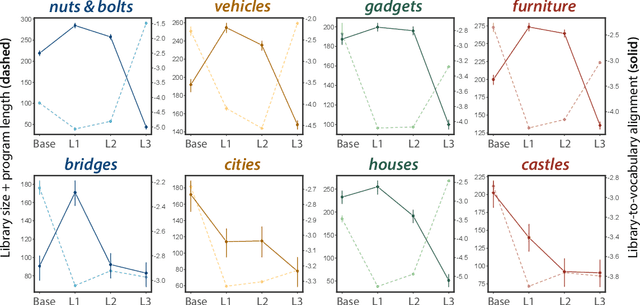
Our understanding of the visual world goes beyond naming objects, encompassing our ability to parse objects into meaningful parts, attributes, and relations. In this work, we leverage natural language descriptions for a diverse set of 2K procedurally generated objects to identify the parts people use and the principles leading these parts to be favored over others. We formalize our problem as search over a space of program libraries that contain different part concepts, using tools from machine translation to evaluate how well programs expressed in each library align to human language. By combining naturalistic language at scale with structured program representations, we discover a fundamental information-theoretic tradeoff governing the part concepts people name: people favor a lexicon that allows concise descriptions of each object, while also minimizing the size of the lexicon itself.
Leveraging Language to Learn Program Abstractions and Search Heuristics
Jun 18, 2021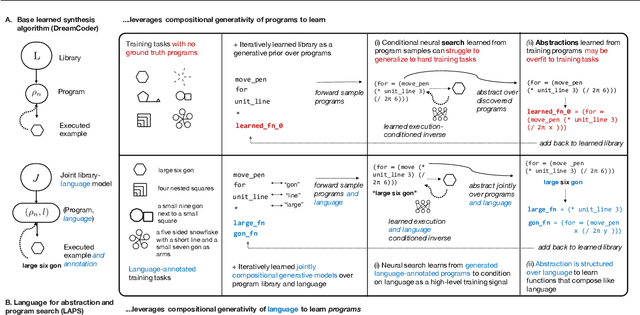
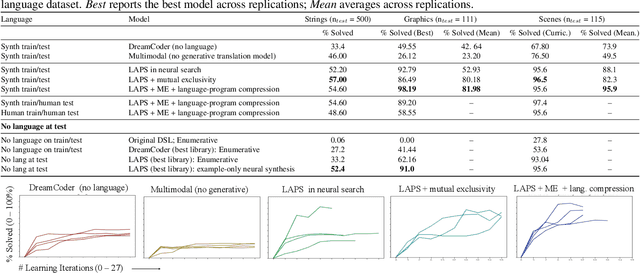


Inductive program synthesis, or inferring programs from examples of desired behavior, offers a general paradigm for building interpretable, robust, and generalizable machine learning systems. Effective program synthesis depends on two key ingredients: a strong library of functions from which to build programs, and an efficient search strategy for finding programs that solve a given task. We introduce LAPS (Language for Abstraction and Program Search), a technique for using natural language annotations to guide joint learning of libraries and neurally-guided search models for synthesis. When integrated into a state-of-the-art library learning system (DreamCoder), LAPS produces higher-quality libraries and improves search efficiency and generalization on three domains -- string editing, image composition, and abstract reasoning about scenes -- even when no natural language hints are available at test time.
Communicating Natural Programs to Humans and Machines
Jun 15, 2021

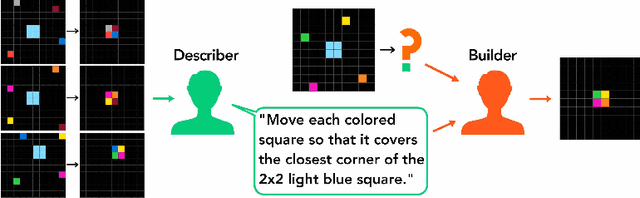
The Abstraction and Reasoning Corpus (ARC) is a set of tasks that tests an agent's ability to flexibly solve novel problems. While most ARC tasks are easy for humans, they are challenging for state-of-the-art AI. How do we build intelligent systems that can generalize to novel situations and understand human instructions in domains such as ARC? We posit that the answer may be found by studying how humans communicate to each other in solving these tasks. We present LARC, the Language-annotated ARC: a collection of natural language descriptions by a group of human participants, unfamiliar both with ARC and with each other, who instruct each other on how to solve ARC tasks. LARC contains successful instructions for 88\% of the ARC tasks. We analyze the collected instructions as `natural programs', finding that most natural program concepts have analogies in typical computer programs. However, unlike how one precisely programs a computer, we find that humans both anticipate and exploit ambiguities to communicate effectively. We demonstrate that a state-of-the-art program synthesis technique, which leverages the additional language annotations, outperforms its language-free counterpart.
DreamCoder: Growing generalizable, interpretable knowledge with wake-sleep Bayesian program learning
Jun 15, 2020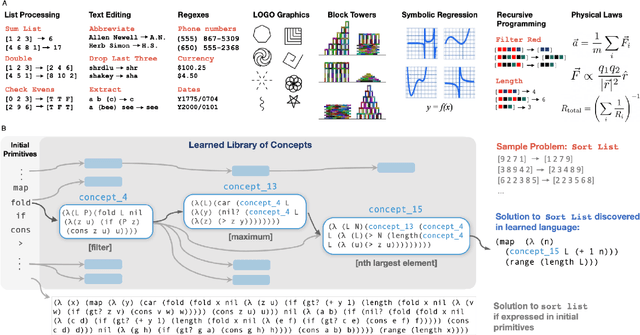
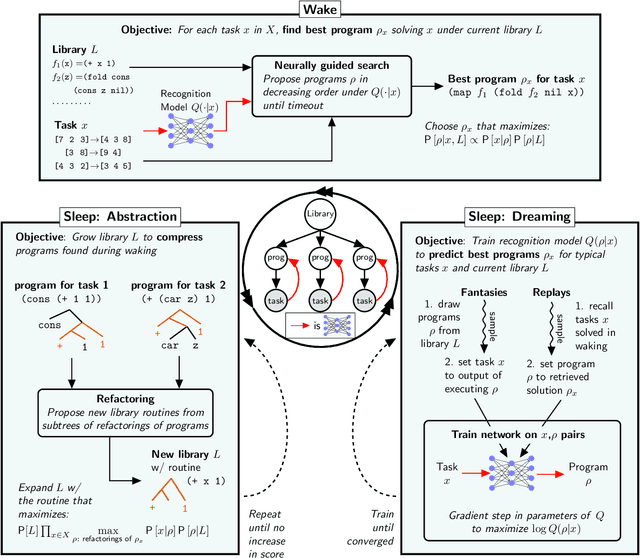
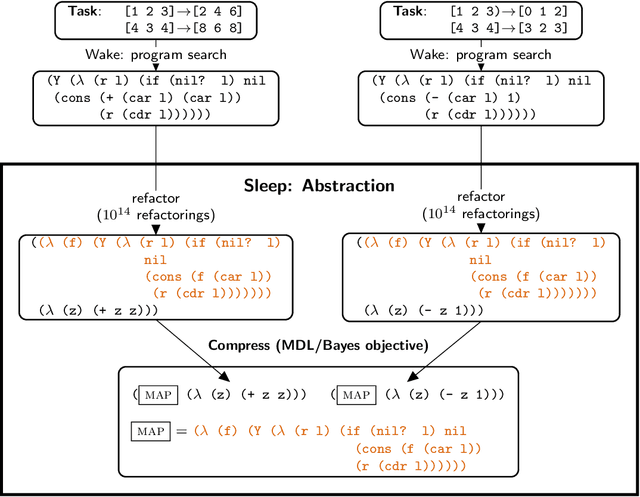

Expert problem-solving is driven by powerful languages for thinking about problems and their solutions. Acquiring expertise means learning these languages -- systems of concepts, alongside the skills to use them. We present DreamCoder, a system that learns to solve problems by writing programs. It builds expertise by creating programming languages for expressing domain concepts, together with neural networks to guide the search for programs within these languages. A ``wake-sleep'' learning algorithm alternately extends the language with new symbolic abstractions and trains the neural network on imagined and replayed problems. DreamCoder solves both classic inductive programming tasks and creative tasks such as drawing pictures and building scenes. It rediscovers the basics of modern functional programming, vector algebra and classical physics, including Newton's and Coulomb's laws. Concepts are built compositionally from those learned earlier, yielding multi-layered symbolic representations that are interpretable and transferrable to new tasks, while still growing scalably and flexibly with experience.
Transfer Learning with Neural AutoML
Sep 27, 2018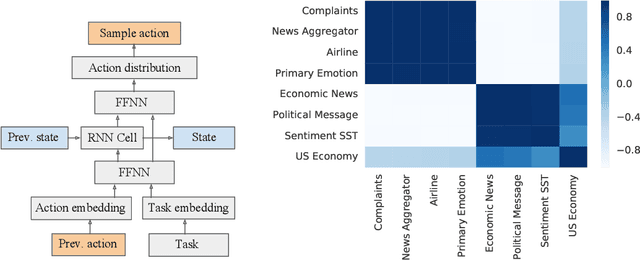
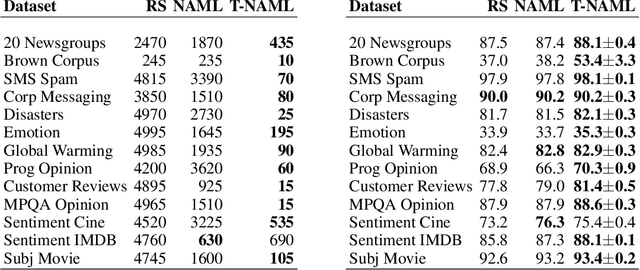
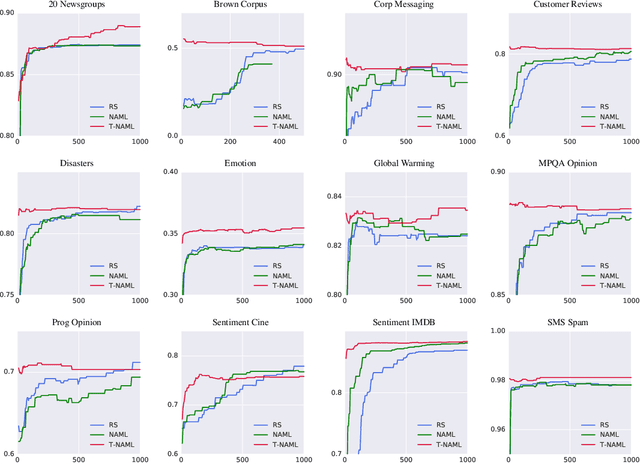
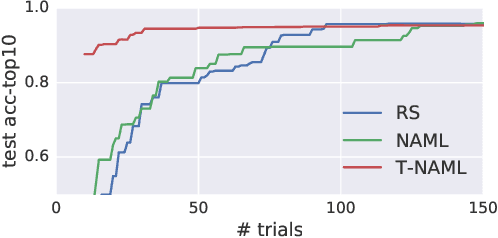
We reduce the computational cost of Neural AutoML with transfer learning. AutoML relieves human effort by automating the design of ML algorithms. Neural AutoML has become popular for the design of deep learning architectures, however, this method has a high computation cost.To address this we propose Transfer Neural AutoML that uses knowledge from prior tasks to speed up network design. We extend RL-based architecture search methods to support parallel training on multiple tasks and then transfer the search strategy to new tasks. On language and image classification data, Transfer Neural AutoML reduces convergence time over single-task training by over an order of magnitude on many tasks.
Amanuensis: The Programmer's Apprentice
Jun 29, 2018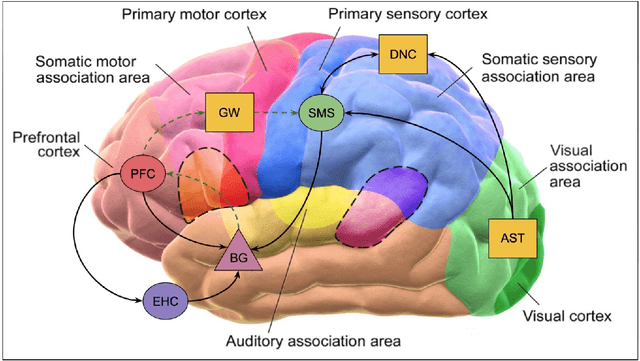
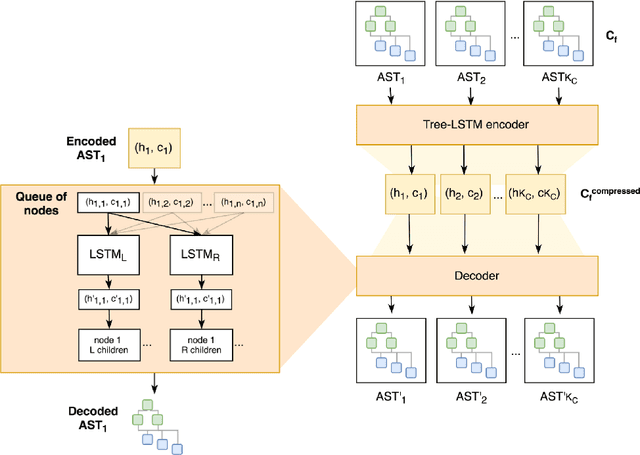
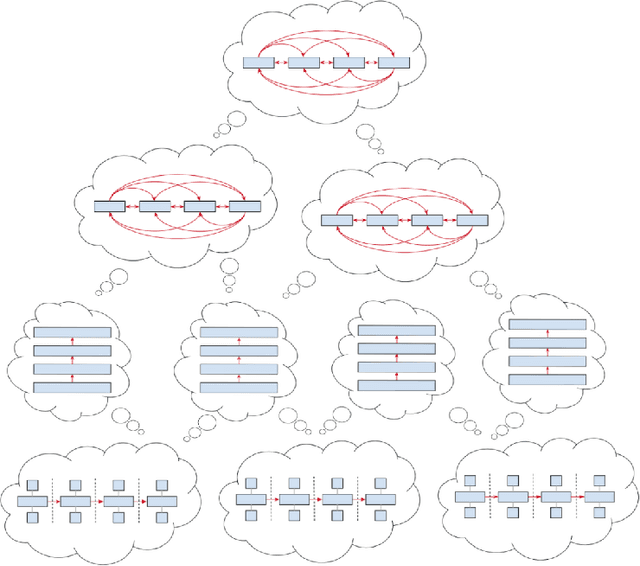
This document provides an overview of the material covered in a course taught at Stanford in the spring quarter of 2018. The course draws upon insight from cognitive and systems neuroscience to implement hybrid connectionist and symbolic reasoning systems that leverage and extend the state of the art in machine learning by integrating human and machine intelligence. As a concrete example we focus on digital assistants that learn from continuous dialog with an expert software engineer while providing initial value as powerful analytical, computational and mathematical savants. Over time these savants learn cognitive strategies (domain-relevant problem solving skills) and develop intuitions (heuristics and the experience necessary for applying them) by learning from their expert associates. By doing so these savants elevate their innate analytical skills allowing them to partner on an equal footing as versatile collaborators - effectively serving as cognitive extensions and digital prostheses, thereby amplifying and emulating their human partner's conceptually-flexible thinking patterns and enabling improved access to and control over powerful computing resources.
DANCin SEQ2SEQ: Fooling Text Classifiers with Adversarial Text Example Generation
Dec 14, 2017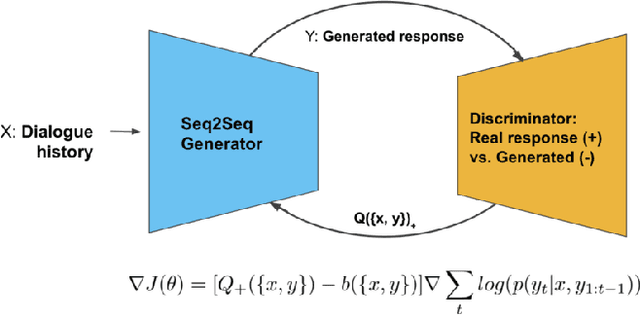
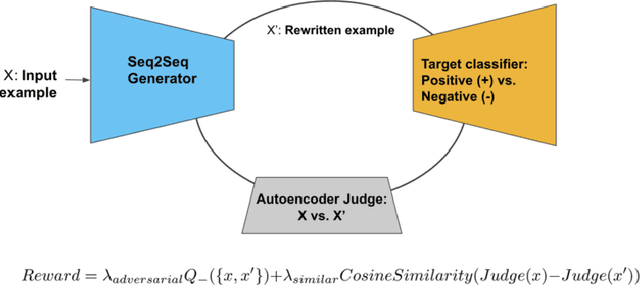


Machine learning models are powerful but fallible. Generating adversarial examples - inputs deliberately crafted to cause model misclassification or other errors - can yield important insight into model assumptions and vulnerabilities. Despite significant recent work on adversarial example generation targeting image classifiers, relatively little work exists exploring adversarial example generation for text classifiers; additionally, many existing adversarial example generation algorithms require full access to target model parameters, rendering them impractical for many real-world attacks. In this work, we introduce DANCin SEQ2SEQ, a GAN-inspired algorithm for adversarial text example generation targeting largely black-box text classifiers. We recast adversarial text example generation as a reinforcement learning problem, and demonstrate that our algorithm offers preliminary but promising steps towards generating semantically meaningful adversarial text examples in a real-world attack scenario.